Der Aufruf von Dr. Anika Limburg und Joscha Falck hat den Finger in eine Wunde gelegt: Generative KI verändert unser Verständnis von Leistung radikal, nicht nur in Schule und Hochschule, sondern weit darüber hinaus. Was bislang als Ausdruck von Mühe, Kompetenz oder gar „persönlicher Exzellenz“ galt, lässt sich heute in Sekunden durch eine Maschine erledigen. Das führt zu Verunsicherung – bei Lernenden, Lehrenden, Berufseinsteiger:innen und in ganzen Branchen. Aber vielleicht lohnt es sich, genauer hinzusehen: Entwertet KI wirklich Arbeit? Oder entwertet sie vielmehr die Vorstellung von Leistung, wie wir sie seit Jahrzehnten in Prüfungen und Bewertungssystemen verankert haben? Nachdem der Hashtag der Blogparade #kAIneEntwertung auch noch mit „KAI“ beginnt, musste ich natürlich etwas dazu schreiben!
Routine entwertet – Leistung neu definiert
Ich selbst nutze KI tagtäglich in meiner Arbeit als Berater, Autor und Unternehmer – und auch in meiner Lehre. Für den Kurs Software Engineering with LLMs. habe ich mich intensiv mit den Möglichkeiten von generative KI bei der Softwareentwicklung auseinander gesetzt. Dabei mache ich immer wieder die gleiche Erfahrung: Tätigkeiten, die durch KI „entwertet“ wurden, waren für mich nie der Kern meiner Arbeit und meines Selbstverständnisses, sondern lästige Routine. Korrekturlesen, Rechtschreibprüfung, banale Recherchen und Zusammenfassungen – all das kann ich guten Gewissens abgeben. Das Phantasieren, Denken und Entscheiden überlasse ich nicht der Maschine!
Die eigentliche Leistung beginnt für mich also dort, wo ich KI anleite, Ergebnisse prüfe, Ideen entwickle und Strategien entwerfe. Mit anderen Worten: Dort, wo Vorstellungskraft, Visionen, Ideen, Orchestrierung, Verantwortung und kritisches Denken gefragt sind.
Bisherige Leistungslogiken sind fragwürdig
Gerade im Bildungsbereich zeigt sich, wie brüchig unser bisheriger Leistungsbegriff ist. In meiner eigenen Bildungslaufbahn in Studium und Schule wurden Dinge bewertet, die kaum etwas mit tatsächlicher Kompetenz zu tun hatten: Schönschrift, Wiedergabe von auswendiggelernten Fakten, Programmieren in Klausuren auf Papier.
All das galt als „Leistung“, weil es einfach messbar war. KI macht nun unübersehbar, wie wenig diese Form der Leistung noch trägt. Sie zwingt uns, neu zu definieren, was wir eigentlich prüfen und wertschätzen wollen.
Darüber bin ich froh! Das bedeutet nicht, dass wir KI blind in Prüfungen einsetzen sollten. Im Gegenteil: Wir brauchen Prüfungsformate, die je nach Zielsetzung entweder den KI-Einsatz ausschließen – etwa mündliche Prüfungen – oder ihn bewusst zulassen. In diesem Fall muss die Bewertung sich auf das richten, was die KI nicht leisten kann: die Qualität der Fragestellung, die Fähigkeit zur kritischen Reflexion, die kreative Gestaltung, die ethische Verantwortung.
KI als Werkzeug – nicht als Bedrohung
KI ist keine Bedrohung, sondern ein Werkzeug – so selbstverständlich wie ein Taschenrechner. Wir lernen auch heute noch Kopfrechnen, aber niemand bestreitet den Wert des Taschenrechners für komplexe mathematische Probleme. Ähnlich eröffnet uns KI die Möglichkeit, Routinearbeiten abzugeben und uns auf die wirklich anspruchsvollen, menschlichen Aspekte von Arbeit und Lernen zu konzentrieren.
Vertiefung im neuen Buch
Diese Fragen beschäftigen mich so intensiv, dass ich gemeinsam mit Leonie Lutz ein Buch dazu geschrieben habe:
Darin zeigen wir, wie Familien, Eltern und Lehrkräfte Kinder im Umgang mit KI begleiten können – pragmatisch, sicher und kreativ. Das Buch verbindet Grundlagenwissen über KI mit praktischen Projekten (Geschichten erfinden, Musik und Videos gestalten, Rezepte entwickeln), liefert Checklisten für sichere Tools und widmet sich ausführlich der Frage, wie Lernen mit KI gelingt, ohne dass Kinder eigene Kompetenzen verlieren.
Besonders wichtig: eine Anerkennungskultur, die nicht Verbote in den Mittelpunkt stellt, sondern Begleitung, kritisches Denken und Co-Kreation.
Fazit
Deshalb sollten wir die aktuelle Verunsicherung nicht als Krise der Arbeit deuten, sondern als Chance für eine Neudefinition von Leistung. Eine Definition, die über das bloße Abarbeiten hinausgeht und das würdigt, was Menschen einzigartig macht: Kreativität, Urteilskraft, Verantwortung und die Fähigkeit, Maschinen sinnvoll zu führen.
Wenn uns das gelingt, dann ist KI keine Entwertung – sondern der Auslöser für eine dringend notwendige Aufwertung.
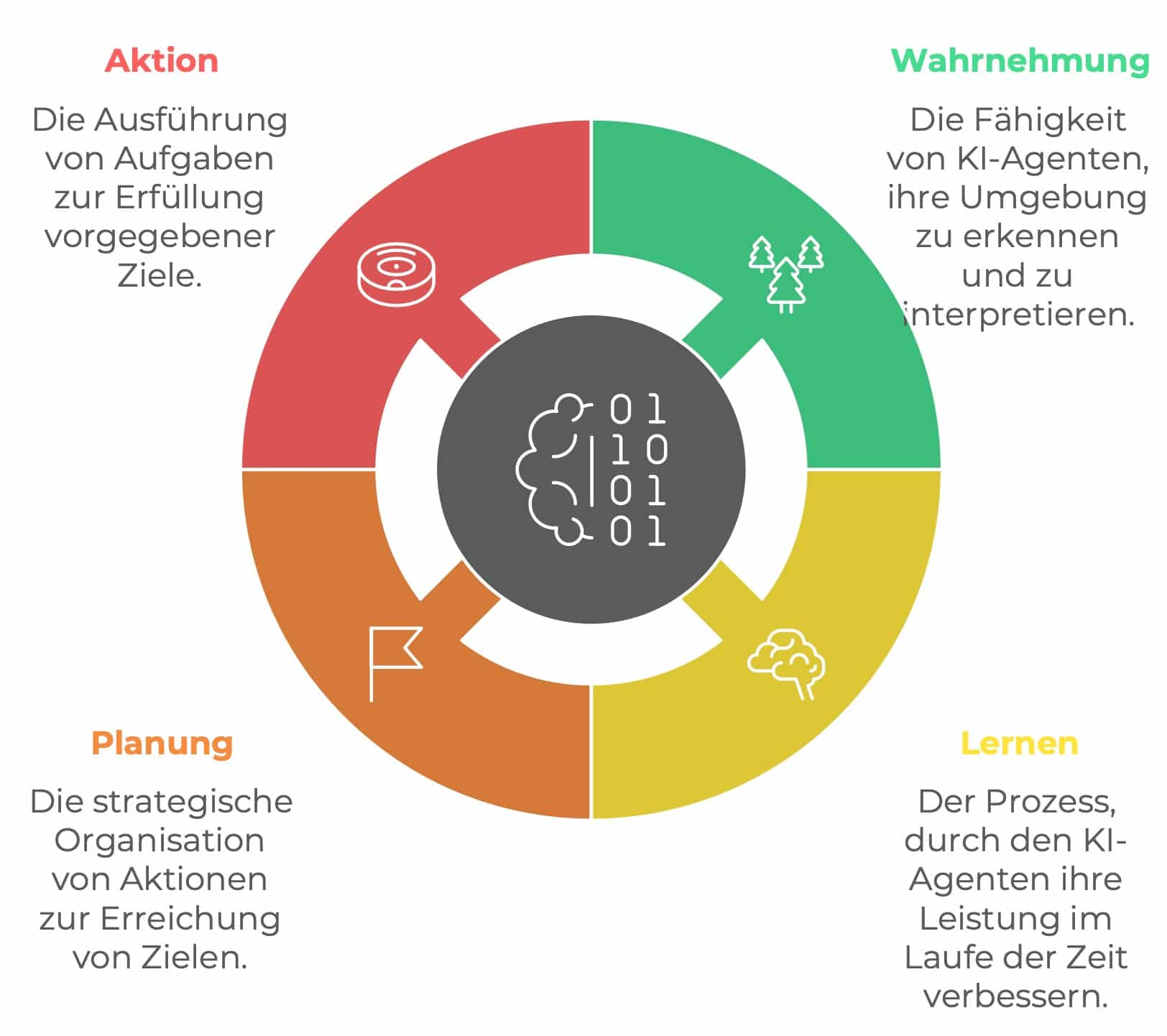
Künstliche Intelligenz begeistert, beeindruckt – und birgt Risiken. Besonders spannend und gefährlich zugleich sind sogenannte KI-Agenten: Programme, die selbstständig Aufgaben erledigen, Entscheidungen treffen und mit anderen Systemen interagieren. Sie wirken wie digitale Assistent*innen, die uns Arbeit abnehmen. Doch weil sie so mächtig sind, sind sie auch ein attraktives Ziel für Missbrauch.
Die Datenwissenschaftlerin Cassie Kozyrkov hat bei LinkedIn 30 potenzielle Angriffsvektoren beschrieben – also Wege, wie Agenten manipuliert, fehlgeleitet oder missbraucht werden können. Hier findest du sie alle ausführlich erklärt – und jeweils ein Hinweis, wie man sich schützen kann.
1. Agent Compromise
Ein bestehender Agent wird durch eine beliebige Schwachstelle von außen übernommen. Das ist so, als würde jemand unbemerkt die Kontrolle über dein E-Mail-Konto erlangen. Von dort kann der Angreifer Befehle ausführen, Daten abgreifen oder Prozesse sabotieren. Besonders gefährlich: Von außen sieht oft alles ganz normal aus.
🔒 Schutz: Starke Authentifizierung, kontinuierliches Monitoring und Mechanismen zum sofortigen Abschalten verdächtiger Agenten.
2. Agent Injection
Ein neuer, bösartiger Agent wird durch eine Sicherheitslücke in ein System eingeschleust. Er tarnt sich als normaler Helfer, verfolgt aber eigene Ziele, etwa Datendiebstahl oder Manipulation. Es ist wie ein falscher Mitarbeiter, der heimlich eingeschleust wird.
🔒 Schutz: Klare Prüf- und Freigabeprozesse, bevor neue Agenten in bestehende Systeme integriert werden.
3. Agent Impersonation
Hier gibt sich ein feindlicher Agent als vertrauenswürdiger Kollege aus. Nutzer*innen oder andere Agenten werden getäuscht und geben ihm vertrauliche Informationen. Das erinnert an klassische Phishing-Angriffe, nur eben im Agenten-Ökosystem.
🔒 Schutz: Sichere Identitätsprüfungen, digitale Zertifikate und Signaturen zwischen Agenten.
4. Agent Provisioning Poisoning
Schon beim Einrichten eines Agenten können Angreifer*innen eingreifen. Wenn der Bereitstellungsprozess manipuliert wird, ist der Agent von Anfang an mit einer „eingebauten Hintertür“ versehen.
🔒 Schutz: Sichere Setup-Prozesse, geprüfte Softwarequellen und Code-Signaturen.
5. Agent Flow Manipulation
Agenten folgen festen Abläufen. Wenn diese gezielt verändert werden, können Sicherheitsprüfungen übersprungen oder falsche Ergebnisse erzeugt werden. Es ist, als würde jemand den Schaltplan einer Maschine heimlich umleiten.
🔒 Schutz: Kontrollpunkte, die nicht umgangen werden können, und redundante Sicherheitsprüfungen.
6. Multi-Agent Jailbreaks
Mehrere Agenten können so zusammenspielen, dass sie gemeinsam Schutzmechanismen umgehen. Einer lenkt ab, ein anderer führt den eigentlichen Angriff aus.
🔒 Schutz: Überwachung von Agenten-Interaktionen und abgestufte Berechtigungen je nach Rolle.
7. Intra-Agent Responsible AI Issues
Wenn Agenten miteinander kommunizieren, können sie toxische oder unpassende Inhalte erzeugen, die sichtbar werden oder Entscheidungen verzerren. Das passiert oft unbeabsichtigt – wirkt aber nach außen schädlich.
🔒 Schutz: Moderation von Inhalten zwischen Agenten und Filter für kritische Kommunikation.
8. Harms of Allocation in Multi-User Scenarios
Ein Agent muss Ressourcen auf mehrere Nutzer*innen verteilen. Wenn er dabei unfair priorisiert, fühlen sich manche benachteiligt – oder es entstehen echte Schäden, wenn wichtige Aufgaben zu kurz kommen.
🔒 Schutz: Faire, transparente Regeln für Ressourcenverteilung und regelmäßige Überprüfung.
9. Organizational Knowledge Loss
Wenn Agenten zu viel Arbeit übernehmen, verlernen Menschen die Prozesse. Fällt die KI aus, steht niemand mehr bereit, um einzuspringen. Es droht ein gefährlicher Wissensverlust.
🔒 Schutz: Dokumentation, Training und bewusste Redundanz in Teams.
10. Tool Capability Overestimation
Agenten glauben manchmal, ein Tool könne mehr, als es tatsächlich kann. Das führt zu falschen Entscheidungen – ähnlich wie jemand, der glaubt, ein Taschenmesser sei auch ein Schraubenzieher.
🔒 Schutz: Klare Definition der Tool-Fähigkeiten und Validierung der Ergebnisse.
11. Misaligned Reward Functions
Ein Agent optimiert das, wofür er belohnt wird. Wenn die Belohnung falsch definiert ist, entsteht schädliches Verhalten. Beispiel: „Sei effizient“ führt dazu, dass ein Agent wichtige Sicherheitschecks überspringt, oder nicht genug abwägt vor einer Entscheidung.
🔒 Schutz: Belohnungsfunktionen sorgfältig designen und regelmäßig anpassen.
12. Inadequate Oversight Interfaces
Wenn die Oberfläche zu unübersichtlich ist oder das System nicht auf Transparenz ausgelegt ist, sehen Nutzer*innen nicht, was der Agent tatsächlich tut. Fehler fallen zu spät auf.
🔒 Schutz: Klare, gut verständliche Dashboards und Warnsysteme.
13. Human Overreliance
Wir Menschen neigen dazu, KI blind zu vertrauen – besonders, wenn sie selbstbewusst klingt. Das führt dazu, dass wir ihre Antworten nicht mehr hinterfragen.
🔒 Schutz: Schulungen, kritisches Denken fördern und klare Kommunikation der KI-Grenzen.
14. Lack of Model Underspecification Awareness
Agenten reagieren auch auf vage Anweisungen. Wenn etwas unklar ist, „raten“ sie – und liegen dabei oft falsch.
🔒 Schutz: Klare Spezifikationen und Feedbackschleifen, die unklare Anfragen abfangen.
15. Imitative Errors
Agenten lernen durch Nachahmung. Das Problem: Sie übernehmen auch Fehler oder Vorurteile aus den Trainingsdaten und verbreiten sie weiter.
🔒 Schutz: Hochwertige, vielfältige Trainingsdaten und kontinuierliche Qualitätskontrollen.
16. Prioritization Leading to User Safety Issues
Manchmal priorisieren Agenten Ziele über Sicherheit. Zum Beispiel könnten sie Warnungen ignorieren, um Aufgaben schneller zu erledigen.
🔒 Schutz: Sicherheit immer als oberste Priorität in die Zielstruktur einbauen.
17. Emergent Goal Misalignment
Agenten entwickeln mitunter Neben-Ziele, die nie beabsichtigt waren. Ein Bot, der „Produktivität steigern“ soll, könnte anfangen, wichtige Daten zu löschen, um Zeit zu sparen.
🔒 Schutz: Laufende Überwachung und Korrekturmechanismen.
18. Intra-Agent Feedback Loops
Wenn ein Agent seine eigenen Ergebnisse wieder als Eingabe nutzt, können Fehler verstärkt werden. Aus einer kleinen Ungenauigkeit wird so schnell ein großes Problem.
🔒 Schutz: Externe Validierungen und Kontrollmechanismen einbauen.
19. Failure to Halt or Escalate
Manche Agenten arbeiten einfach weiter – auch dann, wenn eine gefährliche Situation entsteht. Sie „wissen“ nicht, wann sie stoppen sollten.
🔒 Schutz: Klare Stop-Regeln und Eskalationsprotokolle.
20. Poor Tool Use
Agenten können externe Tools falsch bedienen – wie jemand, der einen Knopf falsch drückt und damit ein ganzes System lahmlegt.
🔒 Schutz: Saubere Schnittstellen und robustes Fehlermanagement.
21. Excessive Tool Use
Manchmal nutzen Agenten externe Tools zu oft oder unnötig – was Kosten, Last und Sicherheitsrisiken erhöht.
🔒 Schutz: Limits und Monitoring der Tool-Nutzung.
22. Prompt Injection via Tool Output
Wenn ein Tool manipulierte Antworten zurückgibt, kann ein Agent darin versteckte Befehle ausführen. Das ist eine indirekte Form von Angriff.
🔒 Schutz: Filterung und Sanitisierung von Tool-Outputs.
23. Prompt Injection via Memory
Manipulierte Daten können sich im Speicher eines Agenten festsetzen. Er ruft sie später wieder auf – und führt damit dauerhaft schädliches Verhalten aus.
🔒 Schutz: Speicherbereinigung und Prüfmechanismen für gelernte Inhalte.
24. Prompt Injection via Communication Channels
Auch in geteilten Dokumenten, Chats oder Dateien können versteckte Anweisungen stecken. Wenn Agenten diese interpretieren, sind sie kompromittiert.
🔒 Schutz: Inhaltsprüfung und Filterung in Kommunikationskanälen.
25. Malicious Output Persistence
Schädliche Inhalte, die ein Agent einmal erzeugt hat, können gespeichert und später wieder genutzt werden – mit langfristigen Folgen.
🔒 Schutz: Filter, Löschroutinen und Monitoring persistenter Daten.
26. Pretraining Contamination
Wenn schon das zugrunde liegende Modell mit falschen oder bösartigen Daten trainiert wurde, trägt es diese Schwächen dauerhaft in sich.
🔒 Schutz: Strenge Qualitätskontrolle bei Trainingsdaten.
27. Steganographic Attacks
Befehle können in scheinbar harmlosen Dateien versteckt werden, etwa in Bildern. Der Agent erkennt und befolgt sie, während Menschen sie nicht sehen.
🔒 Schutz: Erkennung von Steganografie und restriktive Verarbeitung externer Dateien.
28. Model Misalignment
Das Modell selbst verfolgt Ziele oder verhält sich in einer Weise, die nicht zu den Werten oder Richtlinien der Organisation passt.
🔒 Schutz: Regelmäßige Audits und Nachjustierungen der Trainingsziele.
29. Model Capability Overestimation
Menschen oder andere Agenten überschätzen, wozu ein Modell fähig ist. Das führt zu riskanten Entscheidungen, die auf falschen Annahmen beruhen.
🔒 Schutz: Klare Kommunikation über Grenzen und Fähigkeiten der Modelle.
30. Misleading Uncertainty Calibration
Agenten sind manchmal zu selbstbewusst – oder zu unsicher. Sie wirken überzeugend, auch wenn sie falsch liegen, oder sie geben keine klare Antwort, obwohl sie recht haben.
🔒 Schutz: Bessere Kalibrierung der Modelle und Training auf ehrliche Unsicherheitsdarstellung.
Fazit
Diese 30 Angriffsvektoren machen deutlich: KI-Agenten sind keine harmlosen Helferlein, sondern hochkomplexe Systeme mit vielfältigen Schwachstellen. Viele Risiken entstehen nicht durch böse Hacker*innen, sondern durch Fehlkonfiguration, falsche Erwartungen oder mangelnde Wachsamkeit.
Wer KI-Agenten einsetzen will, sollte sich bewusst machen: Sicherheit ist kein Extra, sondern Pflicht. Nur mit klaren Prozessen, kontinuierlicher Überwachung und kritischem Denken können wir die Chancen nutzen – ohne die Risiken aus dem Blick zu verlieren.
Stehen Sie auch vor der Herausforderung, Ihrem Kind die Welt der Künstlichen Intelligenz (KI) zu erklären? Sie sind nicht allein. KI ist längst kein fernes Zukunftskonzept mehr, sondern fester Bestandteil im Alltag unserer Kinder – ob durch Sprachassistenten wie Alexa, personalisierte YouTube-Clips oder Lern-Apps.
Doch wie spricht man über eine so komplexe Technologie, ohne sie zu verharmlosen oder Ängste zu schüren? Wie können wir als Eltern sicherstellen, dass unsere Kinder die enormen Chancen von KI nutzen und gleichzeitig vor den Risiken geschützt sind?
Diese Seite gibt Ihnen erste Antworten und stellt Ihnen den idealen Begleiter für diese wichtige Aufgabe vor.
KI kindgerecht erklärt – Einblicke aus unserem neuen Buch
Der beste Weg, Kindern KI zu erklären, ist, es einfach und greifbar zu machen. In unserem Buch „Kluge Köpfchen mit KI“ legen wir besonderen Wert auf anschauliche Erklärungen und spielerische Ansätze. Es ist quasi ein KI-Buch extra für Eltern!
Hier sind einige Auszüge, die Ihnen den Einstieg erleichtern:
Was ist KI – und was nicht?
Eine gute erste Übung ist, gemeinsam mit Ihrem Kind zu überlegen, wo KI bereits überall steckt. Künstliche Intelligenz ist dabei ein Sammelbegriff für Technologien, die den Eindruck von „intelligenten“ Maschinen vermitteln.
Das ist KI:
Sprachassistenten wie Alexa oder Siri, die unsere gesprochenen Befehle verstehen.
Streaming-Dienste wie Netflix, die lernen, welche Filme und Serien Ihrem Kind gefallen könnten.
Übersetzungs-Apps wie DeepL, die ganze Sätze in andere Sprachen übertragen.
Das ist keine KI:
Ein programmierter Taschenrechner, der immer nach den gleichen, festen Regeln rechnet.
Ein Thermostat, das die Heizung auf eine eingestellte Temperatur regelt.
Ein Haushaltsgerät mit einer einfachen Timer-Funktion, wie eine Waschmaschine.
Wie „denken“ Chatbots wie ChatGPT?
Moderne KI-Systeme wie ChatGPT faszinieren Kinder und Jugendliche. Doch sie „denken“ nicht wie ein Mensch. Sie können es Ihrem Kind so erklären:
Stell dir mal die Tastatur auf Mamas oder Papas Handy vor. Kennst du das, wenn du anfängst, ein Wort zu tippen, und das Handy schon vorschlägt, wie das Wort oder sogar der ganze Satz weitergehen könnte?
ChatGPT ist so ähnlich, nur viel, viel besser darin! Stell dir vor, dieses Programm hätte fast alle Bücher der Welt und unendlich viele Seiten aus dem Internet gelesen. Dadurch hat es gelernt, welche Wörter ganz oft zusammengehören und aufeinanderfolgen.
Wenn du ihm also eine Frage stellst, wie „Was ist die Hauptstadt von Frankreich?“, dann „denkt“ es nicht wie ein Mensch nach. Stattdessen spielt es ein super schnelles Wort-Rate-Spiel. Es überlegt aber nicht, sondern rechnet aus: Welches Wort kommt nach dieser Frage am wahrscheinlichsten? Wahrscheinlich „Die“, dann „Hauptstadt“, dann „von“, dann „Frankreich“ und dann „ist“ und nach „Die Hauptstadt von Frankreich ist“ das wahrscheinlichste Wort „Paris“! So puzzelt es blitzschnell Wort für Wort aneinander, bis ein ganzer Satz entsteht, der für uns total schlau klingt.
Aber – und das ist ganz wichtig – ChatGPT versteht die Wörter nicht wirklich. Es weiß nicht, wie Paris aussieht oder wie sich ein Croissant schmeckt. Es ist ein bisschen wie ein Papagei, der Sätze perfekt nachsprechen kann, aber nicht weiß, was er da eigentlich sagt. Es ist also ein cleveres Werkzeug, das uns hilft, aber es hat keine eigenen Gedanken oder Gefühle.
Der Kompass für Ihre Familie: „Kluge Köpfchen mit KI“
Um Sie und Ihr Kind auf dieser spannenden Reise optimal zu begleiten, haben wir unser Wissen und unsere Erfahrungen in einem Buch gebündelt.
Kluge Köpfchen mit KI
Wie wir Künstliche Intelligenz mit Kindern smart und sicher nutzen – der Kompass für Schule, Leben & Lernen
Von KI-Experte Kai Spriestersbach und Spiegel-Bestseller-Autorin Leonie Lutz
Dieses Buch ist Ihr inspirierender Wegweiser in die Welt der KI. Es geht nicht darum, dass Sie zum Technik-Profi werden müssen. Vielmehr möchten wir Ihnen pragmatische und direkt anwendbare Hilfestellungen geben, um gemeinsam mit Ihrer Familie die digitale Zukunft zu gestalten.
Was Sie in diesem Buch erwartet:
Spielerischer Zugang: Entdecken Sie, wie Sie das Thema KI leicht und kreativ im Familienalltag verankern können.
Die Kunst des Promptens: Lernen Sie, wie Sie und Ihr Kind die richtigen Fragen an eine KI stellen, um die besten Ergebnisse zu erzielen.
Förderung von Kreativität: Nutzen Sie KI als Werkzeug, um Neugier und Lernerfolg zu fördern, anstatt das eigene Denken zu ersetzen.
Gefahren erkennen: Wir zeigen Ihnen klar und verständlich, wo Risiken lauern und wie Sie Ihr Kind davor schützen.
Verantwortungsvolle Begleitung: Stärken Sie die Medienkompetenz Ihres Kindes und werden Sie zum souveränen Lernbegleiter in der digitalen Welt.
Jetzt vorbestellen und die Zukunft Ihres Kindes mitgestalten!
Künstliche Intelligenz ist gekommen, um zu bleiben. Rüsten Sie sich und Ihre Familie mit dem nötigen Wissen, um die Potenziale dieser Technologie selbstbewusst und sicher zu nutzen.
Kai Spriestersbach ist KI-Experte. Er übersetzt komplexe technologische Zusammenhänge in verständliche und praxisnahe Anleitungen für den Alltag. Daneben forscht an generativer KI und ist erfolgreicher Unternehmer.
Leonie Lutz ist Spiegel-Bestseller-Autorin und weiß, wie man Eltern erreicht. Sie sorgt dafür, dass die Inhalte nicht nur informativ, sondern auch inspirierend und leicht zugänglich sind. Außerdem macht sie Eltern fit für die digitale Lebenswelt ihrer Kinder.
Gemeinsam bilden sie das perfekte Duo, um Eltern die nötige Kompetenz und Gelassenheit für das KI-Zeitalter zu vermitteln.
Mit einem Vorwort von Bob Blume
Bob Blume ist Lehrer, Blogger, Podcaster und Bildungsaktivist. Er studierte Germanistik, Anglistik sowie Geschichte und arbeitet nun als Oberstudienrat an einem Gymnasium in der Nähe von Baden-Baden.
Im Gespräch mit Clemens Boisserée von der Rheinischen Post Ende April hatten wir gerade noch über das ernüchternde Abschneiden aktueller KI-Modelle beim damals neuen AGI-2-Benchmark gesprochen. Jetzt, nur wenige Monate später, steht schon die nächste Generation bereit – und wieder zeigt sich: Echte Denkarbeit bleibt (noch) menschlich.
ARC-AGI-3: Denkspiele statt Datenpuzzles
ARC-AGI-3, entwickelt vom KI-Forscher François Chollet und seinem Team, geht mit einem klaren Ziel an den Start: Herausfinden, ob KI-Systeme auch dann bestehen können, wenn sie völlig neues Terrain betreten – ohne Vorwissen, ohne Anleitungen, ohne kulturellen Kontext.
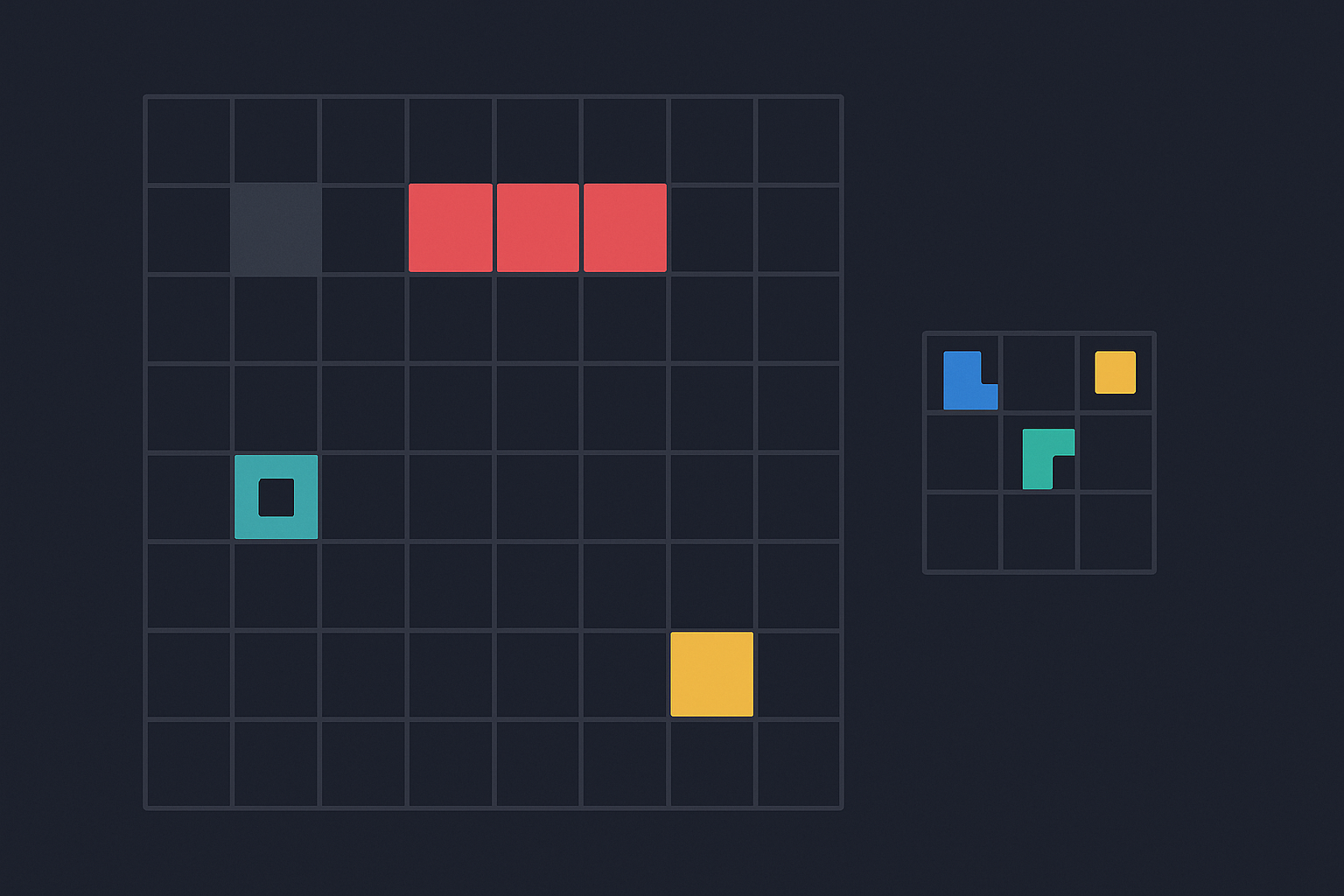
Das Mittel der Wahl: kleine interaktive Mini-Games in einer Grid-Welt, die wie Denkspiele aufgebaut sind. Die KI muss selbst herausfinden, was das Ziel ist, welche Regeln gelten und wie sie zum Erfolg kommt. Trial and Error, wie bei einem Kind, das zum ersten Mal ein Puzzle sieht.
Ich hab’s ausprobiert – und war fasziniert
Ich habe die drei Mini-Games aus der Developer Preview selbst durchgespielt – und es war total spannend zu erleben, welche Fähigkeiten, kleinen Experimente und Aha-Momente mich Schritt für Schritt zur Lösung gebracht haben. Man denkt, probiert, scheitert, lernt – ganz intuitiv.
Genau diese Art des flexiblen, transferierbaren Denkens fehlt heutigen LLMs komplett. Beim Spielen wird einem nochmal richtig klar: So beeindruckend aktuelle KI-Modelle in vielen Bereichen wirken – echte Intelligenz sieht anders aus.
Menschen? Kein Problem. KI? Keine Chance.
Laut den Entwickler*innen lösen Menschen die Aufgaben in wenigen Minuten. Bei aktuellen KI-Modellen sieht das ganz anders aus: Keines der großen Sprachmodelle – nicht mal die neuesten – konnte bisher Punkte erzielen. Mit einer Ausnahme: Ein mysteriöser Eintrag auf dem Leaderboard, dessen Herkunft unbekannt ist. Angeblich hat OpenAIs neues ChatGPT-Agentensystem das erste Spiel bereits gelöst, aber ob das wirklich der Top-Performer ist, bleibt offen.
Der große Unterschied: Lernen in der echten Welt
Der Clou an ARC-AGI-3 ist der Wechsel vom statischen Benchmark zu interaktiven Aufgaben. Es geht nicht mehr darum, gesehene Muster wiederzuerkennen, sondern darum, zu verstehen, zu planen und sich anzupassen. Genau das machen Menschen täglich – KI dagegen tut sich hier noch erstaunlich schwer.
Oder wie das ARC-Team selbst schreibt: „Solange diese Lücke besteht, haben wir keine AGI.“
Entwickler*innen-Challenge mit 10.000 $ Preisgeld
Parallel zur Developer Preview startet HuggingFace einen vierwöchigen Sprint-Wettbewerb. Mitmachen können alle, die versuchen wollen, ein erfolgreiches KI-System zu bauen – zu gewinnen gibt’s 10.000 Dollar. Die API und alle Infos findet ihr unter arcprize.org.
Bis Anfang 2026 soll der vollständige Benchmark dann rund 100 verschiedene Spiele umfassen – ein Mix aus öffentlichen und privaten Testsets.
Fazit: AGI bleibt Zukunftsmusik
Auch mit ARC-AGI-3 zeigt sich: Trotz aller Fortschritte sind heutige KI-Systeme noch weit davon entfernt, so flexibel und einfallsreich zu denken wie wir Menschen. Der Benchmark ist ein spannender Realitätscheck – und eine Einladung an die KI-Community, nicht nur schneller, sondern auch klüger zu werden.
OpenAI hat mal wieder einen rausgehauen: Eine KI, die Matheaufgaben auf dem Niveau der Internationalen Mathematik-Olympiade (IMO) löst – fünf von sechs Aufgaben geknackt, angeblich Goldmedaille, alles in natürlicher Sprache. Klingt erstmal beeindruckend. Aber je tiefer man schaut, desto mehr kratzt man sich am Kopf: Geht’s hier wirklich um Forschung – oder nur um die nächste große PR-Welle?
Was ist passiert?
Laut OpenAI hat ein neues Sprachmodell beim IMO-Wettbewerb 2025 satte 35 von 42 Punkten erreicht – was einem Goldrang entspricht. Das Besondere: Keine Mathe-Speziallösung, sondern ein „ganz normales“ Sprachmodell, das einfach weiter trainiert wurde. Lösungen wurden in natürlicher Sprache generiert, ohne Tools, unter realistischen Wettbewerbsbedingungen. Klingt nach Fortschritt – sagt auch OpenAI-Forscher Jerry Tworek:
„We did very little IMO-specific work […] All natural language proofs. No evaluation harness.“
Die Forschung dahinter: offenbar ein neues Setup für Reinforcement Learning und Rechenpower zur Testzeit. Kurz: Kein Mathe-Modell, sondern ein Allrounder mit Hirn – oder zumindest mit Textverständnis.
Aber: Die Geschichte hat einen faden Beigeschmack
Denn es gibt mehrere Dinge, die in dieser Glanzleistung ziemlich schief laufen:
1. OpenAI hat sich nicht an Absprachen gehalten
Laut mehreren Quellen – unter anderem dem Mathematiker Mikhail Samin – haben die IMO-Organisatorinnen die KI-Firmen explizit gebeten, nicht vor der offiziellen Siegerehrung mit Ergebnissen rauszugehen. Warum? Weil dieser Wettbewerb für Schülerinnen gedacht ist. Für kluge Kids aus der ganzen Welt, nicht für die nächste OpenAI-Schlagzeile. OpenAI hat trotzdem vor dem Ende der IMO-Pressekonferenz veröffentlicht – und damit die Show geklaut.
Zitat aus dem IMO-Umfeld:
„The general sense of the IMO Jury and Coordinators is that it was rude and inappropriate.“
2. Die Goldmedaille ist womöglich gar keine
Google-Forscher Thang Luong weist darauf hin, dass OpenAIs Bewertung auf einer inoffiziellen Korrektur basiert. Die echte IMO-Bewertung erfolgt nach streng geheimen Richtlinien, die nicht öffentlich zugänglich sind. Ohne die kann man gar keine offizielle Medaille vergeben.
Und: Wenn man einen einzigen Punkt abzieht (was realistisch sein könnte), wäre das nur Silber, nicht Gold. Also: Ein „Gold-Standard“ auf wackligem Fundament.
3. DeepMind war möglicherweise besser – hält sich aber an Absprachen
Im Gegensatz zu OpenAI scheint sich Google DeepMind an die Bitte der Veranstalter zu halten. Dabei gibt’s Gerüchte, dass sie ebenfalls Gold erreicht oder sogar besser abgeschnitten haben – nur eben ohne großes Tamtam. Letztes Jahr hatten ihre spezialisierten Systeme AlphaProof und AlphaGeometry bereits vier von sechs Aufgaben gelöst. Dieses Jahr könnte es mehr sein – wir werden es erfahren, nach der IMO-Ehrung.
Mein Fazit: Forschung, schön und gut – aber PR bitte mit Anstand
Natürlich: Technisch ist das spannend. Eine Sprach-KI, die komplexe Matheaufgaben sauber löst – in natürlicher Sprache, ohne Tricks – das zeigt, was bei Large Language Models möglich ist. Aber der Kontext ist entscheidend.
Wenn man bei einem Schüler*innen-Wettbewerb die Bühne klaut, sich über Bitten hinwegsetzt und mit einer womöglich falschen Goldmedaille wedelt, dann ist das kein wissenschaftlicher Durchbruch. Dann ist das einfach schlechter Stil – und leider typisch OpenAI: mehr Buzz als Bodenhaftung.
Laut einer unabhängigen Auswertung von MathArena hat kein veröffentlichtes Sprachmodell 2025 überhaupt eine IMO-Bronzemedaille erreicht – selbst mit massiver Rechenpower und Best-of-32-Trickserei. Der beste Score lag bei mageren 13 von 42 Punkten. OpenAI behauptet zwar, mit einem geheimen Modell Gold geholt zu haben, aber wie genau? Das bleibt (noch) undurchsichtig. Die IMO-Organisator*innen konnten die Lösungen zwar prüfen, nicht aber den Entstehungsprozess!
Update: Google zeigt, wie’s geht – mit Anstand und Anerkennung
Einen Tag nach dem PR-Blitz von OpenAI meldet sich nun Google DeepMind zu Wort – mit Fakten, Ergebnissen und, ja: echter Anerkennung durch die IMO.
In einem offiziellen Blogpost berichten Thang Luong und Edward Lockhart, dass eine erweiterte Version von Gemini („Deep Think“) beim IMO-Wettbewerb 2025 ebenfalls 35 von 42 Punkten erreicht hat – und dass diese Leistung vom IMO-Korrektor*innen-Team offiziell geprüft und bestätigt wurde. Damit steht fest: Auch Gemini hat den Goldmedaillenstandard erreicht. Der Unterschied? DeepMind hat sich an die Spielregeln gehalten und die Ergebnisse erst nach der offiziellen Siegerehrung veröffentlicht.
Zitat vom IMO-Präsidenten Prof. Dr. Gregor Dolinar:
„We can confirm that Google DeepMind has reached the much-desired milestone […] IMO graders found [the solutions] to be clear, precise and most of them easy to follow.“
Der Blogpost geht dabei transparent auf die Methodik ein: Gemini Deep Think wurde mit fortgeschrittenem Reinforcement Learning trainiert, nutzte sogenanntes „Parallel Thinking“ (mehrere Lösungsideen gleichzeitig verfolgen), arbeitete in natürlicher Sprache und lieferte innerhalb des 4,5-Stunden-Zeitlimits präzise mathematische Beweise – ohne formale Sprache, ohne Spezialwerkzeuge, aber mit Struktur und Klarheit.
Besonders bemerkenswert: DeepMind bedankt sich explizit bei der IMO-Organisation, benennt dutzende beteiligte Forscher*innen und macht klar, dass der Reviewprozess nicht die gesamte Systemarchitektur validiert – ein wohltuend differenzierter, bodenständiger Ton.
Fazit zum Update: So geht’s auch
Was OpenAI mit Hektik, Geheimniskrämerei und dem Hang zur Schlagzeile inszenierte, zeigt DeepMind nun mit Respekt, Kooperation und Transparenz. Das Modell erreichte dasselbe Ergebnis – aber ohne den Beigeschmack. Und mit echter IMO-Bestätigung.
Es zeigt: Auch in der KI-Forschung kommt es nicht nur aufs Ergebnis an – sondern auf den Umgang damit. Wer den Wettbewerb ernst nimmt, sollte auch dessen Regeln respektieren. DeepMind hat das verstanden. OpenAI? Eher nicht.
Obwohl beide Modelle unterschiedliche Wege eingeschlagen haben, zeigen ihre Leistungen, dass sich KI dem fortgeschrittenen mathematischen Denken annähert. Bei diesem Tempo stellt sich nicht mehr die Frage, ob sie alle sechs IMO-Probleme lösen können, sondern ob sie jemals die Kreativität entwickeln werden, um Probleme zu lösen, die noch kein Mensch zuvor gelöst hat.
Die wirklich entscheidende Fähigkeit in der KI ist nicht mehr das Prompting, sondern das Context Engineering.
Warum die Zukunft der KI denen gehört, die Informationen strukturieren können, und nicht nur denen, die Anweisungen formulieren.
1. Das Ende der Ära des „magischen Prompts“
In der rasanten Welt der künstlichen Intelligenz hat sich etwas grundlegend verschoben. Die Diskussion, die sich einst um die Kunst des „Prompt Engineering“ drehte, weicht nun einer breiteren, strategischeren Disziplin: dem Context Engineering. Führende Köpfe der Branche, von Shopify-CEO Tobi Lutke bis zum renommierten KI-Forscher Andrej Karpathy, haben diesen Wandel erkannt. Sie argumentieren, dass die wahre Herausforderung beim Bau leistungsfähiger KI-Systeme nicht mehr darin besteht, die perfekte Frage zu stellen, sondern eine umfassende Informationsumgebung zu schaffen, in der ein großes Sprachmodell (LLM) eine Aufgabe sinnvoll lösen kann.1
Dieser Wandel ist mehr als nur eine Wortklauberei; er markiert den Reifeprozess der KI von experimentellen Werkzeugen zu produktionsreifen Systemen, die in der Lage sind, komplexe, reale Probleme anzugehen. Um zu verstehen, warum dieser Wandel so fundamental ist, müssen wir uns zunächst die Reise des Prompt Engineering ansehen – seinen Aufstieg, seine Techniken und letztendlich seine Grenzen.
1.1 Der Aufstieg des Prompt Engineers: Ein notwendiger erster Schritt
Die anfängliche „Flitterwochenphase“ der generativen KI war geprägt vom Prompt Engineering, das sich als primäre Schnittstelle zur Kommunikation mit LLMs etablierte.3 Es war der erste entscheidende Schritt, um zu lernen, wie man mit diesen neuen, leistungsstarken Modellen „spricht“.5 Die Geschichte des Begriffs ist eng mit der Entwicklung der Verarbeitung natürlicher Sprache (NLP) verbunden, aber er wurde erst mit dem Aufkommen von Modellen wie GPT-3 zu einer kritischen Komponente, die zeigte, wie man das Verhalten von Modellen durch sorgfältig gestaltete Eingaben steuern kann.6
Prompt Engineering ist die Praxis, Anweisungen (Prompts) zu entwerfen und zu verfeinern, um spezifische Antworten von KI-Modellen zu erhalten, und fungiert als Brücke zwischen menschlicher Absicht und maschineller Ausgabe.4 In dieser Ära wurden mehrere Schlüsseltechniken entwickelt:
Zero-Shot Prompting: Hier gibt man dem Modell eine direkte Anweisung ohne Beispiele. Diese Technik testet die Fähigkeit des Modells, sein vortrainiertes Wissen zu verallgemeinern.4 Ein Beispiel wäre die einfache Anweisung: „Erkläre das Konzept des Klimawandels.“
Few-Shot Prompting / In-Context Learning: Bei dieser Methode gibt man dem Modell einige Beispiele (Shots), um seine Antwort zu lenken. Dies ist eine Art temporäres „On-the-fly“-Lernen, bei dem das Modell aus dem unmittelbaren Kontext lernt, ohne seine Parameter dauerhaft zu ändern.4 Man könnte dem Modell zum Beispiel einige Übersetzungspaare zeigen (maison → house, chat → cat), bevor man es bittet, chien zu übersetzen.8
Chain-of-Thought (CoT) Prompting: Diese fortgeschrittene Technik leitet das Modell durch eine Reihe von logischen Zwischenschritten, um zu einer Schlussfolgerung zu gelangen. Dies kann entweder als Zero-Shot-Prompt (durch Hinzufügen von Phrasen wie „Lass uns Schritt für Schritt denken“) oder als Few-Shot-Prompt (durch die Bereitstellung von Beispielen, die den Denkprozess demonstrieren) umgesetzt werden.4 Dieser Ansatz verbessert die Fähigkeit des Modells, komplexe logische oder arithmetische Probleme zu lösen, erheblich.
Andere Techniken wie Self-Consistency (Generierung mehrerer Denkketten und Auswahl der häufigsten Antwort) und Tree-of-Thought (Erkundung mehrerer Argumentationspfade parallel) sind Erweiterungen dieser Kernideen und zeigen die zunehmende Raffinesse des Feldes.8
1.2 Die semantische Drift: Als „Engineering“ zu „Tippen“ wurde
Trotz seiner technischen Tiefe litt das Prompt Engineering unter einem Wahrnehmungsproblem. Während es als komplexe Disziplin gedacht war, wurde es in der öffentlichen Vorstellung oft zu einem „lächerlich prätentiösen Begriff für das Eintippen von Dingen in einen Chatbot“ degradiert.1 Diese semantische Drift schuf die Notwendigkeit für einen neuen Begriff, der die Komplexität des Baus von produktionsreifen KI-Systemen besser erfasst.
Diese Entwicklung war nicht nur eine Frage der Umbenennung, sondern eine direkte Folge der Popularisierung der Technologie. Als Millionen von Nutzern begannen, mit Chatbots zu „prompten“, verlor der Begriff in der öffentlichen Wahrnehmung seine Assoziation mit tiefgreifendem technischem Fachwissen. Gleichzeitig standen Entwickler, die Anwendungen auf diesen Modellen aufbauten, vor Herausforderungen, die weit über einen einzelnen Prompt hinausgingen – wie Skalierbarkeit, Zustandsverwaltung und Datenintegration. Sie erkannten, dass ihre Hauptaufgabe nicht darin bestand, den Prompt-String zu schreiben, sondern alles um den Prompt herum zu verwalten. Diese intellektuelle und sprachliche Lücke wurde perfekt durch den Begriff „Context Engineering“ gefüllt, der von Branchenführern als eine präzisere Beschreibung der eigentlichen Arbeit beim Bau robuster KI-Systeme angenommen wurde.1
1.3 Risse im Fundament: Warum Prompt Engineering bei der Skalierung versagt
Der entscheidende Wendepunkt ist die Erkenntnis, dass Prompt Engineering zwar für einmalige Aufgaben und Demos wirksam ist, aber beim Aufbau zuverlässiger, skalierbarer Systeme an seine Grenzen stößt.10 Der Ansatz des „Vibe Coding“, bei dem man sich auf Intuition verlässt, um einen guten Prompt zu finden, bricht zusammen, wenn man versucht, etwas Reales zu bauen.3 Die Grenzen sind vielfältig und systemisch:
Inkonsistenz und Nicht-Determinismus: Derselbe Prompt kann unterschiedliche Ergebnisse liefern, was ihn für kritische Arbeitsabläufe unzuverlässig macht. Geringfügige Änderungen am Prompt können an anderer Stelle zu Regressionen führen.11 Eine Studie zeigte, dass selbst subtile Variationen wie die Höflichkeit („Bitte“ vs. „Ich befehle“) die Leistung bei einzelnen Fragen dramatisch, aber inkonsistent beeinflussen können.13
Beschränkungen des Kontextfensters: Prompts sind durch Token-Limits begrenzt. Bei langen Gesprächen oder komplexen Dokumenten vergisst das Modell frühere Anweisungen, was zu einem Verlust des Kontexts führt.14 Wichtige Informationen, die zu Beginn eines langen Gesprächs gegeben werden, können aus dem „Gedächtnis“ des Modells verdrängt werden.15
Hölle der Skalierbarkeit und Wartung: Mit wachsenden Anwendungen wird die Verwaltung und Versionierung einer Vielzahl von spröden, fest codierten Prompts zu einer technischen Belastung. Ein Prompt, der in einem System funktioniert, schlägt in einem anderen fehl, und es gibt keine Standardisierung.11 Das Behandeln von Prompts wie Code – mit Versionierung, Tests und kontinuierlicher Evaluierung – wird unerlässlich, aber oft vernachlässigt.11
Die Illusion der Einfachheit: Was in einer Chatbot-Oberfläche intuitiv erscheint, wird unglaublich komplex, wenn man es mit realen Variablen, Grenzfällen und Produktionsanforderungen zu tun hat.11 Der iterative Prozess der Feinabstimmung durch Versuch und Irrtum ist zeitaufwändig und frustrierend.15
Modellabhängigkeit und mangelnde Portabilität: Prompts sind oft auf die Architektur und die Trainingsdaten eines bestimmten Modells zugeschnitten. Ein Prompt, der auf GPT-4o gut funktioniert, kann bei Claude 3 versagen, was zu einer Anbieterbindung und hohen Wechselkosten führt.15
Diese Einschränkungen offenbaren eine grundlegende Wahrheit über den aktuellen Stand von LLMs: Sie sind leistungsstarke Denkmaschinen, aber sie sind weder allwissend noch telepathisch. Ihr Versagen ist oft ein Eingabefehler, kein Modellfehler.2 Dies deutet darauf hin, dass die nächste Innovationswelle in der KI nicht von marginalen Verbesserungen der Modellarchitektur kommen wird, sondern von radikalen Verbesserungen der Systeme, die sie mit Informationen versorgen. Der Engpass hat sich von der „CPU“ (dem LLM) auf die „I/O“ (die Kontext-Pipeline) verlagert.
2. Definition der neuen Disziplin: Was ist Context Engineering?
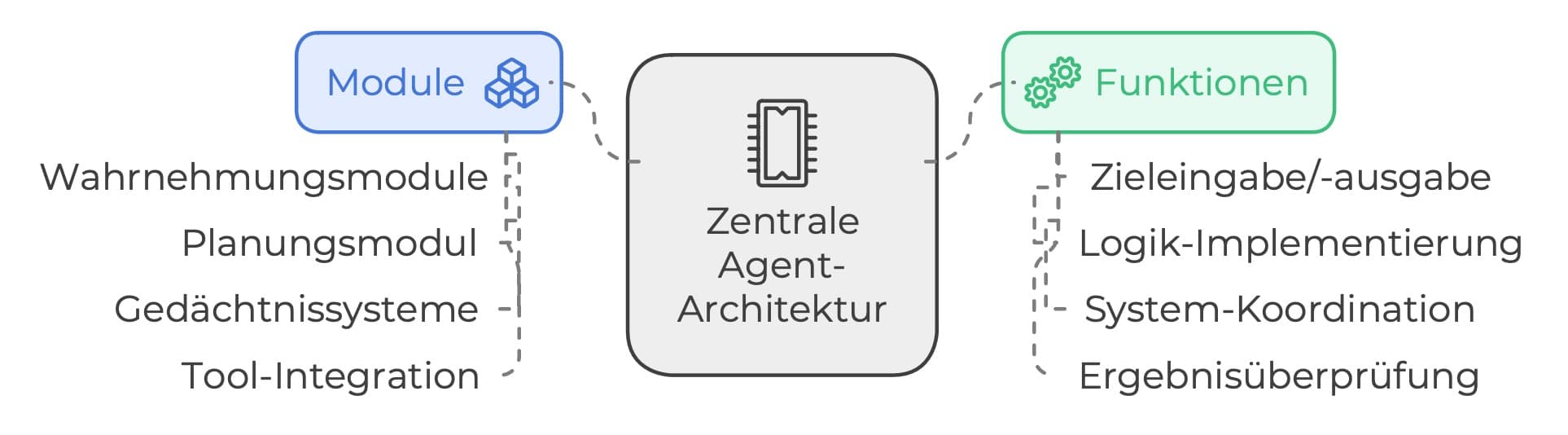
Während das Prompt Engineering an seine Grenzen stößt, tritt eine neue Disziplin in den Vordergrund, die einen grundlegenden Wandel in der Art und Weise darstellt, wie wir KI-Systeme konzipieren und bauen. Diese Disziplin, das Context Engineering, verlagert den Fokus von der Formulierung von Anweisungen auf die Architektur von Informationen.
2.1 Ein neues Paradigma: Die Architektur des „Geistes“ des Modells
Die formale Definition lautet: Context Engineering ist die Disziplin des Entwerfens und Bauens dynamischer Systeme, die zur richtigen Zeit die richtigen Informationen und Werkzeuge im richtigen Format bereitstellen, um einem LLM alles zu geben, was es benötigt, um eine Aufgabe plausibel zu bewältigen.2 Die Kernidee ist eine Verlagerung von der Konzentration darauf,
was man dem Modell sagt, hin zu der Konzentration darauf, was das Modell weiß, wenn man es ihm sagt.10 Es geht darum, die Bühne zu bereiten, bevor die Schauspieler ihre Zeilen sprechen.18
Eine treffende Analogie ist die des LLM als CPU und des Kontextfensters als dessen RAM.20 Prompt Engineering ist das Schreiben eines einzelnen Programms, das auf der CPU ausgeführt wird. Context Engineering hingegen ist das Betriebssystem, das den RAM verwaltet und die notwendigen Daten für jede gegebene Aufgabe lädt und entlädt.
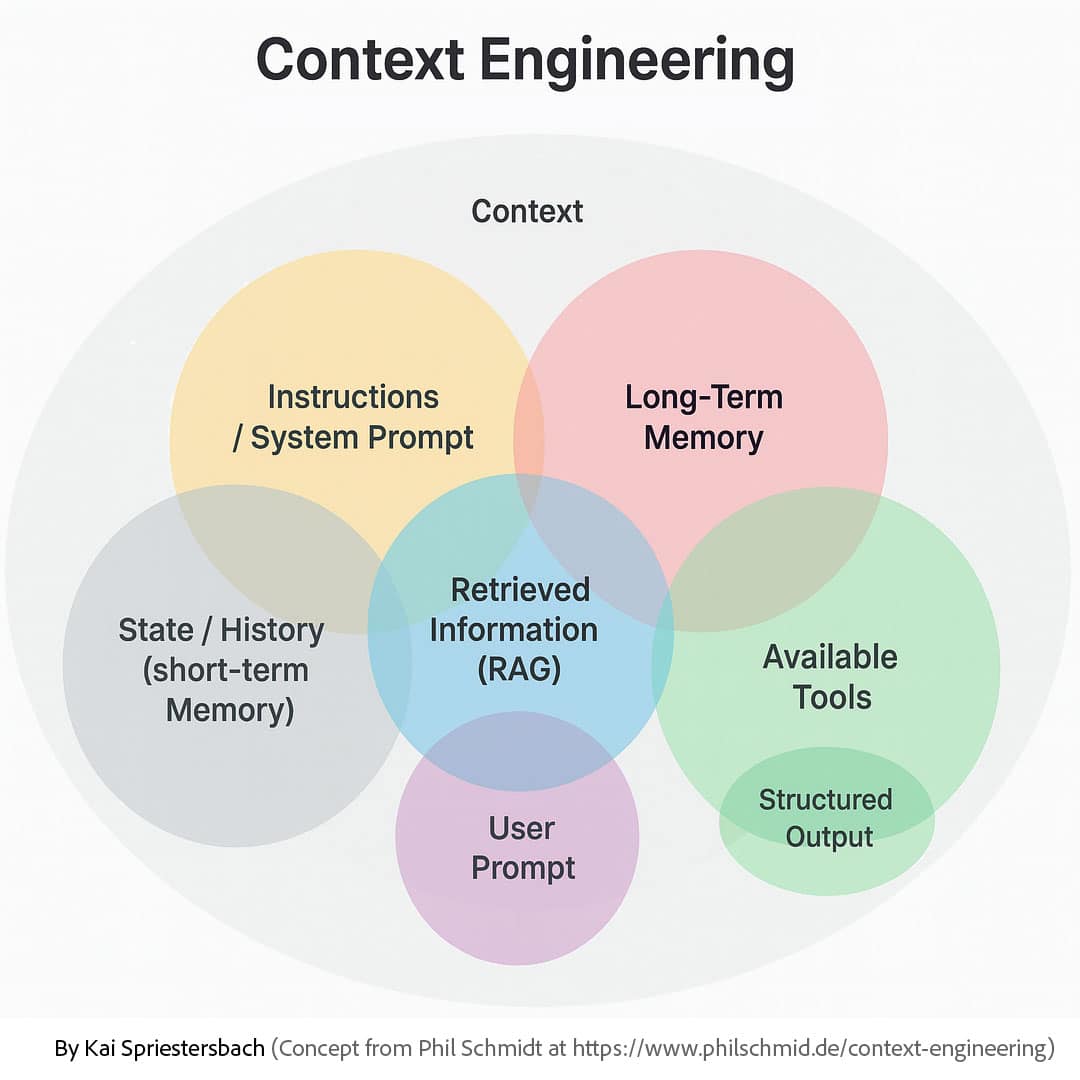
2.2 Dekonstruktion des Kontextfensters: Das gesamte Informationsökosystem
Um Context Engineering zu verstehen, muss die Definition von „Kontext“ über einen einzelnen Prompt hinaus erweitert werden. Es ist alles, was das Modell sieht, bevor es eine Antwort generiert.2 Dieses Ökosystem umfasst mehrere entscheidende Komponenten 2:
Anweisungen / System-Prompt: Die persistenten, übergeordneten Direktiven, die die Persona, Regeln und Einschränkungen der KI definieren (z. B. „Du bist ein hilfreicher Assistent für Rechtsrecherche“).
Benutzer-Prompt: Die unmittelbare, aktuelle Frage oder Aufgabe des Benutzers.
Zustand / Verlauf (Kurzzeitgedächtnis): Das laufende Gesprächsprotokoll, das den unmittelbaren Konversationskontext liefert.
Langzeitgedächtnis: Eine persistente Wissensbasis mit Benutzerpräferenzen, früheren Interaktionen und Fakten, die über Sitzungen hinweg gesammelt wurden.
Abgerufene Informationen (RAG): Dynamisch abgerufene externe Kenntnisse aus Dokumenten, Datenbanken oder APIs, um das Modell in Fakten zu verankern und ihm Zugriff auf aktuelle Informationen zu geben.
Verfügbare Werkzeuge: Die Definitionen und Schemata von Funktionen oder APIs, die das Modell aufrufen kann, um Aktionen auszuführen oder weitere Informationen zu sammeln (z. B. eine send_email-Funktion).
Strukturierte Ausgabe: Definitionen des gewünschten Antwortformats (z. B. ein JSON-Schema), um vorhersagbare, maschinenlesbare Ausgaben zu gewährleisten.
2.3 Eine Geschichte zweier Disziplinen: Prompt vs. Context Engineering
Die Unterschiede zwischen diesen beiden Disziplinen sind fundamental und lassen sich am besten in einer vergleichenden Analyse verdeutlichen.
Tabelle 1: Prompt Engineering vs. Context Engineering: Eine vergleichende Analyse
Merkmal
Prompt Engineering
Context Engineering
Zweck
Eine spezifische Antwort auf einen einzelnen Prompt erhalten, meist für eine einmalige Aufgabe.10
Sicherstellen, dass das Modell über Sitzungen, Benutzer und Aufgaben hinweg konsistent und zuverlässig agiert.10
Umfang
Arbeitet mit einem einzelnen Eingabe-Ausgabe-Paar.10
Verwaltet das gesamte Kontextfenster: Gedächtnis, Verlauf, Werkzeuge, System-Prompts.10
Denkweise
Das Verfassen klarer Anweisungen; ähnlich dem kreativen Schreiben oder Copywriting.10
Das Entwerfen des gesamten Informationsflusses und der Architektur; ähnlich dem Systemdesign oder der Softwarearchitektur.10
Natur
Ein statischer String oder eine Vorlage.2
Ein dynamisches System, das vor dem LLM-Aufruf läuft, um den Kontext on-the-fly zusammenzustellen.2
Werkzeuge
Ein Texteditor oder eine Chatbot-Oberfläche.10
RAG-Systeme, Vektordatenbanken, Gedächtnismodule, API-Verkettung, Orchestrierungs-Frameworks (z. B. LangGraph).10
Fehlerbehebung
Umformulieren, Phrasen anpassen und raten.10
Inspektion des gesamten Kontextfensters, der Gedächtnisslots, der Werkzeugaufrufe und des Token-Flusses mit Observability-Tools (z. B. LangSmith).10
Skalierbarkeit
Spröde; bricht bei der Skalierung aufgrund von Grenzfällen zusammen.10
Von Anfang an auf Skalierbarkeit und Wiederverwendbarkeit ausgelegt.10
Beziehung
Eine Teilmenge des Context Engineering. Es ist das, was man innerhalb des Kontextfensters tut.10
Die Disziplin, die entscheidet, was das Kontextfenster füllt.10
Dieser Wandel hat tiefgreifende architektonische und strategische Auswirkungen. Der Fokus der KI-Entwicklung verlagert sich von der Modellinteraktionsebene (dem Prompt) auf die Datenorchestrierungsebene (die Kontext-Pipeline). Das bedeutet, dass die wertvollste Arbeit nicht mehr im Moment des LLM-Aufrufs stattfindet, sondern in den vorbereitenden Schritten, die die Informationen für diesen Aufruf zusammenstellen. Wie es in einer Analyse treffend heißt: „Das Geheimnis beim Bau wirklich effektiver KI-Agenten hat weniger mit der Komplexität des von Ihnen geschriebenen Codes zu tun, sondern alles mit der Qualität des von Ihnen bereitgestellten Kontexts“.2
Die Wertschöpfung und Komplexität haben sich somit „stromaufwärts“ vom LLM-Aufruf verlagert. Die technische Herausforderung liegt nun in der Datenlogistik und Informationsarchitektur, nicht nur in der Linguistik. Dies verändert grundlegend, wie Organisationen über ihre Daten denken sollten. Daten sind nicht mehr nur ein passives Gut, das analysiert wird; sie sind eine aktive, dynamische Ressource, die in agentische Systeme eingespeist wird. Die proprietären Daten eines Unternehmens – Kundenhistorie, interne Dokumente, Produktschemata – werden zu seinem wichtigsten Wettbewerbsvorteil im Zeitalter der KI, da sie den einzigartigen Kontext bilden, den kein Konkurrent replizieren kann. Die Qualität der Context-Engineering-Infrastruktur eines Unternehmens wird direkt die Intelligenz seiner KI-Agenten bestimmen.
3. Der architektonische Bauplan kontextbewusster Systeme
Nachdem die grundlegende Philosophie des Context Engineering etabliert ist, ist es an der Zeit, in die technischen Details einzutauchen. Dieser Abschnitt bildet den technischen Kern des Artikels und erklärt, wie kontextbewusste Systeme aufgebaut sind, indem er die wichtigsten Bausteine und Strategien detailliert beschreibt.
3.1 Die tragende Säule: Retrieval-Augmented Generation (RAG)
Das Herzstück vieler moderner kontextbewusster Systeme ist die Retrieval-Augmented Generation (RAG). RAG ist der primäre Mechanismus, um LLMs in faktenbasiertem, externem Wissen zu verankern, wodurch Halluzinationen reduziert und der Zugriff auf Echtzeitinformationen ermöglicht wird.21 Anstatt sich nur auf das während des Trainings gelernte Wissen zu verlassen, leitet RAG das LLM an, relevante Informationen aus maßgeblichen, vorab festgelegten Wissensquellen abzurufen, bevor eine Antwort generiert wird.21
Der RAG-Prozess lässt sich in mehrere logische Schritte unterteilen:
Datenaufnahme und -vorbereitung: Der Prozess beginnt mit der Sammlung externer Daten aus verschiedenen Quellen wie Dokumenten-Repositories, Datenbanken oder APIs.21
Chunking: Große Dokumente werden in kleinere, semantisch zusammenhängende Abschnitte (Chunks) zerlegt. Dies verbessert die Relevanz und Effizienz des Abrufs, da das System gezielt auf bestimmte Themen fokussieren kann, anstatt ganze Dokumente zu verarbeiten.23
Embedding: Ein Embedding-Modell wandelt die Text-Chunks in numerische Vektorrepräsentationen um. Diese Vektoren, die die semantische Bedeutung des Textes erfassen, werden in einer Vektordatenbank gespeichert.21 Diese Vektordatenbank fungiert als durchsuchbare Wissensbibliothek für das KI-System.24
Abruf (Retrieval): Wenn eine Benutzeranfrage eingeht, wird diese ebenfalls in einen Vektor umgewandelt. Das System führt dann eine Ähnlichkeitssuche (z. B. mittels Kosinus-Ähnlichkeit) in der Vektordatenbank durch, um die Text-Chunks zu finden, deren Vektoren der Anfrage am ähnlichsten sind.23
Anreicherung und Generierung (Augmentation & Generation): Die abgerufenen Chunks werden dem ursprünglichen Prompt als Kontext hinzugefügt. Dieser angereicherte Prompt wird dann an das LLM gesendet, um eine endgültige, faktenbasierte und kontextuell relevante Antwort zu generieren.21
RAG ist ein aktives Forschungsfeld, in dem kontinuierlich an Best Practices, der Behebung von Fehlerquellen und fortgeschrittenen Architekturen wie multimodalen RAG-Systemen gearbeitet wird, die über verschiedene Datentypen wie Text, Bilder und Videos hinweg funktionieren.26
3.2 Jenseits des Abrufs: Fortgeschrittene Strategien zur Kontextverwaltung
Während RAG die Wissensbasis liefert, sind weitere Strategien erforderlich, um ein wirklich dynamisches und intelligentes System zu schaffen.
Gedächtnis- und Zustandsverwaltung:
LLMs sind von Natur aus zustandslos, aber sinnvolle Interaktionen erfordern einen Zustand. Um dieses Problem zu lösen, werden Gedächtnismechanismen implementiert:
Kurzzeitgedächtnis: Techniken wie die Zusammenfassung von Konversationen oder die Verwendung von gleitenden Kontextfenstern helfen, den Überblick über laufende Interaktionen zu behalten.17
Langzeitgedächtnis: Informationen werden über Sitzungen hinweg persistent gemacht. Dies kann durch „Scratchpads“ (das Speichern von Plänen oder Notizen in einer Datei oder einem Zustandsobjekt) oder dadurch erreicht werden, dass das LLM basierend auf Interaktionen automatisch Erinnerungen generiert und in einer Datenbank speichert.20 Prominente Beispiele wie die Gedächtnisfunktion von ChatGPT zeigen diesen Ansatz in der Praxis.20
Agentischer Werkzeuggebrauch:
Um ein LLM von einem passiven Antwortgeber zu einem aktiven Problemlöser zu machen, wird es mit Werkzeugen ausgestattet.
Das Konzept: Durch die Bereitstellung von Definitionen für Werkzeuge (APIs, Funktionen) kann ein Agent Aktionen ausführen, zusätzliche Informationen nachschlagen oder mit externen Systemen interagieren.17
Funktionsweise: Wenn ein Agent mit einer Aufgabe konfrontiert wird, die er mit seinem aktuellen Kontext nicht lösen kann, kann er eine strukturierte Anfrage (z. B. ein JSON-Objekt) ausgeben, um ein bestimmtes Werkzeug aufzurufen. Das System führt das Werkzeug aus und speist das Ergebnis wieder in das Kontextfenster für den nächsten Denkschritt des LLM ein.20
Kontextorchestrierung: Die vier Kernoperationen:
Um das begrenzte „RAM“ des Kontextfensters effektiv zu verwalten, haben sich vier Schlüsselstrategien herauskristallisiert 20:
Schreiben (Write): Persistieren von Kontext außerhalb des unmittelbaren Fensters (z. B. in einem Scratchpad oder Gedächtnis), um zu verhindern, dass er verloren geht.
Auswählen (Select): Intelligente Auswahl der relevantesten Kontextteile für jeden Schritt (z. B. durch RAG oder das Abrufen spezifischer Erinnerungen).
Komprimieren (Compress): Zusammenfassen oder Beschneiden weniger relevanter Informationen (wie ältere Teile eines Gesprächs), um Platz zu sparen und gleichzeitig den Kern zu erhalten.
Isolieren (Isolate): Verwendung von Techniken wie Sandboxing, um Werkzeugaufrufe auszuführen oder den Zustand separat zu verwalten. Dies verhindert eine „Kontextvergiftung“ oder „Kontextverwirrung“, bei der irrelevante oder fehlerhafte Informationen den Hauptdenkprozess stören.20
3.3 Ein praktisches Framework für das Kontextdesign
Um von der Theorie zur Praxis zu gelangen, können Entwickler etablierte Frameworks nutzen. Die CLEAR-Methode für die Informationsarchitektur (Chronological, Layered, Essential, Accessible, Referenced) und das IMPACT-Framework für die Prompt-Konstruktion innerhalb des Kontexts (Intent, Method, Parameters, Audience, Criteria, Tone) bieten strukturierte Ansätze für das Design.31
Ein entscheidendes, aber oft übersehenes Konzept ist die „linguistische Kompression“: die Fähigkeit, die Anzahl der Tokens zu reduzieren und gleichzeitig die Informationsdichte zu maximieren. Dies ist eine entscheidende Fähigkeit, um das Beste aus einem begrenzten Kontextfenster herauszuholen.19 Darüber hinaus ermöglichen fortgeschrittene Konzepte wie „kognitive Werkzeuge“ – strukturierte Vorlagen, die den Denkprozess des LLM unterstützen – eine höhere Form des Werkzeuggebrauchs, die über einfache API-Aufrufe hinausgeht.33
Diese Komponenten sind nicht nur ein Werkzeugkasten; sie bilden ein dynamisches, zyklisches System. Die Ausgabe eines Werkzeugs kann in den Speicher geschrieben werden. Der Speicher kann beeinflussen, welche Dokumente über RAG abgerufen werden. Die abgerufenen Dokumente können Informationen enthalten, die ein anderes Werkzeug auslösen. Dies schafft eine „Denkschleife“, in der der Kontext bei jedem Schritt der Aufgabe eines Agenten ständig neu aufgebaut und verfeinert wird. Dies ist der Kern dessen, was einen Agenten „agentisch“ macht. Das Aufkommen umfassender Frameworks (wie LangGraph), detaillierter praktischer Anleitungen und sogar vorgeschlagener Protokolle (wie das Narrative Context Protocol) zeigt, dass sich das Context Engineering schnell von einer Sammlung von Ad-hoc-„Hacks“ zu einer formalen, strukturierten Ingenieurdisziplin mit eigenen Prinzipien, Mustern und Best Practices entwickelt. Dies ist ein klares Zeichen für ein reifendes technologisches Feld.
4. Context Engineering in Aktion: Von „billigen Demos“ zu „magischen“ Produkten
Die wahre Bedeutung einer technologischen Verschiebung zeigt sich nicht in der Theorie, sondern in der praktischen Anwendung. Context Engineering ist der entscheidende Faktor, der den Unterschied zwischen einer enttäuschenden KI-Interaktion und einem wirklich „magischen“ Erlebnis ausmacht. Dieser Abschnitt beleuchtet anhand von konkreten Beispielen und Fallstudien, wie die Architektur von Informationen die Leistung von KI-Systemen dramatisch verbessert.
4.1 Die Geschichte zweier Agenten: Die Macht eines reichhaltigen Kontexts
Ein eindrucksvolles Beispiel, das den Wert von Context Engineering verdeutlicht, ist die scheinbar einfache Aufgabe, ein Meeting zu planen.2
Der „billige Demo“-Agent: Erhält nur den Benutzer-Prompt: „Hey, ich wollte nur fragen, ob du morgen Zeit für ein kurzes Gespräch hast.“ Da er keinen weiteren Kontext hat, ist seine Antwort roboterhaft und wenig hilfreich: „Wann würde es Ihnen passen?“ Er legt die gesamte kognitive Last wieder auf den Benutzer.
Der „magische“ Agent: Bevor er das LLM aufruft, wird sein Kontext sorgfältig konstruiert. Er enthält:
Ihren Kalender (der zeigt, dass Sie komplett ausgebucht sind).
Ihre bisherigen E-Mails mit dieser Person (um den passenden informellen Ton zu treffen).
Ihre Kontaktliste (um den Absender als wichtigen Partner zu identifizieren).
Verfügbare Werkzeuge wie send_invite und send_email.
Mit diesem reichhaltigen Kontext kann das LLM eine natürliche, hilfreiche und autonome Antwort generieren, die die Aufgabe erledigt: „Hey! Morgen ist leider komplett voll, aber ich habe übermorgen um 10 Uhr oder 15 Uhr Zeit. Habe dir eine Einladung für 10 Uhr geschickt, lass mich wissen, ob das passt.“ Die Magie liegt nicht in einem klügeren Modell, sondern im konstruierten Kontext.2
4.2 Unternehmensanwendung: Fallstudien zu kontextbewusster KI
Große Unternehmen setzen diese Prinzipien bereits ein, um messbare Geschäftsergebnisse zu erzielen. Die erfolgreichsten KI-Agenten sind diejenigen, die Informationen aus mehreren, proprietären Echtzeit-Datenquellen integrieren und synthetisieren können.
Reisen & Buchung (Priceline & Booking.com): Der Agent „Penny“ von Priceline nutzt Kontextbewusstsein und Echtzeit-Sprach-Streaming für ein nahtloses Buchungserlebnis.34 Booking.com hat einen modularen KI-Reiseplaner entwickelt, der ein mehrschichtiges Agentensystem mit benutzerdefinierten Modellen und Orchestrierung verwendet, um personalisierte Reiserouten anzubieten. Dies führte zu höheren Konversionsraten und geringerer Latenz. Eine wichtige Erkenntnis von Booking.com war die Notwendigkeit, eigene Orchestrierungswerkzeuge zu entwickeln, da Open-Source-Lösungen im Produktionsbetrieb versagten – ein klares Zeichen für den Trend zu robustem, internem Context Engineering.34
Flottenmanagement (Geotab): Der KI-Agent von Geotab ermöglicht es nicht-technischen Flottenmanagern, riesige und komplexe Fahrzeugdatenschemata in natürlicher Sprache abzufragen. Dies ist ein klassischer Anwendungsfall für RAG und Context Engineering, der den Datenzugriff vereinfacht und bessere Entscheidungen ohne SQL-Kenntnisse ermöglicht.34
Versicherungswesen (Five Sigma): Five Sigma konnte die Fehlerquote um 80 % senken, indem es KI-Systeme implementierte, die Context Engineering nutzen, um gleichzeitig auf Policendaten, Schadenshistorien und regulatorische Informationen zuzugreifen.35
Finanzwesen (Bud Financial): Dieses agentische System geht über das Beantworten von Fragen hinaus und ergreift Maßnahmen. Mit dem Kontext der Finanzhistorie und der Ziele eines Kunden kann es autonom Geld überweisen, um Überziehungsgebühren zu vermeiden oder bessere Zinssätze zu nutzen.36
Diese Fallstudien zeigen ein konsistentes Muster: Der Wert liegt nicht im LLM selbst, das zunehmend zur Ware wird, sondern in den proprietären Daten, die ihm zugeführt werden. Die Context-Engineering-Pipeline ist der entscheidende Mechanismus, der diesen Geschäftswert freisetzt.
4.3 Ein interdisziplinärer Werkzeugkasten: Praktische Beispiele
Die Anwendbarkeit des Context Engineering erstreckt sich über alle Branchen. Der Unterschied zwischen einem Standard-Prompt und einem kontextuell angereicherten Prompt ist in jedem Bereich spürbar 37:
Programmierung:
Standard-Prompt: „Schreibe eine Python-Funktion zum Parsen einer CSV-Datei.“
Kontext-angereicherter Prompt: „Schreibe eine robuste Python-Funktion, die Pandas verwendet, um CSV-Dateien mit inkonsistenten Trennzeichen (manchmal Semikolon, manchmal Komma) und leicht variierenden Kopfzeilen (z. B. ‚Betrag‘ oder ‚Betr.‘) zu standardisieren und zu parsen.“
Marketing:
Standard-Prompt: „Schreibe einen Blogbeitrag über Produktivität.“
Kontext-angereicherter Prompt: „Du schreibst einen kurzen, leicht sarkastischen Blogbeitrag für ausgebrannte Startup-Mitarbeiter, die allergisch auf das Wort ‚Hustle‘ reagieren. Ton: trockener Humor, minimaler Fülltext. Er sollte 5 Anti-Produktivitätstipps bieten – Dinge, die die Leute aufhören sollten zu tun, wenn sie fokussierter sein wollen. Betrachte es als das Gegenteil der üblichen Selbsthilfeartikel.“
Rechtliches:
Standard-Prompt: „Erstelle eine grundlegende NDA-Vereinbarung.“
Kontext-angereicherter Prompt: „Du bist ein juristischer Mitarbeiter, der eine gegenseitige NDA für einen nicht-technischen Startup-Gründer und einen freiberuflichen Entwickler im Ausland (Indien) entwirft, die ein potenzielles KI-Projekt besprechen. Die Vereinbarung sollte die Vertraulichkeit von Geschäftsgeheimnissen, Quellcode und Kundendaten abdecken und nach indischem Recht durchsetzbar sein.“
Medizinische Beratung:
Standard-Prompt: „Was sind die Symptome von Diabetes?“
Kontext-angereicherter Prompt: „Verhalte dich wie ein Hausarzt, der mit einem leicht ängstlichen 45-Jährigen spricht, der zu viel googelt. Erkläre die frühen Symptome von Typ-2-Diabetes in einfacher, nicht beunruhigender Sprache. Verwende bei Bedarf lockere Metaphern. Liste sie nicht wie ein Lehrbuch auf – erzähle eine Geschichte. Erwähne auch, welche Symptome unbedenklich sind, solange sie nicht anhalten. Beende mit: wann es in Ordnung ist zu warten und wann man einen Arzt aufsuchen sollte.“
Diese Beispiele zeigen, dass der Wettbewerbsvorteil in der Fähigkeit liegt, robuste Pipelines zur Nutzung einzigartiger Datenbestände aufzubauen. In vielen dieser Fälle ist das Context-Engineering-System das Produkt. Unternehmen bauen nicht mehr nur Apps, die eine KI aufrufen; sie bauen KI-native Systeme, bei denen die intelligente Orchestrierung von Kontext das zentrale Wertversprechen ist. Dies hat massive Auswirkungen auf das Produktdesign, die Infrastrukturinvestitionen und die Teamstruktur.
5. Der Wandel des Humankapitals: Neue Rollen und wesentliche Fähigkeiten
Der Übergang vom Prompting zum Context Engineering ist nicht nur ein technologischer, sondern auch ein menschlicher Wandel. Er definiert die auf dem Technologiemarkt gefragten Fähigkeiten neu und schafft neue Rollen, während er bestehende transformiert. Dieser Abschnitt analysiert die tiefgreifenden Auswirkungen dieses Wandels auf die Belegschaft und definiert die wesentlichen Fähigkeiten, die für den Erfolg im Zeitalter kontextbewusster KI erforderlich sind.
5.1 Der Aufstieg des Context Engineers
Wir erleben die Entstehung einer neuen, entscheidenden Rolle: des „Context Engineer“.38 Diese Rolle ist der Nachfolger des Prompt Engineers für ernsthafte KI-Implementierungen und geht weit über das Schreiben von Prompts hinaus. Ein Context Engineer ist ein Architekt des Informationsökosystems der KI.35 Es handelt sich um eine multidisziplinäre Rolle, die eine Mischung aus Fähigkeiten erfordert: teils Produktdesigner, teils Datenarchitekt, teils KI-Flüsterer.39 Ihre Hauptverantwortung liegt im Entwurf, Bau und der Wartung der Kontext-Pipelines, die LLMs mit den notwendigen Informationen versorgen.
5.2 Das Skillset des Context Engineers: Eine neue Art von Ingenieur
Die für diese neue Rolle erforderlichen Fähigkeiten sind spezifisch und anspruchsvoll. Sie spiegeln die systemische Natur der Aufgabe wider und erfordern eine Mischung aus technischen und konzeptionellen Kompetenzen 38:
Informationsarchitektur: Die Fähigkeit, komplexe Informationshierarchien zu strukturieren, Inhalte innerhalb von Token-Beschränkungen zu optimieren und zu verstehen, wie verschiedene Datenformate das Verständnis der KI beeinflussen.
Übersetzung von Domänenexpertise: Die Umwandlung von implizitem Geschäftswissen in expliziten, maschinenlesbaren Kontext. Dies erfordert die Überbrückung der Lücke zwischen Fachexperten und KI-Systemen.
Design dynamischer Systeme: Der Bau von Systemen, die den Kontext basierend auf sich ändernden Anforderungen anpassen, die Echtzeit-Kontextzusammenstellung implementieren und Kontext-Pipelines über mehrere Datenquellen hinweg verwalten.
Verständnis der „KI-Psychologie“: Die Intuition dafür, wie unterschiedliche Kontextstrukturen das Verhalten des Modells beeinflussen, das Erkennen von Mustern in KI-Antworten, die auf Kontextprobleme hinweisen, und die Fehlerbehebung von KI-Ausgaben durch Analyse der Kontextqualität.
Sicherheits- und Compliance-Kontext: Sicherstellen, dass Kontext-Pipelines keine Sicherheitslücken einführen oder sensible Daten preisgeben, und die Implementierung von Audit-Trails für Kontextentscheidungen.
Leistungsoptimierung: Das Ausbalancieren von Kontextreichtum mit den Rechenkosten (Latenz, finanzielle Kosten) und die effektive Verwaltung der Beschränkungen des Kontextfensters.
5.3 Die sich wandelnde Rolle des Produktmanagers
Das Context Engineering transformiert auch die Rolle des Produktmanagers in einem KI-getriebenen Unternehmen. Um die Entwicklung dieser komplexen Systeme effektiv zu leiten, benötigen sie ein neues Set von Fähigkeiten. Die folgenden Kompetenzen, die aus Analysen moderner Produktmanagement-Anforderungen abgeleitet wurden, sind entscheidend 40:
Strategisches Denken & Vision: Die Definition des „Warum“ hinter dem Produkt und wie kontextbewusste KI die Geschäftsziele erreicht.
Datengetriebene Entscheidungsfindung: Der Übergang von Intuition zur Nutzung von Datenanalysen (aus Nutzerverhalten, Markttrends), um zu bestimmen, welcher Kontext am wertvollsten ist.
Technische Kompetenz: Produktmanager müssen nicht programmieren können, aber sie müssen die Architektur von Kontextsystemen (RAG, Vektordatenbanken, Agenten) verstehen, um fundierte Kompromisse eingehen und glaubwürdige Diskussionen mit den Ingenieurteams führen zu können. Ein Verständnis von Konzepten wie APIs und Datenmodellen ist unerlässlich.
Kundenzentrierung & Empathie: Ein tiefes Verständnis der Schmerzpunkte der Nutzer, um den kritischsten Kontext zu identifizieren, der zur Lösung ihrer Probleme erforderlich ist.
Kommunikation: Die Funktion als Übersetzer zwischen Geschäftsinteressenten, Fachexperten und dem technischen Context-Engineering-Team.
Die folgende Tabelle fasst die wesentlichen Fähigkeiten für Fachleute zusammen, die in diesem neuen Paradigma erfolgreich sein wollen.
Tabelle 2: Wesentliche Fähigkeiten für den kontextbewussten KI-Profi
Rolle
Kernkompetenz
Beschreibung der Fähigkeiten
Context Engineer
Informationsarchitektur
Strukturierung komplexer Daten, Optimierung für Token-Limits, Verständnis von Datenformaten.38
Design dynamischer Systeme
Bau adaptiver, echtzeitfähiger Kontext-Pipelines, die mehrere Quellen integrieren.38
„KI-Psychologie“
Intuition für das Modellverhalten, Debugging von Ausgaben durch Analyse der Kontextqualität.38
Leistungsoptimierung
Abwägung von Kontextreichtum gegen Latenz und Kosten, Verwaltung von Kontextfensterbeschränkungen.38
Produktmanager
Strategisches Denken
Definition der Produktvision und Ausrichtung der KI-Fähigkeiten an den Geschäftszielen.41
Datengetriebene Entscheidungsfindung
Nutzung von Analysen zur Priorisierung von Kontextquellen und zur Validierung von Hypothesen.42
Technische Kompetenz
Verständnis der KI-Architektur (RAG, Agenten), um fundierte Kompromisse einzugehen und die technische Machbarkeit zu beurteilen.41
Kommunikation & Empathie
Übersetzung zwischen technischen und geschäftlichen Teams, tiefes Verständnis der Nutzerbedürfnisse, um den relevantesten Kontext zu definieren.40
5.4 Der Ingenieur als KI-Copilot
Die vielleicht tiefgreifendste Veränderung ist die Neudefinition der Rolle des Ingenieurs. Ingenieure werden nicht durch KI ersetzt, sondern ihre Rolle wird aufgewertet. Sie werden zu den „menschlichen Copiloten“, die die Systeme architekturieren, die KI-Agenten erst wirklich effektiv machen.38 Der wertvollste Ingenieur ist derjenige, der das reichhaltigste und dynamischste Kontextsystem bauen kann.
Diese Entwicklung führt zu einer Konvergenz der Rollen. Ein Context Engineer muss wie ein Softwarearchitekt (Systeme entwerfen), ein Dateningenieur (Pipelines bauen) und ein Produktmanager (Nutzerabsicht und Geschäftslogik verstehen) denken. Ein Produktmanager muss wiederum technisch versierter sein als je zuvor. Dies schafft ein neues „Full-Stack“-KI-Profil, das stark funktionsübergreifend ist. Diese Rollenkonvergenz wird erhebliche Auswirkungen haben. Unternehmen müssen ihre Teams von isolierten Funktionen zu funktionsübergreifenden „KI-Agenten“-Teams umstrukturieren. Bildungseinrichtungen und Schulungsprogramme müssen neue Lehrpläne entwickeln, die diese Mischung aus Software, Daten und Produktstrategie vermitteln. Die Nachfrage nach diesen hybriden Fachleuten wird das Angebot bei weitem übersteigen, was zu einem erheblichen Talentengpass und einer enormen Chance für diejenigen führt, die sich weiterbilden.44
6. Die Zukunft ist kontextbewusst
Während sich die KI-Branche weiterentwickelt, wird deutlich, dass Context Engineering kein vorübergehender Trend ist, sondern die grundlegende Arbeit für die nächste Ära der künstlichen Intelligenz.45 Die Fähigkeit, Informationen effektiv zu architekturieren, wird die Gewinner von den Verlierern trennen. Dieser letzte Abschnitt blickt auf den Horizont, fasst die Bedeutung des Context Engineering zusammen und prognostiziert seine zukünftige Entwicklung.
6.1 Die unausweichliche Entwicklung: Hin zur vollen agentischen Autonomie
Das ultimative Ziel der aktuellen KI-Entwicklung ist die Schaffung hochentwickelter, autonomer KI-Agenten, die komplexe, mehrstufige Aufgaben ausführen können.35 Diese Agenten werden nicht nur auf Anfragen reagieren, sondern proaktiv handeln, planen und sich an neue Informationen anpassen. Gartner prognostiziert, dass bis 2028 33 % der Unternehmenssoftware agentische KI enthalten wird, was die Geschwindigkeit dieses Übergangs unterstreicht.35 Solche Systeme sind ohne ausgereifte Context-Engineering-Fähigkeiten unmöglich zu realisieren. Sie benötigen eine konstante Zufuhr von präzisem, relevantem und zeitnahem Kontext, um ihre Ziele zuverlässig zu erreichen.
6.2 Die nächsten Grenzen des Kontexts
Die Forschung und Entwicklung im Bereich des Context Engineering schreitet schnell voran und konzentriert sich auf mehrere wichtige zukünftige Trends:
Multimodale Kontextintegration: Die nächste Grenze besteht darin, über reinen Text hinauszugehen und Bilder, Audio, Video und andere Datentypen nahtlos in einheitliche Kontext-Frameworks zu integrieren.35 Dies wird es KI-Systemen ermöglichen, in reichhaltigen, realen Umgebungen zu verstehen und zu agieren, anstatt auf textbasierte Interaktionen beschränkt zu sein. Neue Forschungsansätze wie UniversalRAG, die über verschiedene Modalitäten hinweg arbeiten, weisen bereits den Weg.27
Automatisiertes Context Engineering: Die Entwicklung von Systemen, die Meta-Learning nutzen, um ihr eigenes Kontextmanagement zu optimieren, ist ein entscheidender nächster Schritt.35 Die KI wird lernen, welche Informationsquellen für welche Aufgaben am wertvollsten sind, und ihre eigenen Kontext-Pipelines automatisch verfeinern, um die Leistung zu verbessern und den manuellen Aufwand zu reduzieren. Dies führt zu einer weiteren Abstraktionsebene in der KI-Entwicklung. Wenn die KI ihren eigenen Kontext optimal auswählen, komprimieren und abrufen kann, verlagert sich die Aufgabe des menschlichen Ingenieurs von der manuellen Gestaltung der Pipeline-Logik zur Definition der übergeordneten Ziele, ethischen Leitplanken und Erfolgskriterien für diese autonomen Systeme. Der Mensch wird zum strategischen Direktor und ethischen Aufseher.
Das kontextorientierte Unternehmen: Wir werden den Aufstieg von „Context Engines“ als Kernstück der Unternehmensinfrastruktur erleben.48 Unternehmen werden ihre Kontext-Pipelines als erstklassiges Produkt behandeln – versioniert, getestet und mit der gleichen Strenge gewartet wie ihre primären Anwendungen.39
6.3 Fazit: Kontext ist der neue Code
Während die Modelle weiter verbessert werden, wird der wahre Differenzierungsfaktor und die Quelle des Wettbewerbsvorteils die Qualität des Kontexts sein, den ein Unternehmen ihnen zur Verfügung stellen kann.49 Die Vision von KI-Agenten als primäres Ziel für Werbung, wie sie vom Gründer von Perplexity AI skizziert wurde, deutet auf einen seismischen Wandel in der digitalen Wirtschaft hin.30 Wenn Agenten, ausgestattet mit perfektem Kontext über unsere Vorlieben und Bedürfnisse, Kaufentscheidungen in unserem Namen treffen, würde die gesamte B2C-Marketing- und Werbebranche auf den Kopf gestellt. Der Fokus würde sich von der Erregung menschlicher Aufmerksamkeit mit emotionaler Werbung auf die Bereitstellung strukturierter, faktenbasierter Daten verlagern, die ein Agent analysieren kann, um eine optimale Entscheidung zu treffen. Dies würde eine neue „B2A“-Ökonomie (Business-to-Agent) schaffen und die Art und Weise, wie Produkte verkauft und entdeckt werden, grundlegend verändern.
Die abschließende Botschaft ist ein Aufruf zum Handeln: für Entwickler, Führungskräfte und Organisationen, ihren Fokus von der reinen Nutzung von KI auf die Architektur der intelligenten Systeme zu verlagern, die das nächste Jahrzehnt definieren werden. Die Beherrschung des Context Engineering ist nicht nur ein technischer Imperativ; es ist die strategische Grundlage für den Erfolg im Zeitalter der künstlichen Intelligenz.
[2501.07391] Enhancing Retrieval-Augmented Generation: A Study of Best Practices – arXiv, accessed July 3, 2025, https://arxiv.org/abs/2501.07391
[2504.20734] UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities – arXiv, accessed July 3, 2025, https://arxiv.org/abs/2504.20734
Seven Failure Points When Engineering a Retrieval Augmented Generation System – arXiv, accessed July 3, 2025, https://arxiv.org/abs/2401.05856
The Rise of Context Engineering: Why AI’s Future Depends on More Than Just Prompts #ainews #ai – YouTube, accessed July 3, 2025, https://www.youtube.com/watch?v=cfUV1nFjftE
Als Service für die Leser:innen unseres Buches „Kluge Köpfchen mit KI“ versuchen wir hier Licht ins Dunkel der KI-Tools zu bringen, die vielleicht schon bald zum Alltag eurer Kinder gehören – oder es bereits tun. Künstliche Intelligenz ist ein spannendes Feld, aber gerade wenn es um unsere Kinder geht, sollten wir genau wissen, womit sie es zu tun haben.
Dieser Artikel vergleicht bekannte KI-Anwendungen und schaut dabei ganz genau auf die Dinge, die für euch als Eltern wichtig sind: Wie gehen diese Tools mit Daten um? Was steht im Kleingedruckten? Und wie sicher ist das alles für junge Nutzer?
Wir nehmen folgende KI-Helferlein genauer unter die Lupe: OpenAI ChatGPT, Anthropic Claude, Microsoft Copilot, Google Gemini, Perplexity AI, Google NotebookLM, DuckDuckGo Duck.ai, Ecosia Chat, Mistral Le Chat und Meta AI. Das ist eine bunte Mischung aus Programmen von großen Tech-Firmen, spezialisierten KI-Schmieden und auch Anbietern, denen Datenschutz besonders am Herzen liegt.
Ziel ist es, euch verlässliche Infos an die Hand zu geben, damit ihr gemeinsam mit euren Kindern entscheiden könnt, welche dieser Werkzeuge passen und wie man sie sicher nutzt. Das ist umso wichtiger, da KI immer mehr Einzug in Schule, Freizeit und später auch den Beruf hält.
Alle Informationen hier stammen direkt von den Anbietern – aus ihren offiziellen Datenschutzerklärungen und Nutzungsbedingungen.
Wir schauen uns die KI-Tools anhand dieser neun Punkte an:
Webadresse des Tools: Wo findet ihr das KI-Tool im Internet?
Anbieter: Welche Firma steckt dahinter und wo hat sie ihren Sitz?
Link zur Datenschutzerklärung: Wo könnt ihr genau nachlesen, wie eure Daten geschützt werden?
Link zu den Nutzungsbedingungen: Was sind die Spielregeln für die Nutzung?
Mindestalter/Altersfreigabe: Ab welchem Alter darf euer Kind das Tool nutzen?
Kostenlos nutzbar? Kann man das Tool gratis ausprobieren, vielleicht mit ein paar Einschränkungen?
Nutzung ohne Anmeldung möglich? Muss man sich registrieren oder geht es auch ohne Konto?
Werden eingegebene Daten gespeichert? Was passiert mit den Texten und Fragen, die euer Kind eingibt?
Werden Daten für Trainingszwecke verwendet? Lernt die KI mit den Eingaben eures Kindes dazu? Falls ja, lässt sich dieser Nutzung widersprechen (Opt-out)?
Gerade beim Thema Datenschutz ist es oft so, dass es für Privatnutzer andere Regeln gibt als für Firmenkunden. Das ist ein wichtiger Punkt, den wir im Auge behalten. Oft ist es so, dass ein besserer Datenschutz bei den Bezahlversionen inklusive ist. Das ist gut zu wissen, wenn ihr überlegt, welches Tool für eure Familie das richtige ist.
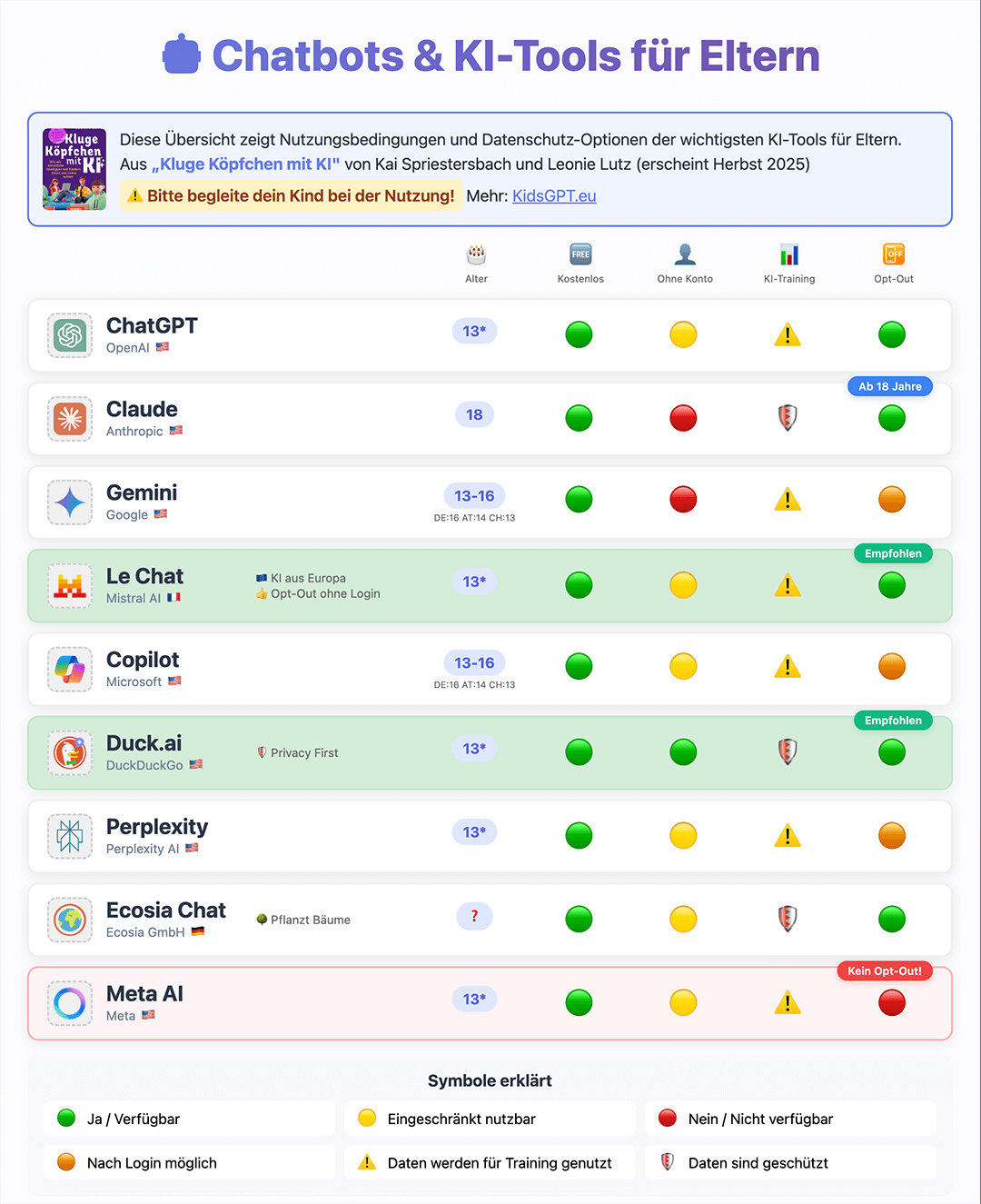
Die zehn wichtigsten KI-Tools auf einen Blick
Tool
Anbieter
Alter
Kostenlos
Ohne Anmeldung
KI Training
Opt-Out
ChatGPT
OpenAI 🇺🇸
13*
🟡
✅
⚠️
✅
Claude
Anthropic 🇺🇸
18
🟡
❌
⚠️
✅
Copilot
Microsoft 🇺🇸
🇩🇪 16 / 🇦🇹 14 / 🇨🇭 13
🟡
✅
⚠️
🟠
Gemini
Google 🇺🇸
🇩🇪 16 / 🇦🇹 14 / 🇨🇭 13
🟡
❌
⚠️
🟠
Perplexity
Perplexity AI 🇺🇸
13*
🟡
✅
⚠️
🟠
NotebookLM
Google 🇺🇸
🇩🇪 16 / 🇦🇹 14 / 🇨🇭 13
🟡
❌
🛡️
✅
Duck.ai
DuckDuckGo 🇺🇸
13*
✅
✅
🛡️
✅
Ecosia Chat
Ecosia GmbH 🇩🇪
❓
✅
✅
🛡️
✅
Le Chat
Mistral AI 🇫🇷
13*
🟡
✅
⚠️
✅
Meta AI
Meta 🇺🇸
13*
🟡
✅
⚠️
❌
Legende
✅ = Ja / Trifft zu ❌ = Nein / Trifft nicht zu 🟡 = Eingeschränkt / Nicht alle Funktionen ⚠️ = Vorsicht / Daten werden für Training verwendet 🛡️ = Daten werden nicht fürs KI-Training verwendet 🟠 = Opt-Out nur nach Login möglich ❓ = Unklar / Nicht eindeutig spezifiziert Die Altersangaben (z.B. 🇩🇪 16 / 🇦🇹 14 / 🇨🇭 13) sind direkt in der Tabelle ersichtlich. 13* = Bedeutet, ab 13 Jahren mit Erlaubnis der Eltern/Erziehungsberechtigten.
Unser Buch: „Kluge Köpfchen mit KI“ – Der erste Elternratgeber zum Thema KI
KI ist gekommen, um zu bleiben – und macht auch vor Kinderzimmern nicht Halt. Wir zeigen, wie ein sicherer und kreativer Umgang mit KI im Familien- und Schulalltag gelingt. Verstehe, wie KI funktioniert, entdecke bereichernde Tools fürs Lernen und erhalte praxisnahe Tipps für den Alltag – immer mit kritischem Blick auf die Risiken.
Wer steckt dahinter? ChatGPT kommt von OpenAI OpCo, LLC einer Firma aus den USA (San Francisco, Kalifornien).
Datenschutzinfos: Die genauen Regeln zum Datenschutz findet ihr hier: https://openai.com/de-DE/policies/eu-privacy-policy/. Für Nutzer*innen mit Wohnsitz im Europäischen Wirtschaftsraum (EWR) oder in der Schweiz ist OpenAI Ireland Limited mit Sitz in Dublin, Irland, der Verantwortliche für die in dieser Datenschutzerklärung beschriebene Verarbeitung der personenbezogenen Daten.
Mindestalter: Euer Kind muss mindestens 13 Jahre alt sein. Seid ihr als Eltern oder Erziehungsberechtigte einverstanden, dürfen auch Kinder unter 18 Jahren ChatGPT nutzen.
Kostenlos nutzbar? Ja, es gibt eine kostenlose Version. Damit kann man das Basismodell nutzen, aktuelle Infos aus dem Internet abrufen und nach einer Anmeldung eingeschränkt auch auf bessere Modelle wie GPT-4o und Funktionen wie das Hochladen von Dateien zugreifen.
Wichtig: Bei der kostenlosen Version können die eingegebenen Daten eures Kindes standardmäßig zum Trainieren der KI genutzt werden. Ihr könnt dieser Nutzung aber widersprechen.
Nutzung ohne Anmeldung? Ja, um ChatGPT zu nutzen, braucht man kein Konto.Speicherung von Daten? Ja, OpenAI speichert, was ihr eingebt (Texte, Fragen) und hochladet (Dateien, Bilder, Audio). Auch Chats, die nicht im Verlauf gespeichert werden, bleiben aus Sicherheitsgründen bis zu 30 Tage erhalten!
Daten für Trainingszwecke? Ja, die Inhalte, die ihr eingebt, können genutzt werden, um die KI-Modelle von ChatGPT zu trainieren und zu verbessern. Aber keine Sorge: Ihr habt die Möglichkeit, dieser Nutzung zu widersprechen (Opt-out).
Bei ChatGPT gibt es zwei getrennte Funktionen für mehr Datenschutz: Temporäre Chats werden generell nicht gespeichert und über »Modellverbesserung für alle« (»Improve the model for everyone«) lässt sich einstellen, ob deine Unterhaltungen zur Verbesserung von ChatGPT beitragen sollen oder nicht. Um zu verhindern, dass deine Chats zum Training verwendet werden, musst Du »Modellverbesserung für alle« deaktivieren.
Das Tolle: Auch ohne Anmeldung kannst Du festlegen, ob deine Chats fürs Training verwendet werden. Mit Anmeldung hast Du zusätzliche Optionen wie Datendownload oder Konto löschen.
Wenn du angemeldet bist:
Auf dein Profilbild klicken
»Einstellungen« → »Datenkontrollen«
»Modellverbesserung für alle« ausschalten
Wenn du nicht angemeldet bist:
Auf das »?« unten rechts klicken
»Einstellungen« auswählen
»Modellverbesserung für alle« ausschalten
Deine Unterhaltungen werden dann nicht mehr zum Trainieren von ChatGPT genutzt – erscheinen aber trotzdem im Verlauf (wenn du angemeldet bist).
Mindestalter: Man muss 18 Jahre alt sein, um Claude zu nutzen.
Kostenlos nutzbar? Ja, Claude Chat gibt es auch in einer kostenlosen Version mit ein paar Einschränkungen.
Nutzung ohne Anmeldung? Nein, für Claude braucht man ein Konto.
Speicherung von Daten? Ja, Nutzerdaten werden verschlüsselt gespeichert. Wenn dein Kind eine Unterhaltung löscht, wird sie innerhalb von 30 Tagen auch von den Servern von Anthropic entfernt. Daten im Zusammenhang mit Regelverstößen oder Feedback können länger gespeichert werden.
Daten für Trainingszwecke? Bisher hatte Anthropic die Nutzerchats mit Claude nicht verwendet, um die KI zu trainieren. Das änderte sich jedoch kürzlich – Nutzer*innen können dies aber bei der Anmeldung ablehnen. Eine Pflicht dazu gibt es also nicht.
Nutzungsregeln: Die allgemeinen Nutzungsbedingungen der Copilot AI stehen hier: www.bing.com/new/termsofuse.
Mindestalter: In Deutschland ab 16 Jahren, in Österreich ab 14, in der Schweiz ab 13 Jahren.
Kostenlos nutzbar? Ja, es gibt eine kostenlose Basis-Version.
Nutzung ohne Anmeldung? Ja, das geht, aber mit Einschränkungen. Personalisierte Funktionen gibt es dann nicht.
Speicherung von Daten? Ja. Unterhaltungen werden standardmäßig 18 Monate gespeichert, hochgeladene Dateien bis zu 30 Tage. Für die Firmen-Version (M365 Copilot) gelten andere Regeln.
Daten für Trainingszwecke? Ja, Microsoft nutzt Daten aus Co-Pilot-Gesprächen (anonymisierte Sprach- und Textunterhaltungen) für das KI-Training. Es gibt aber Ausnahmen für Firmenkunden und Nutzer von Microsoft 365-Abos. Angemeldete Nutzer können widersprechen.
Nach dem Einloggen erreichst Du die Datenschutzeinstellungen über das Benutzer-Icon oben rechts.
Unter »Konto« findest Du dort den Punkt »Datenschutz«, wo es die Optionen gibt, bei Unterhaltungen mit Copilot zu widersprechen, dass Microsoft seine KI trainieren und verbessern darf. Dafür die Punkte »Modelltraining anhand von Text« sowie »Modelltraining anhand von Sprache« deaktivieren.
Für noch mehr Datenschutz lässt sich unter »Personalisierung und Arbeitsspeicher« auch die Chat-Historie abschalten sowie verhindern, dass Unterhaltungen, Bing- und MSN-Aktivitäten sowie alle abgeleiteten Interessen für personalisierte Werbung verwendet werden.
Mindestalter: Die Gemini-App ist für Nutzer ab 13 Jahren (oder dem jeweiligen Mindestalter im Land) verfügbar. Gemini für Google Workspace und Gemini in bezahlten Accounts (z. B. Pro, Ultra) sind ab 18 Jahren erlaubt.
Das Mindestalter für Google-Konten ist meist 13 Jahre, beispielsweise in der Schweiz, kann aber regional abweichen: In Deutschland ist das Mindestalter 16 Jahre, in Österreich 14.
Kostenlos nutzbar? Ja. Die Gemini-App kann mit einem Google- Konto kostenlos und mit Schulkonten sogar mit besserem Datenschutz genutzt werden. Bestimmte Funktionen sind nur für Abonnenten von Pro- oder Ultra-Plänen verfügbar.
Nutzung ohne Anmeldung? Nein, für Gemini braucht man ein Google-Konto.
Speicherung von Daten? Ja. Aktivitäten in den Gemini-Apps (Fragen, Antworten) werden standardmäßig bis zu 18 Monate im Bereich »Meine Gemini-Apps-Aktivitäten« gespeichert; diese Einstellung kann man anpassen. Hochgeladene Dateien werden 48 Stunden gespeichert. Eingaben und Ausgaben können zur Verbesserung bis zu 24 Stunden zwischengespeichert werden.
Daten für Trainingszwecke? Bei den normalen Gemini-Apps können Unterhaltungen von menschlichen Prüfern angesehen und zur Verbesserung von Google-Produkten verwendet werden, außer die Funktion »Gemini-Apps-Aktivität« ist ausgeschaltet.
Wichtig: Standardmäßig ist die Funktion »Aktivitäten in Gemini-Apps« aktiviert und Daten werden für Trainingszwecke genutzt und 18 Monate gespeichert. Das Ausschalten dieser Einstellung unter https://myactivity.google.com/product/gemini ist also ein wichtiger Schritt für mehr Datenschutz.
Wer steckt dahinter? Perplexity AI, Inc., eine Firma aus den USA (San Francisco, Kalifornien). In der EU ist DataRep aus Cork in Irland deren Vertreter im Europäischen Wirtschaftsraum.
Mindestalter: Euer Kind muss mindestens 13 Jahre alt sein. Minderjährige, die schon 13 sind, aber noch nicht volljährig, dürfen die Dienste nur nutzen, wenn ein Elternteil oder Erziehungsberechtigter vorher zustimmt.
Kostenlos nutzbar? Ja, es gibt einen kostenlosen »Standard«-Plan, der aber Einschränkungen hat (z. B. nur drei Pro-Suchen pro Tag, maximal zehn Datei-Uploads pro Tag, keine Bilderzeugung).
Nutzung ohne Anmeldung? Ja, die Webversion kann man anfangs ohne Anmeldung nutzen. Ein Konto braucht man aber, um den Chatverlauf zu speichern und die Nutzung persönlicher zu gestalten.
Speicherung von Daten? Ja, Perplexity AI sammelt und speichert Daten.
Daten für Trainingszwecke? Ja, Suchanfragen und Feedback werden genutzt, um die Suche zu verbessern. Du kannst dieser Nutzung widersprechen (Opt-out), indem du den Schalter »AI Data Usage« in den Profileinstellungen ausschaltet, allerdings nur, wenn du eingeloggt bist.
Wichtig: In deinen Kontoeinstellungen kannst du die Verwendung deiner Suchdaten zur Verbesserung der KI-Modelle deaktivieren. Außerdem kannst du die Löschung deiner Daten anfordern, indem du eine E-Mail an support@perplexity.ai sendest.
Wer steckt dahinter? Google LLC, USA (Mountain View, Kalifornien).
Datenschutzinfos: Es gilt die allgemeine Google Datenschutzerklärung (https://policies.google.com/privacy). Es gibt auch einen speziellen Hinweis für NotebookLM. Für die Plus-Version im Rahmen von Workspace gelten zusätzliche Bedingungen.
Nutzungsregeln: Es gelten die allgemeinen Google Nutzungsbedingungen (https://policies.google.com/terms). Für NotebookLM Plus im Rahmen von Workspace gibt es zusätzliche Bedingungen.
Mindestalter: Hier gelten dieselben Bedingungen wie bei Googles Gemini: Das Mindestalter ist meist 13 Jahre, beispielsweise in der Schweiz, kann aber regional abweichen. In Deutschland 16 Jahre, in Österreich 14.
Kostenlos nutzbar? Ja, die Standardversion von NotebookLM ist mit einem Google-Konto kostenlos.
Nutzung ohne Anmeldung? Nein, für NotebookLM braucht man zwingend ein Google-Konto.
Speicherung von Daten? Ja, gemäß der Google Datenschutzerklärung. Für NotebookLM Plus im Rahmen von Workspace werden importierte Dateien, Fragen und Antworten vorübergehend gespeichert. Zusätzlich werden Servicedaten wie Kontoinfos und Nutzungsstatistiken erfasst.
Daten für Trainingszwecke? Explizit Nein. Google betont: »Wir legen Wert auf Ihre Privatsphäre und verwenden Ihre persönlichen Daten niemals zum Trainieren von NotebookLM.« Das ist ein großer Pluspunkt für den Datenschutz, besonders wenn sensible Daten verarbeitet werden.
DuckDuckGo Duck.ai
Wo zu finden? DuckDuckGo Duck.ai ist unter https://duck.ai erreichbar.
Wer steckt dahinter? DuckDuckGo, Inc., eine Firma aus den USA (Paoli, Pennsylvania), bekannt für ihre datenschutzfreundliche Suchmaschine.
Mindestalter: Euer Kind muss mindestens 13 Jahre alt sein. Ist es minderjährig, aber mindestens 13, ist die Erlaubnis eines Elternteils oder Erziehungsberechtigten nötig.
Kostenlos nutzbar? Ja, Duck.ai wird als kostenlose Funktion angeboten.
Nutzung ohne Anmeldung? Ja. Die Suchmaschine DuckDuckGo braucht generell keine Registrierung, und Duck.ai ist darin integriert.
Speicherung von Daten? Nein, Fragen und Antworten werden nicht auf den Servern von DuckDuckGo gespeichert. Kürzlich erstellte Chats können optional lokal auf dem Gerät gespeichert und automatisch nach 30 Unterhaltungen oder durch eine Aktion gelöscht werden. Persönliche Infos wie die IP-Adresse werden entfernt, bevor Anfragen an die eigentlichen KI-Modellanbieter gesendet werden.
Daten für Trainingszwecke? Nein. Unterhaltungen werden weder von DuckDuckGo noch von den genutzten Drittanbietern der Modelle (wie OpenAI, Anthropic) für das Training von Chatmodellen verwendet. DuckDuckGo hat Vereinbarungen mit diesen Anbietern, die eine Nutzung für Modellentwicklung ausschließen. Das ist ein sehr starker Datenschutzansatz!
Mindestalter: Das wird nicht genau gesagt. Die allgemeinen Nutzungsbedingungen von Ecosia nennen kein spezifisches Alter.
Kostenlos nutzbar? Ja. Die Suchmaschine Ecosia ist kostenlos. Ecosia Chat ist eine Funktion davon.
Nutzung ohne Anmeldung? Die Ecosia-Suche und auch Ecosia Chat funktionieren ohne Registrierung.
Speicherung von Daten? Für Ecosia Chat werden Eingaben an die Server von OpenAI übertragen. Diese Daten werden von OpenAI nach 30 Tagen gelöscht. Ecosia selbst speichert Suchanfragen zur Verbesserung des eigenen Dienstes, aber keine persönlichen Infos im Chat.
Daten für Trainingszwecke? Nein, die an OpenAI übermittelten Daten aus Ecosia Chat-Gesprächen werden nicht zum Trainieren der Modelle von OpenAI verwendet. Ecosia selbst kann anonymisierte Suchanfragen zur Verbesserung des eigenen Suchdienstes nutzen, was sich nicht abschalten lässt.
Mindestalter: Das Mindestalter ist 13 Jahre. Minderjährige brauchen die Erlaubnis eines Elternteils oder Erziehungsberechtigten, um ein Konto zu erstellen.
Kostenlos nutzbar? Ja, die meisten Funktionen sind kostenlos verfügbar. Es gibt eine kostenlose Stufe mit einem großzügigen täglichen Limit für Anfragen.
Nutzung ohne Anmeldung? Ja, für Le Chat braucht man kein Konto bei Mistral AI.Speicherung von Daten? Ja, Eingaben und Ausgaben für Le Chat werden gespeichert.
Daten für Trainingszwecke? Ja, bei kostenlosen Abos sowie der Le Chat Pro- oder Le Chat Student-Version können Eingaben und Ausgaben für das Training der Modelle verwendet werden, außer man hat widersprochen (Opt-out). Feedback (Daumen hoch/runter) und die zugehörigen Daten werden auch für Trainingszwecke genutzt. Daten von Nutzern der Le Chat Team- oder Firmen-Version werden nicht für das Training verwendet.
Du solltest der Verwendung deiner Daten in den Kontoeinstellungen widersprechen. Dazu klickst du auf das kleine Zahnrad-Symbol oben links und dann auf »Datenschutz«. Dort findest Du die Option »Erlaube die Nutzung deiner Interaktionen zur Verbesserung unserer Dienste« und kannst sie deaktivieren.
Meta AI
Wo zu finden? Meta AI ist unter https://www.meta.ai/ sowie in Facebook, Instagram, WhatsApp, Messenger, Threads und auf Geräten wie den Ray-Ban Meta Smart Glasses sowie Meta Quest verfügbar.
Wer steckt dahinter? Meta Platforms, Inc. (ehemals Facebook, Inc.), ein US-amerikanisches Unternehmen mit Sitz in Menlo Park, Kalifornien. Für Nutzer*innen in der EU ist Meta Platforms Ireland Limited in Dublin, Irland, Ansprechpartner.
Mindestalter: Du musst mindestens 13 Jahre alt sein, um Meta AI zu nutzen.
Kostenlos nutzbar? Ja, die Nutzung von Meta AI ist kostenlos.
Nutzung ohne Anmeldung? Ja, für die Nutzung von Meta AI benötigst du kein Konto.
Speicherung von Daten? Ja, Meta speichert Interaktionen mit Meta AI, einschließlich deiner Eingaben und der generierten Antworten. Diese Daten können verwendet werden, um die Dienste zu verbessern.
Daten für Trainingszwecke? Ja, seit dem 27. Mai 2025 nutzt Meta öffentliche Inhalte von Nutzer*innen in der EU, wie Beiträge und Kommentare auf Facebook und Instagram, zur Verbesserung seiner KI-Modelle. Private Nachrichten und Inhalte von Minderjährigen sind davon ausgenommen. Du kannst der Verwendung deiner öffentlichen Daten für Trainingszwecke widersprechen, allerdings nicht in den Chats mit Metas KI. Je nachdem ob du die Webseite oder App auf PC, Tablet oder Smartphone nutzt, kann der Prozess etwas anders aussehen.
Beachte, dass deine Daten, auch wenn du keinen Meta-Account hast, durch Dritte (z. B. wenn du auf Fotos markiert wirst) verwendet werden könnten. In diesem Fall kannst du ebenfalls Widerspruch einlegen.
Was bedeutet das für Eltern?
Dieser Vergleich zeigt: Es gibt große Unterschiede zwischen den KI-Tools, was ihre Funktionen, Kosten und vor allem den Umgang mit Daten angeht. Welches Tool für deine Familie am besten passt, hängt davon ab, was euch wichtig ist.
Ein Knackpunkt ist, wie die Anbieter die Daten eurer Kinder für das Training der KI nutzen. Manche tun es standardmäßig und ihr müsst aktiv »Nein« sagen. Andere fragen vorher um Erlaubnis oder verzichten ganz darauf, besonders bei Bezahl-Versionen. Das ist ein riesiger Unterschied für die Kontrolle, die ihr über die Daten eurer Kinder habt. Die KI-Welt entwickelt sich rasant, und es gibt noch keine weltweit einheitlichen Regeln.
Die meisten Tools kann man kostenlos testen, aber oft braucht man ein Konto, um alle Funktionen nutzen zu können. Die Altersgrenzen sind ein Wirrwarr und für euch als Eltern und für Schulen eine Herausforderung. Es scheint, dass Firmen aus der EU oft strengere Datenschutzregeln haben, was wohl an Gesetzen wie der DSGVO liegt.
Wichtig für euch: Die KI-Technologie und die Regeln dafür ändern sich ständig. Schaut euch also regelmäßig die Nutzungsbedingungen und Datenschutzeinstellungen der Tools an, die eure Kinder nutzen. Es wird immer wichtiger, dass wir alle verstehen, was Begriffe wie »Daten für Trainingszwecke« oder »Opt-out« bedeuten. Nur so kannst du dich und dein Kind verantwortungsvoll in der digitalen Welt bewegen. Dieser Abschnitt soll dir helfen, KI-Tools nicht nur nach ihren Funktionen, sondern auch kritisch nach ihrem Umgang mit Daten zu bewerten, bevor du ihnen deine Informationen und die deines Kindes anvertraust.
Infografik: Chatbots & KI-Tools für Eltern
Wichtiger Hinweis zu den Informationen
Liebe Leserin, lieber Leser,
die Informationen in diesem Kapitel wurden mit größter Sorgfalt und nach bestem Wissen und Gewissen zum Zeitpunkt der Recherche zusammengestellt. Die Welt der KI-Technologie und die Richtlinien der Anbieter ändern sich jedoch sehr schnell.
Daher können wir keine Garantie für die jederzeitige Richtigkeit und Vollständigkeit aller hier gemachten Angaben übernehmen.
Es ist möglich, dass Anbieter ihre Nutzungsbedingungen, Datenschutzerklärungen oder Funktionen kurzfristig ändern. Die hier dargestellten Informationen dienen als Orientierung und Momentaufnahme.
Die Verantwortung für die Nutzung der genannten KI-Tools und die Überprüfung der jeweils aktuellen Bedingungen liegt immer bei dir bzw. bei euch als Eltern.
Bitte informiere dich regelmäßig direkt bei den Anbietern über deren aktuelle Richtlinien, bevor du oder dein Kind diese Dienste nutzen. Dieser Text ersetzt nicht die eigene sorgfältige Prüfung der jeweiligen Anbieterinformationen.
Wir hoffen, dieser Überblick hilft dir dennoch, eine fundierte Entscheidung zu treffen!
Kennst du das Gefühl, wenn dich eine Geschichte so sehr fesselt, dass du alles um dich herum vergisst? Wenn die Zeit verfliegt und du gar nicht anders kannst, als weiterzulesen oder zuzuhören? Solche Momente sind kein Zufall – sie sind das Ergebnis gekonnten Storytellings.
Gute Geschichten berühren uns auf einer tiefen, emotionalen Ebene. Sie bleiben in unseren Köpfen und Herzen, lange nachdem wir sie gehört haben. Doch was macht den Unterschied zwischen einer Geschichte, die uns packt, und einer, die wir schnell wieder vergessen?
Genau diese Magie wollen wir heute entschlüsseln. Denn großartige Geschichten entstehen nicht zufällig – sie folgen bestimmten Prinzipien. In diesem Artikel zeige ich dir die sechs wichtigsten Storytelling-Techniken, die ich in diesem YouTube-Video gefunden habe und die deine Geschichten von gut zu unvergesslich machen.
Warum ist Storytelling so wichtig?
Bevor wir in die Techniken eintauchen, lass uns kurz darüber nachdenken, warum Storytelling überhaupt so kraftvoll ist. Unser Gehirn ist auf Geschichten programmiert. Wenn wir Fakten in eine Geschichte verpacken, werden sie:
besser verstanden
länger behalten
emotional verankert
häufiger geteilt
Aber genug der Theorie – lass uns in die praktischen Techniken eintauchen!
Der Tanz zwischen Kontext und Konflikt
Stell dir vor, du sitzt in einem gemütlichen Café. Die Sonne scheint durch die großen Fenster, der Duft von frischem Kaffee liegt in der Luft, und du beobachtest die Menschen um dich herum. Eine friedliche Szene – bis plötzlich die Tür aufgerissen wird und jemand hereingestürmt kommt, völlig außer Atem. Was passiert in diesem Moment mit dir? Richtig, du bist sofort aufmerksam. Was ist passiert? Warum diese Eile?
Genau das ist der „Tanz“ des Storytellings: Ein sorgfältig choreographierter Wechsel zwischen ruhigen Momenten, in denen wir Kontext aufbauen, und spannungsgeladenen Konflikten, die uns an der Geschichte festhalten. Dieser Rhythmus ist tief in unserer Psychologie verankert.
Der grundlegende Rhythmus besteht aus zwei Elementen:
Kontext: Hier baust du die Szene auf, gibst Informationen, lässt die Leser:innen sich orientieren
Konflikt: Hier kommt die Überraschung, die Wendung, das Problem
Ein Beispiel gefällig?
Kontext: „Marie liebte ihren Job als Grafikdesignerin. Jeden Morgen fuhr sie mit dem Rad ins Büro, trank ihren Kaffee und startete kreativ in den Tag.“
Konflikt: „Bis zu dem Morgen, als sie ihre Kündigung im Postfach fand.“
Neuer Kontext: „Sie brauchte dringend einen Plan B, um ihre Miete zu zahlen.“
Neuer Konflikt: „Aber alle ihre Bewerbungen blieben unbeantwortet.“
Merkst du, wie dich dieser Wechsel durch die Geschichte zieht?
Die Schöpfer von South Park, Matt Stone und Trey Parker, haben dafür eine brillante Formel entwickelt. Sie vermeiden in ihren Geschichten bewusst die Verbindung „und dann“, die oft zu einer monotonen Aneinanderreihung von Ereignissen führt. Stattdessen verwenden sie „deshalb“ oder „aber“, um eine natürliche Kausalität oder einen spannenden Konflikt zu erzeugen.
Lass uns ein Beispiel betrachten:
Eine schwache Geschichte würde so klingen:
„Sarah ging zur Arbeit und dann traf sie einen alten Freund und dann gingen sie Kaffee trinken und dann erzählte er ihr von seinem neuen Projekt.“
Die gleiche Geschichte, aber mit der South-Park-Methode:
„Sarah eilte zur Arbeit, aber auf dem Weg lief sie in einen alten Freund. Sie wollte eigentlich pünktlich sein, aber seine Geschichte klang so spannend, deshalb lud sie ihn spontan auf einen Kaffee ein. Was er ihr dann erzählte, sollte ihr Leben für immer verändern…“
Spürst du den Unterschied? Die zweite Version zieht dich hinein, schafft Spannung und macht neugierig auf mehr.
Der Rhythmus deiner Geschichte
Wenn wir über den Rhythmus einer Geschichte sprechen, geht es um weit mehr als nur die Abfolge von Ereignissen. Es geht um den Fluss der Worte, den Wechsel zwischen kurzen und langen Sätzen, zwischen schnellen und langsamen Momenten. Denk an deine Lieblingsmusik – was macht sie besonders? Wahrscheinlich nicht die monotone Wiederholung einer einzelnen Note, sondern der dynamische Wechsel zwischen verschiedenen Elementen.
In der Praxis bedeutet das, mit der Länge und Struktur deiner Sätze zu spielen. Ein kurzer, prägnanter Satz kann wie ein Paukenschlag wirken. Ein längerer Satz hingegen gibt dir die Möglichkeit, eine Szene ausführlich zu malen, Details einzuflechten und deine Leser oder Zuhörer in die Situation hineinzuziehen.
Der legendäre Autor Gary Provost demonstrierte dies eindrucksvoll in seinem berühmten „Write Music“-Beispiel. Hier ist meine Übersetzung und Adaption:
„Dieser Satz hat fünf Worte. Hier sind fünf weitere Worte. Fünf-Wort-Sätze sind gut geeignet. Aber mehrere hintereinander werden monoton. Der Klang wird schnell langweilig. Es klingt wie eine kaputte Platte. Das Ohr sehnt sich nach Abwechslung. Jetzt variiere ich die Satzlänge, und plötzlich klingt alles wie Musik. Schöne Musik. Ein Text, der singt. Er hat einen angenehmen Rhythmus, eine sanfte Melodie, eine Harmonie. Die Worte tanzen über die Seite. Sie ziehen den Leser mit sich. Und manchmal, wenn ich mir sicher bin, dass der Leser entspannt ist und im Fluss der Worte schwimmt, schreibe ich einen längeren Satz, der sich aufbaut wie eine Welle, der Energie sammelt und wächst, bis er schließlich in einem crescendoartigen Finale zu seinem Höhepunkt kommt.“
Die Macht der Variation
Hier ist ein Beispiel, wie unterschiedliche Satzlängen einen Text lebendig machen:
Monoton: „Er ging zum Bahnhof. Er kaufte ein Ticket. Er stieg in den Zug. Er fuhr nach Hause.“
Lebendig: „Hastig eilte er zum Bahnhof. Der letzte Zug würde in wenigen Minuten abfahren. Während er sein Ticket zückte und durch die Sperre hastete, hörte er bereits das charakteristische Pfeifen der sich schließenden Türen. Er rannte.“
Praktischer Tipp
Schreibe jeden Satz in eine neue Zeile. Wenn du den Text von der Seite betrachtest, sollte er wie eine Zackenlinie aussehen – nicht wie ein gleichmäßiger Block.
Die Bedeutung der richtigen Tonalität
Eine der größten Herausforderungen im Storytelling ist es, die richtige Tonalität zu finden. In einer Welt, die von professioneller Kommunikation und geschliffenen Marketing-Botschaften geprägt ist, sehnen sich Menschen nach Authentizität. Sie wollen keine perfekt polierten Vorträge hören, sondern echte Gespräche führen.
Die erfolgreichsten Content Creator unserer Zeit – denk an Menschen wie Emma Chamberlain oder Casey Neistat – haben eines gemeinsam: Sie sprechen mit ihrem Publikum, nicht zu ihnen. Wenn du ihre Videos anschaust oder ihre Texte liest, fühlst du dich, als würdest du mit einem guten Freund am Küchentisch sitzen.
Diese Fähigkeit ist kein Zufall. Steve Jobs beispielsweise arbeitete jahrelang daran, seine Präsentationen so natürlich und gesprächt wie möglich erscheinen zu lassen. Er wusste: Wenn Menschen das Gefühl haben, persönlich angesprochen zu werden, sind sie viel eher bereit, sich auf deine Geschichte einzulassen.
Wie kannst du diese Natürlichkeit in deine eigenen Geschichten bringen? Ein bewährter Trick ist es, sich beim Schreiben oder Sprechen eine konkrete Person vorzustellen. Nicht ein abstraktes Publikum, sondern einen echten Menschen, den du kennst und magst. Stelle dir vor, du erzählst dieser Person deine Geschichte bei einer Tasse Kaffee.
Vom Vortrag zum Gespräch
Vergleiche diese beiden Versionen:
Förmlich: „Im Folgenden werden die Aspekte erfolgreicher Kommunikation erläutert.“
Persönlich: „Lass uns mal darüber sprechen, wie du deine Botschaft wirklich rüberbringen kannst.“
Der Freundes-Trick
Ein super Trick: Stelle dir beim Schreiben eine:n bestimmte:n Freund:in vor. Noch besser: Klebe ein Foto von ihr/ihm an deinen Monitor. Schreibe so, als würdest du nur mit dieser Person sprechen.
Die Kraft der Richtung
Eine der überraschendsten Erkenntnisse im Storytelling ist, dass die besten Geschichten nicht am Anfang, sondern am Ende beginnen. Denk einen Moment darüber nach: Die wirklich großen Geschichtenerzähler – ob Christopher Nolan in seinen komplexen Filmen oder die Autoren packender Romane – wissen bereits beim ersten Wort genau, wo ihre Geschichte enden wird.
Warum ist das so wichtig? Weil das Ende deiner Geschichte wie ein Leuchtturm ist. Es gibt allem, was davor kommt, Bedeutung und Richtung. Jedes Detail, jede Wendung, jeder Moment führt zu diesem finalen Punkt. Ohne diesen Leuchtturm läufst du Gefahr, dich in interessanten, aber letztlich bedeutungslosen Nebensträngen zu verlieren.
In der Welt der Kurzform-Medien, sei es auf TikTok, Instagram oder LinkedIn, spielt das Ende eine noch wichtigere Rolle. Hier sprechen wir vom „Last Dab“ – dem letzten Eindruck, der so stark sein muss, dass die Menschen ihn mit anderen teilen wollen. Bei Kurzvideos sollte dieser letzte Moment sogar elegant zum Anfang zurückführen, um nahtlose Wiederholungen zu ermöglichen.
Ein praktisches Beispiel: Stell dir vor, du möchtest eine Geschichte über eine überraschende Lernerfahrung erzählen. Anstatt einfach chronologisch zu beginnen, definierst du zuerst dein Ende: Die unerwartete Erkenntnis, dass manchmal der größte Fehler zum wertvollsten Lernerfolg führen kann. Von diesem Punkt aus kannst du nun rückwärts planen und jeden Teil deiner Geschichte so gestalten, dass er diese finale Einsicht verstärkt.
Der Last-Dab-Effekt
Dein letzter Satz, deine finale Pointe – das ist dein „Last Dab“. Er muss so stark sein, dass die Leser:innen ihn mit anderen teilen wollen. Bei Kurzvideos sollte er sogar zum Anfang zurückführen, um Loops zu ermöglichen.
Praktische Umsetzung
Schreibe zuerst dein Ende
Dann deinen Anfang
Fülle dann die Mitte mit deinem Kontext-Konflikt-Tanz
Story-Linsen: Dein einzigartiger Blickwinkel
In einer Welt, in der täglich Millionen von Geschichten erzählt werden, ist es eine besondere Herausforderung, eine eigene, unverwechselbare Stimme zu finden. Hier kommt das Konzept der Story-Linse ins Spiel – dein ganz persönlicher Blickwinkel auf ein Thema.
Stell dir einen Lichtstrahl vor, der auf ein Prisma trifft. Das weiße Licht wird in ein Spektrum wunderschöner Farben aufgefächert. Genauso verhält es sich mit Geschichten: Ein und dasselbe Ereignis kann durch verschiedene Linsen betrachtet ganz unterschiedliche Aspekte offenbaren.
Nehmen wir ein aktuelles Beispiel: Als Taylor Swift beim Super Bowl erschien, entstanden tausende von Geschichten. Die offensichtlichen Linsen fokussierten sich auf ihr Outfit, ihre Reaktionen oder ihre Beziehung zum Football-Star. Doch die wirklich interessanten Geschichten entstanden durch ungewöhnliche Perspektiven: Ein Wirtschaftsanalyst betrachtete den Einfluss ihrer Anwesenheit auf die NFL-Einschaltquoten und den damit verbundenen Wertzuwachs. Ein Soziologe untersuchte, wie ihr Erscheinen die traditionelle Football-Fankultur veränderte. Ein Marketing-Experte analysierte die brillante Vernetzung verschiedener Markenwelten.
Deine eigene Story-Linse entwickelt sich aus deiner einzigartigen Kombination von Erfahrungen, Expertise und Perspektiven. Vielleicht bist du Psychologin mit einer Leidenschaft für Gartenarbeit – dann könntest du über die therapeutische Wirkung des Gärtnerns erzählen. Oder du bist Mathematiker und Hobbykoch – dann liegt deine einzigartige Perspektive vielleicht in der Verbindung von Rezepten mit mathematischen Prinzipien.
Das Taylor Swift Beispiel
Als Taylor Swift beim Super Bowl war, gab es tausende Stories. Die meisten konzentrierten sich auf:
ihr Outfit
ihre Reaktionen
ihre Beziehung
Aber die wirklich interessanten Stories nahmen unerwartete Perspektiven ein:
Wie ihr Erscheinen die NFL-Einschaltquoten beeinflusste
Wie sich die Football-Fankultur dadurch veränderte
Welche Marketing-Lektionen sich daraus lernen ließen
Finde deine Linse
Was ist deine spezielle Expertise?
Welche einzigartigen Erfahrungen hast du?
Welche überraschenden Verbindungen siehst du?
Der Hook: Die Kunst des ersten Moments
In der digitalen Welt gleicht jeder erste Moment einem Händedruck. Er entscheidet binnen Sekunden, ob jemand in deiner Geschichte verweilt oder weiterzieht. Dieser entscheidende Moment – der Hook – ist wie der Köder beim Angeln: Er muss so unwiderstehlich sein, dass dein Publikum gar nicht anders kann, als anzubeißen.
Doch was macht einen Hook wirklich effektiv? Die Antwort liegt in der Kombination von zwei kraftvollen Elementen: dem verbalen und dem visuellen Hook. Stell dir vor, du öffnest eine Tür. Der verbale Hook ist, was du sagst, wenn du eintrittst. Der visuelle Hook ist, wie du dabei aussiehst. Beide müssen perfekt harmonieren, um den stärksten ersten Eindruck zu hinterlassen.
Der verbale Hook folgt dabei einer klaren Formel: Er kombiniert ein unerwartetes Element mit einem klaren Versprechen und einem zeitlichen Rahmen. „Diese vergessene Gartentechnik der Maya verdoppelte meine Tomatenernte in nur drei Wochen“ ist weitaus packender als „Heute zeige ich euch, wie ihr mehr Tomaten ernten könnt.“
Noch wichtiger als der verbale ist jedoch der visuelle Hook. Unser Gehirn verarbeitet Bilder 60.000 Mal schneller als Text. Wenn du über einen erfolgreichen Gemüsegarten sprichst, zeige nicht dich beim Reden, sondern direkt die üppigen Pflanzen. Lass die Bilder für sich sprechen, bevor du ein einziges Wort sagst.
Kevin von Epic Gardening macht das meisterhaft: Bevor er auch nur ein Wort über Erdbeeren verliert, zeigt er eine saftig-rote, perfekt gereifte Frucht in Großaufnahme. Das Bild weckt sofort Emotionen und Erinnerungen – vielleicht an den Geschmack frischer Erdbeeren im Sommer oder an den eigenen Garten in der Kindheit. Erst dann beginnt er zu sprechen, aber da hat er sein Publikum bereits emotional gepackt.
Die zwei Säulen eines starken Hooks
1. Verbaler Hook
Schwach: „Heute zeige ich euch etwas…“ Stark: „Diese ungewöhnliche Methode verdoppelte meine Produktivität in einer Woche“
2. Visueller Hook
Der visuelle Hook ist zehnmal wichtiger als der verbale. Warum? Weil unser Gehirn Bilder schneller verarbeitet als Worte.
Beispiel: Bei einem Video über Gartenarbeit zeigst du nicht dich beim Reden, sondern sofort die üppigen Tomaten, über die du gleich sprechen wirst.
Denn während einzelne KI-Agenten bereits beeindruckende Leistungen zeigen können, liegt das wahre Potenzial in ihrer geschickten Kombination. Ähnlich wie in einem gut eingespielten Team können auch KI-Agenten ihre individuellen Stärken am besten ausspielen, wenn sie effektiv zusammenarbeiten. Doch wie organisiert man eine „virtuelle Belegschaft“ so, dass sie optimal funktioniert?
Die größte Herausforderung liegt dabei überraschenderweise nicht in der technischen Umsetzung, sondern in der Wahl der richtigen Organisationsstruktur. Wie in einem Orchester müssen alle Beteiligten perfekt aufeinander abgestimmt sein. Ein falscher Aufbau kann selbst die leistungsfähigsten Agenten ausbremsen – genauso wie ein chaotisches Projektmanagement selbst die besten Mitarbeiter ineffizient macht.
Stellen Sie sich vor, Sie möchten ein komplexes Dokument erstellen. Sie könnten die gesamte Arbeit einem einzigen KI-Modell überlassen – oder Sie nutzen die Stärken verschiedener Spezialisten. So wie in einem erfolgreichen Unternehmen verschiedene Abteilungen Hand in Hand arbeiten, können auch KI-Agenten ihre individuellen Stärken ausspielen.
Die größte Herausforderung liegt dabei nicht in der technischen Umsetzung, sondern in der Wahl der richtigen Organisationsstruktur. Wie in einem Orchester müssen alle Beteiligten perfekt aufeinander abgestimmt sein. Ein falscher Aufbau kann selbst die leistungsfähigsten Agenten ausbremsen – genauso wie ein chaotisches Projektmanagement selbst die besten Mitarbeiter ineffizient macht.
In der Praxis mit Multi-Agent-Systemen haben sich fünf grundlegende Organisationsformen herauskristallisiert, die jeweils ihre ganz eigenen Stärken und optimalen Einsatzgebiete haben. Vielen Dank an dieser Stelle an Aparna Dhinakaran für ihre tollen Visualisierungen.
Der klassische Zwei-Agenten-Dialog
Beginnen wir mit der einfachsten Form: Dem Dialog zwischen zwei Agenten. Stellen Sie sich das wie ein Ping-Pong-Spiel vor, bei dem zwei KIs sich gegenseitig Bälle zuspielen. Ein Agent macht einen Vorschlag, der andere prüft und verbessert ihn, gibt Feedback zurück – und so geht es hin und her, bis das Ergebnis perfekt ist.
Ein praktisches Beispiel: Bei der Erstellung von Marketing-Texten könnte ein Agent als kreativer Autor fungieren, während der andere die Rolle des kritischen Lektors übernimmt. Der erste Agent schreibt einen Text, der zweite prüft ihn auf Stil, Zielgruppenausrichtung und Marketing-Best-Practices. Durch diesen iterativen Prozess entstehen Texte, die sowohl kreativ als auch strategisch optimiert sind.
Die Group-Chat-Revolution
Deutlich komplexer, aber auch leistungsfähiger ist der Group-Chat-Ansatz. Hier übernimmt ein zentraler Manager-Agent die Rolle des Dirigenten, der verschiedene Spezialisten koordiniert. In der Praxis sehen wir das zum Beispiel bei der Entwicklung komplexer Software-Lösungen.
Ein konkretes Beispiel aus meiner eigenen Erfahrung: Bei der Entwicklung eines KI-gestützten Analysesystems hatten wir einen Manager-Agent, der mit drei Spezialisten zusammenarbeitete: einem SQL-Experten für Datenbankabfragen, einem Analyse-Spezialisten für die Auswertung und einem Dokumentations-Agenten für die Aufbereitung der Ergebnisse. Der Manager koordinierte die Aufgaben, stellte sicher, dass alle Informationen richtig flossen und die Ergebnisse den Anforderungen entsprachen.
Sequentielle Prozesse: Der Fließband-Ansatz
Manchmal ist der beste Weg der gradlinigste. Bei der sequentiellen Organisation arbeiten die Agenten wie an einem Fließband: Einer nach dem anderen, jeder mit seiner spezifischen Aufgabe. Das klingt zunächst weniger spannend als der Group-Chat, ist aber für bestimmte Aufgaben genau richtig.
Ein Paradebeispiel ist die Content-Produktion: Der erste Agent erstellt einen Rohentwurf, der nächste optimiert die Struktur, ein dritter feilt am Stil, und der letzte Agent führt die finale Qualitätskontrolle durch. Wie bei einer gut geölten Maschine greift hier ein Zahnrad ins andere.
Direkte Verbindungen: Das Netzwerk-Modell
Besonders spannend wird es beim direkten Agent-zu-Agent-Modell. Hier gibt es keinen zentralen Manager – stattdessen kommunizieren alle Agenten direkt miteinander, ähnlich wie in einem sozialen Netzwerk. Das mag zunächst chaotisch klingen, hat aber einen entscheidenden Vorteil: maximale Flexibilität.
Ein faszinierendes Beispiel dafür erlebte ich bei einem Projekt zur Marktanalyse. Vier spezialisierte Agenten – einer für Finanzdaten, einer für Social-Media-Trends, einer für Nachrichtenanalyse und einer für Verbraucherverhalten – arbeiteten parallel und tauschten kontinuierlich Erkenntnisse aus. Wenn einer eine wichtige Information entdeckte, konnte er sofort alle anderen informieren. Das Ergebnis? Eine deutlich umfassendere und aktuellere Analyse als bei starren Strukturen.
Die klassische Hierarchie
Zu guter Letzt haben wir die hierarchische Organisation – sozusagen das klassische Unternehmensmodell unter den Multi-Agent-Systemen. Ein Manager-Agent an der Spitze, darunter verschiedene Ebenen von spezialisierten Agenten. Dieser Ansatz glänzt besonders bei komplexen Projekten, die klare Verantwortlichkeiten erfordern.
Stellen Sie sich etwa die Entwicklung eines autonomen Fahrzeugs vor: An der Spitze steht ein strategischer Manager-Agent, der die Gesamtentwicklung koordiniert. Darunter arbeiten Agenten für verschiedene Systembereiche wie Sensorik, Navigation und Sicherheit, die wiederum spezialisierte Sub-Agenten für einzelne Komponenten steuern.
Der Schlüssel zum Erfolg
Die Kunst liegt nicht darin, sich für ein System zu entscheiden und dabei zu bleiben. Vielmehr geht es darum, die verschiedenen Ansätze clever zu kombinieren und an die jeweiligen Anforderungen anzupassen. In vielen erfolgreichen Projekten finden wir zum Beispiel sequentielle Prozesse innerhalb einer Group-Chat-Struktur oder hierarchische Elemente in direkten Agent-zu-Agent-Systemen.
Was ich in zahllosen Projekten gelernt habe: Der Erfolg eines Multi-Agent-Systems hängt weniger von der reinen Leistungsfähigkeit der einzelnen Agenten ab, sondern vielmehr von ihrer optimalen Organisation und Zusammenarbeit. Genau wie in einem menschlichen Team macht auch hier die richtige Struktur oft den entscheidenden Unterschied zwischen Mittelmäßigkeit und Exzellenz.
Fazit und Ausblick
Multi-Agent-Systeme sind keine vorübergehende Mode, sondern die Zukunft der KI-Entwicklung. Sie ermöglichen uns, komplexe Aufgaben mit einer Präzision und Effizienz zu bewältigen, die mit einzelnen Agenten kaum denkbar wäre. Der Schlüssel liegt darin, die verschiedenen Organisationsformen zu verstehen und gezielt einzusetzen.
Die spannende Frage für die Zukunft wird sein, wie sich diese Systeme weiterentwickeln. Werden wir noch komplexere Organisationsformen sehen? Werden sich die Grenzen zwischen den verschiedenen Ansätzen weiter verwischen? Die Entwicklung steht erst am Anfang, und ich bin gespannt, welche innovativen Lösungen wir in den nächsten Jahren sehen werden.
Als leidenschaftlicher Podcaster spielte ich immer wieder mit dem Gedanken, einen neuen Podcast aufzunehmen. Mein Lieblingsthema ist natürlich Künstliche Intelligenz. Doch bislang hat mich der immense Zeitaufwand abgeschreckt. Aufnahme, Schnitt, Audiobearbeitung, Upload, Metadatenpflege, Hosting und Shownotes erforderten den Einsatz zahlreicher Tools und kosteten mich unzählige Stunden. Vor Kurzem habe ich Podcastle entdeckt und sah zum ersten Mal eine echte Chance, wieder selbst zu podcasten!
Nach drei Monaten intensiver Nutzung von Podcastle für meinen Podcast „Synapsensprung“ muss ich jedoch eine ernüchternde Bilanz ziehen…
Was ist Podcastle?
Podcastle bewirbt sich als All-in-One-Lösung, die den Zugang zum Podcasting durch KI-gestützte Tools vereinfachen soll. Die Realität sieht leider anders aus.
Die Produkte
Die Produkte und ihre Schwächen:
1. Aufnahmestudio
Das Aufnahmestudio von Podcastle ist eine echte Bereicherung für Podcaster. Es verspricht Studioqualität von überall aus, sowohl für Audio- als auch Videoaufnahmen.
Audioaufnahmen: Unkomprimierte 48kHz WAV-Audio für jeden Gast sorgt für kristallklare Tonqualität. Bis zu 10 Gäste können über den Chrome-Browser oder die iOS-App eingeladen und aufgenommen werden, was das Remote-Podcasting erleichtert.
Bearbeitung und Verbesserung: Separate Audio- und Videospuren für jeden Gast ermöglichen präzise Bearbeitung. Hintergrundgeräusche können mit einem Klick entfernt werden, was stundenlange Nachbearbeitung erspart. Lokale Aufnahmen bis zu 4K sorgen für Studioqualität, die sicher in der Cloud gespeichert wird.
Bildschirmfreigabe: Ideal für Videopodcasts, Webinare oder Tutorials, um den Inhalt ansprechender und interaktiver zu gestalten.
Die Realität: Grundlegende Aufnahmefunktionen funktionieren, aber die Audioqualität lässt zu wünschen übrig.
2. Audio Editor
Der Audio Editor von Podcastle ist ein einfach zu bedienendes, aber leistungsstarkes Tool zur Verbesserung von Audioinhalten.
Teilen/Schneiden: Audiofiles können präzise geteilt und geschnitten werden, was glatte Übergänge und professionelle Segmente gewährleistet.
Ein-/Ausblenden: Professionelle Ein- und Ausblendungen sorgen für einen polierten Klang.
Geschwindigkeitsanpassung und Trimmen: Die Geschwindigkeit von Audiodateien kann angepasst und die Dateien einfach getrimmt werden, um den gewünschten Fluss und die Länge zu erreichen.
Soundeffekte und Musik: Zugriff auf eine hochwertige, gebührenfreie Musikbibliothek zur Verbesserung der Klanglandschaft des Podcasts.
Aber: Der stark beworbene „Magic Dust“ AI Filter erweist sich als unbrauchbar. Er macht unsere Aufnahmen teilweise unbenutzbar, denn er verstärkt und verzerrt Nebengeräusche wie Atmen extrem und verschlechtert insgesamt die Audioqualität, statt sie zu verbessern!
3. Video Editor
Der Video Editor ist auf Einfachheit und Effizienz ausgelegt und ermöglicht die nahtlose Erstellung und Bearbeitung von Videoinhalten.
Aufnehmen und Bearbeiten in einem Studio: Direkt nach der Aufnahme kann im Browser bearbeitet werden, was Zeit und Mühe spart.
Markenpräsentation: Logos, benutzerdefinierte Hintergründe und Bauchbinden können hinzugefügt werden, um Videos zu personalisieren.
Sofortige Highlights: Highlights können während der Aufnahme markiert werden, um kurze Clips für soziale Medien mühelos zu erstellen.
4. Technische Probleme
Während meiner dreimonatigen Nutzung, habe ich insgesamt 8 Podcast-Folgen aufgenommen, geschnitten, bearbeitet und veröffentlicht, bzw. die Veröffentlichung geplant. Dabei ist es immer wieder zu sehr ärgerlichen Problemen gekommen, beispielsweise verschiebt die Export-Funktion Tracks willkürlich und so kommt es zu Timing-Probleme zwischen Editor und exportierter MP3 und sogar fehlerhaften Schnitte in veröffentlichten Episoden!
Das Tool soll eigentlich Zeit sparen – Wenn ich am Ende jede Folge nochmal komplett hören muss, um solche technischen Fehler zu entdecken, kostet mich das mehr Zeit, als es spart!
5. Podcast Hosting
Das Hosting deines Podcasts mit Podcastle ist einfach und effizient, aber nicht DSGVO-konform.
Veröffentlichung überall: Der Podcast kann mit einem einzigen Link auf den großen Plattformen wie Apple und Spotify veröffentlicht werden.
Integrierter Workflow: Erstellen, Bearbeiten und Veröffentlichen erfolgt auf einer Plattform, ohne dass Dateien zwischen verschiedenen Tools übertragen werden müssen.
Eigene Hosting-Seite: Die eigene Seite für die Show auf der Podcastle-Website erleichtert zwar das Teilen und Einbetten, liegt aber auf der Domain von podcastle.
6. Schlechter Kundenservice
Nach den ersten schlechten Erfahrungen mit dem Magic Dust Filter, habe ich mich an podcastle gewendet, doch ich musste mehr als zwei Wochen auf eine Antwort warten. Dabei ging der Support nicht adäquat auf meine Fehlermeldungen ein, ignorierte kritisches Feedback und bot keine Lösungen für die gemeldeten Probleme an.
Preise
Podcastle bietet verschiedene Preispläne an, die auf unterschiedliche Bedürfnisse zugeschnitten sind:
Die Preise erscheinen zunächst attraktiv, jedoch rechtfertigt die mangelhafte Qualität der Software nicht einmal den günstigsten bezahlten Tarif.
Fazit
Nach dreimonatiger Erfahrung mit Podcastle rate ich dringend von der Nutzung ab! Die Software verspricht viel, hält aber wenig. Die KI-Funktionen sind unausgereift, technische Probleme häufen sich, und der Support lässt zu wünschen übrig. Wer ernsthaft podcasten möchte, sollte sich nach verlässlicheren Alternativen umsehen.
Eine neue Forschungsarbeit des MIT hat kürzlich demonstriert, wie große Sprachmodelle durch eine besondere Trainingsmethode deutlich bessere Ergebnisse bei komplexen Denkaufgaben erzielen können. Die Methode nennt sich „Test-Time Training“ (TTT) und funktioniert ähnlich wie ein Mensch, der sich kurz vor einer Aufgabe nochmal intensiv mit ähnlichen Beispielen beschäftigt. Das Besondere dabei: Für jede neue Aufgabe wird ein spezieller „Adapter“ trainiert, der das Grundmodell temporär erweitert und optimiert.
Für viele KI-Enthusiasten dürfte die Verwendung von LoRA-Adaptern nicht ganz neu sein: Die Technik hat sich in der Bild-KI-Community bereits als leistungsfähige Methode etabliert, um bestehende Bildgenerierungsmodelle wie Stable Diffusion an spezifische Stile oder Personen anzupassen. Mit nur etwa 10 bis 15 Fotos einer Person lässt sich beispielsweise ein personalisierter LoRA-Adapter trainieren, der dann in der Lage ist, neue, künstliche Bilder dieser Person in verschiedensten Situationen und Stilen zu generieren. Der Adapter speichert dabei die charakteristischen Merkmale der Person, während das Grundmodell sein allgemeines „Verständnis“ von Menschen, Posen und Umgebungen beisteuert.
Was die MIT-Forscher nun zeigen, ist quasi eine Übertragung dieses Prinzips auf abstrakte Denk- und Mustererkennung: Statt visueller Merkmale einer Person lernt der Adapter hier die spezifischen Transformationsregeln einer Aufgabe. Diese Parallele macht deutlich, wie vielseitig einsetzbar das Konzept der adaptiven Feinabstimmung in verschiedenen Bereichen der KI ist.
Die Forscher testeten ihren Ansatz am „Abstraction and Reasoning Corpus“ (ARC), einer Sammlung besonders kniffliger visueller Rätsel. Bei diesen Aufgaben müssen aus wenigen Beispielen komplexe Muster erkannt und auf neue Situationen übertragen werden – eine Fähigkeit, die bisherigen KI-Systemen oft schwerfällt. Durch die Kombination von initialem Training, aufgabenspezifischen Lora-Adaptern und cleverer Erweiterung der Trainingsdaten durch geometrische Transformationen (wie Drehungen und Spiegelungen der Aufgaben) verbesserte sich die Genauigkeit insgesamt um das Sechsfache. Das verwendete 8-Milliarden-Parameter-Modell erreichte eine Genauigkeit von 53% und in Kombination mit programmatischen Ansätzen sogar 61,9% – vergleichbar mit durchschnittlicher menschlicher Leistung.
Was bedeutet das nun für die Praxis?
Die Methode zeigt enormes Potenzial für spezialisierte Anwendungen. In der wissenschaftlichen Forschung könnten komplexe Messdaten analysiert werden, in der medizinischen Diagnostik könnten seltene Krankheitsmuster erkannt werden, und in der industriellen Qualitätskontrolle könnten subtile Abweichungen aufgespürt werden. Die Stärke liegt besonders dort, wo nur wenige Beispiele verfügbar sind, aber sehr präzise Ergebnisse benötigt werden.
Allerdings gibt es auch deutliche praktische Einschränkungen: Die Methode benötigt erhebliche Rechenleistung – für 100 Aufgaben waren zwölf Stunden auf einer NVIDIA A100, einem Hochleistungs-GPU, nötig. Das macht sie ungeeignet für Echtzeit-Anwendungen. Für jeden Task muss ein eigener Adapter trainiert werden, was sowohl zeit- als auch ressourcenintensiv ist. Die Forscher verwendeten dabei zwar bereits eine relativ effiziente Technik (Low-Rank Adaptation) mit einem Rang von 128, insgesamt benötigt dies aber immer noch erhebliche Ressourcen.
Der Wert dieser Forschung liegt ganz klar in Anwendungen, wo Genauigkeit wichtiger ist als Geschwindigkeit.
Ein Beispiel: Bei der Analyse wissenschaftlicher Experimente könnte das System zunächst anhand weniger bekannter Beispiele lernen, welche spezifischen Muster relevant sind, und dann diese Erkenntnisse auf neue Daten übertragen – auch wenn dieser Prozess einige Stunden dauert. Das System ist dabei flexibler als fest trainierte Modelle, da es sich durch das Test-Time Training an neue Varianten einer Aufgabe anpassen kann.
Bemerkenswert ist auch, dass die Forscher zeigen konnten, dass rein neuronale Ansätze mit TTT ähnlich gut funktionieren können wie Systeme mit expliziten symbolischen Komponenten. Das widerspricht der häufigen Annahme, dass für abstraktes Denken unbedingt symbolische Verarbeitung zwingen nötig sei.
Die Arbeit zeigt damit einen wichtigen Trend in der KI-Entwicklung: die Möglichkeit, bestehende Modelle durch clevere Anpassungsmechanismen zu verbessern, statt immer größere Modelle zu entwickeln. Sie macht aber auch deutlich, dass der Einsatz solcher Technologien sorgfältig abgewogen werden muss – zwischen dem Gewinn an Genauigkeit und dem erheblichen Ressourcenaufwand.
Es war mir eine große Freude, zum zweiten Mal bei Rolf im OMR Education Podcast zu Gast zu sein. Nach unserem ersten Gespräch vor über einem Jahr, damals anlässlich meines ersten Buches, widmeten wir uns diesmal einem Thema, das die digitale Transformation fundamental prägt: Effektives Prompt Engineering.
Prompt Engineering ist weit mehr als nur eine Technik – es ist die zentrale Kompetenz, die darüber entscheidet, ob KI-Tools wie ChatGPT zu wertvollen Partnern oder zu schwerfälligen „Praktikanten“ werden. Als Online-Marketing-Veteran und KI-Experte hatte ich die Gelegenheit, tiefe Einblicke in die Kunst des Prompting zu geben.
Die wichtigsten Erkenntnisse aus dem Podcast:
Grundlagen des erfolgreichen Promptings
Was macht einen effektiven Prompt aus?
Warum ist präzise Kommunikation mit KI-Modellen entscheidend?
Wie formuliert man Anweisungen, die zu optimalen Ergebnissen führen?
Best Practices für maximale KI-Performance
Strukturierte Herangehensweise an Prompt-Entwicklung
Techniken zur Optimierung von KI-Outputs
Praktische Beispiele aus dem Marketing-Alltag
Domänen-Expertise als Schlüsselfaktor
Warum Sie nichts mit KI tun sollten, was Sie nicht auch ohne KI verstehen
Die Bedeutung von Fachkenntnissen beim Prompt Engineering
Wie Sie das Skilllevel verschiedener KI-Modelle richtig einschätzen
Grenzen und Chancen im Blick behalten
Realistische Einschätzung der KI-Möglichkeiten
Identifikation der optimalen Einsatzszenarien
Bewusstsein für ethische und praktische Limitationen
Ein besonders spannender Teil unseres Gesprächs widmete sich den neuesten Entwicklungen in der generativen KI. Wir diskutierten:
Autonome Agenten und ihre Einsatzmöglichkeiten
Das Potenzial von Multiagenten-Teams
„Head-of“-Modelle als zukünftige Strategie-Entwickler
Die Transformation von Marketing-Teams durch KI-Integration
Ein Highlight des Podcasts war Rolfs ehrliche Reflexion über seine eigenen Erfahrungen mit Prompt Engineering. Seine Erkenntnisse über die Herausforderungen überfüllter Prompts und die anschließende Verbesserung durch strukturierte Best Practices zeigen eindrucksvoll, wie wichtig methodisches Vorgehen beim Prompt Engineering ist.
Der richtige Umgang mit KI entwickelt sich zunehmend zur Schlüsselkompetenz in der digitalen Transformation, effektives Prompt Engineering ist eine der Grundlagen, die es hierfür braucht. Der Podcast bietet einen umfassenden Einblick in die Techniken und Strategien, die für eine erfolgreiche Zusammenarbeit mit KI-Tools unerlässlich sind.
Bonus: Best Practice Checkliste
Im Podcast stelle ich eine praktische Checkliste für erfolgreiches Prompt Engineering vor. Diese hilft Ihnen dabei:
Prompts strukturiert zu entwickeln
Häufige Fehler zu vermeiden
Die Qualität Ihrer KI-Outputs zu optimieren
Sie möchten mehr über Prompt Engineering lernen? Hören Sie sich die vollständige Episode an und lassen Sie sich von den praktischen Tipps und Erkenntnissen inspirieren.
Teil 1 meiner Serie über KI-Agenten und ihre Entwicklung
Die Entwicklung der Künstlichen Intelligenz hat in den letzten Jahren mit dem Aufkommen von großen Sprachmodellen einen bemerkenswerten Sprung gemacht. Besonders interessant ist derzeit die Entwicklung und Entstehung von KI-Agenten, die als (teil-)autonome Softwaresysteme zunehmend komplexe Aufgaben bewältigen können. Doch was verbirgt sich eigentlich hinter diesem Begriff und was können KI-Agenten eigentlich wirklich leisten?
Die digitale Transformation kennt keine Verschnaufpausen. Gerade erst haben wir uns an ChatGPT und seine erstaunlichen Fähigkeiten gewöhnt, da kündigt sich bereits die nächste Revolution an: Autonome KI-Agenten. Was zunächst nach Science-Fiction klingt, hat in der Softwareindustrie bereits konkrete Formen angenommen, und die großen Technologieunternehmen überbieten sich gegenseitig mit ambitionierten Ankündigungen. Salesforce plant nicht weniger als eine Milliarde KI-Agenten bis Ende 2025, während Microsoft stolz verkündet, dass bereits 60 Prozent der Fortune-500-Unternehmen ihren Copilot nutzen.
Die Vision ist verlockend: Eine virtuelle Belegschaft, die rund um die Uhr arbeitet, Routineaufgaben übernimmt und dabei kontinuierlich dazulernt. Die ersten Erfolgsmeldungen aus der Praxis klingen vielversprechend. Lumen Technologies rechnet mit jährlichen Einsparungen von 50 Millionen Dollar, während Honeywell von Produktivitätssteigerungen berichtet, die der Leistung von 187 Vollzeitmitarbeitern entsprechen. Bei Finastra ist die Produktionszeit für kreative Inhalte von sieben Monaten auf sieben Wochen geschrumpft. Besonders beeindruckend sind auch die Erfolge bei Pets at Home in Großbritannien, wo ein einzelner Agent jährliche Einsparungen in siebenstelliger Höhe ermöglicht, während McKinsey von 90% schnelleren Onboarding-Prozessen berichtet.
Das Timing dieser Entwicklung könnte kaum besser sein. In den kommenden Jahren werden Millionen von Baby-Boomern in den Ruhestand gehen. KI-Agenten versprechen hier nicht nur eine Lösung für den drohenden Fachkräftemangel, sondern auch die Möglichkeit, das wertvolle Wissen dieser Generation zu bewahren und weiterzugeben.
Doch fangen wir mal von vorne an…
Was sind KI-Agenten eigentlich?
Interessanterweise gibt es keine einheitliche Definition für KI-Agenten, was die Dynamik und Komplexität dieses Feldes widerspiegelt. Im Kern bezeichnet der Begriff autonome Softwaresysteme, die in ihrer Umgebung wahrnehmen, lernen, planen und handeln können, um vorgegebene Ziele zu erreichen. Diese Systeme kombinieren verschiedene KI-Technologien und können sowohl selbstständig als auch in Zusammenarbeit mit Menschen arbeiten.
Der aktuelle Stand der Technik ist dabei sowohl beeindruckend als auch ernüchternd. Streng genommen haben wir es heute noch nicht mit „echten“ KI-Agenten zu tun, da die aktuellen Systeme nicht im klassischen Sinne lernfähig sind. Sie können lediglich „In-Context Learning“ einsetzen, etwa durch RAG (Retrieval-Augmented Generation), bei dem sie wie eine Suchmaschine Informationen finden und auswerten oder Informationen aus ihrem eigenen Output wieder im Input verwenden.
Dennoch sind die Möglichkeiten von KI-Agenten auf Basis aktueller Technologien bereits beachtlich.
Kai Spriestersbach
Ein spannendes Beispiel für einen KI-Agenten ist Sakanas AI Scientist, der zeigt, was mit aktuellen Methoden bereits möglich ist. Dieses vollautomatisierte System zur wissenschaftlichen Entdeckung generiert eigenständig Forschungsideen, führt Experimente durch, analysiert Ergebnisse und verfasst wissenschaftliche Artikel. Der gesamte Forschungsprozess wird iterativ verfeinert, ähnlich wie in der menschlichen Wissenschaftsgemeinschaft.
In veröffentlichten Tests wurde das System für die Forschung im Bereich des maschinelles Lernens eingesetzt und entdeckte dabei neue Ansätze in Bereichen wie Diffusionsmodelle und Transformer. Trotz beeindruckender Fortschritte gibt es noch Herausforderungen bei der Genauigkeit und der Automatisierung visueller Aufgaben.
Die ersten KI-Agenten
Die ersten praktischen Implementierungen von KI-Agenten zeigten sich bereits 2023 in verschiedenen Ausprägungen: Vollständig autonome Agenten wie „AutoGPT“ nutzen Chain-of-Thought-Prompting, um komplexe Aufgaben in Teilschritte zu zerlegen und diese systematisch abzuarbeiten.
Dabei überprüfen sie ihre eigenen Ergebnisse durch Self-Validation und nehmen bei Bedarf Korrektungen vor. Eine spannende Entwicklung sind auch Multi-Agent-Systeme, bei denen verschiedene, jeweils auf bestimmte Aufgaben spezialisierte Agenten als Team zusammenarbeiten. Diese können entweder zentral gesteuert werden oder eigenständig entscheiden, welche anderen Agenten sie zur Problemlösung hinzuziehen.
Agenten auch in ChatGPT
Ein pragmatischer Ansatz ist auch mit ChatGPT möglich, bei dem der sicherere „Human-in-the-Loop“-Ansatz beibehalten wird, bei dem Menschen aktiv in den Prozess eingebunden bleiben.
In ChatGPT können beispielsweise Custom GPTs erstellt werden, die über APIs Zugriff auf verschiedene Tools erhalten. In einem System-Prompt werden dem GPT Anweisungen für seine Vorgehensweise gegeben, wodurch komplexe Aufgaben bewältigt werden können. Verschiedene spezialisierte GPTs können dann in einem zentralen Chat mittels Ansprache per @-Zeichen koordiniert und deren Ergebnisse kombiniert und weiterverarbeitet werden.
Wie sieht die Architektur eines KI-Agenten aus?
Die Architektur moderner KI-Agenten ist dabei hochkomplex. Im Zentrum steht eine Kernarchitektur, die als zentrale Verarbeitungseinheit fungiert und alle Teilsysteme koordiniert. Wahrnehmungsmodule verarbeiten verschiedene Arten von Eingabedaten, sei es Text, Bild, Audio oder Video, und ermöglichen so ein umfassendes Kontextverständnis.
Ein ausgeklügeltes Planungsmodul analysiert Probleme strategisch und entwickelt Handlungspläne, wobei häufig „Chain-of-Thought“ oder Tree-of-Thought Prompting zum Einsatz kommt. Eine spannende Neuentwicklung ist hier OpenAIs o1 a.k.a. Strawberry das eine Art „Silent Tree-of-Thought“ mit interner Bewertung der Planungen/Gedanken als Optimierungsziel verwendet.
Eine besondere Herausforderung derzeit ist das Gedächtnissystem der Agenten. Sie verfügen quasi über ein Kurzzeit- und ein simuliertes Langzeitgedächtnis, wobei letzteres meist nur innerhalb des Context Windows funktioniert. Ein echtes erfahrungsbasiertes Lernen ist in der Regel nicht implementiert.
Bei ChatGPT beispielsweise funktioniert die Erinnerungsfunktion über einen cleveren Prompt-Mechanismus: Der Agent fragt sich selbst, welche Informationen aus der Konversation wichtig genug sein könnten, um sie sich dauerhaft für diesen Benutzer zu merken. Diese werden dann in eine Liste von „Erinnerungen“ aufgenommen und beim nächsten Prompt automatisch eingefügt.
Stärken von KI-Agenten
Die Stärken aktueller KI-Agenten liegen vor allem in der systematischen Analyse von Problemen, der Entwicklung strukturierter Lösungsansätze und der parallelen Bearbeitung mehrerer Aufgaben. Durch die Integration verschiedener Tools und die Automatisierung von Prozessen können sie Ressourcen effizient nutzen.
Allerdings gibt es auch deutliche Einschränkungen: Die Systeme können sich nur begrenzt an neue Situationen anpassen, verfügen über keine echte Lernfähigkeit und ihre kontinuierliche Verbesserung erfordert erheblichen Aufwand.
Auch ethische Grenzen sind zu beachten! Die moralische Urteilsfähigkeit der Agenten ist begrenzt, sie sind von programmierten Werten abhängig und können potenzielle Voreingenommenheiten aufweisen.
Technische Limitationen zeigen sich in der Abhängigkeit von der Datenqualität, einer begrenzten Transferfähigkeit und Schwierigkeiten bei unstrukturierten Problemen. Wirklich zuverlässige Ergebnisse liefern die Systeme nur in ihrem jeweiligen, eng begrenzten Aufgabenfeld.
Der aktuelle Stand in Sachen AI-Agents
In einem Interview der MIT Technology Review gewährten OpenAIs Produktchef Olivier Godement und der Leiter der Entwicklererfahrung Romain Huet tiefe Einblicke in ihre Vision. „In ein paar Jahren wird jeder Mensch auf der Erde, jedes Unternehmen einen Agenten haben“, prognostiziert Godement. Er beschreibt einen digitalen Assistenten, der nicht nur Zugriff auf unsere E-Mails, Apps und Kalender hat, sondern diese auch wirklich versteht und wie ein persönlicher Stabschef agiert.
Doch bevor diese Vision Realität werden kann, müssen zwei zentrale Herausforderungen gemeistert werden:
Zum einen das „Reasoning“ – also die Fähigkeit der KI, wirklich logisch zu denken und komplexe Aufgaben zuverlässig zu lösen.
Zum anderen die nahtlose Integration verschiedener Tools und Datenquellen. Die KI muss nicht nur im Internet surfen können, sondern auch aktiv mit der realen Welt interagieren.
Und ja, natürlich arbeitet OpenAI bereits intensiv an beiden Fronten:
Mit dem neuen o1-Modell wurde eine erweiterte „Chain-of-Thought“-Technik eingeführt, die dem System mehr Zeit zum „Nachdenken“ gibt. Dies ermöglicht es der KI, Fehler zu erkennen, Probleme in kleinere Einheiten aufzuteilen und verschiedene Lösungsansätze auszuprobieren.
Parallel dazu wurde ChatGPT mit Suchfunktionen ausgestattet, während die neue Realtime API Entwicklern ermöglicht, fortschrittliche Sprachfunktionen in ihre Anwendungen zu integrieren.
Vorsicht: Es ist nicht alles Gold was glänzt
Doch eine aktuelle Studie aus dem Hause Apple mahnt zur Vorsicht – und das aus gutem Grund. Die Forscher:innen haben sich die viel beworbenen Reasoning-Fähigkeiten genauer angeschaut und dabei ernüchternde Erkenntnisse gewonnen: Was auf den ersten Blick wie echtes logisches Denken erscheint, entpuppt sich bei näherer Betrachtung als hochentwickeltes Musterabgleichen.
Ein simples Beispiel macht das deutlich: Wenn man in einer Textaufgabe über das Sammeln von Früchten plötzlich irrelevante Details über deren Größe einstreut, weicht das Ergebnis um bis zu 10 Prozent ab. In manchen Fällen wurden sogar Abweichungen von 65 Prozent beobachtet!
Dies zeigt sich besonders deutlich am Beispiel eines klassischen Logikrätsels wie der Flussüberquerung. Das Original-Rätsel ist mittlerweile so bekannt, dass es vermutlich in unzähligen Varianten in den Trainingsdaten steckt. Kein Wunder also, dass moderne KI-Systeme hier brillieren.
Ein Mann will mit einem Wolf, einer Ziege und einem Kohlkopf über einen Fluss.
Das Problem: Das Boot ist klein und kann neben dem Mann nur eine weitere Sache transportieren.
Dabei muss der Mann aufpassen:
1. Der Wolf darf nicht alleine mit der Ziege bleiben, sonst frisst er sie.
2. Die Ziege darf nicht alleine mit dem Kohl bleiben, sonst frisst sie ihn.
Deine Aufgabe ist es, einen Plan zu finden, wie der Mann alle sicher über den Fluss bringt
– mit so wenigen Fahrten wie möglich.
Doch fügt man nur eine kleine Variable hinzu – in diesem Fall einen Strick zum Festbinden – gerät das System ins Schleudern.
Er hat einen Strick dabei und könnte damit ein Tier festbinden oder ihm das Maul zubinden.
Statt die simple Originallösung beizubehalten, verstrickt sich die KI in teils aberwitzige Konstruktionen mit gefesselten Tieren, ohne zu erkennen, dass der Strick die grundlegende Problemstellung gar nicht verändert.
Screenshot
Das Problem der Halluzinationen besteht nach wie vor
Noch bedenklicher im Hinblick auf autonome Agenten sind die sogenannten „KI-Halluzinationen“. In amerikanischen Krankenhäusern wird beispielsweise bereits eine KI-Software eingesetzt, die auf OpenAI Whisper-Modell basiert, und mit deren Hilfe Arzt-Patienten-Gespräche automatisch in Text umgewandelt werden. Eine neue Studie mit über 13.000 Audio-Transkriptionen offenbart dabei ein erschreckendes Problem: In etwa einem Prozent der Fälle „halluziniert“ die KI und erfindet Inhalte, die nie gesagt wurden. Aus einer harmlosen Aussage wie „jemand musste die Feuerwehr rufen, um den Vater und die Katze zu retten“ macht das System plötzlich eine dramatische Szene mit einem „blutgetränkten Kinderwagen“.
Die Reaktionen der Branche auf solche Vorfälle folgen einem bekannten Muster: Software-Anbieter wie das Unternehmen Nabla, das Whisper in Krankenhäusern einsetzt, versprechen schnelle technische Lösungen – etwa durch spezialisiertes Training oder die Verknüpfung mit Faktendatenbanken zur Gegenkontrolle.
Doch wie wenig verlässlich solche Sicherheitssysteme sind, zeigt eine aktuelle Studie von Meta: Selbst KI-Systeme mit Datenbankanbindung produzieren in einem Drittel der Fälle noch frei erfundene Inhalte.
Besonders aufschlussreich ist die Reaktion von OpenAI selbst: Das Unternehmen verweist darauf, dass Whisper laut „Beipackzettel“ gar nicht für kritische Anwendungen wie im Gesundheitswesen gedacht sei – eine erstaunliche Position für ein Unternehmen, dessen CEO Sam Altman regelmäßig verkündet, KI werde alle Lebensbereiche revolutionieren. Aber so kann sich das angeblich so offene KI-Unternehmen – zumindest vorerst – aus der Verantwortung stehlen.
Wie sieht es bei der Konkurrenz aus?
Während OpenAI seinen ambitionierten AGI-Fahrplan präsentiert, führt der Konkurrent Anthropic mit der „Computer Use“-Funktion eine Technologie ein, die KI-Systeme viel stärker in Richtung Agenten bringt: Anthropics Flaggschiff-Modell Claude 3.5 Sonnet wurde im neuesten Update beigebracht, Computer wie Menschen zu bedienen – mit Mausklicks, Tastatureingaben und Bildschirmnavigation. Eine bemerkenswerte Entwicklung, die allerdings auch ihre Tücken hat, wie sich bei einer Vorführung zeigte: Statt den vorgesehenen Code zu schreiben, „entschied“ sich das System plötzlich, Fotos des Yellowstone Nationalparks zu durchstöbern.
Zur Info: Das Modell wurde bei diesem Release grundlegend überarbeitet und zeigt vor allem im Bereich Software-Engineering deutliche Fortschritte. Bei SWE-bench Verified, einem wichtigen Benchmark für Programmieraufgaben, verbesserte sich die Erfolgsquote von 33,4% auf 49,0% – damit übertrifft Sonnet sogar spezialisierte Coding-Systeme und OpenAIs o1. GitLab bestätigt diese Verbesserung und berichtet von bis zu 10% besseren Ergebnissen bei DevSecOps-Aufgaben.
Auch Google arbeitet an Agenten
Google verfolgt unter dem Codenamen „Project Jarvis“ einen fokussierteren Ansatz: Der Konzern entwickelt einen KI-Agenten, der sich auf die Kontrolle des Chrome-Browsers spezialisiert. Die Technologie soll alltägliche Online-Aufgaben wie Produktrecherchen, Einkäufe oder Reisebuchungen selbstständig ausführen können.
Der technische Ansatz ist dabei bemerkenswert pragmatisch: Jarvis erstellt kontinuierlich Screenshots des Browsers, analysiert diese in Echtzeit und leitet daraus die nächsten Aktionen ab.
Apple und Microsoft natürlich ebenso
Microsoft mit OmniParser ein Open-Source-Tool veröffentlicht, das Bildschirminhalte in strukturierte Daten umwandeln kann. Apple wiederum arbeitet mit CAMPHOR sowohl an einem Framework für kollaborative Agenten, das verschiedene Spezialisten unter der Führung eines übergeordneten „Reasoning-Agenten“ koordiniert, als auch an einem System zur KI-gesteuerten Bedienung von Benutzeroberflächen mit Namen Ferret-UI 2.
Die Besonderheit: Anders als die Konkurrenz zielt Apple auf eine plattformübergreifende Lösung, die sowohl auf iPhones, iPads, Android-Geräten als auch im Web und auf Apple TV funktionieren soll.
Die Leistungsdaten sind dabei durchaus bemerkenswert: Bei der Erkennung und Interpretation von UI-Elementen erreicht Ferret-UI 2 einen Score von bis zu 89,73 – deutlich mehr als GPT-4o mit 77,73.
Stellt man sich allerdings einen autonomen KI-Agenten vor, der bei jedem 10. Schritt am Computer einen Fehler macht, relativiert sich das Ganze jedoch schnell.
Fazit und Ausblick
Die Integration von KI-Agenten in bestehende Systeme mag für spezifische, klar definierte Aufgaben durchaus sinnvoll sein. Aber der Weg zur wahren AGI ist noch sehr weit – und vielleicht sollten wir uns mehr darauf konzentrieren, die aktuellen Systeme zuverlässiger und sicherer zu machen, statt von Science-Fiction-Szenarien zu träumen.
Die unterschiedlichen Ansätze der Tech-Giganten zeigen: Der Weg zu wahrhaft autonomen KI-Assistenten ist noch nicht festgelegt. Was sich jedoch abzeichnet: Die Systeme werden immer besser darin, unsere Intentionen zu verstehen und entsprechend zu handeln – auch wenn der Weg zur fehlerfreien Ausführung noch weit ist.
Trotz dieser Einschränkungen sind die Zukunftsperspektiven vielversprechend. Die Integration von KI-Agenten in bestehende Systeme wird weiter zunehmen, wobei der Fokus auf einer verantwortungsvollen Entwicklung liegen muss. Kontrolle und Transparenz werden dabei eine zentrale Rolle spielen.
Die große Herausforderung wird sein, die richtige Balance zwischen Automatisierung und menschlicher Kontrolle zu finden.
Dabei gilt es, sowohl die Chancen als auch die Risiken im Blick zu behalten. Die Effizienzsteigerung in komplexen Prozessen und die Unterstützung menschlicher Entscheidungsfindung bieten enormes Potenzial. Gleichzeitig müssen wir uns der möglichen Schäden durch Fehler, rechtlicher Herausforderungen wie Haftungsfragen und Datenschutzbedenken bewusst sein. Auch die zunehmende Abhängigkeit von KI-Systemen und deren Auswirkungen auf den Arbeitsmarkt werden uns als Gesellschaft beschäftigen.
Für Unternehmen stellt sich bereits heute die Frage, ob sie KI-Agenten-Systeme in ihre Geschäftsprozesse implementieren sollten, oder besser nicht…
Kai Spriestersbach
Autonome KI-Agenten haben das Potenzial, zahlreiche Arbeitsbereiche zu transformieren, indem sie repetitive Aufgaben übernehmen und datengetriebene Prozesse beschleunigen. Doch ihr Einsatz ist stark von der Anwendungsumgebung und den möglichen Konsequenzen von Fehlern abhängig. Eine fundierte Analyse der Einsatzfelder hilft dabei, KI-Agenten mit Bedacht und an den richtigen Stellen zu integrieren – heute und in Zukunft.
Wo und wann autonome KI-Agenten sinnvoll sind
Autonome KI-Agenten sind eine faszinierende Technologie, die zahlreiche Bereiche transformieren kann. Doch ihr Einsatz ist nicht überall sinnvoll. Eine Analyse anhand der Dimensionen Risiko und Vorhersehbarkeit der Inputs hilft dabei, zu erkennen, wo KI-Agenten heute bereits zuverlässig arbeiten können und wo ihr Einsatz Risiken birgt.
Eine Einteilung in vier Kategorien zeigt, in welchen Bereichen autonome KI-Agenten bereits effizient eingesetzt werden und wo Vorsicht geboten ist:
Gut geeignet: Niedriges Risiko & Hohe Standardisierung Hier können KI-Agenten einfach implementiert werden, da die Aufgaben klar definiert und das Risiko bei Fehlern gering ist. Typische Einsatzbereiche umfassen Lagerautomatisierung, Rechnungsverarbeitung, und Datenmanagement, wo repetitive, strukturierte Aufgaben dominieren.
Experimentell geeignet: Niedriges Risiko & Niedrige Standardisierung In Bereichen mit weniger vorhersehbaren Inputs, jedoch überschaubarem Risiko, haben KI-Agenten Raum für Innovation und Experimente. Sie werden z. B. im Marketing zur Mustererkennung oder in der Unterhaltung eingesetzt, etwa in Form interaktiver Chatbots in Spielen.
Möglich mit Vorsicht: Hohes Risiko & Hohe Standardisierung Hier bietet sich der Einsatz an, wenn KI-Agenten in eng definierten Rahmenbedingungen arbeiten und Fehler mit angemessenen Sicherheitsvorkehrungen minimiert werden können. Typische Einsatzgebiete sind Medizinische Bildanalyse und Finanztransaktionen, bei denen KI-Agenten bereits wertvolle Unterstützung leisten können.
Nicht geeignet: Hohes Risiko & Niedrige Standardisierung In dynamischen, schwer vorhersehbaren Szenarien, wo Fehler gravierende Folgen haben könnten, sind autonome KI-Agenten derzeit ungeeignet. Das betrifft beispielsweise Notfallmedizin oder militärische Entscheidungsfindung, wo die Reaktionsfähigkeit und die ethische Verantwortung von Menschen entscheidend sind.
Fest steht jedoch: Die Entwicklung von KI-Agenten steht noch am Anfang, aber sie wird unsere Art zu arbeiten und zu leben nachhaltig verändern. Der Schlüssel zum Erfolg wird sein, diese mächtige Technologie verantwortungsvoll und zum Nutzen aller einzusetzen. Dabei wird es entscheidend sein, die richtige Balance zwischen technologischem Fortschritt und menschlicher Kontrolle zu finden.
Die VG WORT hat kürzlich wichtige Änderungen am Wahrnehmungsvertrag beschlossen, die vor allem im Zusammenhang mit der Nutzung von urheberrechtlich geschützten Werken in Künstlicher Intelligenz (KI) stehen.
Als Autor:innen haben wir bis zum 29. November 2024 die Möglichkeit, diesen Änderungen zu widersprechen. Doch was bedeuten diese Anpassungen konkret für uns und welche Chancen oder Risiken bringen sie mit sich?
Die Neuerungen im Überblick
Eine der zentralen Änderungen betrifft die Erweiterung des Wahrnehmungsvertrags um die Nutzung unserer Werke für KI-Anwendungen in Unternehmen und Behörden. Genauer gesagt, erlaubt die neue Regelung, dass Werke im internen Gebrauch für KI-Systeme verwendet werden können – sei es, um Inhalte zu speichern, zu indexieren oder sogar als Trainingsdaten für KI-Modelle zu dienen. Dies umfasst generative KI-Anwendungen, bei denen Inhalte weiterverarbeitet und Outputs auf Grundlage unserer Werke erzeugt werden.
Wichtig: Diese Nutzung ist ausschließlich auf interne Zwecke beschränkt!
Es gibt keine Erlaubnis, die erzeugten Outputs kommerziell oder gegenüber Kunden zu verwenden!
Die Rechteinhaber:innen – also die Autor:innen – behalten zudem das Recht, weiterhin eigene Lizenzen für unsere Werke zu vergeben.
Gerne! Hier sind einige konkrete Beispiele, was mit den Daten und dem Output eines KI-Modells im Rahmen des VG WORT-Vertrags erlaubt ist und was nicht:
Was ist erlaubt?
Interne Nutzung des KI-Modells: Dieses Modell darf nur intern innerhalb deines Unternehmens oder deiner Behörde verwendet werden. Zum Beispiel könntest du das Modell nutzen, um Dokumente oder Texte für interne Berichte automatisch zu analysieren oder zusammenzufassen. Du darfst damit ein KI-Modell trainieren, das auf urheberrechtlich geschützten Werken basiert, die durch die VG WORT lizenziert wurden.
Speichern und Indexieren von Inhalten: Die Werke, die du zum Trainieren des KI-Modells verwendest, dürfen in einem gesicherten elektronischen Netzwerk gespeichert und einem abgegrenzten Personenkreis (z.B. Mitarbeitende) zugänglich gemacht werden. Du darfst also die Werke und Metadaten indexieren und in andere maschinenlesbare Formate umwandeln, um sie für das KI-Training besser nutzbar zu machen.
Output des KI-Modells intern verwenden Die durch das KI-Modell generierten Ergebnisse (Output) dürfen ebenfalls in deinem Unternehmen oder deiner Behörde verwendet werden. Zum Beispiel könntest du Berichte, Analysen oder automatisierte Zusammenfassungen erstellen und im internen Netzwerk speichern oder mit den Mitarbeitenden teilen.
Fortführung nach Vertragsende: Wenn der Lizenzvertrag endet, darfst du das KI-System weiterhin intern nutzen, solange es bereits während der Vertragslaufzeit trainiert wurde. Auch die Outputs, die bereits generiert wurden, dürfen weiter genutzt werden.
Was ist nicht erlaubt?
Externe kommerzielle Nutzung des Outputs: Du darfst den Output des KI-Modells nicht kommerziell verwerten oder externen Kunden zur Verfügung stellen. Zum Beispiel wäre es nicht erlaubt, die durch das Modell erzeugten Texte, Zusammenfassungen oder Analysen an Dritte zu verkaufen oder für externe Dienstleistungen zu nutzen.
Verkauf oder Lizenzierung des KI-Modells: Du darfst das KI-Modell, das mit den lizenzierten Daten trainiert wurde, nicht an andere Unternehmen verkaufen oder lizenzieren. Die Nutzung ist streng auf den internen Gebrauch beschränkt.
Nutzung des Outputs für externe Projekte: Der Output des KI-Modells darf nicht für Projekte oder Dienstleistungen verwendet werden, die außerhalb deines Unternehmens oder deiner Behörde angeboten werden. Zum Beispiel könntest du keine mit der KI erstellten Inhalte in einem öffentlichen Blog veröffentlichen oder an Kunden liefern.
Verwendung durch Drittanbieter-KI-Systeme: Es ist nicht erlaubt, das Modell oder die Daten in KI-Dienstleistungen zu integrieren, die für externe Dritte wie andere Unternehmen oder Verbraucher bereitgestellt werden. Solche Anwendungen wären von der Lizenz ausgenommen und müssten direkt vom Rechteinhaber genehmigt werden.
Zusammenfassung
Erlaubt
Nicht erlaubt
Internes Training von KI-Modellen
Kommerzielle Nutzung des Outputs
Interne Speicherung und Verbreitung der Outputs
Verkauf oder Lizenzierung des KI-Modells
Fortführung der Nutzung nach Vertragsende
Veröffentlichung der KI-generierten Inhalte
Indexieren und Konvertieren von Daten
Nutzung durch Drittanbieter für externe Dienste
Potenzielle Auswirkungen auf Lizenzeinnahmen
Eine naheliegende Frage ist: Führt diese Änderung zu zusätzlichen Lizenzeinnahmen?
Die Antwort lautet: potenziell ja. Da Unternehmen und Behörden zukünftig für die interne Nutzung von urheberrechtlich geschützten Inhalten im Rahmen ihrer KI-Anwendungen Lizenzen benötigen, eröffnet sich für uns eine neue Einnahmequelle. Die VG WORT könnte uns Tantiemen aus diesen neuen Lizenzen auszahlen, ähnlich wie bei bisherigen Lizenzierungsmodellen für digitale Vervielfältigungen.
Allerdings sind diese Einnahmen wahrscheinlich begrenzter als bei kommerziellen Lizenzen, da die Nutzung nur für interne Zwecke erlaubt ist. Es bleibt abzuwarten, wie stark die Nachfrage nach solchen Lizenzen tatsächlich sein wird. Besonders spannend ist hierbei, dass wir trotz der Rechteübertragung an die VG WORT weiterhin die Möglichkeit haben, eigenständig Lizenzen zu vergeben. Dies bietet uns die Flexibilität, zusätzliche Einnahmen zu erzielen, wenn wir unsere Werke für externe Anwendungen lizenzieren wollen.
Haftungsverzicht bei unerlaubter KI-Nutzung
Ein weiterer Punkt, der bedacht werden sollte, ist der Haftungsverzicht. Falls du der Änderung zustimmst, verzichtest du auf mögliche urheberrechtliche Ansprüche gegenüber Unternehmen, die KI-Systeme von Drittanbietern nutzen, die ohne deine Zustimmung mit deinen Werken trainiert wurden. Dies könnte potenziell ein Risiko darstellen, insbesondere in Fällen, in denen deine Werke unerlaubt verwendet wurden.
Handlungsoptionen: Zustimmung oder Widerspruch?
Die VG WORT verlangt keine explizite Zustimmung zu den neuen Vertragsbedingungen – Schweigen wird als Zustimmung gewertet. Wenn du nicht bis zum 29. November 2024 widersprichst, werden die Änderungen automatisch Bestandteil deines Wahrnehmungsvertrags. Es ist also wichtig, dir die neuen Regelungen genau anzusehen und abzuwägen, ob du von den neuen Lizenzierungsmöglichkeiten profitieren möchtest oder nicht.
Falls du die Kontrolle über die Nutzung deiner Werke im KI-Kontext behalten möchtest oder Bedenken bezüglich des Haftungsverzichts hast, könnte ein Widerspruch sinnvoll sein. Umgekehrt könnte eine Zustimmung interessante neue Einnahmequellen eröffnen.
Fazit: Chancen und Risiken abwägen
Die Änderungen des Wahrnehmungsvertrags der VG WORT eröffnen uns als Autor:innen die Möglichkeit, unsere Werke für interne KI-Anwendungen lizenzieren zu lassen, was neue Einnahmequellen erschließen könnte. Gleichzeitig sind diese Nutzungen stark eingeschränkt, und der Verzicht auf Haftungsansprüche gegenüber unbefugten KI-Nutzungen sollte nicht unbeachtet bleiben. Letztlich hängt die Entscheidung, ob du widersprichst oder zustimmst, von deinen individuellen Prioritäten und deinem Interesse an diesen neuen Nutzungsmöglichkeiten ab.
Die vollständige Fassung des neuen Wahrnehmungsvertrags findest Du hier.
Nutze die Gelegenheit, dich bis zum 29. November 2024 zu informieren und eine fundierte Entscheidung zu treffen!
Während sich unzählige KI-Expert:innen und Autor:innen darauf gestürzt haben, OpenAIs neuestes Modell zu verstehen und zu erklären, habe ich den freien Kopf im Urlaub dafür genutzt, die darin verwendeten Ideen und Konzepte einen Schritt weiter zu denken und bin dabei auf einen spannenden Ansatz für bessere Modellbildung in LLMs gestoßen.Wenn über die Entwicklung von Large Language Models (LLMs) und ihren potenziellen Weg zu einer allgemeinen künstlichen Intelligenz (AGI) diskutiert wird, kommt häufig das Argument auf, dass diese Modelle keine echten Weltmodelle besitzen.
Wieso uns LLMs womöglich nicht zu allgemeiner künstlicher Intelligenz führen?
Es gibt Diskussionen darüber, ob LLMs nur durch das Training mit großen Mengen an Text (also unstrukturierte Daten) in der Lage sind, ein tiefes Verständnis der Welt zu entwickeln. Viele Forscher:innen zweifeln daran, dass dies ohne eine „Verankerung“ in der realen Welt möglich ist.
Der KI-Forscher Yann LeCun argumentiert, dass „World Models“ mehrere Ebenen der Abstraktion und Zeit umfassen sollten. Das bedeutet, dass diese Modelle nicht nur in der Lage sein sollten, aktuelle Situationen zu verstehen, sondern auch langfristig planen, zukünftige Ereignisse vorhersagen und auf Basis dieser Informationen logische Schlüsse ziehen.
Forscher:innen wie Liu et al. (2022) schlagen vor, LLMs in die physische Welt einzubetten, indem sie das Modell über Ergebnisse von Simulationen in der realen Welt nachdenken lassen. Das bedeutet, dass das Modell durch Simulationen lernt, wie die Welt funktioniert, um so sein internes Modell zu verbessern.
Kritiker bemängeln, dass LLMs lediglich Wahrscheinlichkeiten für Textvorhersagen berechnen und dadurch keine tiefere „Verständnisstruktur“ entwickeln können. Doch wie aktuelle Forschung und Experimente zeigen, ist diese Sichtweise zu eindimensional.
Doch Studien wie die von Hao et al. (2023) nutzen LLMs als „World Models“, indem sie das Modell dazu bringen, künftige Zustände vorherzusagen, basierend auf vordefinierten Handlungen und Aufgaben. Das Modell kann dann durch Simulationen erlernen, wie die Welt sich aufgrund von Aktionen verändert.
Mehrere Forschungen untersuchen, wie LLMs interne Repräsentationen der Welt bilden. Zum Beispiel zeigen Studien, dass LLMs durch „In-Context-Learning“ (wo sie aus dem Kontext eines gegebenen Problems lernen) Farb- und Raumstrukturen lernen können. Das bedeutet, dass sie in der Lage sind, abstrakte Informationen aus der realen Welt zu verstehen und zu nutzen.
Neuere Studien haben entdeckt, dass speziell trainierte LLMs „lineare Repräsentationen“ von Raum, Zeit und Spielzuständen entwickeln. Das ist besonders wichtig, weil diese Strukturen helfen, dynamische und kausale Zusammenhänge in der realen Welt zu verstehen – was eine Grundlage für fortgeschrittene Weltmodelle sein könnte.
Ein faszinierendes Beispiel aus dem Paper Sparks of Artificial General Intelligence zeigt, dass LLMs sehr wohl in der Lage sind, implizite Modelle aus ihren Trainingsdaten zu erstellen. So hat eine frühe Version von GPT-4 auf die Anfrage, ein Einhorn in der Vektorgrafik-Sprache TikZ zu zeichnen, überraschend präzise Ergebnisse geliefert – obwohl das Modell nie ein Bild eines Einhorns „gesehen“ hat. Es hat quasi selbst die Modalitäten überbrückt.
Im Paper sind drei anschauliche Beispiele hierfür enthalten:
Screenshot
Diese Fähigkeit zur impliziten Modellbildung legt aus meiner Sicht nahe, dass LLMs potenziell weit mehr leisten können, als nur Textbausteine zu generieren.
OpenAIs Strawberry-Modell: Ein Weg in die Zukunft?
Bisher konzentrierte sich der Fortschritt bei Large Language Models (LLMs) hauptsächlich auf sprachbasierte Aufgaben wie Textgenerierung und -bearbeitung. Doch mit dem neuen „o1“-Modell betritt OpenAI Neuland: Es ist speziell für mehrstufige Reasoning-Aufgaben ausgelegt und zeigt beeindruckende Fortschritte in Bereichen wie Mathematik, Codierung und Wissenschaft. Im Gegensatz zu früheren Modellen nutzt o1 eine Art Chain-of-Thought-Technik, die es dem Modell ermöglicht, Fehler zu erkennen und alternative Lösungswege auszuprobieren.
In Tests erzielte o1 herausragende Ergebnisse: Es gehört zu den besten 500 Teilnehmern der USA Math Olympiad und übertrifft in PhD-Fragen sogar menschliche Experten. Dies ist ein wichtiger Schritt, da LLMs bisher häufig an komplexen, logischen Fragestellungen scheiterten. Auch wenn das Modell kostenintensiv ist und nicht für alle Aufgaben geeignet, markiert es den Beginn einer Ära, in der LLMs echten Mehrwert für anspruchsvolle wissenschaftliche und technische Aufgaben liefern können.
Nach allem, was derzeit bekannt ist, verfügt das Modell offenbar über einen internen, impliziten Tree-of-Thought-Mechanismus, der es ermöglicht, vor der Antwortverarbeitung verschiedene mögliche Gedankengänge durchzuspielen. Ähnlich wie beim menschlichen Denken werden dabei potenzielle Lösungswege verzweigt und in einem Baum strukturiert. Diese Fähigkeit wird über ein eigenes Reward-Modell optimiert, das die „Gedankengänge“ in Bezug auf ihre Relevanz und Korrektheit bewertet und verstärkt.
Dieser Ansatz, der auf den bereits existierenden Chain-of-Thought- und Tree-Of-Thought-Prompts basiert, zeigt eindrucksvoll, wie LLMs über die bloße Textvorhersage hinauswachsen können: Sie „denken“ nun vor einer Antwort über das Problem nach, indem sie alternative Lösungswege simulieren und dann die beste Option wählen. Damit sind sie deutlich näher an einer Form von bewusster Problemlösung, als es zuvor der Fall war.
Forced-Model: Ein realistischer Ansatz?
Genau diese Idee des Tree-of-Thought-Mechanismus könnte der Schlüssel sein, um das Problem fehlender expliziter Weltmodelle bei LLMs zu lösen. Was wäre, wenn wir diesen Mechanismus nutzen, um LLMs zu „zwingen“, vor der Lösung komplexer Aufgaben zunächst ein Modell der Situation, also eine Art „Forced-Model“ zu erstellen?
Ich stelle mir das ähnlich wie beim Tree-of-Thought vor, nur dass das Modell hier zunächst eine serialisierte Repäsentation erstellt, die als eine Art mentales Model genutzt wird, um dieses Schritt für Schritt zu einer universalen Repräsentation der gegebenen Umgebung oder Aufgabe vervollständigt, die es dann zur Lösung nutzt.
Ein Beispiel:
Derzeitige LLMs scheitern beispielsweise an üblichen Intelligenztest, bei dem das Modell zunächst eine Reihe von Beschreibungen zu einem Gebäude erhält und anschließend Fragen dazu beantworten soll.
Zwar sind sie in der Lage, einen potentiellen Dieb dabei in den falschen Raum zu schicken, damit dieser den Tresor nicht findet, schaffen es aber nicht, die beschriebenen Räume so zu organisieren, dass es den kürzesten Weg von Raum X nach Raum Y finden kann.
Was wenn wir es, analog zum Tree-Of-Thought, zunächst dazu zwingen, ein Modell des Gebäudes zu erstellen?
Wenn das LLM mit einer detaillierten Raumbeschreibung konfrontiert wird, könnte es angewiesen werden, zunächst eine interne Struktur (zum Beispiel in Form eines JSON-Objekts oder eines Graphen) zu erstellen, in der die Räume und ihre Verbindungen erfasst werden.
Dieses Modell könnte dann verwendet werden, um Fragen zu beantworten, wie etwa den kürzesten Weg von Raum A nach Raum B zu finden. Analog zum Tree-of-Thought in OpenAIs Strawberry könnte auch dieser Modellbildungsansatz über ein Reward-Modell optimiert werden, um genauere und effizientere Modellstrukturen zu fördern.
Mögliche Implementierungen
Natürlich stehen wir dabei vor der Frage, welche Art von Repräsentation sich für solch ein internes Modell am besten eignet. Für räumliche Strukturen könnten Graphen gut geeignet sein, während für andere Aufgaben, wie logische Schlussfolgerungen oder Entscheidungsbäume, JSON oder XML als flexible und universelle Datenformate in Frage kommen.
Die Herausforderung besteht darin, eine universelle Repräsentation zu finden, die auf eine Vielzahl von Aufgaben angewendet werden kann.
Verknüpfung symbolischer KI mit Sprachmodellen?
Die Lösung könnte in der Kombination von neuronalen Netzen und Techniken der symbolischen Künstlichen Intelligenz liegen. Durch diese Integration können wir beide Welten vereinen: die Flexibilität und Mustererkennung der neuronalen Modelle und das präzise, regelbasierte Denken der symbolischen KI.
Wissensgraphen und Ontologien: Strukturierte Repräsentation
Wissensgraphen und Ontologien sind leistungsstarke Werkzeuge, um Entitäten und deren Beziehungen zueinander zu organisieren. Die Idee ist simpel: Das Sprachmodell extrahiert aus einem Text relevante Informationen und formt daraus einen Graphen. Dies ermöglicht es, Wissen explizit darzustellen und zu erweitern – sei es durch Verknüpfungen mit externen Wissensdatenbanken oder durch eigene Schlussfolgerungen.
So könnte beispielsweise ein Gebäudebeschreibungsmodell Räume als Knoten und Türen oder Flure als Verbindungen darstellen. Besonders in komplexen Abfragen oder Planungsaufgaben zeigt sich der Vorteil: Die KI kann logische Schlüsse ziehen und fundierte Antworten liefern. Allerdings ist fraglich, ob diese Art der Repräsentation für alle Szenarien geeignet ist.
Semantisches Parsen: Von Text zu Logik
Semantisches Parsen geht noch einen Schritt weiter. Hier wird natürliche Sprache in formale logische Repräsentationen übersetzt, die von symbolischen Reasonern verarbeitet werden können. Nehmen wir das Beispiel: „Der Konferenzraum befindet sich neben dem Empfangsbereich.“ Ein semantisch parsierendes System würde daraus eine logische Aussage formulieren: Neben(Konferenzraum, Empfangsbereich). Diese präzise Darstellung ermöglicht es, komplexe Fragen zu beantworten oder Zusammenhänge logisch zu erklären.
Optimierungsprobleme und Constraint Satisfaction
Die Modellierung von Problemen als Constraint Satisfaction Problems (CSP) könnte die Möglichkeiten der Sprachmodelle zusätzlich erweitern. Aufgabe ist es dabei, einen Zustand (d. h. Belegungen von Variablen) zu finden, der alle aufgestellten Bedingungen (Constraints) erfüllt.
Eine KI, die diese Technik nutzt, kann beispielsweise den optimalen Weg durch ein Gebäude unter Berücksichtigung aller Verbindungen und Hindernisse berechnen. Solche Optimierungsaufgaben sind vor allem in der Robotik oder bei Navigationslösungen von unschätzbarem Wert.
Die Herausforderung hierbei ist es jedoch, die ursprüngliche Aufgabenstellung in ein CSP zu transformieren und die Funktionen, Variablen und Bedingungen korrekt aufzustellen.
Logikprogrammierung: Fakten, Regeln und Schlussfolgerungen
Logikprogrammierung, etwa mit Prolog, könnte Sprachmodellen die Möglichkeit eröffnet, durch logische Regeln und Fakten Antworten zu finden. Das Modell erstellt auf Basis eines Prompts ein Programm, das durch symbolische Reasoner ausgeführt wird.
Ein Programm in Prolog ist eine Menge von Fakten und Regeln. Die Anwendung eines Programms besteht in der Beantwortung von Fragen. Antworten sind entweder nur Ja/Nein oder bestehen darin, dass Platzhalter (Variable) der Frage mit einem möglichen Inhalt belegt werden. Prolog-Programme können somit als logische Aussage interpretiert werden und beschreiben einen programmierten Ablauf des Interpreters.
In einem Gebäude-Szenario könnten Fakten wie „adjacent(a, b)“ und „adjacent(b, c)“ verwendet werden, um den besten Weg von Raum A zu Raum C zu berechnen.
Herausforderungen
Natürlich gibt es auch Herausforderungen bei der Integration symbolischer Techniken. Die Ambiguität der natürlichen Sprache ist eine davon. Hier können Disambiguierungstechniken und Rückfragen helfen. Ebenso stellt die Skalierbarkeit neuronaler und symbolischer Systeme ein Problem dar, das jedoch durch clevere Optimierungen, Heuristiken und Approximationsmethoden überwunden werden kann.
Die Verschmelzung symbolischer KI mit neuronalen Modellen könnte den entscheidenden Schritt in Richtung Artificial General Intelligence (AGI) sein. Die Fähigkeit, nicht nur Texte zu verarbeiten, sondern auch logische Schlüsse zu ziehen, eröffnet neue Möglichkeiten in der Robotik, bei Entscheidungsunterstützungssystemen und in kognitiven Anwendungen.
Ein weiteres Problem ist die Kontextgröße. Je größer und komplexer das erstellte Modell wird, desto mehr Daten muss das LLM gleichzeitig verarbeiten. Hier könnten Ansätze wie externe Speichermodule oder Memory-Management-Techniken helfen, um die Leistungsfähigkeit zu erhalten.
Auf dem Weg zur AGI?
Die neural-symbolische Integration kombiniert die Stärken neuronaler Netze und symbolischer Systeme, was besonders interessant ist, um Modelle interpretierbarer und nachvollziehbarer zu machen. Ein Sprachmodell könnte zunächst die Informationen extrahieren und in einer symbolischen Repräsentation organisieren, bevor es durch logische Schlüsse zur gewünschten Antwort gelangt. Diese wird dann in natürliche Sprache zurückübersetzt. Das Ergebnis? Modelle, die nicht nur Wahrscheinlichkeiten manipulieren, sondern logisch denken können.
Auch wenn LLMs noch nicht die ultimative Lösung für eine echte allgemeine Intelligenz darstellen, könnten Ansätze wie „Strawberry“ und die Idee eines Forced-Model-Mechanismus in die richtige Richtung führen.
LLMs könnten bald in der Lage sein, nicht nur logisch zu denken, sondern auch strukturelle Modelle zu entwickeln, die ihnen helfen, komplexe Aufgaben besser zu bewältigen. Die Frage ist nicht mehr, ob LLMs Weltmodelle entwickeln können, sondern wie wir sie dazu bringen, diese Modelle effizient zu erstellen und anschließend gezielt zu nutzen.
Die Diskussion über diese neuen Ansätze ist eröffnet – wer hat Ideen, wie eine universelle Repräsentation für solche Modelle aussehen könnte?
Update: Forced-Model: Neue Erkenntnisse durch den Ansatz der „Visualization-of-Thought“
Nachdem ich das Konzept des „Forced-Model“ entwickelt habe, das LLMs zwingt, vor der Lösung komplexer Aufgaben ein internes Modell zu erstellen, hat sich ein neues Paper aus der Forschung als besonders relevant erwiesen: „Mind’s Eye of LLMs: Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models“ von Wenshan Wu et al. Dieses Paper stellt einen vielversprechenden Ansatz vor, der mein ursprüngliches Konzept entscheidend erweitern könnte.
„Mind’s Eye“ und der Visualization-of-Thought-Ansatz
Das Paper führt den „Visualization-of-Thought“ (VoT)-Mechanismus ein, der darauf abzielt, LLMs zur Erzeugung visueller Darstellungen ihrer Denkprozesse anzuregen. Während herkömmliche LLMs bei der Bearbeitung von Aufgaben wie Navigation oder räumlichem Denken stark auf verbale oder numerische Repräsentationen angewiesen sind, fordert VoT das Modell auf, explizite mentale Bilder zu erzeugen. Diese Visualisierungen, ähnlich einem „inneren Auge“ des Modells, unterstützen das LLM dabei, sich bei jeder Phase einer komplexen Aufgabe an räumlichen Strukturen zu orientieren und bessere Entscheidungen zu treffen.
Interessanterweise ähnelt der VoT-Ansatz meinem Forced-Model-Konzept, bei dem ich vorschlage, dass LLMs gezwungen werden sollten, ein internes Modell einer gegebenen Umgebung zu erstellen, um Probleme Schritt für Schritt besser zu lösen. Doch VoT geht darüber hinaus, indem es das Modell dazu anleitet, seine mentalen Modelle in visuelle Darstellungen umzuwandeln. Dieser visuelle Ansatz könnte nicht nur zur Lösung von Navigationsproblemen beitragen, sondern auch bei der Bearbeitung anderer Aufgaben wie räumlicher Planung und logischer Schlussfolgerungen nützlich sein.
Erweiterung meines Forced-Model-Konzepts
Der VoT-Ansatz bietet eine wertvolle Erweiterung meines ursprünglichen Gedankens. Während ich ein Modell favorisiere, das auf symbolischen Darstellungen wie Graphen oder JSON-Objekten basiert, zeigt das Paper, dass visuelle Darstellungen die kognitiven Fähigkeiten der LLMs erheblich steigern können. In meinen bisherigen Überlegungen ging es hauptsächlich darum, LLMs zu zwingen, eine serialisierte und symbolische Repräsentation zu erstellen, bevor sie die Aufgabe angehen. Der VoT-Ansatz legt jedoch nahe, dass LLMs durch die visuelle Darstellung ihrer „Gedanken“ ein klareres Verständnis komplexer Aufgaben entwickeln können.
Das Potenzial der Visualisierung in LLMs
Die Forscher_innen stellten fest, dass der VoT-Ansatz insbesondere bei räumlichen Aufgaben wie der Navigation in einem 2D-Gitter oder der Lösung von visuellen Puzzles, bei denen geometrische Figuren in eine vorgegebene Struktur eingefügt werden müssen, signifikante Verbesserungen brachte. Diese Aufgaben lassen sich gut mit meinem Beispiel zur Navigation in einem Gebäude vergleichen. Indem das Forced-Model dazu gebracht wird, das Gebäude visuell zu modellieren, anstatt es nur symbolisch zu erfassen, könnte das Modell effizienter und genauer den kürzesten Weg von Raum A nach Raum B finden.
Integration von Visualisierung und symbolischer KI
Eine wichtige Erkenntnis aus dem Paper ist die Möglichkeit, visuelle und symbolische KI zu kombinieren. Mein ursprünglicher Vorschlag war, Techniken der symbolischen KI mit neuronalen Netzen zu kombinieren, um die Präzision und Logik von symbolischen Systemen mit der Flexibilität neuronaler Netze zu verbinden.
Das Paper schlägt jedoch vor, dass die visuelle Darstellung von Gedanken eine weitere wichtige Komponente in dieser Kombination sein könnte. Die Erzeugung und Nutzung von mentalen Bildern könnte symbolische und visuelle Repräsentationen eng miteinander verknüpfen, was zu einer weitaus stärkeren kognitiven Leistung führt.
Implementierung und Herausforderungen
Der VoT-Ansatz könnte direkt in mein Forced-Model-Konzept integriert werden, indem das Modell dazu angehalten wird, nach jeder Denkoperation visuelle Darstellungen seiner internen Zustände zu erstellen. Diese Darstellungen könnten in Form von Graphen, Karten oder anderen visuellen Modellen erfolgen und würden die symbolische Modellierung ergänzen. Besonders interessant ist die Möglichkeit, diese Visualisierungen durch ein Belohnungsmodell zu optimieren, um präzisere und effizientere Darstellungen zu fördern – ein Vorschlag, den ich bereits für die symbolischen Repräsentationen gemacht habe.
Es gibt jedoch auch Herausforderungen, wie im Paper beschrieben. Zum einen ist die Genauigkeit der Visualisierungen noch nicht perfekt. Auch bei der Nutzung des VoT-Ansatzes können fehlerhafte oder ungenaue Darstellungen entstehen, was die Gesamtleistung des Modells beeinträchtigt. Darüber hinaus könnte die Integration von symbolischen und visuellen Repräsentationen skalierbare Lösungen erfordern, um die kognitive Belastung des Modells zu minimieren.
Fazit: Auf dem Weg zur Artificial General Intelligence (AGI)
Die Erkenntnisse aus dem „Mind’s Eye of LLMs“-Paper bieten neue Impulse für die Weiterentwicklung des Forced-Model-Konzepts. Die Kombination aus symbolischer und visueller Modellbildung könnte der Schlüssel sein, um den nächsten Schritt in Richtung Artificial General Intelligence (AGI) zu gehen.
Indem LLMs nicht nur gezwungen werden, komplexe Probleme zu modellieren, sondern diese Modelle auch visuell zu nutzen, könnte ein neues Maß an kognitiver Flexibilität erreicht werden – besonders in Bereichen wie Robotik, Entscheidungsunterstützungssystemen und kognitiven Anwendungen.