Kürzlich hatte ich die Gelegenheit, auf der SparksCon, Deutschlands größter Digital Experience Conference, einen Vortrag zum Thema „KI im Unternehmensalltag“ zu halten. Für alle, die nicht dabei sein konnten oder die Inhalte noch einmal vertiefen möchten, habe ich die Aufzeichnung nun samt Folien online gestellt:
In diesem Blogbeitrag möchte ich euch einen Einblick in die Kernthemen meines Vortrags geben.
Eine Reise durch die Welt der KI
In meinem Vortrag nahm ich das Publikum mit auf eine Reise durch die Entwicklung der künstlichen Intelligenz, von den Anfängen bis zum aktuellen Hype um generative KI. Dabei betonte ich, dass KI keineswegs ein neues Phänomen ist. Schon 1956 wurde der Begriff geprägt, ursprünglich als Mittel, um Forschungsgelder zu akquirieren. Seitdem hat sich viel getan, und wir befinden uns nun auf dem Höhepunkt des Hypes um generative KI.
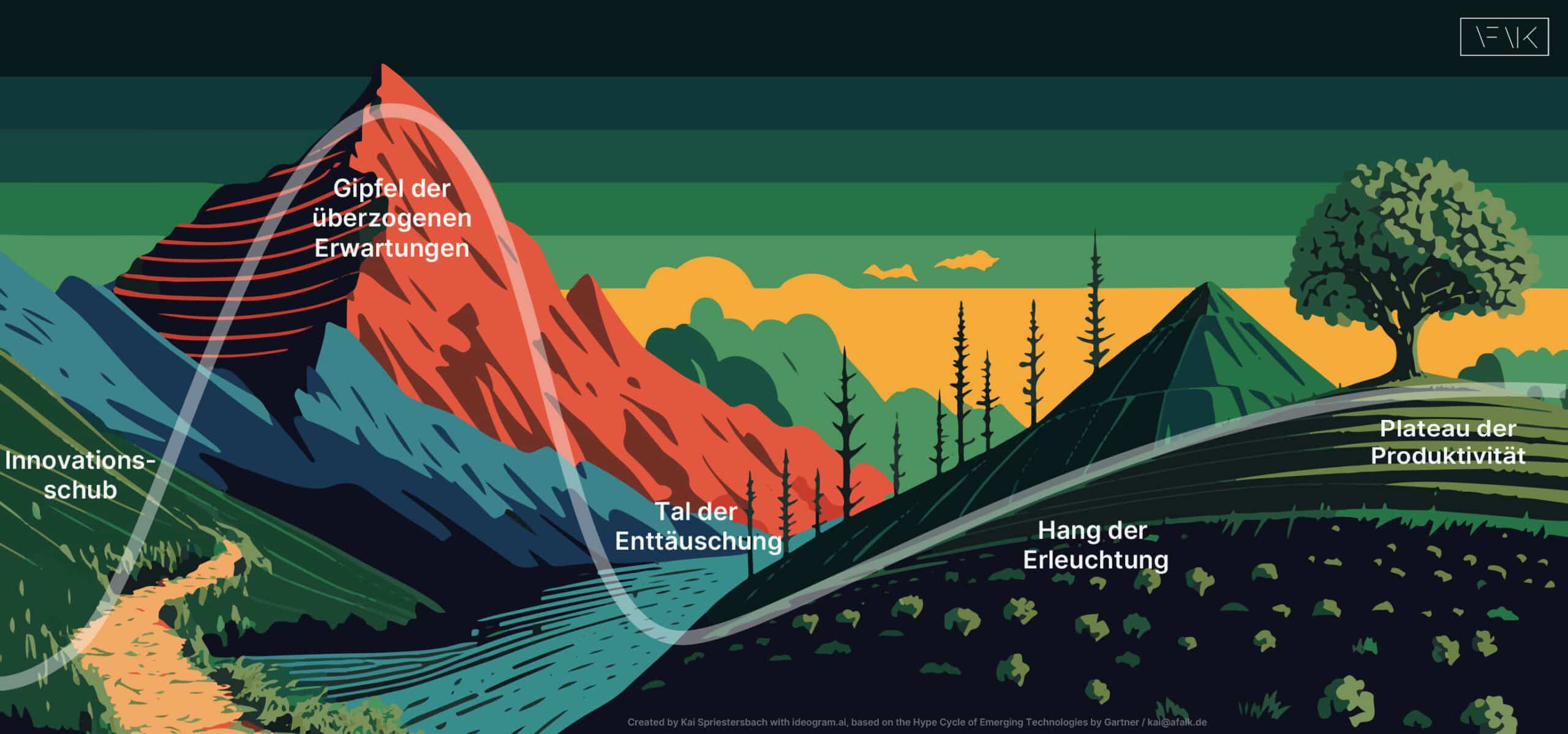
Ich erläuterte den „Hype Cycle“ von Gartner, der die Entwicklung neuer Technologien beschreibt. Generative KI befindet sich derzeit auf dem „Gipfel der überzogenen Erwartungen“. Das bedeutet, dass wir in der nächsten Phase wahrscheinlich eine gewisse Ernüchterung erleben werden, bevor die Technologie wirklich produktiv eingesetzt werden kann.
Technische Grundlagen und Herausforderungen
Ein wichtiger Teil meines Vortrags widmete sich den technischen Grundlagen der modernen KI-Modelle. Ich erklärte das Konzept der Transformer, die einen Durchbruch in der Verarbeitung natürlicher Sprache ermöglicht haben. Diese Architektur erlaubt es KI-Modellen, den Kontext von Wörtern in einem Satz besser zu verstehen und dadurch präzisere Vorhersagen zu treffen.
Trotz dieser Fortschritte betonte ich, dass KI-Modelle auf statistischen Wahrscheinlichkeiten basieren und kein echtes Verständnis haben. Sie können beeindruckende Ergebnisse liefern, aber auch schwerwiegende Fehler machen, insbesondere wenn es um Fakten geht. Ich illustrierte dies mit Beispielen von KI-generierten Texten, die zwar überzeugend klingen, aber oft falsche Informationen enthalten.
Praxisbeispiel: KI im Kundenservice
Um die praktische Anwendung von KI zu verdeutlichen, teilte ich ein Beispiel aus meiner eigenen Erfahrung. Ich berichtete von einem Projekt für einen Trapezblech-Händler, bei dem wir KI einsetzten, um den potenziellen Auftragswert von Kundenanfragen zu schätzen. Dies half dem Unternehmen, effizienter zu entscheiden, welche Anfragen eine persönliche Bearbeitung erfordern und welche automatisch beantwortet werden können.
Dieses Beispiel zeigte auch die Herausforderungen bei der Implementierung von KI-Lösungen. Wir mussten uns mit Fragen des Datenschutzes, der Modellauswahl und der Integration in bestehende Systeme auseinandersetzen. Besonders wichtig war es, ein System zu entwickeln, das transparent und nachvollziehbar arbeitet.
Die Bedeutung menschlicher Expertise
Ein zentraler Punkt meines Vortrags war die anhaltende Notwendigkeit menschlicher Expertise bei der Arbeit mit KI. Ich betonte, dass KI derzeit am besten als Unterstützung für menschliche Experten funktioniert, nicht als deren Ersatz. KI kann beeindruckende Ergebnisse liefern, aber es braucht immer noch Menschen mit Fachwissen, um diese Ergebnisse zu interpretieren, zu validieren und in den richtigen Kontext zu setzen.
Ich warnte auch vor den Gefahren des blinden Vertrauens in KI-generierte Inhalte. Es ist wichtig, sich bewusst zu sein, dass KI-Modelle Voreingenommenheiten aus ihren Trainingsdaten übernehmen können und dass sie keine echte Unterscheidung zwischen Wahrheit und Fiktion treffen können.
Verantwortungsvoller Umgang mit KI
Zum Abschluss meines Vortrags betonte ich die Wichtigkeit eines verantwortungsvollen Umgangs mit KI. Ich ermutigte das Publikum, KI als leistungsfähiges Werkzeug zu betrachten, aber auch ihre Grenzen zu respektieren. Es ist entscheidend, dass wir kritisch hinterfragen, wo und wie wir KI einsetzen, und dass wir uns der ethischen Implikationen bewusst sind.
Ich schloss mit dem Rat, dass Unternehmen, die KI einsetzen wollen, sorgfältig planen, testen und überwachen sollten. KI kann enorme Vorteile bringen, aber nur wenn sie mit Bedacht und Expertise eingesetzt wird.
Für alle, die tiefer in das Thema KI eintauchen möchten: Ich lade euch herzlich ein, meinen Newsletter zu abonnieren. Dort teile ich regelmäßig die neuesten Entwicklungen und Erkenntnisse aus der Welt der KI.
In der heutigen digitalen Welt, in der Inhalte eine entscheidende Rolle für den Erfolg eines Unternehmens spielen, suchen Marketingstrategen ständig nach Wegen, um ihre Content-Strategien zu verbessern. Insbesondere mit Blick auf KI-basierte Suchmaschinen wie Perplexity und KI-Zusammenfassungen bei traditionellen Suchmaschinen wie Google, bing und Co. stellen sich viele Content-Marketer und SEOs zu Recht die Frage, welche Inhalte überhaupt noch dafür sorgen, dass man die hart erarbeitete Sichtbarkeit halten oder im besten Falle sogar noch zulegen kann.
Auf die Einführung von KI-generierten Zusammenfassungen auf der Suchergebnisseite mit KI-generierten Inhalten zu reagieren, die im schlimmsten Falle auf ein paar simplen Prompts basieren, kann jedenfalls nicht die Antwort sein. Selbst „ausgetüftelte“ AI-Writer, die Informationen aus den rankenden Dokumenten der Konkurrenz einbeziehen, liefern bestenfalls etwas, das in den Top 10 „mithalten“ kann.
Diese Strategie führt langfristig zu einer Gleichförmigkeit der Ergebnisse, was aus Sicht der Suchmaschine wenig wünschenswert ist. Diese reagieren daher, durch Features wie „Perspectives“ oder Core Updates mit immer mehr Diversität innerhalb der vordersten Treffer.
Ein Konzept, das in diesem Zusammenhang zunehmend an Bedeutung gewinnt, ist der sogenannte „Information Gain“, auf den ich daher in diesem Artikel einmal näher eingehen möchte.
Einführung in Information Gain
Der Information Gain bezeichnet den zusätzlichen Nutzen oder Mehrwert, den ein Inhalt bietet, indem er neue Daten, Einsichten oder Perspektiven zu einem bestehenden Thema hinzufügt. Man kann es auch als diejenigen Inhalte verstehen, die nicht nur bestehende Informationen wiederholen, sondern dem Nutzer etwas wirklich Neues und Wertvolles bieten.
Der Fokus auf diesen Informationsvorsprung hilft nicht nur dabei, die Relevanz eines Inhalts für Suchmaschinen zu erhöhen, sondern trägt auch dazu bei, dass der Content für die Zielgruppe interessanter und nützlicher wird!
Warum Information Gain wichtig ist
Im digitalen Raum, wo Unternehmen ständig um die Aufmerksamkeit der Nutzer kämpfen, kann Information Gain ein entscheidender Faktor sein, um sich von der Konkurrenz abzuheben. Viele Webseiten bieten ähnliche Inhalte an, die oft generisch und wenig innovativ sind.
Dies führt zu einer hohen „Serp-Ähnlichkeit“, bei der viele Suchergebnisse im Grunde die gleichen Informationen liefern. Nur Inhalte mit hohem Informationsgewinn sind in der Lage diese Serp-Ähnlichkeit zu durchbrechen und sich so eine bessere Position in den Suchergebnissen sichern können.
Ein weiterer wichtiger Punkt ist die sogenannte „Topical Authority“ – die Autorität einer Webseite in Bezug auf ein bestimmtes Thema. Indem Unternehmen Inhalte schaffen, die durch Information Gain angereichert sind, können sie sich als führende Experten in ihrer Nische etablieren. Dies stärkt nicht nur die Sichtbarkeit in den Suchmaschinen, sondern auch das Vertrauen und die Bindung der Zielgruppe.
Integration von Information Gain in die Content-Erstellung
Amanda Johnson, Senior Marketing Managerin bei Clearscope, hat in ihrem Vortrag ausführlich erklärt, warum es so wichtig ist, Information Gain in den Content-Entwicklungsprozess zu integrieren und wie dies auf großem Maßstab umgesetzt werden kann.
Amanda führt darin das Konzept mit einem spannenden Beispiel ein, ihrer persönlichen Suche nach Informationen über eine Pflanze namens „Creeping Phlox“. Sie erläutert, wie Google ihre Suchanfragen zunächst mit allgemeinen Informationen beantwortete, später jedoch Inhalte vorschlug, die spezifisch auf ihre Suchhistorie und Interessen abgestimmt waren. Dies veranschaulicht, wie Google Inhalte priorisiert, die einen hohen Informationsgehalt bieten und auf den spezifischen Bedarf des Nutzers abgestimmt sind.
Die Integration von Information Gain in den Content-Erstellungsprozess erfordert eine strategische Herangehensweise und die Bereitschaft, bestehende Inhalte kritisch zu überprüfen und zu optimieren. Amanda schlägt vor, mit einem Audit der vorhandenen Inhalte zu beginnen, um Bereiche zu identifizieren, die aktualisiert oder erweitert werden könnten. Hierbei sollte der Fokus darauf liegen, neue Informationen, Daten oder Perspektiven einzufügen, die den bestehenden Inhalt bereichern und für den Leser wertvoller machen.
Ein praktisches Beispiel aus Amandas Arbeit zeigt, wie ein Artikel über ein saisonales Thema – der anfänglich kaum Suchvolumen hatte – durch die Integration von Information Gain zu einem der erfolgreichsten Inhalte einer Webseite wurde. Dieser Artikel, der zunächst nur als Ressource für das Vertriebsteam gedacht war, entwickelte sich durch gezielte Optimierungen zu einem Top-Performer mit tausenden von organischen Klicks pro Monat. Dies verdeutlicht, wie wichtig es ist, Inhalte zu schaffen, die auf den spezifischen Informationsbedarf der Zielgruppe eingehen, auch wenn diese Themen zunächst wenig Suchvolumen aufweisen.
Praktische Tipps zur Umsetzung
Amanda gibt zahlreiche praktische Tipps, wie Unternehmen Information Gain effektiv in ihre Inhalte integrieren können:
Entwickeln Sie entitätsreiche Inhalte: Diese sollten nicht nur die Suchintention genau treffen, sondern auch neue Daten und Perspektiven bieten, die für die Zielgruppe relevant sind. KI-basierte SEO- und Content-Tools können dabei helfen, die richtigen Entitäten und Themen zu identifizieren, die in einem Inhalt abgedeckt werden sollten.
Erfahrungen und Expertise demonstrieren: Inhalte sollten echte Geschichten, frische Perspektiven und aktuelle Daten beinhalten, um ihre Glaubwürdigkeit und Relevanz zu erhöhen. Dies kann durch die Einbindung von Fallstudien, Experteninterviews und originalen Forschungsergebnissen erreicht werden.
Autorität aufbauen durch neue Themen: Selbst Inhalte zu sogenannten „Zero-Volume-Keywords“ – also Suchanfragen mit geringem oder keinem Suchvolumen – können dazu beitragen, Autorität in einem bestimmten Themenbereich aufzubauen. Diese Themen sind oft Vorreiter für aufkommende Trends und können langfristig eine hohe Sichtbarkeit erzielen.
Organisieren Sie Ihre Daten: Beginnen Sie mit der Erstellung eines „Information Gain Swipe Files“, in dem alle relevanten Informationen gesammelt und strukturiert aufbewahrt werden. Dies erleichtert die spätere Integration in neue oder bestehende Inhalte und stellt sicher, dass die Informationen konsistent und effektiv genutzt werden.
Langfristige Implementierung und Erfolgskontrolle
Die erfolgreiche Integration von Information Gain erfordert nicht nur initiale Anstrengungen, sondern auch eine kontinuierliche Überwachung und Anpassung. Amanda rät dazu, regelmäßige Überprüfungen der Inhalte durchzuführen, um deren Leistung zu messen und gegebenenfalls weitere Optimierungen vorzunehmen. Dies kann durch die Analyse von Metriken wie organischem Traffic, Rankings und Engagement-Raten erfolgen.
Ein strukturierter Ansatz, bei dem Informationen systematisch gesammelt und regelmäßig in die Content-Strategie integriert werden, ist entscheidend für den langfristigen Erfolg. Durch die kontinuierliche Optimierung und das Einfügen neuer Informationen können Unternehmen sicherstellen, dass ihre Inhalte immer relevant, aktuell und wertvoll für die Zielgruppe bleiben.
Fazit: Fokussierung auf den Information Gain lohnt sich!
Die Integration von Information Gain in die Content-Strategie ist kein einfacher Prozess, aber einer, der sich langfristig auszahlt. In einer Welt, in der Inhalte zunehmend von Künstlicher Intelligenz generiert werden können, ist es wichtiger denn je, Inhalte zu schaffen, die durch Originalität und Mehrwert hervorstechen. Der Fokus auf den Information Gain ist nicht nur ein kurzfristiger SEO-Trick, sondern ein grundlegendes Prinzip für die Schaffung von Inhalten, die sowohl für Suchmaschinen als auch für Leser von Bedeutung sind.
Durch die Fokussierung auf relevante, frische und wertvolle Informationen können Unternehmen nicht nur ihre Sichtbarkeit in den Suchergebnissen erhöhen, sondern auch eine starke und nachhaltige Beziehung zu ihrer Zielgruppe aufbauen. Dies ist letztlich der Schlüssel, um in der heutigen digitalen Landschaft erfolgreich zu sein.
Als ich kürzlich von Astrid Kramer zum Digital Strategy Talk Podcast eingeladen wurde, bot sich mir die Gelegenheit, über ein Thema zu sprechen, das mich seit Jahren fasziniert: Künstliche Intelligenz und ihre Auswirkungen auf die digitale Landschaft.
Mein Weg von SEO zur KI
In den letzten Jahren hat sich die künstliche Intelligenz rasant weiterentwickelt und dabei viele Bereiche unseres Lebens und Arbeitens verändert. Meine eigene Reise in die Welt der KI begann früh durch meine Leidenschaft für Science-Fiction, insbesondere in den Bereichen Zeitreisen und künstliche Intelligenz. Für mich war KI lange Zeit eher ein Konzept aus Filmen wie „Terminator“, „Matrix“ oder „Ex Machina“ – faszinierend, aber weit entfernt von der Realität. Das änderte sich schlagartig, als ChatGPT veröffentlicht wurde und erstmals das Gefühl aufkam, tatsächlich mit einer „echten“ KI zu interagieren.
Bevor ich mich intensiv mit KI beschäftigte, war ich als Experte für Suchmaschinenoptimierung (SEO) tätig. Seit fast 20 Jahren arbeite ich in diesem Bereich und habe miterlebt, wie Google sich durch technologische Innovationen ständig weiterentwickelte. Ein entscheidender Wendepunkt war die Einführung von RankBrain im Jahr 2015 und insbesondere die Einführung von BERT (Bidirectional Encoder Representations from Transformers), die die Verarbeitung natürlicher Sprache (NLP) revolutionierte. Vor BERT gab es spezialisierte Modelle für jede einzelne Aufgabe im NLP, doch BERT ermöglichte es, nahezu jede NLP-Anwendung mit einem einzigen Modell auf höchstem Niveau durchzuführen. OpenAI setzte auf diese Technologie auf und entwickelte GPT-3, das durch größere Datenmengen und mehr Rechenleistung beeindruckende Ergebnisse erzielte.
Bereits 2020 erhielt ich frühen Zugang zur API von GPT-3. Als jemand, der aus dem SEO-Bereich kommt, war ich sofort fasziniert von den Möglichkeiten, die dieses Modell bot. Die Fähigkeit von GPT-3, Texte zu vervollständigen und zu generieren, ging weit über das hinaus, was ich bis dahin gesehen hatte. Während frühere textgenerierende Tools oft mühsam und wenig überzeugend waren, bot GPT-3 eine Textkomplettierung, die eine völlig neue Ebene der Textgenerierung darstellte. Der Fortschritt war so schnell, dass ich alle kommerziellen Tools, die auf GPT-3 basierten, wie Frase oder Jasper, intensiv testete, um ihre Möglichkeiten und Grenzen auszuloten.
Die Herausforderungen bei der Implementierung von KI
Als ich begann, Unternehmen bei der Implementierung von KI zu unterstützen, wurde mir schnell klar, dass es viele Missverständnisse über die Fähigkeiten und Grenzen von KI gibt. Oft übersehen Entscheidungsträger_innen, insbesondere im C-Level-Bereich, die tatsächlichen technischen Grundlagen der KI. Sie hören von den Möglichkeiten, die KI bietet, haben aber oft keine praktischen Erfahrungen und setzen deshalb unrealistische Erwartungen an die Technologie. Ein häufiges Missverständnis ist, dass KI alle Mitarbeiter_innen ersetzen könnte oder dass sie für nahezu jede Aufgabe die perfekte Lösung sei.
Um diese Missverständnisse zu klären, lege ich in meinen Workshops großen Wert darauf, den Teilnehmer_innen ein grundlegendes Verständnis der Technologie zu vermitteln. Es ist wichtig zu begreifen, dass alles, was von ChatGPT generiert wird, streng genommen Halluzinationen sind. Einige dieser Halluzinationen ergeben für uns Menschen Sinn, andere nicht. GPT-Modelle „wissen“ nichts im herkömmlichen Sinne. Sie haben kein tiefes Verständnis der Welt; sie sind vielmehr Wahrscheinlichkeitsrechner, die auf Basis der Trainingsdaten das nächste Wort vorhersagen.
Um dieses Verständnis zu vertiefen, lasse ich die Teilnehmer_innen in meinen Workshops praktische Erfahrungen sammeln. Ich stelle einfache Aufgaben, die die Grenzen der Technologie aufzeigen. Diese „Aha“-Momente sind entscheidend, um zu verstehen, warum KI manchmal nicht das gewünschte Ergebnis liefert. Beispielsweise lasse ich die Teilnehmer_innen ChatGPT Aufgaben stellen, wie die Generierung von Wörtern mit einer bestimmten Anzahl von Zeichen, was oft zu Fehlern führt. Diese praktischen Übungen ermöglichen es, die technischen Details wie Tokens und deren Verarbeitung besser zu verstehen.
Nachdem die Grundlagen gelegt sind, zeige ich Beispiele für erfolgreiche KI-Implementierungen und diskutiere mit den Teilnehmer_innen mögliche Anwendungsfälle in ihrem Unternehmen. Ein wichtiger Teil dieser Workshops ist es, die Limitationen der KI zu erkennen und zu lernen, wie man diese umgehen kann. Hierbei spielt beispielsweise die Technik der „Retrieval-Augmented Generation“ (RAG) eine wichtige Rolle, bei der ein Modell auf traditionelle Suchmaschinen zugreift, um relevante Dokumente zu finden und darauf basierend Antworten zu generieren.
In meiner Arbeit mit Unternehmen habe ich insbesondere diese Erkenntnisse gewonnen:
Bildung ist entscheidend: Das Verständnis der Technologie ist der erste Schritt zu einer erfolgreichen KI-Implementierung. In meinen Workshops lege ich großen Wert auf praktische Erfahrungen und erkläre die zugrunde liegende Technologie.
Häufige Missverständnisse: Oft gibt es eine Kluft zwischen den Erwartungen auf C-Level und den tatsächlichen Fähigkeiten der KI. Während einige die Fähigkeiten der KI überschätzen, unterschätzen andere ihr Potenzial aufgrund begrenzter Experimente.
Praktische Anwendungen: KI kann die Effizienz in verschiedenen Geschäftsprozessen erheblich steigern, von der Inhaltserstellung bis zur Datenanalyse.
Ethische Überlegungen: Voreingenommenheit in KI-Modellen ist ein erhebliches Problem. Ich betone immer wieder, wie wichtig es ist, diese Voreingenommenheit und die Grenzen der KI zu verstehen, um sie verantwortungsvoll einzusetzen.
Die Zukunft der KI: Wo stehen wir in fünf Jahren?
Ein Blick in die Zukunft der KI zeigt, dass wir auf eine weitgehende Kommoditisierung zusteuern. KI wird in allen Produkten, Softwarelösungen und Systemen integriert sein, ähnlich wie heute ein Taschenrechner. Schon jetzt sehen wir, dass KI in Tools wie Zoom integriert wird, um beispielsweise Übersetzungen, Transkriptionen oder Zusammenfassungen zu automatisieren. Diese grundlegenden Technologien wie Text-zu-Sprache, Sprache-zu-Text und Zusammenfassungen, die heute bereits funktionieren, werden in naher Zukunft völlig normal sein – vergleichbar mit der alltäglichen Nutzung eines Taschenrechners in der Schule.
Ein besonders spannender Bereich ist die Robotik, die durch KI stark vorangetrieben wird. Kürzlich wurde beispielsweise ein humanoider Roboter angekündigt, der für etwa 16.000 US-Dollar erhältlich sein soll und Aufgaben im Haushalt übernehmen kann. Diese Roboter basieren auf ähnlichen unüberwachten Lernansätzen wie die großen Sprachmodelle und lernen durch Beobachtung, wie Menschen Aufgaben ausführen. Die Geschwindigkeit, mit der sich diese Technologie entwickelt, ist atemberaubend.
Auch in meiner eigenen Arbeit habe ich die rasanten Fortschritte der KI-Technologie hautnah erlebt. Allein in den letzten 14 Monaten habe ich meine Arbeitsmethoden in meiner AI-Masterclass viermal umgestellt, um den neuen Entwicklungen Rechnung zu tragen. Von GPT-3 über GPT-4 hin zu den neuesten Sprachmodellen – die Entwicklungen sind so schnell, dass man ständig am Ball bleiben muss.
In den nächsten fünf Jahren werden wir vermutlich keine künstliche Superintelligenz (AGI) erleben, aber wir werden deutlich effizientere und kleinere Modelle sehen, die auf Geräten direkt laufen und damit auch datenschutzfreundlicher sind. Ein weiterer wichtiger Aspekt wird die Energieeffizienz sein. Die derzeitigen Modelle verbrauchen enorme Mengen an Rechenleistung und Energie, was erhebliche Auswirkungen auf den CO2-Fußabdruck hat. Microsoft und Google haben bereits erklärt, dass sie ihre CO2-Ziele aufgrund des hohen Energieverbrauchs durch KI nicht erreichen werden. Daher wird es in Zukunft entscheidend sein, kleinere, effizientere Modelle zu entwickeln, die weniger Energie verbrauchen.
Für Unternehmen wird es immer wichtiger, die Technologie zu verstehen, um die damit verbundenen Risiken managen zu können. KI birgt nicht nur Chancen, sondern auch Herausforderungen wie Verzerrungen und unvorhergesehene Ergebnisse, die es zu kontrollieren gilt. Wenn Unternehmen beispielsweise Prozessautomatisierungen ohne menschliche Überwachung einsetzen, besteht die Gefahr, dass Fehler unbemerkt bleiben und Schaden anrichten. Deshalb ist es entscheidend, die Technologie zu verstehen und verantwortungsvoll einzusetzen.
Die Zukunft der Suchmaschinen im Zeitalter der KI
Ein weiteres spannendes Feld ist die Zukunft der Suchmaschinen im Zeitalter der KI. Die Einführung von SearchGPT hat gezeigt, dass wir uns auf eine echte semantische Suche zubewegen. Statt lediglich die relevantesten Dokumente zu einem Suchbegriff zu liefern, analysiert die KI die tatsächliche Intention hinter einer Suchanfrage und liefert Antworten, die auf den besten verfügbaren Informationen basieren. Dabei stützt sich die KI auf echte Dokumente und nicht nur auf Wahrscheinlichkeitsverteilungen.
Meine ersten Tests mit SearchGPT waren überraschend positiv. Besonders beeindruckend war, wie gut die KI Quellen auswählte, die qualitativ hochwertige und vertrauenswürdige Informationen lieferten. Bei Anfragen zu Gesundheitsthemen stützte sich Search GPT auf Informationen von renommierten Institutionen wie Regierungsorganisationen und großen Gesundheitsportalen. Doch auch kleinere Blogs und weniger optimierte Webseiten wurden herangezogen, wenn sie relevante und nützliche Inhalte boten. Dies zeigt, dass die KI nicht nur auf SEO-optimierte Seiten setzt, sondern tatsächlich nach den besten Inhalten sucht.
Die Zukunft der Suche und SEO
Für die Zukunft von SEO bedeutet dies, dass es wichtiger denn je sein wird, Inhalte zu erstellen, die wirklich die Fragen der Nutzer_innen beantworten. Die besten Dokumente sind diejenigen, die Antworten liefern – und genau diese wird eine semantische Suchmaschine bevorzugen. SEO wird sich also zunehmend darauf konzentrieren müssen, Inhalte zu erstellen, die auf die tatsächlichen Bedürfnisse und Fragen der Nutzer_innen eingehen.
Als ehemaliger SEO-Experte sehe ich, wie KI die Suchlandschaft neu gestaltet:
Search GPT: Meine Erfahrungen mit Search GPT sind beeindruckend. Die Geschwindigkeit und Fähigkeit, relevante Quellen auszuwählen, oft mit Bevorzugung autoritativer Seiten für sensible Themen, ist bemerkenswert.
Semantische Suche: KI-gestützte Suchmaschinen bewegen sich in Richtung einer echten semantischen Suche, die die Benutzerabsicht über das reine Keyword-Matching hinaus versteht.
Auswirkungen auf SEO: Traditionelle SEO-Taktiken könnten weniger effektiv werden, da KI-gestützte Suchen mehr Wert auf Inhaltsrelevanz und Autorität legen.
Googles Position: Trotz anfänglicher Bedenken hinsichtlich des Einflusses von ChatGPT auf Google bin ich der Meinung, dass Google mit Gemini und anderen KI-Integrationen gut für die Zukunft gerüstet ist.
Praktische KI-Tools für Einzelpersonen und Unternehmen
Basierend auf meinen Erfahrungen empfehle ich folgende KI-Tools:
ChatGPT und Claude: Für Textgenerierung und -analyse, wobei Claude einen eher journalistischen Schreibstil bietet.
MidJourney: Meiner Meinung nach immer noch das Beste für allgemeine Bildgenerierung.
FIux: Eine Open-Source-Alternative für Bildgenerierung, mit unterschiedlichen Ebenen des kostenlosen Zugangs.
KI-Ethik und gesellschaftliche Auswirkungen
Ein Thema, das mir besonders am Herzen liegt, sind die ethischen Überlegungen rund um KI:
Voreingenommenheit in KI-Modellen: Historische Daten können zu verzerrten KI-Modellen führen. Ein Beispiel dafür ist Amazons KI-Rekrutierungstool, das unbeabsichtigt Frauen benachteiligte.
EU-KI-Gesetz: Die Bedeutung von Regulierung bei KI-Anwendungen mit hohem Risiko, wie z.B. in HR-Prozessen, kann nicht genug betont werden.
Datenschutzbedenken: Das Potenzial zur De-Anonymisierung von Daten mittels KI-Techniken ist ein wichtiges Thema, das wir im Auge behalten müssen.
Balance zwischen Autorität und Vielfalt: Es ist eine Herausforderung, autoritative Informationen bereitzustellen und gleichzeitig vielfältige Perspektiven in Suchergebnissen zu berücksichtigen.
Die Bedeutung des Verständnisses von KI
Die rasante Entwicklung der KI bietet enorme Chancen, stellt uns aber auch vor große Herausforderungen. Es ist unerlässlich, neugierig zu bleiben und die zugrunde liegende Technologie zu verstehen. Nur so kann man KI verantwortungsvoll und effektiv einsetzen. KI ist kein Allheilmittel, sondern ein Werkzeug, das in bestimmten Bereichen außergewöhnlich gut funktioniert, in anderen jedoch an seine Grenzen stößt. Der Schlüssel liegt darin, die Technologie zu verstehen, ihre Stärken zu nutzen und ihre Schwächen zu erkennen. Nur wer die Technologie wirklich begreift, kann ihre Potenziale voll ausschöpfen und gleichzeitig die Risiken minimieren.
Abschließend möchte ich betonen: Bleiben Sie neugierig und bemühen Sie sich, KI-Technologie zu verstehen. Nur wenn wir verstehen, wie KI funktioniert, können wir sie sicher, verantwortungsvoll und optimal einsetzen. In einer Zeit, in der KI zunehmend in unser tägliches Leben und in Geschäftsabläufe integriert wird, ist dieses Verständnis der Schlüssel zur Navigation durch die sich ständig weiterentwickelnde technologische Landschaft.
Die rasante Entwicklung im Bereich der künstlichen Intelligenz fasziniert mich jeden Tag aufs Neue. Ich bin gespannt, welche Innovationen und Herausforderungen die Zukunft für uns bereithält, und freue mich darauf, weiterhin an der Spitze dieser spannenden Entwicklung zu stehen.
In der heutigen Welt, in der KI-Systeme und Sprachmodelle wie GPT eine immer größere Rolle spielen, wird es zunehmend wichtiger, präzise und durchdachte Eingaben (Prompts) zu formulieren. Genau hier setzt mein Cheatsheet an: Es bietet dir einen kompakten Überblick über die besten Techniken, Strategien und Frameworks, um das volle Potenzial dieser KI-Modelle auszuschöpfen.
Was beinhaltet mein Cheatsheet?
Mein Cheatsheet deckt eine breite Palette von Themen und Techniken ab, darunter:
Frameworks für strukturiertes Prompting
RTF (Role, Task, Format)
RODES (Role, Objective, Details, Example, Sense Check)
Kombination verschiedener Techniken für beste Ergebnisse
Formatierungsanweisungen für klare Ausgaben
Wichtige Überlegungen bei der Arbeit mit KI-Modellen
Beispiele für KI-Rollen wie Journalist:in, Interviewer:in, Englisch-Lehrer:in, Werbetexter:in, SEO-Expert:in und mehr.
Mögliche Ausgabeformate wie Artikel, Gliederungen, Aufzählungen, Tabellen, Code, Podcast-Skripte und mehr.
Für wen ist das Cheatsheet geeignet?
Egal, ob du gerade erst in die Welt des Prompt Engineerings eintauchst oder schon erfahren bist – mein Cheatsheet bietet dir wertvolle Einblicke und sofort anwendbare Techniken. Es ist ideal für Content Creator, Programmierer:innen, Marketer:innen und alle, die ihre Arbeit durch den gezielten Einsatz von KI verbessern möchten.
Warum dieses Cheatsheet wichtig ist
Da sich KI-Sprachmodelle ständig weiterentwickeln und verbessern, ist es entscheidend, mit den neuesten Prompt-Engineering-Techniken Schritt zu halten. Mein Cheatsheet bietet dir einen prägnanten, aber umfassenden Überblick über die effektivsten Strategien und hilft dir dabei:
Die Qualität und Relevanz KI-generierter Inhalte zu verbessern
Deinen Workflow bei der Arbeit mit KI-Tools zu optimieren
Die Grenzen und potenziellen Risiken von KI-Sprachmodellen zu verstehen
Neue und kreative Wege zu erkunden, um KI in deinen Projekten einzusetzen
Ich habe das Cheatsheet so gestaltet, dass du es als schnelle Referenz bei deiner Arbeit nutzen kannst. Komplexe Techniken werden auf das Wesentliche reduziert und in einem klaren und übersichtlichen Format präsentiert. Außerdem findest du Tipps, die dir helfen, typische Fehler zu vermeiden und bessere Ergebnisse zu erzielen.
Hol dir dein Exemplar noch heute!
Das Cheatsheet steht dir ab sofort kostenlos zur Verfügung. Du kannst es einfach herunterladen und sofort mit dem Optimieren deiner Prompts loslegen. Ich hoffe, dass es dir genauso viel Spaß macht, damit zu arbeiten, wie mir beim Erstellen!
Falls du noch Fragen hast oder Feedback geben möchtest, hinterlasse gerne einen Kommentar oder schreib mir direkt. Ich würde gerne hören, wie es dir bei deinen KI-Projekten hilft!
In seinem aktuellen Newsletter analysiert Sayash Kapoor, Doktorand in Informatik am Center for Information Technology Policy der Princeton University, die aktuellen Entwicklungen und Herausforderungen im Bereich generativer KI. Kapoor, dessen Forschung den gesellschaftlichen Einfluss von KI untersucht, bringt umfangreiche Erfahrungen aus der Industrie und der Wissenschaft mit, unter anderem durch seine Tätigkeiten bei Facebook, der Columbia University und der EPFL in der Schweiz. Er wurde mehrfach ausgezeichnet, unter anderem mit dem Best Paper Award bei ACM FAccT und einem Impact Recognition Award bei ACM CSCW, und zählt laut TIME zu den 100 einflussreichsten Personen im Bereich KI. In diesem Beitrag beschreibt Kapoor die strategischen Fehler führender KI-Unternehmen und erläutert die fünf großen Hürden, die noch überwunden werden müssen, um generative KI zu kommerziell erfolgreichen Produkten weiterzuentwickeln.
Fehlender Product-Market-Fit
Zu Beginn des Hypes um ChatGPT entdeckten Nutzer:innen zahlreiche unerwartete Anwendungen für KI-Modelle. Das führte zu einer Überbewertung der Technologie und dem Irrglauben, dass die Vielseitigkeit dieser Modelle eine umfassende Produktentwicklung ersetzen könnte. Unternehmen wie OpenAI und Anthropic setzten daher zunächst auf die Entwicklung immer leistungsfähigerer Modelle, ohne sich um die Umsetzung in benutzerfreundliche Produkte zu kümmern.
Das Ergebnis: Trotz milliardenschwerer Investitionen dauerte es Monate, bis einfache Anwendungen wie ChatGPT-Apps für iOS und Android verfügbar waren. Gleichzeitig integrierten Google und Microsoft KI nahezu hektisch in eine Vielzahl von Produkten, oft ohne Rücksicht darauf, ob diese Integration wirklich sinnvoll war. Die Folge waren halbherzig umgesetzte Funktionen, die oft mehr störten als nutzten.
Ein Beispiel hierfür ist Microsofts „Sydney“-Chatbot, der aufgrund unzureichender Tests negative Schlagzeilen machte. Auch Googles Bildgenerator „Gemini“ verursachte durch fehlerhafte Ergebnisse Frustration bei den Nutzer:innen. Diese Fehltritte trugen dazu bei, dass sich das öffentliche Bild von generativer KI verschlechterte.
Inzwischen beginnen die Unternehmen, ihre Ansätze zu überdenken. OpenAI wandelt sich von einem forschungsorientierten Labor hin zu einem Produktunternehmen, während Anthropic weiterhin stark auf die Erforschung allgemeiner künstlicher Intelligenz (AGI) fokussiert bleibt, aber ebenfalls den Druck spürt, marktfähige Produkte zu entwickeln.
Google und Microsoft scheinen noch langsamer zu reagieren, könnten jedoch durch den technologisch vorsichtigeren Ansatz von Apple gezwungen werden, ihre Strategie zu überarbeiten. Apple, das zunächst als „AI-Nachzügler“ galt, verfolgt einen bedächtigeren Ansatz, wie auf der Entwicklerkonferenz WWDC gezeigt wurde. Dies könnte langfristig besser bei den Nutzer:innen ankommen.
Die fünf großen Herausforderungen für KI-basierte Produkte
Kapoor und Narayanan nennen fünf zentrale Hürden, die Entwickler:innen überwinden müssen, um generative KI in erfolgreiche Konsumprodukte zu verwandeln:
Kosten: Obwohl die Kosten für die Nutzung von KI-Modellen in den letzten 18 Monaten drastisch gesunken sind – um den Faktor 100 – bleibt dies ein entscheidender Faktor. In Anwendungen wie Chatbots bestimmen die Kosten, wie viel Konversation ein Modell sinnvoll verarbeiten kann. Günstigere Modelle ermöglichen es, Aufgaben häufiger zu wiederholen und so durch Versuch und Irrtum die Erfolgsrate zu steigern. Obwohl einige Unternehmen behaupten, dass KI bald „zu günstig zum Messen“ sein wird, bleiben Zweifel bestehen, insbesondere da genauere Modelle oft teurer sind.
Zuverlässigkeit: Ein häufig unterschätztes Problem ist die mangelnde Zuverlässigkeit generativer KI. Systeme, die nur 90 % der Aufgaben korrekt erledigen, gelten zwar als fähig, erfüllen aber nicht die Erwartungen der Nutzer:innen an verlässliche Software. Das ist besonders kritisch in sensiblen Anwendungen wie Reisebuchungen oder anderen Bereichen, in denen Fehler gravierende Folgen haben können. Aktuell bleibt unklar, ob es möglich ist, deterministische Systeme aus den grundlegend stochastischen LLMs zu entwickeln.
Datenschutz: Obwohl LLMs überwiegend mit öffentlichen Daten trainiert wurden, gewinnen Datenschutzbedenken wieder an Bedeutung, insbesondere bei KI-Assistenten, die auf persönliche Daten zugreifen müssen. Ein Beispiel ist Microsofts geplanter „CoPilot“, der durch regelmäßige Screenshots die Aktivitäten der Nutzer:innen verfolgen sollte, um bessere Kontexte zu schaffen. Diese Idee stieß auf heftige Kritik, und Microsoft musste zurückrudern. Unternehmen müssen hier den Spagat zwischen nützlichen Funktionen und der Wahrung der Privatsphäre meistern.
Sicherheit: Kapoor betont, dass unabsichtliche Fehler wie Verzerrungen in Bildgeneratoren oder Missbrauch von KI für Deepfakes und Stimmklonungen ernsthafte Probleme darstellen. Besonders alarmierend ist jedoch das Risiko von Hacks. Angriffe wie „Prompt Injection“ könnten dazu führen, dass KI-Systeme manipuliert und für schädliche Zwecke missbraucht werden. Während Unternehmen hier bisher größtenteils improvisierte Abwehrmaßnahmen ergriffen haben, bleibt die Gefahr schwerwiegenderer Angriffe bestehen.
Benutzeroberfläche: Eine der größten Herausforderungen bei der Entwicklung benutzerfreundlicher KI-Produkte liegt in der Gestaltung der Schnittstellen. Bei vielen Anwendungen müssen Nutzer:innen die Möglichkeit haben, einzugreifen, wenn die KI Fehler macht. Das ist bei Textschnittstellen noch vergleichsweise einfach, wird aber in komplexeren Szenarien, wie Sprachassistenten, deutlich schwieriger. Die Vision einer unsichtbaren, ständig präsenten KI – zum Beispiel in einer Brille, die automatisch hilft, ohne aktiv gefragt zu werden – bleibt zwar faszinierend, aber die Grenzen aktueller Benutzeroberflächen machen sie noch schwer erreichbar.
Fazit
Kapoor und Narayanan stellen klar, dass die vielbeschworenen Revolutionen durch generative KI wohl langsamer kommen werden als von vielen erhofft. Selbst wenn die technischen Fähigkeiten weiter rasch zunehmen, bleiben die beschriebenen Herausforderungen, die nicht nur technischer, sondern auch gesellschaftlicher Natur sind. Der Weg zu breiter Akzeptanz und wirklicher Nützlichkeit von KI wird daher eher ein langfristiger sein. Entwickler:innen müssen lernen, KI so in bestehende Produkte und Arbeitsabläufe zu integrieren, dass sie wirklich wertschöpfend ist, ohne gleichzeitig die beschriebenen Risiken zu ignorieren.
Buchempfehlung
Gemeinsam mit Arvind Narayanan arbeitet Kapoor an dem Buch AI Snake Oil, das kritisch beleuchtet, was KI wirklich leisten kann – und was nicht. Viele ihrer Ideen teilen die beiden bereits über Substack mit einem breiteren Publikum.
In dieser Woche hat ein Projekt namens „The AI Scientist“ in der internationalen Forschungsgemeinschaft für Aufsehen gesorgt. Entwickelt von Sakana AI in Zusammenarbeit mit Forschern der Universität Oxford und der University of British Columbia, verspricht dieses System nichts Geringeres als die weitgehende Automatisierung des gesamten wissenschaftlichen Forschungsprozesses. Der AI Scientist, der am 13. August 2024 vorgestellt wurde, ist das Ergebnis jahrelanger Forschung und baut auf früheren Erfolgen von Sakana AI auf, wie der automatischen Verschmelzung des Wissens mehrerer großer Sprachmodelle (LLMs) und der Entdeckung neuer Zielfunktionen für das Finetuning von LLMs.
Das System ist tatsächlich ziemlich bemerkenswert in seiner Fähigkeit, den gesamten Forschungszyklus zu automatisieren. Es beginnt mit der Ideengenerierung, bei der der AI Scientist eigenständig neue Forschungsrichtungen vorschlägt und deren Neuartigkeit bewertet.
Anschließend führt er experimentelle Iterationen durch, wobei er sogar eigenständig Experimente plant, durchführt und die Ergebnisse analysiert. Das geht natürlich nur für Experimente, die auch innerhalb eines Computers mittels Programmcode durchgeführt werden können, beispielsweise im Bereich Data Science oder Machine Learning.
Ein besonders beeindruckendes Feature ist die Fähigkeit des Systems, vollständige wissenschaftliche Manuskripte zu verfassen, einschließlich der Erstellung von Visualisierungen und der Einbindung relevanter Zitate!
Darüber hinaus verfügt der AI Scientist über einen automatisierten Peer-Review-Prozess mittels eigener KI-Agenten. Diese bewerten die generierten Arbeiten, geben Feedback und helfen so bei der kontinuierlichen Verbesserung der Forschungsansätze.
In ersten Tests hat das System bereits beeindruckende Ergebnisse geliefert, indem es neue Beiträge in komplexen Bereichen wie Diffusionsmodellen, Transformerarchitekturen und dem Phänomen des „Grokkings“ generierte.
Interessant sind auch die Angaben zu den Kosten des Systems: Laut den Entwicklern kann jede Idee für etwa 15 Dollar in ein vollständiges wissenschaftliches Paper umgesetzt werden. Dies eröffnet potenziell neue Möglichkeiten für die Demokratisierung der Forschung und könnte den wissenschaftlichen Fortschritt erheblich beschleunigen.
Wieso nicht gleich ein „AI Journalist“?
Doch die Implikationen dieses ehrgeizigen Projekts reichen weit über die Grenzen der Wissenschaft hinaus und werfen wichtige Fragen zur Zukunft anderer wissensbasierter Bereiche auf, insbesondere des Journalismus. Die Fähigkeiten des AI Scientist lassen sich auf den journalistischen Prozess übertragen. Ein hypothetischer „AI Journalist“ könnte Aufgaben wie Themenfindung, Recherche, Artikelerstellung und sogar die Produktion multimedialer Inhalte übernehmen.
Stellen wir uns vor, ein solches System würde auf den Journalismus angewendet: Es könnte automatisch Nachrichtenquellen und soziale Medien überwachen, um aufkommende Themen und Trends zu identifizieren. Es könnte große Datenmengen durchsuchen und analysieren, um tiefgreifende Recherchen durchzuführen.
Die Erstellung von Artikeln in verschiedenen Stilen und Formaten, angepasst an unterschiedliche Zielgruppen, ist ebenso möglich wie die automatische Generierung passender Bilder, Infografiken und Videos. Sogar die Personalisierung von Inhalten basierend auf individuellen Leserinteressen und -verhalten könnte durch ein solches System realisiert werden.
Bitte keine Automatisierung!
Die Vorstellung von KI-gesteuerten Nachrichtenredaktionen, die rund um die Uhr personalisierte Inhalte produzieren, mag zunächst verlockend erscheinen. Die potenziellen Vorteile in Bezug auf Effizienz, Skalierbarkeit und Kosteneinsparungen sind offensichtlich. Doch während die technologischen Möglichkeiten faszinierend sind, ist es entscheidend, die damit verbundenen Risiken und ethischen Implikationen gründlich zu betrachten.
Trotz des unbestreitbaren Potenzials der KI in der Informationsverarbeitung und Textproduktion, gibt es zwingende Gründe, warum der menschliche Faktor insbesondere im Journalismus Bereich unverzichtbar bleibt:
KI-Systeme mögen beeindruckende Fähigkeiten in der Datenverarbeitung und Texterstellung haben, doch sie stoßen an ihre Grenzen, wenn es um das tiefe Verständnis komplexer gesellschaftlicher Zusammenhänge geht. Menschliche Journalisten bringen lebensweltliche Erfahrungen, Intuition und die Fähigkeit zum kritischen Denken mit – Qualitäten, die für eine fundierte und nuancierte Berichterstattung unerlässlich sind.
Die journalistische Ethik stellt eine weitere Herausforderung für KI-Systeme dar. Oft erfordert die Arbeit eines Journalisten komplexe ethische Abwägungen, sei es beim Schutz von Quellen oder bei der Entscheidung, welche Informationen im öffentlichen Interesse veröffentlicht werden sollten. Diese Art von Urteilsvermögen, die auf einem tiefen Verständnis menschlicher Werte und gesellschaftlicher Normen basiert, liegt derzeit jenseits der Fähigkeiten künstlicher Intelligenz.
Zudem zeichnet sich herausragender Journalismus oft durch Kreativität und originelles Denken aus. Bahnbrechende investigative Arbeiten erfordern häufig unkonventionelle Ansätze und die Fähigkeit, Verbindungen herzustellen, die auf den ersten Blick nicht offensichtlich sind. KI-Systeme, so fortschrittlich sie auch sein mögen, sind letztlich auf vorhandene Daten und programmierte Algorithmen beschränkt. Sie können Muster erkennen und Inhalte generieren, aber echte Kreativität und Innovation bleiben eine Domäne des menschlichen Geistes.
Eine unkritische Anwendung von KI im Journalismus birgt erhebliche Risiken
Ohne sorgfältige menschliche Überwachung könnten KI-Systeme zur Verbreitung von Fehlinformationen beitragen, indem sie falsche oder irreführende Informationen verstärken. Es besteht die Gefahr, dass die journalistische Integrität untergraben wird, wenn Nachrichten primär auf Basis von Algorithmen optimiert werden, die auf Engagement und Klickzahlen ausgerichtet sind, statt auf fundierte Berichterstattung.
Angesichts dieser Herausforderungen erweist sich der „Human-in-the-Loop“-Ansatz als vielversprechendster Weg für die Zukunft des Journalismus. Dieser Ansatz sieht vor, dass KI als leistungsfähiges Unterstützungswerkzeug eingesetzt wird, während Menschen die Kontrolle über den redaktionellen Prozess behalten.
Kai Spriestersbach
KI kann ohne Frage bei der Recherche, Datenanalyse und der Erstellung erster Textentwürfe wertvolle Dienste leisten. Die endgültige inhaltliche Gestaltung, die kritische Bewertung und die Entscheidung über die Veröffentlichung sollten jedoch in den Händen erfahrener Journalisten bleiben!
Um diesen Ansatz erfolgreich umzusetzen, sind kontinuierliche Schulungen sowohl für KI-Systeme als auch für menschliche Journalisten unerlässlich. Die KI-Tools müssen regelmäßig überprüft und angepasst werden, um ihre Leistung und Zuverlässigkeit zu gewährleisten. Gleichzeitig müssen Journalisten im effektiven Umgang mit diesen neuen Technologien geschult werden, um ihr volles Potenzial auszuschöpfen, ohne dabei die Grundprinzipien des Journalismus aus den Augen zu verlieren.
Transparenz gegenüber dem Publikum spielt eine entscheidende Rolle in diesem Prozess
Nachrichtenorganisationen sollten offen kommunizieren, wenn KI bei der Erstellung von Inhalten beteiligt war, und die verwendeten Methoden sowie deren Grenzen offenlegen. Dies fördert das Vertrauen der Öffentlichkeit und ermöglicht es den Lesern, die Quellen und Prozesse hinter den Nachrichten, die sie konsumieren, besser zu verstehen.
Letztendlich wird der Journalismus der Zukunft wahrscheinlich eine sorgfältig austarierte Symbiose zwischen menschlicher Expertise und KI-Unterstützung sein. Die größte Herausforderung wird darin bestehen, die Vorteile der KI zu nutzen, ohne die Grundprinzipien des Journalismus zu kompromittieren. Nur durch einen verantwortungsvollen, ethischen und menschenzentrierten Ansatz können wir sicherstellen, dass der Journalismus auch im KI-Zeitalter seine wichtige Rolle als vierte Gewalt in der Demokratie erfüllt.
Kai Spriestersbach
Der AI Scientist zeigt uns das enorme Potenzial von KI in komplexen intellektuellen Prozessen. Im Journalismus könnte ähnliche Technologie zu einer Effizienzsteigerung und Erweiterung der Berichterstattung führen. Doch es ist von entscheidender Bedeutung, dass wir die Grenzen und Risiken dieser Technologien erkennen und den menschlichen Faktor nicht aus den Augen verlieren. Nur so können wir eine Zukunft gestalten, in der Technologie den Journalismus bereichert, ohne dessen Kern – die menschliche Perspektive, Ethik und kritisches Denken – zu ersetzen.
KI-Automatisierung in anderen Bereichen
Während die vollständige Automatisierung des investigativen Journalismus noch in weiter Ferne liegt, eröffnen sich in anderen Bereichen der Textproduktion bereits heute vielversprechende Möglichkeiten für den Einsatz von KI. Es lohnt sich, einen differenzierten Blick auf verschiedene Textformate zu werfen und zu untersuchen, wo eine Automatisierung sinnvoll und machbar ist.
Besonders im Bereich der Produkt- und Gebrauchstexte zeigt sich ein erhebliches Potenzial für KI-gestützte Automatisierung. Diese Textsorten, zu denen beispielsweise Produktbeschreibungen, technische Dokumentationen oder FAQ-Seiten gehören, folgen oft standardisierten Strukturen und basieren auf klar definierten Informationen. Hier können KI-Systeme ihre Stärken in der Verarbeitung großer Datenmengen und der konsistenten Anwendung vorgegebener Muster voll ausspielen.
Ein Beispiel hierfür ist die Erstellung von Produktbeschreibungen für Online-Shops. E-Commerce-Plattformen wie Amazon oder Zalando müssen täglich tausende neue Produkte mit aussagekräftigen Beschreibungen versehen. KI-Systeme können dabei helfen, aus technischen Spezifikationen, Herstellerinformationen und Kundenbewertungen automatisch ansprechende und informative Produkttexte zu generieren. Dies spart nicht nur Zeit und Ressourcen, sondern gewährleistet auch eine konsistente Qualität und Struktur über das gesamte Produktsortiment hinweg.
Auch im Bereich der technischen Dokumentation eröffnen sich interessante Möglichkeiten. KI-Systeme können aus technischen Daten, Bedienungsanleitungen und Fehlerbehebungsprotokollen strukturierte und leicht verständliche Anleitungen erstellen. Sie können sogar verschiedene Versionen für unterschiedliche Zielgruppen generieren, von detaillierten technischen Handbüchern für Experten bis hin zu vereinfachten Kurzanleitungen für Endverbraucher.
Im Finanzsektor werden bereits KI-Systeme eingesetzt, um aus komplexen Finanzdaten automatisch Marktberichte und Analysen zu erstellen. Diese Texte folgen oft einem standardisierten Format und basieren auf quantitativen Daten, was sie für eine KI-gestützte Erstellung prädestiniert. Große Nachrichtenagenturen wie Bloomberg und Reuters nutzen solche Systeme bereits erfolgreich, um die Geschwindigkeit und den Umfang ihrer Finanzberichterstattung zu erhöhen.
Auch im Sportjournalismus, insbesondere bei der Berichterstattung über Sportereignisse mit klaren statistischen Daten, können KI-Systeme wertvolle Unterstützung leisten. Sie können aus Spielstatistiken, historischen Daten und aktuellen Entwicklungen automatisch Spielberichte generieren, die die wichtigsten Ereignisse und Leistungen zusammenfassen.
Es ist jedoch wichtig zu betonen, dass selbst in diesen Bereichen, wo die Anforderungen an Kreativität und kritisches Denken möglicherweise geringer sind, die menschliche Überwachung und Kontrolle unerlässlich bleibt. Die Technologie hat ihre Grenzen und Schwächen, die es zu verstehen und zu managen gilt.
Kai Spriestersbach
Eine der Hauptherausforderungen besteht darin, die KI-Systeme mit ausreichend hochwertigen und relevanten Daten zu füttern. Nur so können sie akkurate und nützliche Texte produzieren. Es bedarf einer sorgfältigen Kuratierung der Eingabedaten und einer kontinuierlichen Überprüfung der Ausgaben, um Fehler oder unbeabsichtigte Verzerrungen zu vermeiden.
Ein weiterer kritischer Punkt ist die Anpassungsfähigkeit der Systeme an sich ändernde Anforderungen und Kontexte. Produktbeschreibungen müssen beispielsweise an neue Markttrends oder gesetzliche Vorgaben angepasst werden, technische Dokumentationen müssen mit Produktaktualisierungen Schritt halten. Hier ist menschliches Urteilsvermögen gefragt, um die KI-Systeme entsprechend zu justieren und ihre Ausgaben zu validieren.
Darüber hinaus gibt es ethische und rechtliche Überlegungen zu berücksichtigen. Auch wenn es sich um scheinbar unkritische Textsorten handelt, können unbedachte Formulierungen oder versteckte Vorurteile in automatisch generierten Texten problematische Auswirkungen haben. Eine menschliche Prüfung auf Angemessenheit und potenzielle negative Implikationen bleibt daher unerlässlich.
Die Zukunft der Textproduktion liegt in einer hybriden Herangehensweise
KI-Systeme können die Grundlagen schaffen, indem sie Rohtexte generieren, Daten zusammenfassen und konsistente Strukturen vorgeben. Menschliche Redakteure und Experten übernehmen dann die Rolle der Kuratoren, Editoren und Qualitätsprüfer. Sie verfeinern die Texte, fügen nuancierte Einsichten hinzu und stellen sicher, dass die endgültigen Produkte den gewünschten Qualitätsstandards entsprechen.
Diese Zusammenarbeit zwischen Mensch und Maschine ermöglicht es, die Effizienz und Skalierbarkeit der KI-Systeme zu nutzen, ohne dabei auf die unverzichtbaren menschlichen Qualitäten wie Urteilsvermögen, Kreativität und ethisches Bewusstsein zu verzichten. So können Unternehmen und Organisationen von den Vorteilen der Automatisierung profitieren, während sie gleichzeitig die Qualität und Integrität ihrer Texte wahren.
Letztendlich zeigt diese differenzierte Betrachtung, dass die KI-gestützte Textautomatisierung kein Alles-oder-Nichts-Szenario ist. Es gibt ein breites Spektrum von Anwendungsmöglichkeiten, die je nach Textsorte, Zielgruppe und Anforderungen variieren. Der Schlüssel zum Erfolg liegt darin, die Stärken der KI gezielt dort einzusetzen, wo sie den größten Mehrwert bieten, und gleichzeitig die menschliche Expertise dort zu bewahren, wo sie unverzichtbar ist. Nur so kann eine ausgewogene und effektive Integration von KI in die Textproduktion gelingen, die sowohl die Effizienz steigert als auch die Qualität und Integrität der Inhalte gewährleistet.
Andrej Karpathy, ehemaliger OpenAI-Forscher und KI-Pionier, hat in einem Tweet kürzlich auf ein grundlegendes Problem in der KI-Entwicklung hingewiesen, über das aus meiner Sicht viel zu wenig gesprochen wird: Die Schwächen des Reinforcement Learning from Human Feedback (RLHF). Damit bringt er das Dilemma in der KI-Forschung hoffentlich wieder ins Rampenlicht.
Wie können wir Systeme entwickeln, die nicht nur menschenähnliche Texte produzieren, sondern echtes Verständnis und Problemlösungsfähigkeiten demonstrieren? Und wie können wir diese Fähigkeiten objektiv und zuverlässig messen?
Diese Fragen zu beantworten, wird entscheidend sein für die nächste Generation von KI-Systemen – Systeme, die nicht nur imitieren, sondern wirklich verstehen und denken können.
Das RLHF-Dilemma
RLHF, oft als Schlüssel zum Erfolg von Chatbots wie ChatGPT gepriesen, steht schon länger in der Kritik von KI-Forschern. Das Problem: Es fehlt an wirklich objektiven Kriterien und einem generalisierbaren Trainingsziel.
Zum Hintergrund: RLHF steht für Reinforcement Learning from Human Feedback und beschreibt eine Trainingsmethode für KI-Modelle, insbesondere für große Sprachmodelle (LLMs), die menschliches Feedback nutzt, um das Verhalten des Modells zu verbessern.
Das Grundprinzip hinter RLHF ist ziemlich einfach: Das Modell wird belohnt, wenn es Antworten generiert, die Menschen als gut bewerten und im Gegenzug wird es „bestraft“, wenn seine Ausgaben als unerwünscht eingestuft werden.
Auf Basis menschlicher Bewertung wird in der Regel ein separates Belohnungsmodell trainiert, das menschliche Präferenzen vorhersagen soll. Anschließend kann das ursprüngliche LLM wird mit Hilfe des Belohnungsmodells optimiert werden.
Das hat durchaus seine Vorteile, beispielsweise ermöglicht es die Anpassung von KI-Verhalten an menschliche Präferenzen und kann unerwünschtes Verhalten reduzieren (z.B. Toxizität, Voreingenommenheit, etc. aber es basiert letztlich auf subjektiven menschlichen Urteilen Einzelner, die voreingenommen sein können.
Zudem werden unglaublich große Mengen an menschlichem Feedback benötigt, was in der Praxis zum Einsatz des Reward-Modells führt, welches die tiefe menschliche Erfahrung nur unzureichend vorhersagen kann. Zudem kommt es schnell zu einer Überanspassung und das LLM kann lernen, das Belohnungssystem „auszutricksen“, statt wirklich besser zu werden
Karpathy vergleicht in seinem Tweet RLHF mit dem Training von DeepMinds AlphaGo, um das Problem verständlicher zu erklären:
AlphaGo lernte durch echtes Reinforcement Learning Spiele zu gewinnen, also dadurch, automatisiert, immer wieder „gegen sich selbst“ zu spielen und dabei ein klares Trainingsziel zu verfolgen, nämlich zu gewinnen.
Dies ist bei RLHF nie möglich, denn hier optimiert man auf subjektiven menschlichen Bewertungen, also mehr einen Vibe anstatt objektiver Kriterien und bräuchte zudem eine schier unendliche Schar an menschlichen Feedback-Geber:innen.
Neue Ansätze für besseres KI-Training
Es wäre doch mal eine Idee, das Basismodell mit einem Datensatz zu trainieren, der ausschließlich faktisch korrekte Aussagen enthält. Dies könnte die Grundlage für zuverlässigere und weniger halluzinierende Modelle schaffen.
Ich frage mich schon länger, ob sauberere Trainingsdaten die Grundmodelle nicht schon besser machen würden.
Außerdem müssen wir objektivere Methoden zur Bewertung von KI-Leistungen entwickeln, statt sich auf menschliche Bewertungen zu verlassen!
Aber um Dinge wie Faktenüberprüfung zu automatisieren, brächten wir erstmal zuverlässige, automatisierte Systeme zur Verifizierung von Modellantworten gegen verifizierte Datenbanken. Hier kommen dann wieder fehleranfällige LLMs zum Einsatz und damit beißt sich die Katze in den Schwanz!
Ebenso wenig lässt sich die Logische Konsistenz einfach Berechnen. Wie könnte eine Bewertung der internen Kohärenz von Antworten über mehrere verwandte Fragen hinweg aussehen, in der weder Menschen, noch LLMs zum Einsatz kommen?
Noch komplexer wird es dann bei der Beurteilung echter Problemlösungsfähigkeit. Bei der Messung der Fähigkeit, komplexe Aufgaben in mehreren Schritten zu lösen, könnte man sicherlich Benchmarks mit einigen Tests erstellen, die aber dann schnell als Teil der Trainingsdaten in die Modelle einfließen und keine Aussagekraft über echte Generalisierung des Modells erlauben.
Self-Exploration als Weg aus den lokalen Maxima
In einem aktuellen Paper beschreiben Forscher:innen der Northwestern University und Microsoft einen Ansatz, den sie Self-Exploring Language Models nennen, einen interessanten neuen Ansatz zur Verbesserung des RLHF-Prozesses für große Sprachmodelle.
Das Paper löst also nicht das Grundproblem von RLHF, aber adressiert ein wichtiges Problem von RLHF: Die effiziente Erkundung des riesigen Raums möglicher Sprachausgaben. Also unabhängig davon, wer oder wie wir die Ergebnisse bewerten, stellt sich immernoch die Frage: „Wie können wir sicherstellen, dass Modelle systematisch den gesamten möglichen Ausgaberaum erkunden, um das bestmögliche Ergebnis zu finden?“
Es baut dabei auf bestehenden Methoden wie DPO (Direct Preference Optimization) auf und versucht, deren Schwächen zu überwinden. Die Autoren führen hierfür einen neuen Algorithmus namens SELM (Self-Exploring Language Models) ein. SELM verwendet ein zweistufiges Optimierungsziel, das „optimistisch“ auf potenziell hochwertige Antworten ausgerichtet ist. Dies soll eine aktivere Erkundung von Bereichen außerhalb der Trainingsverteilung ermöglichen und es ermöglichen, lokale Maxima zu überwinden.
SELM eliminiert dabei die Notwendigkeit eines separaten Reward Models (RM) und reduziert die undifferenzierte Bevorzugung ungesehener Extrapolationen, ein bekanntes Problem bei DPO. Der Ansatz verspricht also eine effizientere Erkundung des Antwort-Raums. SELM verwendet dazu ein bilevel (zweistufiges) Optimierungsproblem. Die Grundidee ist, nicht nur die Belohnung zu maximieren, sondern auch aktiv nach potenziell hohen Belohnungen in unerforschten Bereichen zu suchen. Der Algorithmus fügt einen „Optimismus-Term“ zur Zielfunktion hinzu. Dieser Term bevorzugt Antworten, die möglicherweise hohe Belohnungen in bisher unerforschten Bereichen erzielen könnten.
Statt ein separates Reward Model (RM) zu verwenden, wird die Belohnungsfunktion direkt durch das Sprachmodell selbst parametrisiert. Dies eliminiert die Notwendigkeit eines externen RMs.
SELM aktualisiert das Modell iterativ. In jeder Iteration: a) Generiert das Modell Antworten auf Prompts. b) Diese Antworten werden bewertet (durch Menschen oder ein AI-System). c) Das Modell wird basierend auf diesem Feedback und dem optimistischen Explorationsziel aktualisiert.
Anders als bei zufälligem Sampling wird das Modell ermutigt, Antworten zu generieren, die möglicherweise hohe Belohnungen in bisher wenig erforschten Bereichen des Antwortspektrums erzielen könnten.
Der Ansatz zielt darauf ab, die übermäßige Bevorzugung von ungesehenen, aber möglicherweise irrelevanten Extrapolationen zu reduzieren – ein bekanntes Problem bei DPO. Durch die gezielte Exploration kann SELM effizienter diverse und hochwertige Antworten generieren, was den Trainingsprozess beschleunigt und verbessert.
Konkret läuft der Prozess etwa so ab:
Das Modell generiert eine Antwort auf einen Prompt.
Statt nur die erwartete Belohnung zu maximieren, wird auch berücksichtigt, wie „neuartig“ oder „unerforschte“ diese Antwort ist.
Die generierte Antwort wird bewertet.
Das Modell wird aktualisiert, wobei sowohl die erhaltene Bewertung als auch das Potenzial für zukünftige hohe Belohnungen in ähnlichen, bisher unerforschten Antwortbereichen berücksichtigt werden.
Dieser Prozess wird wiederholt, wobei das Modell kontinuierlich ermutigt wird, den Antwort-Raum breiter zu erkunden, anstatt sich nur auf bekannte „sichere“ Antworten zu verlassen.
Dieser Ansatz ermöglicht es dem Modell, aktiv neue Arten von Antworten zu erkunden und zu lernen, während es gleichzeitig die Qualität der Antworten basierend auf dem erhaltenen Feedback verbessert. Es ist ein Balanceakt zwischen Exploration (Erkundung neuer Möglichkeiten) und Exploitation (Nutzung des bereits Gelernten).
In ersten Tests konnten bereits signifikante Leistungssteigerungen bei Instruction-Following-Benchmarks wie MT-Bench und AlpacaEval 2.0 erzielt werden, sowie Verbesserungen bei verschiedenen akademischen Benchmarks.
Wenn sich die Methode bewährt, könnte sie zu besser ausgerichteten und vielseitigeren LLMs führen. Der Ansatz könnte auch die Effizienz des Trainingsprozesses verbessern, was angesichts der hohen Kosten für das Training großer Modelle bedeutsam ist.
Allerdings ist noch unklar, wie gut dieser Ansatz auf noch größere Modelle skaliert und wie sich die Methode in Bezug auf ethische Überlegungen und Sicherheitsaspekte verhält.
Insgesamt scheint dieses Paper einen vielversprechenden neuen Ansatz zur Verbesserung von RLHF zu präsentieren, der einige der Hauptherausforderungen im Bereich des Alignments von LLMs adressiert. Es wird interessant sein zu sehen, wie sich diese Methode in der breiteren Forschungsgemeinschaft bewährt und ob sie in der Praxis bei der Entwicklung zukünftiger LLMs Anwendung findet.
LLM-Evaluation: Ein Schritt vorwärts, aber noch nicht am Ziel
Hugging Faces CTO Philipp Schmids Ansatz zur LLM-Evaluation, wie er ihn in seinem Blogpost beschreibt, bietet einige clevere und praktische Lösungen für die Herausforderungen bei der Bewertung von Sprachmodellen. Dennoch zeigt er auch, wie tief verwurzelt die Probleme sind.
Der Fokus auf eine unkomplizierte Evaluationsmethode macht sie leicht implementierbar und skalierbar. Die Verwendung von additiven Scores und vordefinierten Evaluationsschritten bietet eine gewisse Konsistenz und die Einbeziehung von Beispielen kann die Bewertung besser an menschliche Präferenzen anpassen.
Aber die Schwächen von RLHF, insbesondere die Subjektivität bleibt erhalten, denn auch wenn ein LLM als „Richter“ eingesetzt wird, basiert dessen Urteil letztlich auf subjektiven Kriterien, die von Menschen definiert wurden. Wir verwenden ein LLM, um ein anderes LLM zu bewerten, was zu einer Art „Echokammer“ führen kann, in der die Schwächen und Verzerrungen des bewertenden Modells die Evaluation beeinflussen. Die Bewertung basiert immer noch auf oberflächlichen Merkmalen und „Vibes“ statt auf einem tiefgreifenden Verständnis des Inhalts!
Leider keine Lösung für das Grundproblem
Der Ansatz umgeht das zentrale Problem, das wir diskutiert haben – den Mangel an wirklich objektiven Kriterien für die Leistung von LLMs in offenen Domänen. Schmids Methode ist vielleicht ein Schritt in Richtung praktischer, skalierbarer Evaluationen und kann durchaus nützlich sein für schnelle, iterative Verbesserungen von LLM-Anwendungen, eine konsistente Qualitätskontrolle in produktiven Umgebungen und Vergleiche zwischen verschiedenen Modellversionen oder -konfigurationen.
Allerdings müssen wir weiterhin nach Lösungen für die grundlegenderen Herausforderungen suchen!
Das Problem der Skalierbarkeit des menschlichen Feedbacks wird derzeit in der Regel durch „Gespräche mit sich selbst“ gelöst, also das Modell soll seine eigenen Ausgaben analysieren und verbessern oder verschiedene Instanzen des Modells überprüfen gegenseitig ihre Antworten.
Theoretisch wäre sogar eine Art evolutionäres Training möglich, welches Modellvarianten für weiteres Training bevorzugt, die konsistentere und korrektere Antworten geben.
Dafür braucht es jedoch zunächst wirklich objektive Kriterien, beispielsweise für:
Informationsgehalt: Quantifizierung des tatsächlichen Informationsgehalts in Modellantworten.
Anwendbarkeit: Messung, wie gut Menschen die Antworten des Modells in realen Situationen umsetzen können.
Kreative Problemlösung: Bewertung der Fähigkeit, neuartige Lösungen für unbekannte Probleme zu generieren.
Ethische Konsistenz: Überprüfung der Einhaltung ethischer Richtlinien über verschiedene Szenarien hinweg.
Metakognitive Fähigkeiten: Beurteilung der Fähigkeit des Modells, die Grenzen seines eigenen Wissens zu erkennen und zu kommunizieren.
Diese Kritik an RLHF ist nicht neu, aber sie unterstreicht die Notwendigkeit innovativer Ansätze im KI-Training. Die Kombination aus saubereren Trainingsdaten, objektiveren Bewertungsmethoden und fortgeschrittenen Self-Training-Techniken könnte der Schlüssel zu einer neuen Generation von KI-Systemen sein. Diese Systeme wären nicht nur leistungsfähiger, sondern auch zuverlässiger und ethisch vertretbarer. Die Herausforderung bleibt groß, aber die potenziellen Belohnungen sind es wert.
Fazit und Ausblick
Wir brauchen Bewertungskriterien, die weniger auf subjektiven menschlichen Urteilen und mehr auf messbaren, reproduzierbaren Ergebnissen basieren. Evaluation sollte stärker auf spezifisches Fachwissen in verschiedenen Bereichen zurückgreifen, um die Korrektheit und Nützlichkeit von Antworten besser beurteilen zu können. Statt einer einzelnen Punktzahl sollten wir multiple Dimensionen der Leistung betrachten – von faktischer Korrektheit über logische Konsistenz bis hin zu ethischen Aspekten.
Wir brauchen Methoden, die nicht nur bewerten, sondern auch deterministisch erklären können, warum eine bestimmte Ausgabe als gut oder schlecht eingestuft wird. Zudem brauchen wir vollkommen neue Tests, die nicht nur Textgenerierung, sondern echtes Problemlösen und Reasoning bewerten.
In einem kürzlich veröffentlichten Artikel präsentiert Bernard Huang, Mitbegründer von Clearscope, ein faszinierendes Konzept namens „Ranch-Style SEO“. Huangs Beitrag ist zweifellos eine tiefgründige Analyse der aktuellen SEO-Landschaft und bietet wertvolle Einblicke in die Zukunft der Content-Erstellung. Doch wirft seine Darstellung auch die Frage auf: Brauchen wir wirklich einen neuen Begriff? Was unterscheidet Ranch-Style SEO denn vom aktuellen Stand der etablierten SEO-Strategien?
Die Kernpunkte von Ranch-Style SEO
Huang argumentiert überzeugend, dass die Ära der keywordlastigen, technischen SEO vorbei ist. Stattdessen plädiert er für einen Ansatz, der sich auf folgende Aspekte konzentriert:
Fokus auf Disaggregation statt Aggregation: Im Gegensatz zur „Skyscraper-Technik“, in Deutschland eher als „holistische Landingpages“ bekannt, die massive, umfassende Inhalte erstellt, legt Ranch Style SEO Wert darauf, Themen in kleinere, gezieltere Stücke zu zerlegen, die eng mit der Suchreise des Nutzers übereinstimmen.
Themenzentrierung statt Keywordzentrierung: Es verschiebt sich weg von der starken Abhängigkeit von Keywords und konzentriert sich stattdessen darauf, Themen gründlich aus mehreren Blickwinkeln und Perspektiven abzudecken.
Betonung des Informationsgewinns: Ranch Style SEO zielt darauf ab, neue, einzigartige Erkenntnisse zum Knowledge Graph von Google beizutragen, anstatt nur bestehende Informationen neu zu verpacken. Dies hilft Inhalten, sich in einer Ära der KI-generierten Inhaltssättigung abzuheben.
Priorisierung von Erfahrung aus erster Hand und Expertise: Es orientiert sich an Googles verstärktem Fokus auf E-E-A-T (Erfahrung, Expertise, Autorität, Vertrauenswürdigkeit), indem es echte Fachkompetenz demonstriert und wertvolle, relevante Informationen liefert.
Qualität vor Quantität: Anstatt zu versuchen, massive Mengen an Inhalten zu produzieren, konzentriert sich Ranch Style SEO darauf, hochwertige, gezielte Stücke zu erstellen, die eng mit der Suchintention des Nutzers übereinstimmen.
Anpassungsfähigkeit an sich entwickelnde Themen: Durch die Konzentration auf die Abdeckung von Themen aus mehreren Blickwinkeln hält dieser Ansatz Inhalte relevant, während sich Suchtrends und Nutzerbedürfnisse im Laufe der Zeit ändern.
Nutzerzentrierter Ansatz: Die Strategie zielt darauf ab, die Suchintention des Nutzers effektiver zu befriedigen, indem sie präzise, verdauliche Inhaltsstücke liefert, die auf verschiedene Stadien der Nutzerreise zugeschnitten sind.
Dieser Ansatz wird als eine „zukunftssichere“ Strategie positioniert, die sich an Änderungen in Googles Algorithmen und die Herausforderungen durch KI-generierte Inhalte anpasst.
Die Argumentation hinter Ranch-Style SEO
Huangs Argumentation für diesen Ansatz ist stichhaltig:
Entwicklung der Google-Algorithmen: Er zeichnet die Evolution von Google’s Algorithmen nach, von Hummingbird bis zu den jüngsten Helpful Content Updates, die alle eine Verschiebung hin zu qualitativ hochwertigen, nutzerzentrierten Inhalten zeigen.
Herausforderung durch KI: Huang erkennt die Herausforderungen, die durch KI-generierte Inhalte entstehen, und argumentiert, dass menschliche Expertise und einzigartige Einsichten wichtiger denn je sind.
Verändertes Nutzerverhalten: Er weist auf die zunehmende Skepsis gegenüber Suchmaschinenergebnissen hin und betont die Notwendigkeit, vertrauenswürdige, erfahrungsbasierte Inhalte zu liefern.
Neuer Ansatz oder bewährte Praxis?
Während Huangs Analyse zweifellos wertvoll ist, stellt sich die Frage: Beschreibt „Ranch-Style SEO“ wirklich einen neuen Ansatz, oder fasst es lediglich Best Practices zusammen, die echte Experten bereits seit Jahren anwenden?
Die Fokussierung auf Nutzerintention und hochwertige Inhalte ist seit langem ein Mantra.
Die Bedeutung von E-A-T (jetzt E-E-A-T) wird von Google seit Jahren betont.
Content-Strategien, die auf ganzheitliche Themenabdeckung setzen, sind nicht neu.
Dennoch liegt der Wert von Huangs Beitrag in der klaren Artikulation und Zusammenfassung dieser Prinzipien sowie in der Betonung ihrer zunehmenden Wichtigkeit im Zeitalter der KI-generierten Inhalte.
Fazit
Bernard Huangs „Ranch-Style SEO“ bietet aus meiner Sicht durchaus eine wertvolle Perspektive auf die Zukunft der Content-Erstellung und SEO. Ob wir diesen Ansatz nun als revolutionär oder als Evolution bewährter Praktiken betrachten – die zugrundeliegenden Prinzipien sind zweifellos von entscheidender Bedeutung für den SEO-Erfolg in der sich ständig wandelnden digitalen Landschaft.
Unabhängig von der Nomenklatur erinnert uns Huangs Beitrag daran, dass im Kern erfolgreicher SEO-Strategien immer die Erstellung von hochwertigen, relevanten und einzigartigen Inhalten steht, die einen echten Mehrwert für die Nutzer bieten.
Den Fokus auf einen Informationsgewinn und echte Erfahrung aus erster Hand und Expertise zu legen, halte ich in Zeiten von KI-generierter Texte für den wichtigsten Punkt, den man garnicht überbetonen kann!
Als langjähriger Beobachter und Kommentator der digitalen Suchlandschaft habe ich seit Jahren auf diesen Moment gewartet: Am 29. Juli 2024 hat die KI-basierte Suchmaschine Perplexity ihr bahnbrechendes „Publishers‘ Program“ vorgestellt. Dieses Programm könnte endlich die dringend benötigte Brücke zwischen KI-Technologie und Qualitätsjournalismus schlagen – ein Schritt, der in Zeiten von KI-generierten Suchantworten überfällig war.
Ist das der lang erwartete Paradigmenwechsel?
Seit Google und andere Suchmaschinen begonnen haben, mittels KI direkte Antworten in den Suchergebnissen zu präsentieren (die sogenannten „AI Overviews“), hat sich die Dynamik zwischen Suchmaschinen und Content-Erstellern dramatisch verändert.
Nutzer werden nicht mehr auf die Webseiten der Inhaltsanbieter weitergeleitet, was die traditionellen Geschäftsmodelle der Verlage erheblich unter Druck setzt.
In diesem Kontext ist Perplexity’s Initiative nicht nur innovativ, sondern geradezu revolutionär!
Das Herzstück: Faire Einnahmenteilung
Der Kern des Programms ist ein Modell zur Einnahmenteilung, das in den kommenden Monaten eingeführt werden soll. Wenn die Inhalte eines Verlags in einer Antwort zitiert werden, die zu Werbeeinnahmen führt, wird der Verlag daran beteiligt.
Dies ist genau der neue „Deal“, auf den die Branche gewartet hat – eine faire Kompensation für die Nutzung hochwertiger Inhalte in KI-generierten Antworten.
Namhafte Partner von Beginn an: Es ist ermutigend zu sehen, dass sich bereits renommierte Publikationen wie TIME, Der Spiegel, Fortune und Entrepreneur dem Programm angeschlossen haben. Auch die Beteiligung kleinerer, aber einflussreicher Medien wie The Texas Tribune unterstreicht das Potenzial dieses Ansatzes, die gesamte Medienlandschaft zu transformieren.
Mehr als nur Geld: Technologie-Sharing und Analytics
Besonders beeindruckend finde ich, dass Perplexity über die bloße Einnahmenteilung hinausgeht. Der Zugang zu den Online-LLM-APIs und die Entwicklerunterstützung ermöglichen es Verlagen, die KI-Technologie für ihre eigenen Zwecke zu nutzen.
Die Zusammenarbeit mit ScalePost.ai für detaillierte Analytik ist ein weiterer kluger Schritt, der Verlagen wertvolle Einblicke in die Nutzung ihrer Inhalte gibt.
Ein Modell für die Zukunft: Aufruf an die Tech-Giganten
Perplexity-CEO Aravind Srinivas‘ Vision eines Systems, „von dem das gesamte Internet profitiert“, klingt vielversprechend. Die Offenheit für weitere Kooperationsformen, wie etwa gebündelte Abonnements, zeigt, dass hier langfristig und ganzheitlich gedacht wird.
Nun liegt der Ball im Feld der großen Technologieunternehmen. Es ist höchste Zeit, dass Google, Bing und andere diesem Beispiel folgen und skalierbare Systeme zur Inhaltslizenzierung entwickeln, anstatt sich auf Einzeldeals mit den ganz Großen der Branche zu beschränken.
Nur so kann ein nachhaltiges Ökosystem entstehen, das Qualitätsjournalismus im Zeitalter der KI-gestützten Informationsverbreitung fördert und erhält.
Ein Hoffnungsschimmer für die digitale Medienzukunft
Das Perplexity Publishers‘ Program ist mehr als nur eine Neuerung – es ist ein Hoffnungsschimmer für eine ausgewogenere und fairere digitale Medienlandschaft.
Es zeigt, dass es möglich ist, die Interessen von KI-Technologie und Qualitätsjournalismus in Einklang zu bringen.
Als jemand, der die Entwicklungen in diesem Bereich seit Jahren verfolgt, kann ich nur sagen: Es wurde Zeit!
Jetzt liegt es an der restlichen Industrie, nachzuziehen und diesen vielversprechenden Ansatz weiterzuentwickeln. Nur so können wir sicherstellen, dass hochwertiger, vertrauenswürdiger Content auch in Zukunft das Rückgrat unserer digitalen Informationslandschaft bleibt.
Der Countdown läuft: In sechs Monaten tritt der EU AI Act in Kraft!
In weniger als einem halben Jahr wird der EU AI Act die Art und Weise, wie Unternehmen mit künstlicher Intelligenz umgehen, grundlegend verändern. Eine der weitreichendsten, aber oft übersehenen Anforderungen betrifft die KI-Kompetenz der Mitarbeiter. Sind Sie und Ihr Unternehmen darauf vorbereitet?
Die neue Pflicht: KI-Kompetenz als gesetzliche Vorgabe
Ab Januar 2025 tritt Artikel 4 des EU AI Acts in Kraft. Dieser verpflichtet jede Organisation, die KI-Systeme einsetzt – und sei es nur ein einfacher Chatbot – sicherzustellen, dass ihr Personal über „ein ausreichendes Maß an KI-Kompetenz“ verfügt. Diese Verpflichtung gilt nicht nur für EU-Unternehmen, sondern für alle, die KI-Systeme auf dem EU-Markt anbieten oder nutzen.
Was bedeutet KI-Kompetenz?
Der EU AI Act definiert KI-Kompetenz als die Fähigkeiten, das Wissen und das Verständnis, die erforderlich sind, um:
Fundierte Entscheidungen über KI-Systeme zu treffen
Die Chancen und Risiken von KI zu verstehen
Mögliche Schäden durch KI-Systeme zu erkennen und zu vermeiden
KI-Systeme verantwortungsbewusst einzusetzen
Warum ist KI-Kompetenz so wichtig?
Unabhängig von der gesetzlichen Verpflichtung ist die Schulung der Mitarbeiter in KI-Technologien eine der wichtigsten Maßnahmen bei der Implementierung von KI. Gut informierte Mitarbeiter können:
KI-Technologien effektiver nutzen
Risiken frühzeitig erkennen und minimieren
Innovationen vorantreiben
Die Einhaltung von Vorschriften sicherstellen
Was müssen Unternehmen tun?
Bestandsaufnahme: Identifizieren Sie, wo in Ihrem Unternehmen KI-Systeme eingesetzt werden.
Schulungsbedarf ermitteln: Analysieren Sie, welche Mitarbeiter mit KI arbeiten und welche spezifischen Kompetenzen sie benötigen.
Schulungsprogramme entwickeln: Erstellen Sie maßgeschneiderte Schulungen, die technische, ethische und gesellschaftliche Aspekte von KI abdecken.
Kontinuierliche Weiterbildung: KI entwickelt sich rasant. Stellen Sie sicher, dass die Kompetenzen Ihrer Mitarbeiter aktuell bleiben.
Die Konsequenzen der Nichtbeachtung
Viele Organisationen sind sich dieser bevorstehenden Anforderungen noch nicht bewusst. Doch Unwissenheit schützt vor Strafe nicht. Verstöße gegen den EU AI Act können zu erheblichen Bußgeldern führen. Wichtiger noch: Mangelnde KI-Kompetenz kann den sicheren und effektiven Einsatz von KI-Technologien behindern und Ihr Unternehmen im Wettbewerb zurückwerfen.
Chance statt Last
Auch wenn die Erfüllung der KI-Kompetenzanforderungen zunächst aufwendig erscheinen mag, bietet sie enorme Chancen. Gut geschulte Mitarbeiter können das volle Potenzial von KI ausschöpfen, Innovationen vorantreiben und Ihr Unternehmen an die Spitze der digitalen Transformation führen.
Fazit: Jetzt handeln!
Der Countdown läuft. In sechs Monaten müssen Unternehmen die Anforderungen des EU AI Acts erfüllen. Nutzen Sie die Zeit, um sich mit den Vorgaben vertraut zu machen und entsprechende Schulungsprogramme zu implementieren. Investieren Sie in die KI-Kompetenz Ihrer Mitarbeiter – es ist eine Investition in die Zukunft Ihres Unternehmens.
Bereiten Sie sich und Ihr Unternehmen rechtzeitig auf die Anforderungen des EU AI Acts vor. Kontaktieren Sie uns noch heute für ein individuelles Beratungsgespräch und sichern Sie sich Ihren Platz in unseren KI-Kompetenz-Schulungen.
Bereiten Sie Ihr Unternehmen auf die Zukunft vor – mit KI-Kompetenz von Kai Spriestersbach
Kai Spriestersbach ist KI-Experte und Gründer von AFAIK. Mit über zwei Jahrzehnten Erfahrung in digitalen Technologien und als Dozent für generative KI unterstützt er Unternehmen dabei, die Herausforderungen des EU AI Acts zu meistern und das volle Potenzial von KI auszuschöpfen.
Trotz der Herausforderungen und potenziellen Fallstricke, die mit der Erstellung und Nutzung von Knowledge Graphen verbunden sind und die ich in meinem letzten Beitrag beschrieben habe, setzen große Technologieunternehmen wie Google weiterhin auf diese Technologie, insbesondere im Bereich der Websuche. Dies wirft die Frage auf: Warum nutzt Google noch immer Knowledge Graphen, wenn die Erstellung mit Hilfe von unzuverlässigen LLMs weder besonders effektiv noch effizient erscheint?
Insbesondere SEOs stellt sich diese Frage, denn Google hat seinen Knowledge Graphen sogar in seine Cloudbasierte Enterprise Suche Vertex AI Search integriert.
Die Antwort liegt in der Natur der Websuche und der Art und Weise, wie Google seinen Knowledge Graph aufbaut und einsetzt. Anders als bei einem vollständig LLM-generierten Knowledge Graphen, wie er im GraphRAG-Ansatz verwendet wird, basiert Googles Knowledge Graph auf einer Kombination von Quellen und Methoden:
Kuratierte Datenquellen: Ein Großteil von Googles Knowledge Graph basiert auf sorgfältig kuratierten und verifizierten Datenquellen wie Wikipedia, Wikidata, Freebase und anderen vertrauenswürdigen Informationsquellen.
Strukturierte Daten aus dem Web: Google nutzt strukturierte Daten, die Webseitenbetreiber in ihren HTML-Code einbetten (z.B. Schema.org Markup), um den Knowledge Graph zu erweitern.
Maschinelles Lernen und NLP: Fortschrittliche Algorithmen werden eingesetzt, um Informationen aus unstrukturierten Webinhalten zu extrahieren und zu verarbeiten, aber dies geschieht unter strenger Kontrolle und Überprüfung.
Dieser Ansatz ermöglicht es Google, die Vorteile von Knowledge Graphen zu nutzen, während gleichzeitig die Risiken minimiert werden, die mit einer vollständig automatisierten Erstellung verbunden wären. Hier sind einige konkrete Beispiele, wie der Knowledge Graph die Websuche verbessert:
1. Erkennung und Kontextualisierung von Eigennamen
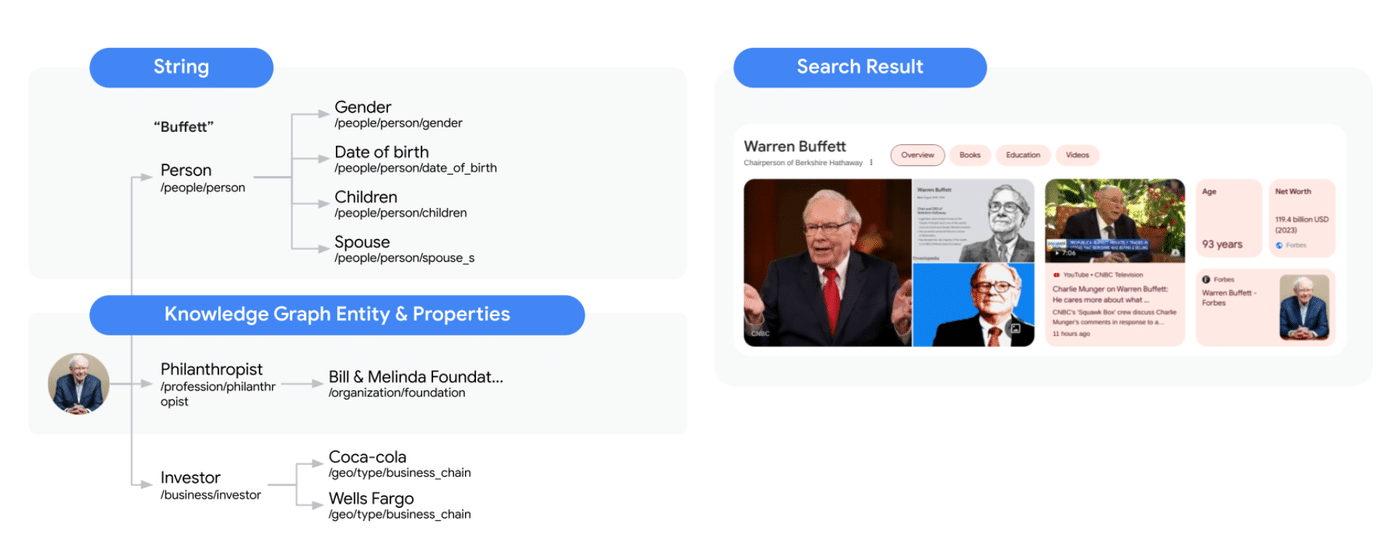
Die Erkennung von Nachnamen berühmter Persönlichkeiten ein gutes Beispiel. Der Knowledge Graph ermöglicht es Google, Suchanfragen wie „Merkel Politik“ korrekt zu interpretieren, auch wenn der Vorname „Angela“ nicht explizit genannt wird. Der Graph enthält die Information, dass „Merkel“ der Nachname einer prominenten Politikerin ist, und kann so den Kontext erweitern und insgesamt relevantere Suchergebnisse liefern.
2. Disambiguierung von mehrdeutigen Begriffen
Ein weiteres Anwendungsgebiet ist die Disambiguierung von Begriffen, die mehrere Bedeutungen haben können. Nehmen wir als Beispiel den Begriff „Jaguar“:
Wenn ein Nutzer „Jaguar Geschwindigkeit“ sucht, kann Google anhand des Knowledge Graphs erkennen, dass sich die Anfrage auf das Tier und die Automarke beziehen könnte.
Basierend auf dem Suchverlauf des Nutzers, seiner geografischen Location und anderen kontextuellen Hinweisen kann die Suchmaschine die wahrscheinlichere Bedeutung priorisieren oder eine gemischte Suchergebnisseite erstellen, die beide Bedeutungen gleichermaßen berücksichtigt.
3. Beantwortung von Faktenfragen
Bei einfachen Faktenfragen kann der Knowledge Graph direkte Antworten liefern, ohne dass der Nutzer eine Website besuchen muss. Zum Beispiel:
„Wie hoch ist der Eiffelturm?“
„Wer ist der aktuelle Bundeskanzler von Deutschland?“
„Wann wurde Albert Einstein geboren?“
Diese Informationen werden oft direkt in den Suchergebnissen angezeigt, was die Benutzerfreundlichkeit erheblich verbessert.
4. Verknüpfung verwandter Konzepte
Der Knowledge Graph ermöglicht es Google, verwandte Konzepte zu verknüpfen und so umfassendere Suchergebnisse zu liefern.
Ein Beispiel:
Bei einer Suche nach „Impressionistische Maler“ kann Google nicht nur eine Liste von Künstlern liefern, sondern auch Informationen über die Epoche, wichtige Werke und Museen, in denen diese Werke ausgestellt sind.
5. Verbesserung lokaler Suchen
Für lokale Suchanfragen ist der Knowledge Graph besonders wertvoll:
Eine Suche nach „Italienische Restaurants in der Nähe“ kann dank des Knowledge Graphs nicht nur Adressen liefern, sondern auch Öffnungszeiten, Bewertungen, typische Gerichte und sogar Informationen zur italienischen Küche im Allgemeinen.
Diese Informationen liegen Google dank der Unternehmensprofile in gesicherter und strukturierter Form zum Größten Teil bereits vor.
6. Unterstützung bei der Beantwortung komplexer Fragen
Obwohl der Knowledge Graph allein keine komplexen Fragen beantworten kann, unterstützt er die Suchmaschine dabei, relevante Informationen zu finden und zu präsentieren.
Ein Beispiel:
Bei einer Frage wie „Wie hat sich die Klimapolitik in Deutschland seit 2010 entwickelt?“ kann der Knowledge Graph helfen, relevante Ereignisse, Personen und Konzepte zu identifizieren und in einen zeitlichen Kontext zu setzen, was mit einer semantischen Suche alleine nicht möglich wäre.
Keine generierten Knowledge Graphen in Suchmaschinen
Trotz dieser Vorteile und Beispiele, generiert Google (zumindest bislang) noch keine Knowledge Graphen via KI aus unstrukturierten Texten. Die folgende Google SERP zu „ChatGPT Alternatives“ wird zwar von einigen SEOs als automatisch generierte Knowledge Graph Integration interpretiert, aber das ist eine Fehleinschätzung:
Wenn man sich die Eigenschaften dieser gefundenen Entitäten, insbesondere die fehlenden Beziehungen ansieht, wird klar, dass hierbei lediglich eine NER (Named-entity recognition) zum Einsatz kommt.
Google erkennt auf Webseiten also die Firmen oder Tools, kann diese aber noch lange nicht in Beziehung zu anderen Entitäten setzen, insbesondere nicht zu denen im gesichterten KG!
Kai Spriestersbach
Die Verwendung von Knowledge Graphen in Suchmaschinen wie Google zeigt, dass diese Technologie, wenn sie sorgfältig implementiert und mit anderen Methoden kombiniert wird, erhebliche Vorteile bieten kann. Der Schlüssel liegt in der Kombination verschiedener Datenquellen und Methoden, sowie in der ständigen Überprüfung und Verfeinerung der Informationen.
Während die Erstellung von Knowledge Graphen ausschließlich mit Hilfe von LLMs tatsächlich problematisch wäre, zeigt der Ansatz von Google, dass eine ausgewogene Mischung aus kuratierten Daten, maschinellem Lernen und menschlicher Überprüfung zu deutlichen Verbesserungen in der Qualität und Relevanz von Suchergebnissen führen kann.
Es ist jedoch wichtig zu betonen, dass selbst Googles gesicherter Knowledge Graph nicht unfehlbar ist und ständiger Verbesserung und Aktualisierung bedarf. Die Herausforderung besteht darin, die richtige Balance zwischen Automatisierung und menschlicher Überprüfung zu finden, um sowohl Effizienz als auch Zuverlässigkeit zu gewährleisten.
Generative künstliche Intelligenz gewinnt immer mehr Einfluss auf unser tägliches Leben und zieht ebenso Stück für Stück auch in Suchmaschinen und andere Information Retrieval Systeme ein. Dabei stehen wir jedoch vor einer grundlegenden Herausforderung: Wie können wir sicherstellen, dass KI-Systeme zuverlässige und faktisch korrekte Informationen liefern?
Eine Möglichkeit das sogenannte Grounding über das Einbeziehen von Informationen aus einer Websuche über Googles eigene Grounding API zu realisieren, habe ich in meinem letzen Beitrag beschrieben.
Eine weitere oft diskutierte Lösung sind sogenannte Knowledge Graphen – komplexe Netzwerke von Informationen, die Beziehungen zwischen Entitäten darstellen. Doch während diese Technologie in bestimmten Bereichen brilliert, stößt sie in anderen an ihre Grenzen. Dieser Artikel beleuchtet die Potenziale und Limitationen von Knowledge Graphen im Kontext der KI-Zuverlässigkeit.
Die Stärke von Knowledge Graphen
Knowledge Graphen sind zweifellos leistungsfähige Werkzeuge, wenn es darum geht, komplexe Zusammenhänge zu erfassen und abzubilden. Ein klassisches Beispiel, das die Stärke dieser Technologie verdeutlicht, ist die Analyse von Unternehmensgründungen durch ehemalige Mitarbeiter großer Tech-Konzerne.
Stellen wir uns vor, wir möchten herausfinden, welche erfolgreichen Start-ups von ehemaligen Apple- oder Google-Mitarbeitern gegründet wurden. Ein gut strukturierter Knowledge Graph könnte diese Frage nahezu instantan beantworten, indem er Verbindungen zwischen Personen, Unternehmen, Positionen und Zeiträumen herstellt.
Diese Art von Analyse, die normalerweise aufwendige journalistische Recherche erfordern würde, kann durch einen Knowledge Graphen automatisiert und in Sekundenschnelle durchgeführt werden.
Die Stärke liegt hier in der Fähigkeit, disparate Informationen zu verknüpfen:
Wer hat welches Unternehmen gegründet?
Wie erfolgreich sind diese Unternehmen?
Wo haben die Gründer vorher gearbeitet?
Welche Positionen hatten sie inne und wie lange?
Durch die Verknüpfung dieser Datenpunkte können Knowledge Graphen komplexe Fragen beantworten und Muster aufdecken, die sonst verborgen blieben.
Die Herausforderung der Datengenerierung
Trotz ihrer offensichtlichen Vorteile stoßen Knowledge Graphen auf ein fundamentales Problem: Sie bauen sich nicht von selbst auf. Die Recherchearbeit, die normalerweise von Journalist:innen oder Wissenschaftler:innen geleistet wird, muss auch für den Aufbau eines Knowledge Graphen durchgeführt werden – und zwar mit der gleichen Sorgfalt und Genauigkeit.
Einige Unternehmen haben diesen Prozess perfektioniert. In Spezialbereichen wie der Medizin gibt es Firmen, die seit Jahrzehnten hochwertige und faktisch sorgfältig überprüfte Knowledge Graphen aufbauen. Diese wertvollen Datensammlungen werden nun für beträchtliche Summen an Unternehmen lizenziert, die ihre KI-Anwendungen damit „grounden“ – also mit einer verlässlichen Faktenbasis untermauern – wollen.
Der Aufbau solcher spezialisierten Knowledge Graphen ist jedoch ein zeitaufwändiger und kostspieliger Prozess. Er erfordert nicht nur technisches Know-how, sondern auch tiefgreifendes Fachwissen in den jeweiligen Domänen. Zudem müssen die Daten ständig auf ihre Aktualität und Richtigkeit überprüft werden, was den Prozess zusätzlich verkompliziert.
Der verführerische Einsatz von Large Language Models
Angesichts des enormen Aufwands, der mit dem manuellen Aufbau von Knowledge Graphen verbunden ist, erscheint der Einsatz von Large Language Models (LLMs) zur Automatisierung dieses Prozesses verlockend. Die Idee ist bestechend einfach: LLMs könnten unstrukturierte Texte analysieren, relevante Informationen extrahieren und daraus automatisch Knowledge Graphen generieren.
Ein vielversprechender, aber problematischer Ansatz: GraphRAG
Angesichts der Herausforderungen bei der Erstellung und Nutzung von Knowledge Graphen arbeiten Forscher intensiv an Lösungen, die die Vorteile dieser Technologie nutzen und gleichzeitig ihre Limitationen adressieren wollen. Ein Ansatz, der in diesem Kontext besondere Aufmerksamkeit erregt hat, ist GraphRAG von Microsoft Research.
GraphRAG baut auf der Technologie der Retrieval-Augmented Generation (RAG) auf, erweitert diese aber durch den Einsatz von LLM-generierten Knowledge Graphen. RAG ist eine Technik, bei der Informationen basierend auf einer Benutzeranfrage gesucht und als Referenz für eine KI-generierte Antwort bereitgestellt werden. GraphRAG geht einen Schritt weiter, indem es LLMs nutzt, um aus unstrukturierten Texten Knowledge Graphen zu erstellen und diese dann für verbesserte Antworten zu verwenden.
Dieser Ansatz bietet durchaus einige Vorteile:
Verbesserte Kontextualisierung: Der GraphRAG-Ansatz verspricht, besser darin zu sein, „die Punkte zu verbinden“ und komplexe Zusammenhänge zu erfassen. Es kann Informationen aus verschiedenen Teilen eines Dokuments oder sogar aus mehreren Dokumenten kombinieren, um umfassendere Antworten zu generieren.
Umgang mit privaten Datensätzen: GraphRAG wurde speziell entwickelt, um mit privaten Datensätzen zu arbeiten – also mit Informationen, die nicht im Trainingsdatensatz des LLMs enthalten sind. Dies macht es besonders interessant für Unternehmen, die ihre eigenen, proprietären Daten analysieren möchten.
Thematische Analyse: GraphRAG zeigt sich besonders stark darin, übergreifende Themen und Konzepte in großen Datensätzen zu identifizieren. Dies verspricht ein tieferes Verständnis komplexer Informationssammlungen.
Kritische Betrachtung: Verschiebung statt Lösung des Problems
Trotz der vielversprechenden Aspekte von GraphRAG ist es wichtig, einen kritischen Blick auf diesen Ansatz zu werfen. Ein fundamentales Problem bleibt bestehen: Die Verwendung eines LLMs zur Erstellung eines Knowledge Graphen, der dann wiederum für das Grounding desselben oder eines anderen LLMs genutzt wird, verschiebt das Problem der Unzuverlässigkeit, löst es aber nicht grundsätzlich.
Der Kern des Problems liegt darin, dass das LLM in Microsofts GraphRAG-Ansatz dafür zuständig ist, die Informations-Tupel oder -Tripel aus unstrukturiertem Text zu extrahieren, um den Graphen aufzubauen. Dieser Prozess ist inhärent mit den gleichen Risiken und Schwächen behaftet, die wir bei LLMs generell beobachten:
Fehleranfälligkeit: LLMs können Informationen falsch interpretieren oder Zusammenhänge herstellen, die in Wirklichkeit nicht existieren. Diese Fehler würden direkt in den Knowledge Graphen übernommen.
Halluzinationen: Die Tendenz von LLMs, plausibel klingende, aber faktisch falsche Informationen zu generieren, könnte zu einem Knowledge Graphen führen, der nicht existierende Verbindungen oder Entitäten enthält.
Bias und Verzerrungen: Vorurteile und Verzerrungen, die im Trainingsdatensatz des LLMs vorhanden sind, könnten sich in der Struktur und den Inhalten des generierten Knowledge Graphen widerspiegeln.
Kontextuelle Missverständnisse: LLMs können den Kontext von Informationen missverstehen, was zu fehlerhaften Verknüpfungen im Knowledge Graphen führen kann.
Indem wir ein LLM verwenden, um einen Knowledge Graphen aufzubauen, und diesen dann für das Grounding eines (möglicherweise desselben) LLMs nutzen, schaffen wir einen potenziellen Teufelskreis der Fehlerfortpflanzung. Es besteht die Gefahr, dass Fehler oder Ungenauigkeiten im ursprünglichen Text durch das LLM in den Knowledge Graphen übernommen und dann durch den Grounding-Prozess weiter verstärkt werden.
Kai Spriestersbach
Dies bedeutet nicht, dass GraphRAG ohne Wert ist. Der Ansatz kann durchaus zu verbesserten Ergebnissen in bestimmten Anwendungsfällen führen, insbesondere wenn es um die Verarbeitung großer Mengen unstrukturierter Daten geht. Allerdings ist es entscheidend zu verstehen, dass GraphRAG das grundlegende Problem der KI-Zuverlässigkeit nicht löst, sondern lediglich auf eine andere Ebene verlagert.
Um wirklich zuverlässige KI-Systeme zu entwickeln, müssen wir weiterhin an Methoden arbeiten, die die Genauigkeit und Verlässlichkeit von LLMs grundlegend verbessern. Dies könnte die Entwicklung verbesserter Trainingsmethoden, die Integration von externem Faktenwissen oder die Kombination von KI mit menschlicher Expertise umfassen.
Gleichzeitig unterstreicht die Entwicklung von Ansätzen wie GraphRAG die Notwendigkeit für robuste Evaluierungsmethoden. Wir müssen in der Lage sein, die Qualität und Zuverlässigkeit von automatisch generierten Knowledge Graphen rigoros zu überprüfen und zu bewerten, bevor wir sie für kritische Anwendungen einsetzen.
Dieser Ansatz verspricht eine erhebliche Beschleunigung und Kosteneinsparung bei der Erstellung von Knowledge Graphen. Statt mühsam jede einzelne Information manuell zu überprüfen und einzupflegen, könnten LLMs riesige Textmengen in kurzer Zeit verarbeiten und strukturieren.
Das Dilemma der Verifizierung
Eine mögliche Lösung wäre, den KI-generierten Knowledge Graphen einer gründlichen manuellen Überprüfung zu unterziehen. Doch dies bringt uns zurück zum Ausgangspunkt: Der enorme Zeit- und Ressourcenaufwand, den wir ursprünglich durch den Einsatz von KI vermeiden wollten.
Dennoch könnte sich dieser Aufwand lohnen, wenn wir einen einmal verifizierten Knowledge Graphen für eine Vielzahl von Anwendungen nutzen könnten. Die Idee eines universellen, zuverlässigen Wissensfundaments für KI-Systeme ist zweifelsohne attraktiv.
Die Dynamik der realen Welt
Doch selbst wenn wir einen perfekt verifizierten Knowledge Graphen erstellen könnten, stoßen wir auf ein weiteres, fundamentales Problem: Die Welt steht nicht still. Informationen, die heute korrekt sind, können morgen schon veraltet sein. Menschen wechseln Jobs, Unternehmen fusionieren oder gehen bankrott, wissenschaftliche Erkenntnisse werden revidiert.
Ein Knowledge Graph ist daher niemals wirklich „fertig“. Er erfordert eine ständige Aktualisierung und Pflege, um mit der sich ändernden Realität Schritt zu halten. Dies stellt eine enorme logistische und finanzielle Herausforderung dar, insbesondere wenn wir von einem umfassenden, domänenübergreifenden Knowledge Graphen sprechen.
Knowledge Graphen als Teil der Lösung, nicht als Allheilmittel
Knowledge Graphen sind zweifellos ein mächtiges Werkzeug im Arsenal der KI-Technologien. Sie können komplexe Zusammenhänge abbilden und Erkenntnisse liefern, die sonst verborgen blieben. In spezialisierten Bereichen, wo die Datenmenge überschaubar und die Aktualisierungsrate handhabbar ist, können sie einen erheblichen Mehrwert bieten.
Doch als universelle Lösung für das Problem der KI-Zuverlässigkeit stoßen sie an ihre Grenzen. Die Herausforderungen bei der Erstellung, Verifizierung und kontinuierlichen Aktualisierung sind enorm. Der Einsatz von LLMs zur Automatisierung dieser Prozesse verschiebt das Problem der Unzuverlässigkeit lediglich, anstatt es zu lösen.
Die Zukunft liegt wahrscheinlich in einem hybriden Ansatz: Der gezielte Einsatz von Knowledge Graphen in Bereichen, wo ihre Stärken voll zum Tragen kommen, kombiniert mit anderen Technologien und menschlicher Expertise. Wir müssen akzeptieren, dass es keine einfache, universelle Lösung für das Problem der KI-Zuverlässigkeit gibt.
Stattdessen sollten wir uns darauf konzentrieren, die Grenzen und Möglichkeiten jeder Technologie zu verstehen und transparente Systeme zu entwickeln, die ihre Unsicherheiten klar kommunizieren. Nur so können wir KI-Systeme schaffen, die nicht nur leistungsfähig, sondern auch vertrauenswürdig sind.
Die Herausforderung der KI-Zuverlässigkeit bleibt bestehen, aber mit einem nuancierten Verständnis der verfügbaren Werkzeuge – einschließlich der Stärken und Schwächen von Knowledge Graphen – sind wir besser gerüstet, ihr zu begegnen.
Als jemand, der seit Jahren in der KI-Forschung und SEO-Branche tätig ist, bin ich immer auf der Suche nach bahnbrechenden Entwicklungen. Und lasst mich Euch sagen: Google hat gerade einen Volltreffer gelandet!
Stellt Euch vor, Ihr fragt Euren KI-Assistenten nach dem Wetter und bekommt eine Vorhersage vom letzten Jahr. Oder Ihr erkundigt Euch nach dem aktuellen Oscar-Gewinner und hört von einer Verleihung, die schon ewig her ist. Klingt frustrierend, oder? Genau dieses Problem an Large Language Models und KI-basierten Chatbots hat Google jetzt angegangen, und zwar mit einer Lösung, die wir sofort nutzen können!
Googles „Grounding“-Technologie
Auf der Google Cloud Next 2024 haben die Produktmanager:innen Louis Leo und Tom eine Technologie vorgestellt, die sie „Grounding“ nennen. Im Kern ist es verblüffend einfach: Jede Anfrage an ein Gemini-Modell (Googles neueste KI-Familie) löst eine Suche im Hintergrund aus. Die KI greift also in Echtzeit auf das riesige, stets aktuelle Wissen des Internets zu – ganz so, als würde sie kurz googeln, bevor sie antwortet.
Screenshot aus dem YouTube Video der Präsentation
Aber es kommt noch besser: Das System liefert auch gleich Quellenangaben und Links mit. Es ist, als hätte Euer KI-Assistent plötzlich einen Grundkurs in wissenschaftlichem Arbeiten belegt:
Screenshot aus dem YouTube Video der Präsentation
Die Anwendungsmöglichkeiten sind so vielfältig wie aufregend: Stellt Euch vor, Ihr fragt Eure Essenslieferungs-App nach einem Gericht, das Ihr noch nie probiert habt. Statt einer langweiligen Standardbeschreibung bekommt Ihr eine informative Antwort mit kulturellem Kontext, Zutateninformationen und sogar aktuellen Bewertungen – und das alles, ohne die App zu verlassen.
Uber Eats experimentiert bereits mit dieser Technologie. Bald könnte es Schluss sein mit dem hektischen Googeln von „Was ist Poke?“, während Ihr versucht, Euer Abendessen zu bestellen. Eure App wird zu einem:r kenntnisreichen Foodie-Freund:in, der:die Euch mit brandaktuellen Informationen durch kulinarische Abenteuer führt.
Jenseits des Chats: Die RAG-Revolution
Google hat noch mehr in petto: Eine ganze Suite von Tools für Unternehmen und Entwickler:innen, um ihre eigenen „geerdeten“ KI-Erfahrungen zu schaffen. Diese Technologie nennt sich Retrieval-Augmented Generation (RAG) und umfasst:
Vertex AI Search: Eine vollständig verwaltete Lösung für Unternehmen, um ihre eigenen Daten zu indexieren und zu durchsuchen.
Grounded Generation API: Ein System zur Erstellung von KI-Antworten, die auf spezifischen Informationssets basieren.
Check Grounding API: Ein Faktenchecker für KI-generierte Inhalte.
Stellt Euch einen Kundenservice-Chatbot vor, der sofort auf die gesamte Wissensdatenbank Eures Unternehmens zugreifen kann, oder ein Content-Creation-Tool, das sich in Echtzeit selbst auf Fakten prüft. Die Möglichkeiten sind endlos!
Die Zukunft ist geerdet
Je mehr KI in unseren Alltag integriert wird, desto wichtiger wird es, dass wir ihr vertrauen können. Googles Grounding-Technologie ist ein großer Schritt in diese Richtung und ich gehe fest davon aus, dass OpenAI und Co. hier nachziehen werden.
Für Unternehmen bedeutet das effizientere Werkzeuge und bessere Kundenerfahrungen. Für Entwickler:innen eröffnen sich neue Horizonte bei der Erstellung intelligenter, reaktionsschneller Anwendungen. Und für uns alle verspricht es eine Zukunft, in der digitale Assistent:innen nicht nur clevere Lügner:innen sind, sondern kenntnisreiche, stets aktuelle Begleiter:innen auf unseren digitalen Reisen.
Wenn Du das Ganze in Aktion sehen willst, hier das Video zum Vortrag:
Für meinen aktuell laufenden Onlinekurs „The Future of Search“ entwickle ich gerade ein kleines Tool, mit dem man gezielt die Relevanz von Dokumenten zu Suchanfragen messen kann, um gezielter für die kommenden „AI Overviews“ oder „Search Generative Experience“ optimieren zu können. Bei meinen Recherchen bin ich auf etwas unglaublich spannendes gestoßen…
Das Unternehmen hat seine Suchtechnologie, die bis dato als „Enterprise Search“ vermarktet wurde und auf den Kernbestandteilen der Google Suche basiert, für alle über die Vertex AI API verfügbar gemacht. Diese nutzt unter anderem das proprietäre RankBrain-System, ein einzigartiges Text-Embedding-Modell sowie ein fortgeschrittenes neuronales Matching-System, das bislang nur von ausgewählten Testkunden ausprobiert werden konnte.
Diese Entwicklung eröffnet aus meiner Sicht vollkommen neue Perspektiven für SEO-Experten & -Expertinnen sowie KI-Enthusiasten & -Enthusiastinnen. Insbesondere mit Blick auf die SGE (Search Generative Experience) und Googles AI Overviews bekommt dieser Release, den wahrscheinlich die meisten nicht einmal mitbekommen haben, aus meiner Sicht eine vollkommen neue Bedeutung.
Zum ersten mal ist es möglich, das Ranking von Dokumenten, alleine auf Basis deren Relevanz bei Google zu erforschen, ohne dass andere Rankingfaktoren dieses Bild verzerren. Und das beste: Vertex AI Search kann noch mehr!
Kai Spriestersbach
Was ist Vertex AI Search?
Vertex AI Search ist eine sofort einsatzbereite Suchmaschine, die von der Vertex AI-Plattform von Google Cloud bereitgestellt wird. Damit können Unternehmen schnell auf generativer KI basierende Suchmaschinen für Kunden und Mitarbeiter erstellen. Wenn Sie die Qualität der Suche auf Ihren Websites verbessern möchten oder Ihre Mitarbeiter interne Daten leichter finden sollen, können Sie über Vertex AI Search ganz einfach Suchmaschinen einrichten, die Ihren Zielen entsprechen und gleichzeitig Zugriffssteuerung, Datenschutz und Datenhoheit unterstützen.
Vertex AI Search baut auf einer Vielzahl von Google-Suchtechnologien auf, darunter die semantische Suche. Durch Natural Language Processing sowie Machine Learning lassen sich so relevantere Ergebnisse als bei herkömmlichen, auf Suchbegriffen basierenden Suchverfahren bereitstellen, weil anhand der Suchanfrage des Nutzers Beziehungen innerhalb des Inhalts sowie die eigentliche Absicht erkannt werden.
Der wirklich interessante Teil ist allerdings aus meiner Sicht:
Darüber hinaus baut Vertex AI Search auf die Google-Erfahrung zum Suchverhalten der Nutzer auf und berücksichtigt bei der Reihenfolge der angezeigten Ergebnisse die Relevanz von Inhalten.
Denn damit verrät Google quasi, dass mehr als nur reine Texte in das Modell einfließen. Insbesondere dieser Umstand, also dass Daten zum Nutzerverhalten der Google Suche verwendet werden, um die Ergebnisse von Rankbrain zu verbessern, macht die Technologie aus meiner Sicht extrem interessant für SEOs, im Gegensatz zu klassischen Text-Embeddings von OpenAI & Co.
Was ist Google RankBrain?
RankBrain, eingeführt im Jahr 2015, ist ein auf maschinellem Lernen basierendes System, das Google nutzt, um Suchanfragen zu verstehen und relevante Ergebnisse zu liefern. Über Jahre hinweg haben SEOs darüber gerätselt, was sich hinter dieser Technologie verbergen könnte. Google spricht selbst von einem „Deep-Learning-Rankingsystem“.
Was genau sich dahinter verbirgt, können wir uns nun selbst anschauen, denn Googles Cloud Dienst „Vertex AI Search“ nutzt dieselben RankBrain- und neuronalen Matching-Prozesse, um Abfrage- und Dokumenteneinbettungsvektoren zu generieren, die semantische Beziehungen abbilden und eine semantische Suche in Google-Qualität ermöglichen.
Im Grunde handelt es sich also um eine semantische Suche, die mit Text-Embeddings arbeitet, vergleichbar mit denen anderer Anbieter, wie beispielsweise OpenAI, nur mit dem Vorteil, dass dieses mit Nutzerdaten aus echten Suchvorgängen bei Google optimiert wurde.
Vertex AI Search ist optimiert für RAG
Der Hauptanwendungsbereich für diese Technologie ist natürlich die Retrieval-Augmented-Generation, kurz RAG. Beim RAG-Pattern kombiniert man große Sprachmodelle (LLMs) mit einem Informationsabruf aus externen Quellen, um einige der größten Einschränkungen von LLMs zu überwinden. Insbesondere der begrenzten Wissensbasis aufgrund des Trainingsdatensatzes, dem Mangel an relevantem Kontext aus Unternehmensdaten sowie veralteten Informationen im Sprachmodell lassen sich damit begegnen.
RAG heißt im Grunde, dass die KI eine Suchmaschine als Werkzeug benutzt, um Fragen besser beantworten zu können.
LLMs sind zwar intelligent genug, um Fragen zu verstehen und diese korrekt zu beantworten, wenn man ihnen die dazu notwendigen Informationen mitliefert, aber sie können ihre Leistung nicht voll ausschöpfen, wenn die Suche nicht die richtigen Dokumente findet, in denen die notwendigen Informationen stehen!
Seit dem RAG-basierte Ansätze in KI-Tools und Suchmaschinen wie perplexity oder auch ChatGPT Einzug halten, lässt sich gut nachvollziehen, dass die Effizienz eines RAG-Systems nahezu vollständig von der Suchqualität des Backend-Retrievalsystems, also der Suchmaschine dahinter abhängt und hier hat Google zweifelsohne die besten Daten.
In den letzten Monaten haben KI-Forscher und -Entwickler zahlreiche RAG-Technologien erforscht, darunter Text Chunking, Query Expansion, Hybrid Search, Knowledge Graphen, Reranking und andere. Aber fest steht: Ein LLM braucht die richtigen Daten, damit es keine Dinge erfinden muss, und du brauchst die beste Suchtechnologie, um die besten Daten zu bekommen.
Die semantische Suche mittels Deep Learning ist heutzutage für die meisten Suchmaschinen unverzichtbar geworden. Sie ermöglicht es Entwicklern, Systeme zu erstellen, die den Sinn von Suchanfragen verstehen können, anstatt nur nach Schlüsselwörtern zu suchen. Doch die meisten RAG-Systeme verwenden relativ einfache Ähnlichkeitssuchen in Vektordatenbanken, meist auf Basis der Text-Embeddings von Suchanfrage und Dokumenten-Chunks um Informationen zu finden. Dies führt jedoch oft zu qualitativ minderwertigen und irrelevanten Ergebnissen, insbesondere bei komplexeren Fragestellungen und Fachthemen.
Exkurs: Matching-Verfahren im RAG
Es gibt verschiedene Methoden, um die Ähnlichkeit zwischen zwei Vektoren zu berechnen, die in zahlreichen Anwendungen in der Künstlichen Intelligenz zum Einsatz kommen, zum Beispiel um zu erkennen, wie ähnlich sich zwei Sätze sind.
Die übliche Methode dafür ist die Cosine Similarity, zu Deutsch Kosinus-Ähnlichkeit. Sie hat aber einen Nachteil: Wenn zwei Vektoren sehr ähnlich sind (also fast in die gleiche Richtung zeigen), kann sie die kleinen Unterschiede nicht gut erfassen.
Google hat daher in einem Forschungspapier eine verbesserte Methode vorgeschlagen. Diese nennt sich Angular Distance (Winkelabstand). Sie kann auch bei sehr ähnlichen Vektoren die feinen Unterschiede besser erkennen.
Der Hauptunterschied ist, dass die Kosinus-Ähnlichkeit bei sehr ähnlichen Vektoren fast immer den Wert 1 ausgibt. Zudem ist die Kosinus-Ähnlichkeit beispielsweise effektiv bei hochdimensionalen Räumen, die typisch für Textanalysen sind, kann bei sehr kurzen Dokumenten oder Anfragen jedoch ziemlich unzuverlässig sein.
Die Angular Distance differenziert hier stärker und gibt unterschiedlichere Werte aus und ist insgesamt robuster bei kurzen Texten. Es ist also ein bisschen so, als ob man eine Lupe benutzt, um feine Unterschiede besser zu sehen. Das macht die Angular Distance gerade im Vergleich von Suchanfragen mit Dokumenten-Chunks in vielen Fällen genauer und nützlicher, allerdings auch rechenintensiver und weniger effizient bei hochdimensionalen Embedding-Vektoren. Für das Matching komplexer Suchanfragen mit längeren Dokumentenvektoren ist daher die Cosine Similarity oft die beste Wahl.
Es noch weitere Methoden, die ähnliche Verbesserungen bringen können. Die Wahl der besten Methode hängt vom konkreten Anwendungsfall ab. In der Regel findet zudem eine Vorverarbeitung der Texte (z.B. Stemming, Stopword-Entfernung) statt und es werden moderne Embedding-Techniken mit klassischen Relevanzkriterien (z.B. TF-IDF, BM25) kombiniert.
Semantische Suche ist mehr als nur Ähnlichkeitssuche von Texten
In wissenschaftlichen Publikationen und theoretischen Demonstration ist diese einfache Ähnlichkeitssuche sehr effektiv, da die Datensätze Millionen von Frage-Antwort-Paaren enthalten. In vielen realen RAG-Szenarien gibt es jedoch keine vorgefertigten Frage-Antwort- oder Anfrage-Kandidaten-Paare. Daher ist es wichtig, dass ein KI-Modell die Beziehung zwischen Anfragen und entsprechenden Antworten lernen und vorhersagen kann, um eine qualitativ hochwertige semantische Suche zu ermöglichen.
Google Search begann 2015 mit der Einführung der semantischen Suche, insbesondere durch das Deep-Learning-Rankingsystem RankBrain. Kurz darauf folgte das neuronale Matching, um die Genauigkeit der Dokumentensuche zu verbessern. Neuronales Matching ermöglicht es einer Suchmaschine, die Beziehungen zwischen den Absichten einer Anfrage und hochrelevanten Dokumenten zu erlernen. So kann die Suchmaschine den Kontext einer Anfrage erkennen, anstatt nur nach Ähnlichkeiten zu suchen.
Googles Vertex AI Search ist extrem spannend für SEOs, denn diese besondere Art des maschinellen Lernens hinsichtlich der Relevanz von Suchanfragen zu Dokumenten, genannt Rankbrain, bietet kein anderes Embedding-Modell.
Kai Spriestersbach
Neuronales Matching lernt die Beziehungen zwischen Anfragen und Dokumenten
Vertex AI Search nutzt tatsächlich die gleichen RankBrain- und neuronalen Matching-Prozesse, um Anfrage- und Dokument-Embeddings zu erzeugen, wie Googles Suche. Diese Vektoren bilden semantische Beziehungen ab und ermöglichen eine semantische Suche in Google-Qualität.
Über den Parameter task_type wird also der Anwendungszweck der Embeddings spezifiziert, um dem Modell zu helfen, Einbettungen mit höherer Qualität zu erstellen und diese Liste ist extrem interessant!
Es gibt sowohl Werte für Suchanfragen, als auch Dokumente einer Suche, sowie Texte für eine semantische Textähnlichkeit (Semantic Textual Similarity, STS). Andere NLP-Tasks wie Klassifizierung, Clustering und sogar die Beantwortung von Fragen werden offenbar jeweils mit speziell optimierten Embeddings versehen. Und sogar zur Faktenüberprüfung gibt es eigene Embeddings!
Das bietet kein anderer Anbieter!
Kai Spriestersbach
Anstatt selbst einen Weg zu finden, die Lücke zwischen Fragen und Antworten in einem RAG-System zu schließen, können Entwickler:innen ganz einfach die Vorteile der semantischen Suchtechnologie nutzen, die von Milliarden von Nutzer:innen über viele Jahre getestet wurde. Mit Vertex AI Search bietet Google nun eine vollständig verwaltete Plattform, die dieselben RankBrain- und Neural Matching-Prozesse nutzt, die Google Search seit Jahren einsetzt und die von Milliarden von Nutzern über viele Jahre hinweg trainiert und erprobt wurde.
Google ist führend bei semantischer Suche
Entgegen der weitverbreiteten Meinung ist die semantische Suche jedoch keine neue Erfindung, die erst mit dem Aufkommen von großen Sprachmodellen populär wurde. Tatsächlich ist sie das Ergebnis jahrelanger Forschung und Entwicklung.
Google war hier schon früh Vorreiter und traf bereits 2013 die strategische Entscheidung, in die Entwicklung eigener KI-Prozessoren zu investieren – den sogenannten Tensor Processing Units (TPUs). Diese TPUs wurden speziell dafür konzipiert, die nötige Rechenleistung für maschinelles Lernen und KI-Anwendungen bereitzustellen. Ihr Ursprung liegt laut Google jedoch in dem Ziel, das für eine praxistaugliche semantische Suche erforderliche Deep Learning zu ermöglichen.
Der erste TPU wurde 2015 in die Produktionsinfrastruktur von Google Search integriert. Diese erhebliche Investition hat dazu beigetragen, Kosten und Latenzzeiten zu reduzieren und so eine hochwertige semantische Suche für Milliarden von Nutzern zu realisieren. Google hat über Jahre hinweg in die Entwicklung leistungsfähiger Suchtechnologien investiert. So verarbeitet Google Search semantische Suchen mithilfe von ScaNN, einer der größten und schnellsten Vektorsuch-Infrastrukturen weltweit.
ScaNN kommt nicht nur bei Google Search zum Einsatz, sondern auch in vielen anderen Google-Diensten. Es findet blitzschnell relevante Dokumente und Inhalte, um Nutzern in Sekundenschnelle die benötigten Informationen zu liefern. Laut Benchmarks gehört ScaNN zu den führenden Algorithmen der Branche für die Abfrage-Verarbeitung.
Insgesamt stellen Googles bahnbrechende Suchtechnologien wie RankBrain, neuronales Matching, ScaNN und die TPU-Familie einige der wertvollsten technologischen Errungenschaften des letzten Jahrzehnts dar. Diese Technologien werden nun auch in Vertex AI Search genutzt, wodurch Entwickler Zugang zu semantischen Suchfunktionen in Google-Qualität erhalten – mit minimaler Latenz und zu vertretbaren Kosten.
Aber damit nicht genug…
Funktionen & Bedeutung für SEOs
Wenn wir unsere Inhalte und Webseiten für KI-basierte Suchmaschinen wie Perplexity, das neue bing und Googles SGE optimieren wollen, oder die Chance steigern wollen, dass Googles „AI Overviews“ Informationen von unserer Webseite zitiert, brauchen wir zunächst einmal irgendeinen Anhaltspunkt, ob wir in die richtige Richtung gehen. Wir müssen also die semantische Relevanz unserer Inhalte im Bezug auf Suchanfragen messen.
Vertex AI Search bietet uns hierfür quasi eine fertige hybride Suchmaschine an, die für jede Anfrage gleichzeitig sowohl eine Schlüsselwort- als auch eine semantische Suche auf Basis der Technologien durchführt, die Google auch in seiner eigenen Suche verwendet!
Kai Spriestersbach
Die Ergebnisse werden dann zusammengeführt und basierend auf ihren jeweiligen Bewertungen neu geordnet. Dadurch werden die Vorteile beider Suchansätze kombiniert und die Lücken, die jeder Ansatz für sich genommen lässt, geschlossen.
Ein weiterer wichtiger Aspekt ist das Verstehen und Umformulieren von Suchanfragen.
Nutzer tippen oft Suchanfragen falsch ein oder erinnern sich nicht genau an die richtigen Bezeichnungen. Hier kommen Techniken wie die Umformulierung und Erweiterung von Suchanfragen zum Einsatz.
Vertex AI Search bietet standardmäßig eine automatische, kontextbezogene Umformulierung und Erweiterung von Suchanfragen in den unterstützten Sprachen an.Dazu gehören neben der Wortstammbildung (Stemming) und Rechtschreibkorrektur auch das Hinzufügen verwandter Wörter und Synonyme sowie das Entfernen unwichtiger Wörter.
Diese Funktionen helfen der Suche dabei, die Intention hinter einer Suchanfrage besser zu verstehen und präzisere Ergebnisse zu liefern, selbst wenn die ursprüngliche Eingabe des Nutzers nicht optimal war, was insbesondere mit Blick auf die Suchmaschinenoptimierung eine wertvolle Informationsquelle darstellt.
Mit der Vertex AI Search bekommen wir nun ein Werkzeug direkt von Google an die Hand, mit dem wir ein besseres Verständnis der Nutzerintention hinter Suchanfragen erhalten, als auch überprüfen können, ob unsere Inhalte für Fragestellungen relevanter sind, als die unserer Mitbewerber!
Kai Spriestersbach
Bau Dir Dein eigenes Google!
Wir können nun also zu einem beliebigen Keyword einfach die Top 50 der rankenden Dokumente in einen eigenen Mini-Index direkt in der Google Cloud packen, um den ersten Teil von Googles zweistufigen Retrieval-Ansatz nachzubauen und können die selben Funktionen der API für die Extraktion und Erstellung von Inhalten verwenden, wie Google sie selbst in seiner Suche verwendet.
Nachdem wir also die Suche mit relevanten Dokumenten gefüttert haben, kann diese uns auch noch die wichtigsten Abschnitte herausfiltern, die dann als Grundlage für das KI-Sprachmodell dienen, um Antworten zu generieren oder Zusammenfassungen zu erstellen.
Das KI-SEO-Tool der Zukunft?
Umgehauen hat es mich, als ich gesehen habe, dass Googles Vertex AI Search gleich mehrere Möglichkeiten mitbringt, um besonders relevante Inhalte aus den gefundenen Dokumenten zu extrahieren.
Jedem SEO sollten diese Beispiele von Google das Wasser im Mund zusammen laufen lassen:
Jedes Suchergebnis kann folgende Inhaltstypen umfassen, die sich aus meiner Sicht perfekt für die Verwendung in SEO-Tools eignen:
1. Textauszug für die Snippet-Optimierung
Vertex AI Search erstellt automatisch einen kurzen Ausschnitt aus dem Dokument, der einen Überblick über den Inhalt gibt. Diese Auszüge werden ähnlich wie bei Google-Suchergebnissen unter jedem Treffer angezeigt und helfen Nutzern, die Relevanz einzuschätzen.
Hiermit erhalten SEOs quasi einen Einblick in den Mechanismus, der die automatisch generierten Snippets erstellt und können sehr viel gezielter für diesen optimieren!
2. Extrahierte Antwort für die Optimierung für „Featured Snippets“
Laut Googles eigener Dokumentation handelt es sich dabei um einen wörtlichen Textauszug aus dem Originaldokument, vergleichbar mit Google’s eigenen „Featured Snippets“. Diese Antworten stehen typischerweise am Anfang der Seite und bieten knappe, kontextbezogene Antworten auf Nutzeranfragen.
Hiermit lassen sich Texte also potentiell dahingehend optimieren, häufiger als Quelle für Googles Featured Snippets herangezogen zu werden!
3. Extrahierte Segmente für die Optimierung der „AI Summaries
In dieser Funktion liefert die Suche ausführlichere wörtliche Textauszüge aus einem Dokument, die mehr Kontext für KI-Sprachmodelle liefern als eine extrahierte Antwort. Diese Segmente können anschließend noch weiterverarbeitet werden, z.B. als Input für ein KI-Modell wie Gemini 1.5 um KI-generierte Zusammenfassungen zu erstellen, oder Vorschläge für die Verbesserung eines Dokumentes. Man könnte sogar den Inhalt direkt per KI verbessern, wenn man eine menschliche Qualitätssicherung nachschaltet.
Hiermit lassen sich wahrscheinlich nicht nur die „AI Summaries“ gezielt optimieren, sondern die Verbesserungen der Inhalte könnte auch zu einer Verbesserung des Rankings in der organischen Suche bei tragen und dabei sowohl die Nutzerzufriedenheit, als auch die Konversionsraten positiv beeinflussen.
Die Informationsextraktion lässt sich so konfigurieren, wie sie (mutmaßlich) auch in Googles Suche zum Einsatz kommt. So lässt sich beispielsweise die Anzahl der zu extrahierenden Textabschnitte pro Dokument festlegen, benachbarte Abschnitte für zusätzlichen Kontext einbeziehen und sogar die relevantesten Segmente auswählen oder weniger wichtige herausfiltern.
Kai Spriestersbach
Bonus: Dokumenten Handling like you are Google!!
Wie jeder SEO weiß, ist es für eine Suchmaschine wichtig, die Struktur jedes Dokuments zu verstehen und sie angemessen zu verarbeiten, bevor die eigentliche Informationssuche und -bewertung stattfindet. Wer schon einmal selbst eine Suchmaschine oder ein RAG-System gebaut hat, weiß wie schwierig es sein kann, PDFs, HTML-Dateien und andere Dokumente so zu parsen und in Häppchen aufzuteilen, dass diese die Antworten der KI wirklich verbessert.
Vertex AI Search nimmt einem diese mühsame Arbeit komplett ab und geht dabei, wie Googles Suche, über die reine Textextraktion hinaus. Der Prä-Prozessor erkennt dabei sogar strukturelle und inhaltliche Elemente wie Überschriften, Abschnitte, Absätze und Tabellen, die die Organisation und Hierarchie verschiedener Dokumente definieren.
Diese Informationen werden genutzt, um die Dokumente intelligent in kleinere, abrufbare Segmente (Chunks) zu unterteilen. Dabei wird die Kohärenz semantischer Elemente bewahrt und Störfaktoren minimiert. Diese Methode ist effektiver als die weit verbreitete einfache Textsegmentierung, die oft die semantische Kohärenz nicht aufrechterhält.
Dieses Feature alleine hat mir nächtelang Kopfzerbrechen gemacht, als ich überlegt hatte, wie man eine KI-basierte Suche bauen würde.
Killer-Feature: Einblicke in den Knowledge Graph
Wir sind noch nicht am Ende. Denn sogar die Entitäts-Fetischisten kommen auf ihre Kosten! Google liefert, sozusagen als Sahne auf der Torte noch eine automatische Dokumenten- und Suchanfragen-Annotation mit Wissensgraphen mit.
Falls Du mit diesem Begriff nichts anfangen kannst: Ein Wissensgraph, auf englisch Knowledge Graph findet Informationen, indem die Beziehungen zwischen Entitäten in einem Graphen genutzt werden.
Google setzt Knowledge Graphen bereits seit 2012 in der Google-Suche ein und hat sogar 2013 für 30 Millionen das Unternehmen Wavii gekauft, um seinen Knowledge Graph zu verbessern. Dieser hilft Google dabei, Suchanfragen mehr Kontext zu geben, indem sie Informationen über Dinge, Personen oder Orte liefern, die Google bereits kennt.
Die Google-Suche nutzt Wissensgraphen, um auf ihr bestehendes Wissen und Verständnis des Webs zuzugreifen und Ergebnisse zu finden, die mit der Suchanfrage des Nutzers in Verbindung stehen, wie etwa Sehenswürdigkeiten, Prominente, Städte, geografische Merkmale, Filme und vieles mehr.
Wenn beispielsweise ein Dokument oder eine Suchanfrage das Stichwort „Buffett“ enthält, ist es sehr wahrscheinlich, dass sich dieses Keyword auf Warren Buffett bezieht.
Vertex AI Search annotiert Dokumente automatisch mit zusätzlichen Informationen über ihn aus dem Wissensgraphen der Google-Suche und fügt der ursprünglichen Anfrage verwandte Keywords. Dies erhöht die Wahrscheinlichkeit, dieses Dokument auch mit anderen Stichwörtern oder Themen zu finden, die mit ihm in Verbindung stehen.
Vertex AI Search identifiziert automatisch relevante Entitäten bei Anfragen sowie der Verarbeitung oder Zusammenfassung von Dokumenten mithilfe von Wissensgraphen und fügt diese den Annotationen hinzu, welche sich anschließend in strukturierte Daten überführen und der Seite zur semantischen Auszeichnung oder für die interne Verlinkung nutzen lassen.
Kai Spriestersbach
AI Content Advanced: Grounding via Google Search
Nach der Sahne auf der Torte, hier noch die Kirsche: Automatisiert generierte Texte bieten immer die Gefahr von Halluzinationen und Falschaussagen. Um die Korrektheit generierter Texte zu überprüfen lässt sich Googles Grounding API daher mit Google Search für alle Gemini-Modelle verwenden, um quellenbasiert Texte zu erstellen.
https://www.afaik.de/googles-grounding-api/
Dabei greift Googles Sprachmodell Gemini im Hintergrund auf die Google-Suche zu und erzeugt eine Ausgabe, die mit den relevanten Suchergebnissen „gegrounded“ ist, also deren Fakten und Aussagen auf den Informationen dieser Webseiten basieren.
Damit lassen sich Modelle mit aktuellem Wissen aus dem Internet verknüpfen, oder man nutzt eine Verankerung mittels eigener Daten.
Das beste ist: Hierbei lässt sich das Modell mit persönlichen Daten aus dem Vertex AI Search-Datenspeicher kombinieren. Damit kannst Du also Deine Unternehmensdaten, FAQ-Artikel, Blogbeiträge oder redaktionellen Inhalte quasi als Quellen für die generierung korrekter Antworten hinterlegen!
Diese Funktion befindet sich derzeit jedoch noch in der Vorschauphase.
Mein Fazit und Ausblick
Jetzt denkst du vielleicht, wow das ist eine ganze Menge. Und wenn du – wie ich – vorhast, diese Technologien für deine eigene SEO-Arbeit zu nutzen, hast du Recht.
Um derartig fortschrittliche Suchtechnologien zu implementieren, die eine mit der Google-Suche vergleichbare Suchqualität liefern, egal ob du sie GenAI verwendest oder nicht, bräuchtest du Jahre der Entwicklung und die Einstellung einer Vielzahl von Datenwissenschaftlern und Ingenieuren mit Spezialkenntnissen in ML, Suchmaschinen, DevOps und MLOps.
Oder einfach einen Account bei Googles Vertex AI Cloud.
Kai Spriestersbach
Ich bin, wie du vielleicht beim Lesen gemerkt hast, ziemlich gehyped, denn für SEOs eröffnet die Verfügbarkeit von Googles bislang geheimen Technologien wie RankBrain und dem Knowledge Graphen über Vertex AI vollkommen neue Möglichkeiten für Innovationen im Bereich der Suchmaschinenoptimierung.
Dazu liefert Google quasi die Technologie zur Verbesserung und Erstellung von Inhalte mit und bietet mit der Grounding API sogar endlich die Möglichkeit, die Korrektheit der generierten Aussagen zu verbessern.
Ich bin extrem gespannt, welche Toolanbieter zuerst von den neuen Möglichkeiten gebrauch machen werden. Meinen eigenen KI-SEO-Stack werde ich vollständig auf Vertex AI umstellen. Leider ist die Dokumentation aktuell noch ziemlich inkonsistent und weist große Lücken auf.
Ian P. McCarthy, Timothy R. Hannigan und André Spicer haben sich in einem sehr guten Artikel im Harvard Business Review dem Thema Halluzinationen von Chatbots und großen Sprachmodellen angenommen und das Ganze mal aus Sicht des Risikomanagements von Unternehmen bewertet.
Sie verwenden für ungenaue und unwahre Inhalte von Chatbots, die von Menschen unkritisch für Aufgaben verwendet werden den Begriff „Botshit“ und machen zu Recht darauf aufmerksam, dass dieser erhebliche Risiken für Unternehmen darstellen kann. Dazu gehören Reputationsschäden, Fehlentscheidungen, rechtliche Haftung, wirtschaftliche Verluste und sogar Gefährdung der menschlichen Sicherheit.
Auf absehbare Zeit ist es unwahrscheinlich, dass Chatbots verschwinden werden und auch wenn RAG und Grounding-Techniken die Assistenten zuverlässiger machen und die KI-Forscherinnen und -Forscher mit Hochdruck an zuverlässigeren Modellen arbeitet, müssen wir uns die Frage stellen, wie Unternehmen diese Risiken managen und gleichzeitig die Vorteile dieser vielversprechenden neuen Werkzeuge nutzen können.
Die Autoren schlagen vor, basierend auf ihrer Forschung zwei Schlüsselfragen zu stellen:
Wie wichtig ist die Richtigkeit der Chatbot-Antwort für eine bestimmte Aufgabe?
Wie schwierig ist es, die Richtigkeit der Chatbot-Antwort zu überprüfen?
Anhand der Antworten auf diese Fragen können Unternehmen die mit einer bestimmten Aufgabe verbundenen Risiken besser identifizieren und erfolgreich mindern.
Die Autoren erläutern verschiedene Vorfälle, bei denen der unkritische Einsatz von Chatbots zu Problemen geführt hat. Zum Beispiel führte ein Fehler des Google-Chatbots Bard zu einem massiven Kurssturz der Alphabet-Aktie. In einem anderen Fall wurden zwei Anwälte mit Geldstrafen belegt, weil sie von ChatGPT generierte fiktive Rechtsfälle eingereicht hatten.
Um die Risiken von „Botshit“ zu managen, schlagen die Autoren vier Kategorien von Aufgaben vor, bei denen Chatbots eingesetzt werden können:
Authentifizierte Aufgaben: Hier ist die Richtigkeit entscheidend, aber schwer zu überprüfen. Das größte Risiko ist eine falsche Kalibrierung. Dies kann durch sorgfältige Überprüfung und Kalibrierung des Chatbot-Modells gemindert werden.
Erweiterte Aufgaben: Die Genauigkeit ist weniger wichtig und schwer zu überprüfen. Das Hauptrisiko ist Unwissenheit. Dies kann durch den Einsatz menschlicher Experten zur Ergänzung der Chatbot-Antworten gemindert werden.
Automatisierte Aufgaben: Genauigkeit ist wichtig und leicht zu überprüfen. Das Risiko liegt in der übermäßigen Routinisierung. Dies kann durch regelmäßige menschliche Überprüfung gemindert werden.
Autonome Aufgaben: Genauigkeit ist weniger wichtig und leicht zu überprüfen. Das Risiko besteht in einer „Black Box“. Dies kann durch Einschränkung des Einsatzbereichs und strenge Leitplanken gemindert werden.
Zusammenfassend lässt sich sagen, dass Chatbots und andere KI-Werkzeuge ein großes Potenzial haben, viele Arbeitsprozesse erheblich zu verbessern. Wie bei jeder wichtigen neuen Technologie bringen sie jedoch auch Risiken mit sich. Bei sorgfältigem Management können diese Risiken eingedämmt werden, während gleichzeitig die Vorteile genutzt werden können.
Ich finde den Artikel sehr lesenswert, insbesondere weil die Autoren nicht so tun, als ließen sich Halluzinationen technisch lösen oder ignorieren, sondern liefern für unterschiedliche Aufgaben differenzierte Ansätze für eine Mitigierung der Risiken.