Seit Ende 2025 macht ein Konzept namens „Grounding Page Standard“ die Runde. Die Idee: Unternehmen sollen spezielle, maschinenlesbare Seiten erstellen, die als „semantischer Anker“ für KI-Systeme dienen. ChatGPT, Perplexity und Co. sollen diese Seiten heranziehen, um Marken und Entitäten korrekt zu interpretieren – weniger Halluzinationen, mehr Sichtbarkeit in KI-generierten Antworten.
Klingt verlockend. Aber hält das Versprechen einer Überprüfung stand?
Was der Standard verspricht
Das Grounding Page Project definiert sich als offener Standard für „machine-readable brand management“. Die Kernbehauptung: KI-Systeme performen besser, wenn sie strukturierte, konsistente Informationen erhalten. Grounding Pages sollen genau das liefern – faktische, Marketing-freie Entitätsbeschreibungen, die RAG-Systeme und Grounding-APIs bevorzugt heranziehen.
Die Zielgruppe sind Brand Manager und „AI-SEOs“. Die Vision: Eine strukturierte Evolution der klassischen About-Seite für das KI-Zeitalter.
Das Problem: Kein nachweisbarer Mechanismus
Damit eine Grounding Page funktioniert, wie behauptet, müssen zwei Dinge stimmen: Erstens muss ein KI-System die Seite überhaupt abrufen. Zweitens muss es sie gegenüber anderen Quellen bevorzugen.
An beiden Punkten hapert es.
Chatbots suchen seltener als man denkt. Die meisten LLM-basierten Chatbots entscheiden situativ, ob sie eine Websuche durchführen. Bei einer Frage wie „Was macht Firma X?“ passiert zum Teil Folgendes: Kennt das Modell die Firma aus dem Training, antwortet es direkt aus dem parametrischen Wissen – ohne jede Websuche. Die Grounding Page wird gar nicht abgerufen.
Das erzeugt ein Paradox: Starke Marken wie BMW oder SAP brauchen keine Grounding Page, weil LLMs ohnehin genug über sie wissen. Schwache Marken, die am meisten profitieren würden, lösen oft gar keine Suche aus – oder das Modell sagt schlicht „darüber weiß ich nichts“. Perplexity ist eine Ausnahme, weil es grundsätzlich sucht. Aber das ist nur ein System von vielen.
Es gibt keinen Ranking-Vorteil für Grounding Pages. Bei RAG-Systemen entscheidet ein Retrieval-Schritt (typischerweise Embedding-Similarity oder ein Suchindex), welche Dokumente als Kontext in den Prompt kommen. Dieser Schritt kennt keinen Seitentyp namens „Grounding Page“. Er rankt nach semantischer Relevanz zur Anfrage. Eine gut geschriebene Wikipedia-Seite, ein Presseartikel oder eine klassische About-Seite kann genauso gut oder durch Verlinkungen sogar besser ranken.
Bei Googles Grounding-API für Gemini wird aus dem Google-Suchindex gezogen. Da gelten dieselben Ranking-Faktoren wie bei der normalen Suche: Autorität, Relevanz, Linkprofil. Der Seitentyp hat keinen inhärenten Vorteil.
Was tatsächlich hilft
Der erfundene „Standard“ ist überflüssig. Aber die Grundidee dahinter ist nicht verkehrt – sie ist nur nicht neu.
Wer ein gut verlinktes Dokument auf seiner Website pflegt, das klar und faktisch beschreibt, was das Unternehmen ist, was es tut und was es anbietet, macht es KI-Systemen tatsächlich leichter. Konkret:
Informationsdichte und Klarheit. Eine Seite, die frei von Marketing-Fluff ist und stattdessen strukturiert Fakten liefert, hat ein besseres Signal-Rausch-Verhältnis. Wenn ein RAG-System diese Seite in seine Chunks zerlegt, entsteht weniger Rauschen. Die relevanten Informationen sind leichter extrahierbar.
Konsistenz über Quellen hinweg. Wenn die eigene Website sauber und faktisch formuliert, was das Unternehmen ist und tut, steigt die Wahrscheinlichkeit, dass diese Formulierungen im Trainingskorpus des nächsten Modells kohärent repräsentiert sind. Das ist kein Grounding im technischen Sinne – es ist ein Beitrag zur Trainingsqualität.
Strukturierte Daten. Schema.org-Markup (Organization, Product, Service) hilft Knowledge-Graph-Systemen bei der Entitätszuordnung. Das ist ein seit Jahren etabliertes Instrument, kein neuer Standard. LLMs brauchen übrigens kein Schema-Markup und parsen den Quellcode in vielen Fällen auch nicht, sondern schauen sich den puren Text an, den Menschen zu Gesicht bekommen!
Kurzum: Eine saubere, gut verlinkte Informationsseite über das eigene Unternehmen „schmeckt“ einem LLM tatsächlich besser als eine mit Superlativen überladene Marketing-Landingpage. Das war allerdings auch schon vor diesem Standard der Fall und braucht keinen neuen Seitentyp mit eigenem Logo.
Die Drittquellen-Frage
Ein wichtiger Aspekt fehlt in der Diskussion um Grounding Pages fast vollständig: LLMs gewichten Drittquellen in der Regel stärker als Eigenaussagen. Was auf Wikipedia, in Pressartikeln oder in Branchenverzeichnissen über ein Unternehmen steht, hat für die meisten Systeme mehr Gewicht als die eigene About-Seite.
Das Grounding Page Project suggeriert, dass eine strukturierte Eigenaussage den gleichen Effekt haben kann. Die Hoffnung, dass Journalist:innen, Blogger:innen oder Wikipedia-Autor:innen eine Grounding Page als Quelle heranziehen und damit Drittquellen entstehen, die den KI-Systemen als Signal dienen, halte ich für sehr fraglich. Journalist:innen recherchieren nicht auf standardisierten Fakten-Landingpages. Sie suchen Geschichten, Zitate und Kontext – nicht maschinenlesbare Entitätsdefinitionen.
Eine Grounding Page ersetzt nicht die Arbeit, die tatsächlich Drittquellen erzeugt: PR, Thought Leadership, relevante Inhalte, die andere zitieren wollen.
Fazit
Das Grounding Page Project adressiert ein reales Problem: Viele Unternehmen haben ihre Entitäten nie systematisch und faktisch für KI-Systeme beschrieben. Diese Erkenntnis ist richtig und wichtig.
Aber die Lösung braucht keinen eigenen Standard mit Versionsnummer. Sie braucht das, was gute Informationsarchitektur schon immer gebraucht hat: eine klare, gut verlinkte Seite mit faktischen Informationen über das Unternehmen, ergänzt durch strukturierte Daten. Wer das noch nicht hat, sollte damit anfangen. Wer es hat, braucht keine Grounding Page.
Der Mehrwert des Standards liegt allenfalls darin, dass er Unternehmen dazu bringt, erstmals systematisch über ihre Entitätsbeschreibungen nachzudenken. Danke dafür Hanns. Aber für die tatsächliche Wirkung auf KI-Systeme zählt nicht der Seitentyp, sondern die Qualität der Information, die Verlinkung und vor allem die Bestätigung durch Drittquellen, die unabhängig von jeder Grounding Page entsteht – oder eben nicht.
In der SEO- und Marketing-Bubble geistert gerade eine gewaltige Zahl durch die Feeds: 1,2 Millionen. So viele Suchergebnisse hat Kevin Indig in seiner viel beachteten Studie „The Science of How AI Pays Attention“ analysiert. Sein Ziel: Endlich das Geheimnis zu lüften, worauf KI-Suchmaschinen wie Google AI Overviews, Perplexity oder SearchGPT eigentlich achten, wenn sie Antworten generieren.
Das zentrale Ergebnis klingt revolutionär und banal zugleich: KIs sind faul. Sie leiden unter einem massiven „Attention Decay“. Was nicht ganz oben im Text steht, existiert für die Maschine oft gar nicht.
Aber stimmt das wirklich? Ist das ein technisches Limit der großen Sprachmodelle (LLMs), oder messen wir hier nur menschliche Gewohnheiten? Und vor allem: Wie belastbar ist diese „Big Data“-Analyse eigentlich für unsere tägliche Arbeit?
Als jemand, der sich tief in die Wissenschaft, LLMs und Generative Engine Optimization (GEO) eingegraben hat, habe ich mir die Studie methodisch sehr genau angesehen. Lass uns gemeinsam die „Statistik-Zwiebel“ schälen, die akademische Beweislage prüfen und schauen, was am Ende wirklich an Gold für deine Content-Strategie übrig bleibt:
Die Statistik-Zwiebel: Was bedeuten „1,2 Millionen“ wirklich?
Bevor wir Ergebnisse blind übernehmen, müssen wir die Datenbasis verstehen. In der heutigen „Headline-Ökonomie“ wirken große Zahlen wie Autoritäts-Booster. „1,2 Millionen analysierte Ergebnisse“ suggeriert eine lückenlose Vermessung des Internets, die keinen Raum für Zufälle lässt.
Doch wissenschaftlich betrachtet müssen wir differenzieren. Man muss sich die Datenbasis wie eine Zwiebel oder einen Trichter vorstellen, der nach unten hin immer enger wird:
Der Top of Funnel (Die Basis): Ja, es wurden 1,2 Millionen Keywords (SERPs) überwacht. Das ist das Spielfeld. Aber hier liegt bereits der erste „Selection Bias“: Die Keywords waren stark kommerziell geprägt (z.B. „Best CRM Software“). Informationsorientierte Nischen-Themen sind unterrepräsentiert.
Der erste Filter (AI-Trigger): Nicht jede Suche löst eine AI-Antwort aus. Die Verbreitung von AI Overviews schwankt massiv. Wir betrachten also nur die Teilmenge, bei der Google überhaupt eine Antwort generiert hat.
Die Extraktion (Zitate): Jede AI-Antwort enthält Quellen. Diese müssen extrahiert werden.
Das Matching (Der kritische Kern): Um zu prüfen, wo im Text eine Information stand, muss die Studie den zitierten Satz exakt im Quellcode der Webseite wiederfinden. Hier schrumpft die Datenbasis von der Million auf einen Bereich von ca. 18.000 bis 50.000 verifizierten Datenpunkten.
Zwischenfazit: Die Stichprobe ist immer noch groß genug, um statistisch signifikant zu sein – sie ist weit besser als bloßes Bauchgefühl. Aber sie ist kein absolutes Naturgesetz. Wir sollten die Ergebnisse als starke Heuristik (Faustregel) betrachten, aber immer im Hinterkopf behalten, dass hier primär „Review-Content“ analysiert wurde! Eine Übertragung auf andere Content-Typen ist zumindest fraglich!
Der „Front-Loading“-Effekt: Ein klassisches Henne-Ei-Problem
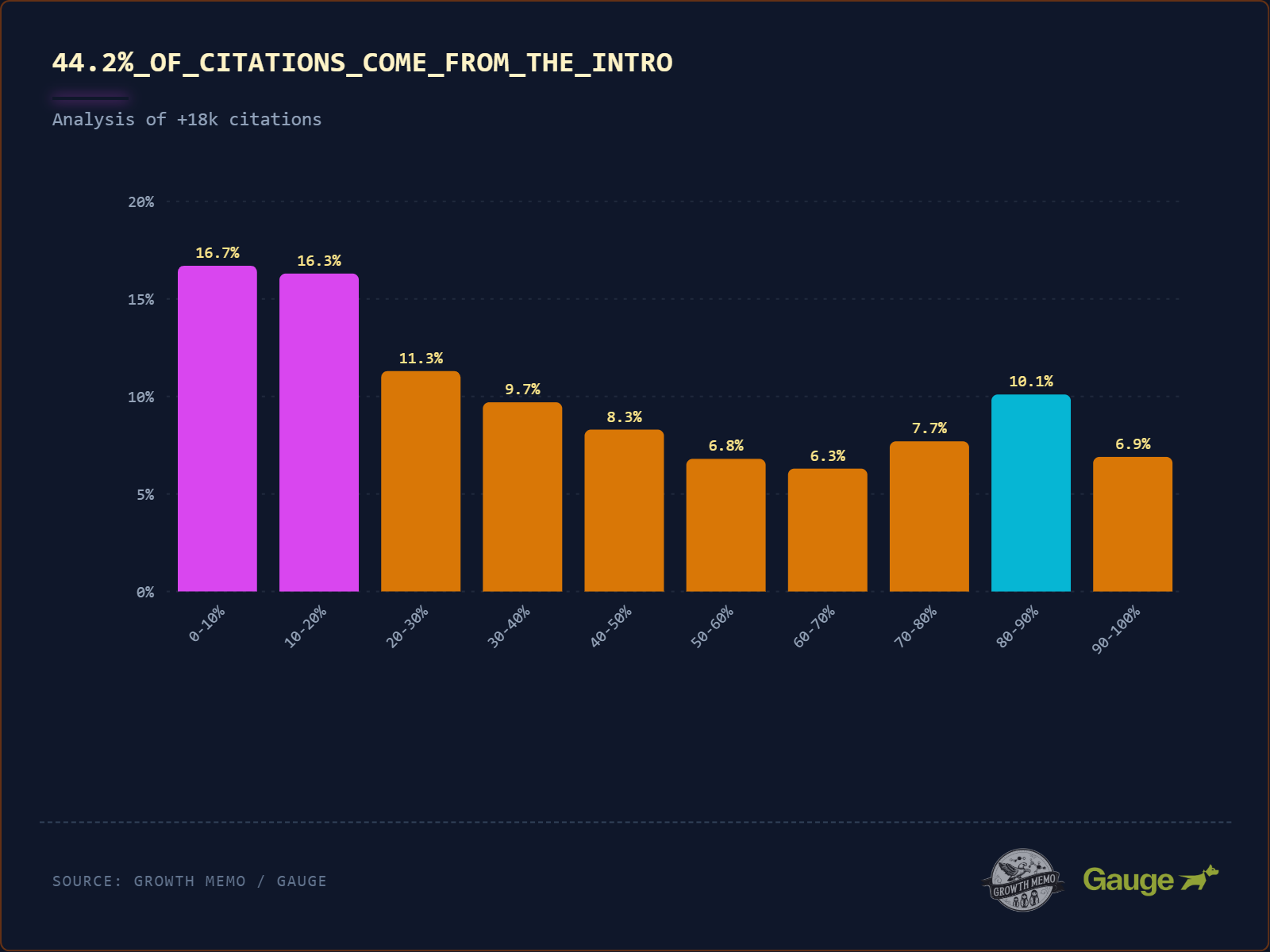
Das wichtigste Chart der Studie ist visuell eindeutig: 44,2 % aller Zitate stammen aus den ersten 30 % des Contents. Danach fällt die Kurve steil ab. Indig nennt das treffend den „Busy Editor“-Effekt: Die KI liest wie ein gestresster Chefredakteur – ein schneller Scan des Intros, die wichtigsten Fakten werden mitgenommen, der Rest wird ignoriert.
Hier müssen wir jedoch methodisch kritisch einhaken. Die Studie zeigt eine Korrelation, keine Kausalität.
Die These der Studie: Die KI bevorzugt technisch den Anfang (Attention Bias).
Der Gegenentwurf (Nullhypothese): Gute Autoren schreiben seit 100 Jahren nach dem Prinzip der „Umgekehrten Pyramide“.
Jeder Journalist lernt am ersten Tag: Das Wichtigste (die News, das Fazit, die Antwort) gehört nach oben – „Above the Fold“. Wenn also 90 % der relevanten Fakten im Internet zufällig im ersten Drittel stehen, dann muss die KI sie dort finden, um die Frage korrekt zu beantworten.
Sprich: Messen wir hier also einen Bias der Maschine oder einfach nur den Qualitätsstandard guter Autoren? Die Studie selbst kann das aufgrund ihres Designs (Beobachtung von Live-Daten statt Labor-Experiment) nicht auflösen.
Die wissenschaftliche Evidenz: Warum Indig trotzdem recht hat
Müssen wir die Studie also verwerfen? Nein. Denn auch wenn Indigs Design die Ursache nicht isolieren kann, gibt es harte wissenschaftliche Rückendeckung für die „Front-Loading“-These aus der Computerwissenschaft.
Die berühmte Studie „Lost in the Middle“ von Liu et al. beweist das Phänomen unter Laborbedingungen. Die Forscher zeigten, dass LLMs (wie GPT-4 oder Claude) eine U-förmige Aufmerksamkeitskurve haben:
Primacy Effect: Informationen ganz am Anfang des Kontext-Fensters werden exzellent verarbeitet.
Recency Effect: Informationen ganz am Ende ebenfalls.
The Valley of Death: Informationen in der Mitte eines langen Kontextes werden signifikant häufiger „vergessen“ oder halluziniert.
Dazu kommt ein technischer Aspekt der RAG-Systeme (Retrieval Augmented Generation): Um Kosten und Rechenleistung zu sparen, lesen Crawler oft nicht die gesamte Seite, sondern setzen ein Token-Limit. Da wir als SEOs nie wissen, wann der Crawler „abschneidet“ (Cut-off), ist das Ende einer Seite ein unsicherer Ort. Der Anfang bleibt der einzige sichere Hafen für deine Kernbotschaften.
Die 5 Gewinnermerkmale der KI-Suche (und ihr Faktencheck)
Neben der Positionierung hat die Studie fünf spezifische textliche Eigenschaften identifiziert, die Gewinner-Inhalte gemeinsam haben. Doch auch hier gilt: Nicht blind optimieren! Lass uns jeden Punkt mit der gleichen methodischen Strenge behandeln wie das Front-Loading.
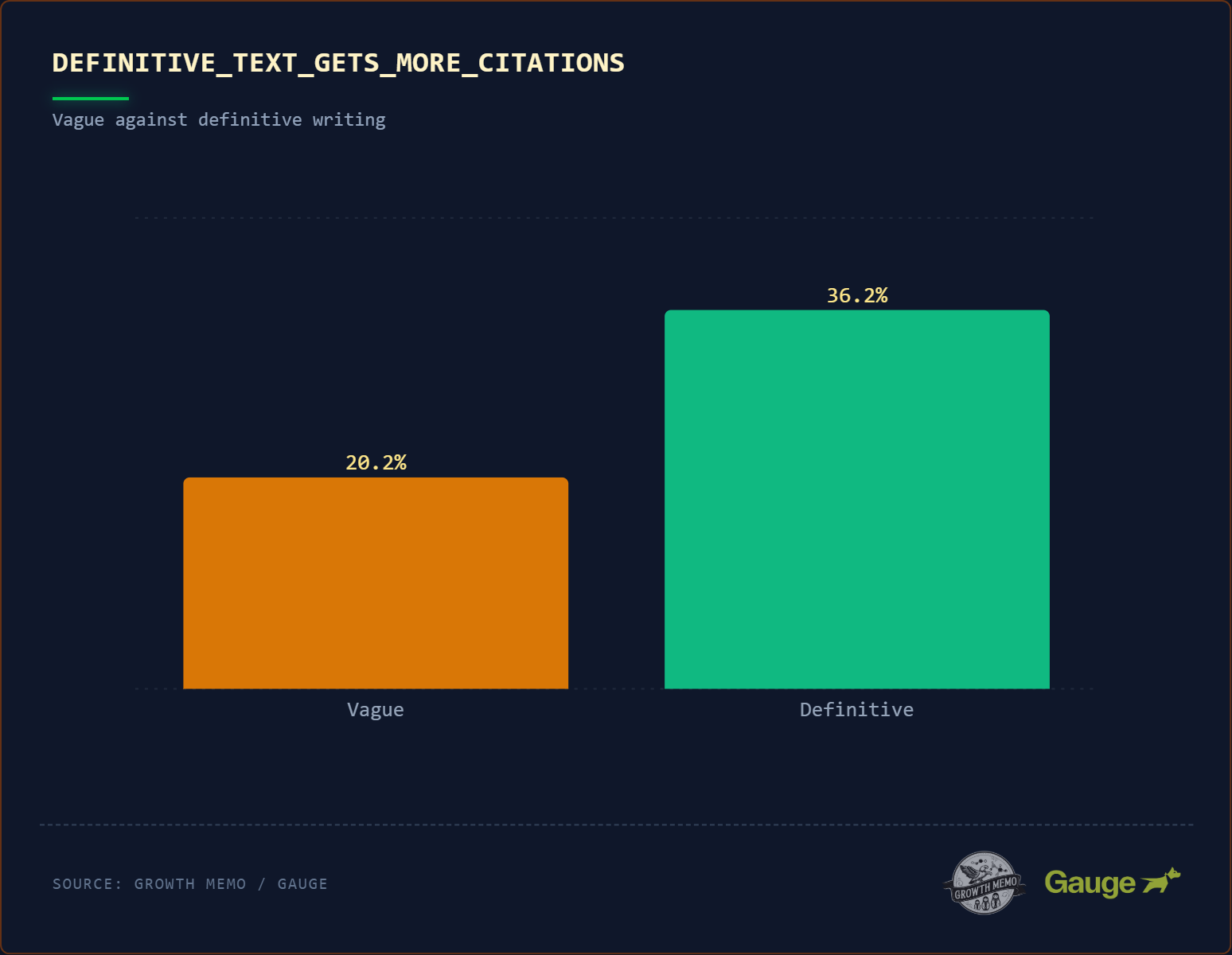
A. Definitive Language (Klartext statt Konjunktiv)
Was die Studie sagt: Zitierte Texte enthalten fast doppelt so häufig definitive Sprache wie nicht-zitierte (36,2 % vs. 20,2 %). Gemeint sind klare „X ist Y“-Strukturen mit Verben wie „is defined as“ oder „refers to“.
Die methodische Einordnung: Die Erklärung der Studie klingt technisch elegant: In einer Vektor-Datenbank fungiere das Wort „ist“ als starke semantische Brücke zwischen Subjekt und Definition. Wenn ein Nutzer fragt „Was ist X?“, suche das Modell den kürzesten Vektorpfad – und der führe fast immer zu einem direkten „X ist Y“-Satz.
Das ist im Kern korrekt, aber die Kausalität ist komplizierter als die Studie es darstellt. Was wir hier beobachten, ist kein mysteriöser „Preference Bias“ der KI für Klartext. Es ist ein Artefakt der Architektur.
LLMs operieren auf Basis eines Attention-Mechanismus (Vaswani et al., 2017, „Attention Is All You Need“). Dieser Mechanismus berechnet die Beziehungsstärke zwischen Token-Paaren im Kontext. Ein Satz wie „Demo-Automatisierung ist der Prozess der Nutzung von Software zur…“ erzeugt in der Attention-Matrix einen extrem starken, gerichteten Pfad vom Subjekt zum Prädikat. Ein Satz wie „In unserer schnelllebigen Welt wird Automatisierung immer wichtiger…“ verteilt die Attention-Gewichte diffus auf irrelevante Füllwörter – die eigentliche Relation ertrinkt im Rauschen.
Das Phänomen lässt sich auch über das Konzept der Perplexität erklären: Definitive Sätze sind für das Modell vorhersagbarer (niedrigere Perplexität), weil die „X ist Y“-Struktur eines der häufigsten Muster in den Trainingsdaten ist. Schwammige Formulierungen erhöhen die Perplexität, was das Modell als Signal für geringere Informationsqualität interpretiert.
Aber Vorsicht – der YMYL-Vorbehalt: In Nischen wie Medizin, Recht oder Finanzen kann ein „X ist Y“-Absolutismus gefährlich werden. Wenn ein medizinischer Text behauptet „Vitamin D heilt Depressionen“ statt „Studien zeigen einen Zusammenhang zwischen Vitamin-D-Mangel und depressiven Symptomen“, dann gewinnt er vielleicht das Zitat – aber verliert die fachliche Seriosität. Googles Quality-Rater-Guidelines bewerten übermäßige Vereinfachung in YMYL-Bereichen explizit negativ! Die Empfehlung „Schreib definitiv“ ist also kein Universalgesetz, sondern gilt primär für die untersuchte Stichprobe kommerzieller Ratgeber-Queries.
Das Fazit für deine Praxis: Beantworte die Kernfrage in deinem ersten Satz mit einer klaren „X ist Y“-Struktur. Aber verwechsle „definitiv“ nicht mit „vereinfacht“. Präzision schlägt Vagheit – aber erfundene Gewissheit schlägt zurück.
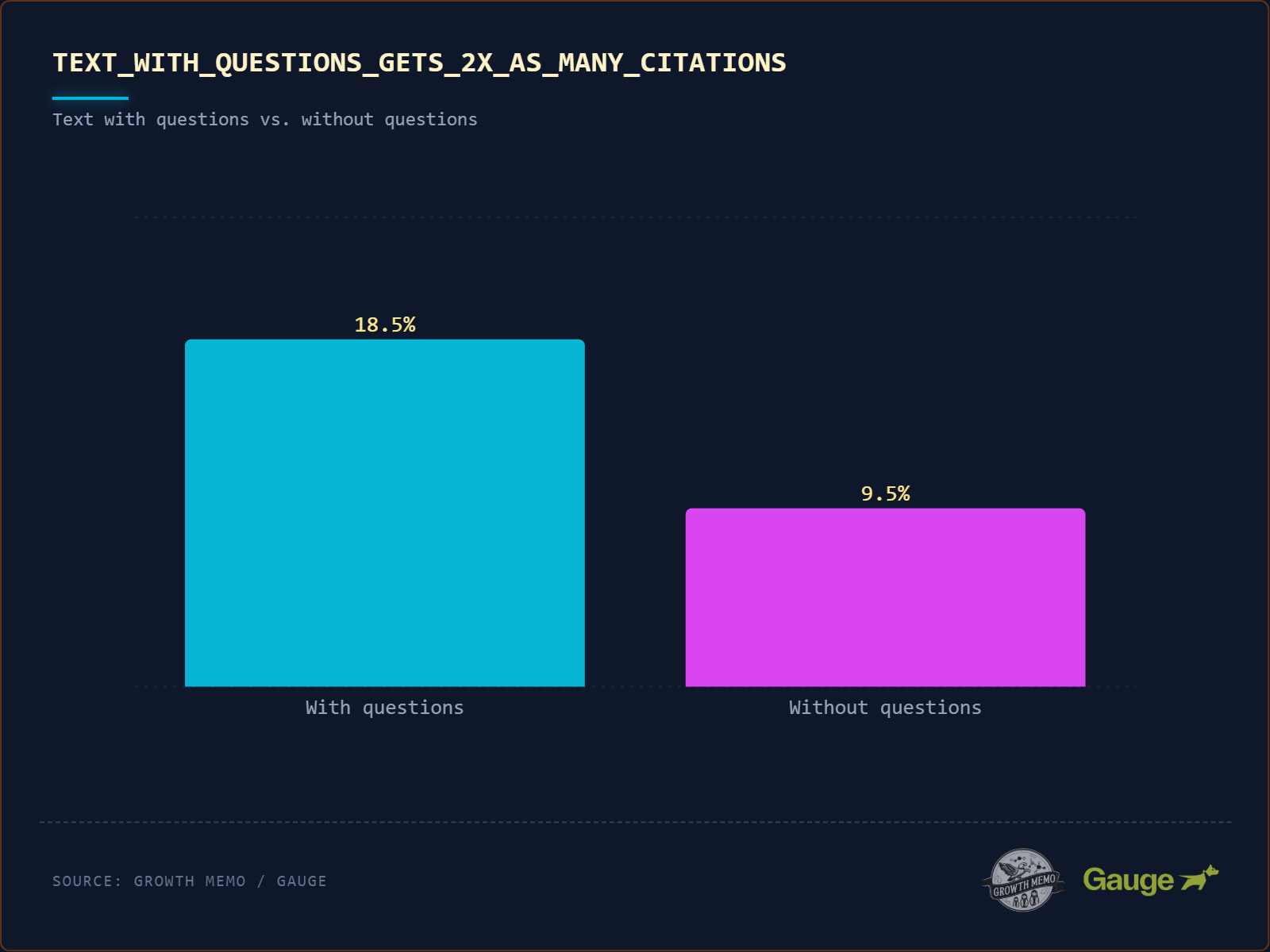
B. Conversational Question-Answer Structure (Q&A-Format)
Was die Studie sagt: Zitierte Texte enthalten doppelt so häufig Fragezeichen wie nicht-zitierte (18 % vs. 8,9 %). Noch wichtiger: 78,4 % dieser Fragen stehen in Überschriften (H2-Tags). Die KI behandelt die Überschrift als User-Prompt und den folgenden Absatz als generierte Antwort.
Die methodische Einordnung: Von allen fünf Ergebnissen hat dieses die stärkste kausale Begründung – und zwar direkt aus der Architektur moderner LLMs.
Der Grund liegt im sogenannten „Instruction Tuning“ (auch „RLHF“ – Reinforcement Learning from Human Feedback, Ouyang et al., 2022). Jedes moderne LLM durchläuft nach dem Pretraining eine Feinabstimmungsphase, in der es auf Millionen von Frage-Antwort-Paaren trainiert wird. Das innere Format ist dabei immer identisch: User: [Frage] → Assistant: [Antwort]. Dieses Schema ist so tief im Modell verankert, dass es quasi die „Muttersprache“ jedes LLMs darstellt.
Wenn du nun eine H2-Überschrift als Frage formulierst und im ersten Satz darunter direkt antwortest, dann replizierst du exakt das Format, auf das das Modell optimiert ist. Die Studie beschreibt dafür den treffenden Mechanismus des „Entity Echoing“: Wenn die Überschrift nach „SEO“ fragt und das erste Wort der Antwort „SEO“ ist, erzeugt das im Attention-Mechanismus einen direkten Rückbezug, der die Relevanz des Absatzes für die Frage maximiert.
Das ist auch aus der Information-Retrieval-Forschung gut belegt. BM25, der klassische Ranking-Algorithmus, bewertet Term-Frequenz und inverse Dokumentfrequenz. Neuere Dense-Retrieval-Modelle arbeiten ähnlich: Ein Passage wird als relevant für eine Query eingestuft, wenn die semantische Überlappung im Embedding-Raum hoch ist. Eine Frage-Überschrift, die das Query exakt spiegelt, erzeugt maximale Überlappung.
Warum das Ergebnis trotzdem nicht universell ist: Die 78,4 % gelten für die untersuchte Stichprobe kommerzieller Queries. Für narrative Formate (Longform-Reportagen, wissenschaftliche Abhandlungen) ist eine reine Q&A-Struktur weder üblich noch sinnvoll. Die Studie misst, was KI-Suchmaschinen für informationssuchende Queries zitieren – nicht, was generell den „besten“ Content ausmacht.
Das Fazit für deine Praxis: Formuliere deine H2-Überschriften als exakte User-Fragen. Beginne den ersten Satz darunter mit einer direkten Antwort, die die Schlüssel-Entität aus der Frage wiederholt. Das ist kein Hack – es ist die strukturelle Sprache, die LLMs am besten verstehen.
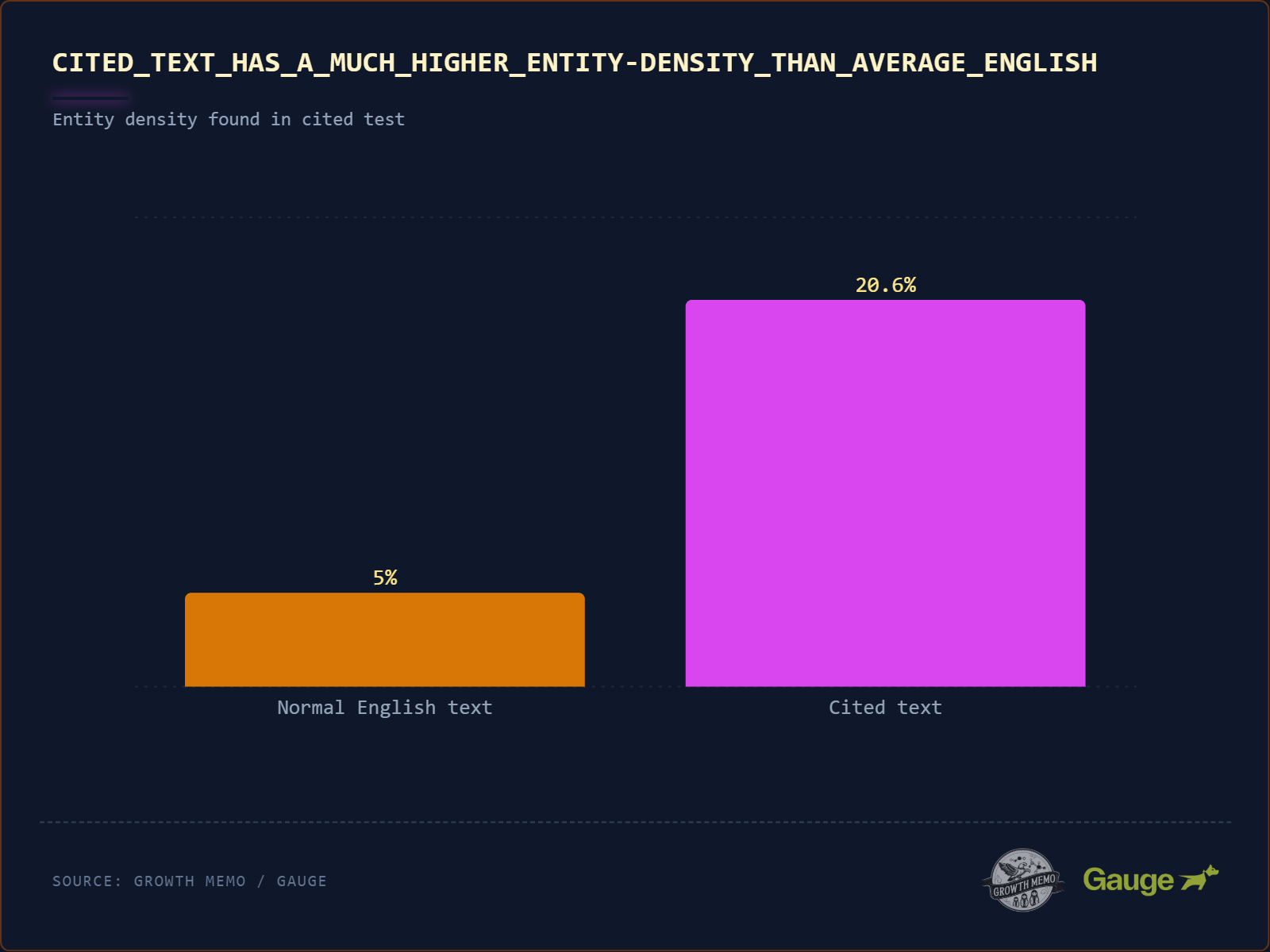
C. Entity Richness (Faktendichte)
Was die Studie sagt: Normaler englischer Text hat eine „Entitätsdichte“ (Anteil von Eigennamen wie Marken, Tools, Personen) von ca. 5–8 %. Häufig zitierter Text liegt bei 20,6 % – fast dem Vierfachen.
Die methodische Einordnung: Die Referenzwerte von 5–8 % stammen laut Studie aus linguistischen Standard-Korpora wie dem Brown Corpus und dem Penn Treebank. Das ist eine solide Benchmark für „durchschnittliches Englisch“. Der Sprung auf 20,6 % ist beeindruckend – aber methodisch liegt hier ein klassischer Zirkelschluss vor, den die Studie nicht adressiert.
Das Problem: Die untersuchten Suchanfragen sind überwiegend kommerziell und entitätsbezogen. „Best CRM Software“ verlangt nach Antworten, die Salesforce, HubSpot und Pipedrive nennen. Ein Text, der diese Frage beantwortet, ohne Entitäten zu nennen, wäre schlicht eine schlechte Antwort. Die hohe Entitätsdichte der „Winner“ ist also kein KI-Bias, sondern eine Mindestanforderung an inhaltliche Relevanz für diese Art von Queries.
Wissenschaftlich lässt sich das über das Konzept des „Information Gain“ einordnen. In der Information-Retrieval-Theorie wird ein Dokument als relevanter eingestuft, wenn es mehr neue, konkrete Information liefert als konkurrierende Dokumente. Entitäten sind dabei die effizientesten Informationsträger: Der Satz „Das Gerät ist schnell“ enthält nahezu null Information Gain. Der Satz „Der Apple M2-Chip verarbeitet 15,8 Billionen Operationen pro Sekunde“ trägt drei Entitäten (Apple, M2, Operationen/Sekunde) und einen konkreten Datenpunkt. Für ein Sprachmodell bedeutet mehr Entitäten pro Satz weniger Perplexität bei der Antwortgenerierung – die Aussage ist „verankert“ und verifizierbar.
Das Gegenargument: Die 20,6 % sind kein Zielwert zum Reverse-Engineeren. Wenn du künstlich Markennamen in einen Text stopfst, der sie nicht braucht, verschlechterst du die Lesbarkeit, ohne Relevanz zu gewinnen. Entitäten sind kein Stilmittel, sondern ein Indikator für Informationsdichte. Der Unterschied ist entscheidend!
Das Fazit für deine Praxis: Ersetze generische Formulierungen durch konkrete Entitäten – Markennamen, Produktbezeichnungen, Kennzahlen, Personennamen. Aber tu das nicht als Keyword-Stuffing, sondern weil es deinen Text faktisch besser macht. Und ja: Nenne ruhig auch Wettbewerber. Ein Vergleich „Salesforce vs. HubSpot vs. Pipedrive“ ist für die KI informativer als „verschiedene Tools im Vergleich“.
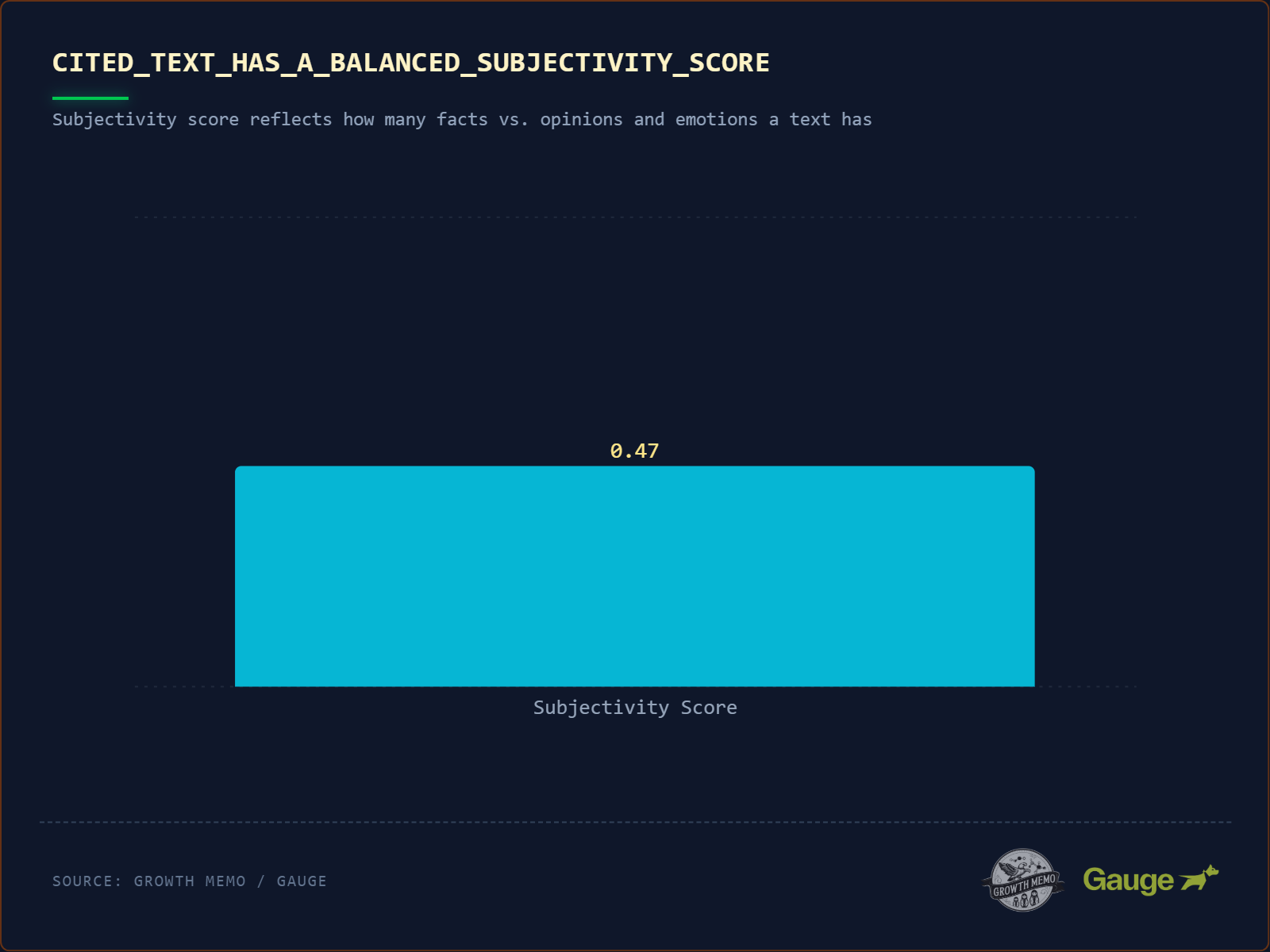
D. Balanced Sentiment (Die „Analysten-Stimme“)
Was die Studie sagt: Zitierte Texte haben einen durchschnittlichen Subjectivity Score von 0,47 auf einer Skala von 0,0 (rein objektiv) bis 1,0 (rein subjektiv). Die KI will weder trockenen Wikipedia-Stil (0,1) noch ungefilterte Meinung (0,9), sondern eine Art „Analysten-Stimme“.
Die methodische Einordnung: Der Subjectivity Score ist eine Standard-Metrik im Natural Language Processing (NLP) und misst den Anteil persönlicher Meinungen, Emotionen oder Wertungen in einem Text. Die Studie nutzt ihn, um zu zeigen, dass ein ausgewogener Ton bevorzugt wird. Aber wie belastbar ist dieser Wert?
Zunächst das methodische Problem: Ein Subjectivity Score von 0,47 ist ein Durchschnitt. Durchschnitte können irreführend sein, wenn die Verteilung bimodal ist – also wenn sowohl sehr objektive als auch sehr subjektive Texte zitiert werden und sich der Mittelwert „zufällig“ bei 0,5 einpendelt. Ohne Einsicht in die Verteilung der Scores (Standardabweichung, Quartile) ist die Aussagekraft begrenzt.
Trotzdem ist das Ergebnis wissenschaftlich plausibel, und zwar aus zwei Gründen:
Erstens durchlaufen alle modernen LLMs ein Safety-Alignment via RLHF. In diesem Prozess werden die Modelle systematisch darauf trainiert, ausgewogene, hilfreiche und nicht-polarisierende Antworten zu bevorzugen. Wenn ein Retrieval-System einen Textbaustein für eine Antwort auswählt, wird ein Kandidat, der selbst bereits dem trainierten „Ton“ des Modells ähnelt, mit höherer Wahrscheinlichkeit übernommen. Extreme Meinungen – ob euphorisch positiv oder harsch negativ – weichen vom trainierten Gleichgewicht ab und werden häufiger verworfen.
Zweitens gibt es einen informativen Grund: Ein rein faktischer Satz („Das iPhone 15 wurde im September 2023 veröffentlicht“) beantwortet ein „Wann?“, aber kein „Warum sollte mich das interessieren?“. Ein rein meinungsbasierter Satz („Das iPhone 15 ist ein absolutes Meisterwerk!“) liefert keine verwertbare Information. Der „Sweet Spot“ bei ~0,5 ergibt sich, weil die nützlichsten Antworten Fakt und Einordnung verbinden: „Das iPhone 15 setzt auf den A16-Chip (Fakt), was es besonders für Content Creator attraktiv macht (Analyse).“
Das Fazit für deine Praxis: Schreib wie ein Analyst, nicht wie ein Marktschreier und nicht wie ein Lexikon. Jede Behauptung braucht einen Fakt als Fundament, und jeder Fakt profitiert von einer Einordnung, die dem Leser (und der KI) sagt, warum er relevant ist. Vermeide sowohl werbliche Superlative („Das beste Tool aller Zeiten!“) als auch emotionslose Datenfriedhöfe.
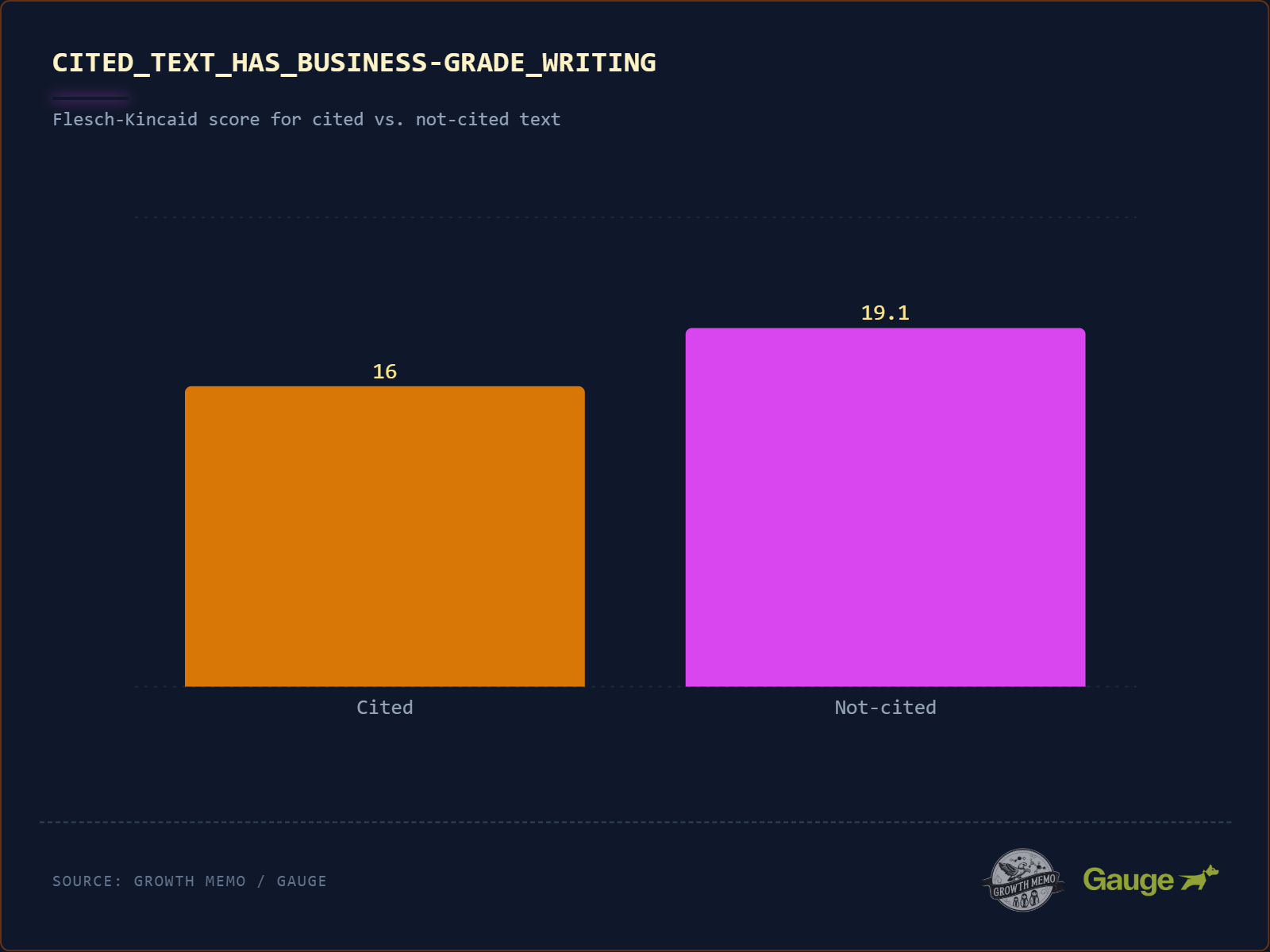
E. Business-Grade Writing (Einfachheit ≠ Verdummung)
Was die Studie sagt: „Winner“-Texte haben einen Flesch-Kincaid-Grade-Level von 16 (College-Niveau), „Loser“-Texte von 19,1 (akademisches PhD-Niveau). Selbst bei komplexen Themen schadet übermäßige sprachliche Komplexität.
Die methodische Einordnung: Der Flesch-Kincaid-Score ist eine der ältesten Lesbarkeitsformeln (Kincaid et al., 1975) und basiert auf genau zwei Variablen: durchschnittliche Satzlänge und durchschnittliche Silbenzahl pro Wort. Das ist einerseits ein Vorteil (objektiv, reproduzierbar), andererseits eine massive Vereinfachung. Der Score misst Oberflächenkomplexität, nicht inhaltliche Tiefe.
Was die Studie trotzdem richtig erfasst, ist ein Architektur-Effekt der Transformer-Modelle. LLMs verarbeiten Text Token für Token und berechnen Attention-Gewichte zwischen allen Token-Paaren in einem Fenster. Bei langen Schachtelsätzen mit vielen Einschüben steigt die Distanz zwischen semantisch zusammengehörigen Token. Die Attention muss über mehr „Rauschen“ hinweg die richtige Verbindung herstellen – was die Wahrscheinlichkeit erhöht, dass der semantische Bezug verloren geht.
Konkret: Der Satz „Salesforce, das 1999 von Marc Benioff gegründete und heute in San Francisco ansässige Unternehmen, das sowohl im B2B- als auch im B2C-Segment aktiv ist, bietet eine CRM-Lösung an“ zwingt das Modell, über 25+ Token hinweg die Verbindung zwischen „Salesforce“ und „CRM-Lösung“ aufrechtzuerhalten. Der Satz „Salesforce bietet eine CRM-Lösung an“ erzeugt die gleiche Kernaussage mit maximaler Attention-Konzentration.
Hier widerlegt die Studie übrigens eine verbreitete Annahme in der SEO-Szene: Nein, KI belohnt nicht das „Dumbing Down“ von Content! Ein Flesch-Kincaid-Score von 16 ist College-Niveau – das entspricht dem Stil von The Economist oder Harvard Business Review. Es geht nicht darum, Fachsprache zu vermeiden, sondern darum, sie in klaren syntaktischen Strukturen zu verpacken. „Einfache Sprache“ bedeutet: kurze Sätze, Subjekt-Verb-Objekt, ein Gedanke pro Satz. Es bedeutet nicht: einfache Gedanken.
Das Fazit für deine Praxis: Vereinfache die Satzstruktur, nicht den Inhalt. Zerlege komplexe Aussagen in mehrere kurze Sätze. Nutze Fachbegriffe, wenn sie nötig sind – aber bette sie in klare syntaktische Strukturen ein. Dein Zielwert ist „The Economist“, nicht „Blöd-Zeitung“ und nicht „Doktorarbeit“.
Du willst tiefer in die Welt der Generative Engine Optimization eintauchen und lernen, wie du deine Inhalte systematisch für die KI-Suche fit machst? Genau darum geht es in meinem neuen Buch „SEO für KI – Auf den Punkt“, an dem ich gerade schreibe. Abonniere gerne meinen Newsletter, um den Start nicht zu verpassen.
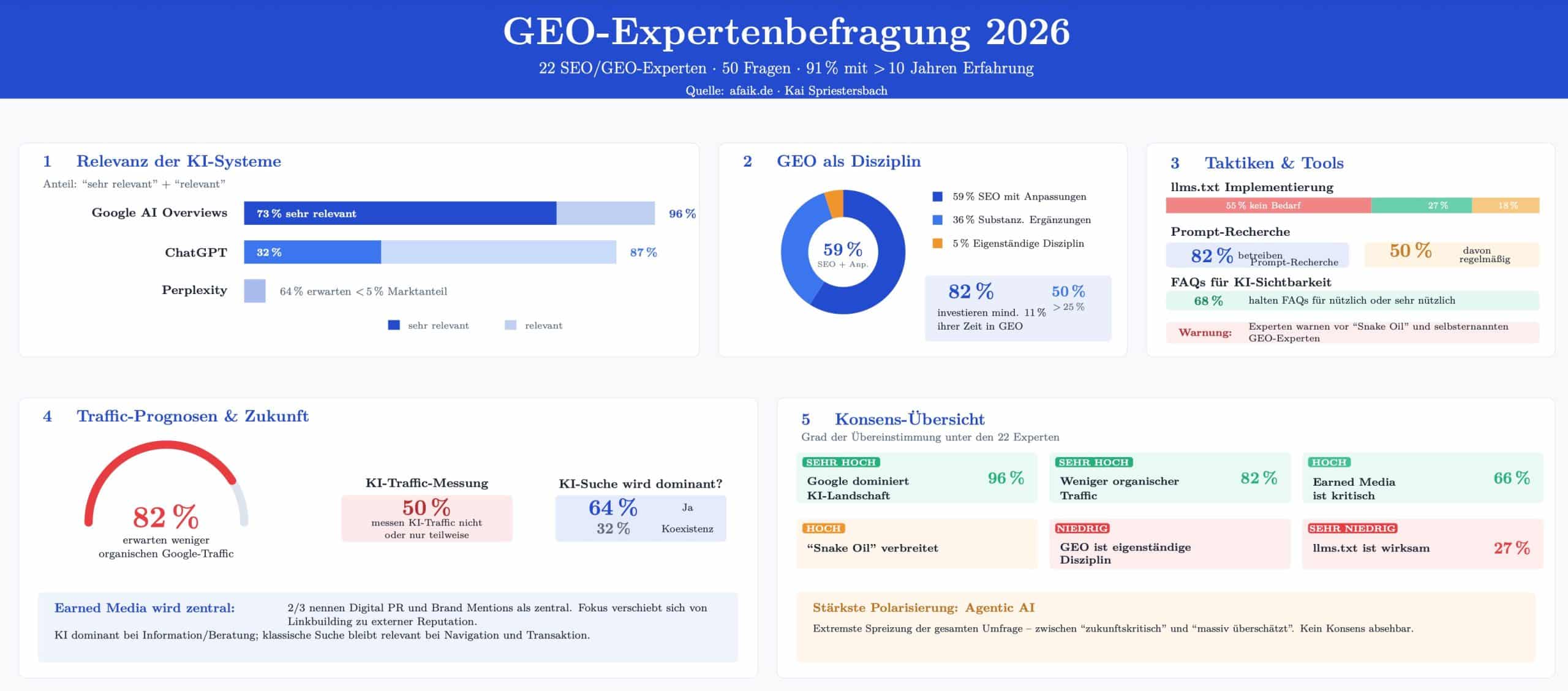
22 der erfahrensten SEO-Köpfe im DACH-Raum, eine Umfrage mit 50 Fragen, null Konsens bei den spannendsten Themen. Die Ergebnisse der GEO-Expertenbefragung für mein kommendes Buch „SEO für KI“ (O’Reilly Verlag) sind da — und sie räumen mit einigen Mythen auf.
Im Januar 2026 habe ich für mein Buch „SEO für KI — Auf den Punkt“ (O’Reilly Verlag, geplant Q3 2026) eine umfangreiche Expertenbefragung durchgeführt. 22 deutschsprachige SEO- und GEO-Experten haben sich die Zeit genommen, 50 Fragen zu beantworten — von der Relevanz einzelner KI-Systeme über Prompt-Recherche bis hin zu Agentic AI. 91 Prozent der Teilnehmer bringen mehr als zehn Jahre SEO-Erfahrung mit, verteilt auf Agenturen, Beratung, Tool-Anbieter und Inhouse-Positionen.
Was dabei herausgekommen ist, überrascht an vielen Stellen. Nicht weil die Antworten besonders exotisch wären, sondern weil sie so nüchtern sind. Hier die wichtigsten Erkenntnisse.
Daten: GEO-Expertenbefragung 2026 · afaik.de/geo-expertenbefragung-2026 · Kai Spriestersbach · Visualisierung: TikZ/LATEX via Claude Cowork
1. Google dominiert, der Rest kämpft um Aufmerksamkeit
Die deutlichste Botschaft der Umfrage: Wer über KI-Sichtbarkeit spricht, spricht zuerst über Google. 73 Prozent der Befragten halten Googles AI Mode und AI Overviews für „sehr relevant“, weitere 23 Prozent für „relevant“. Kein einziger Experte stuft Google als wenig oder nicht relevant ein. Das ist der stärkste Konsens aller Relevanz-Bewertungen in der gesamten Umfrage.
ChatGPT folgt mit Abstand auf Platz zwei: 32 Prozent „sehr relevant“, 55 Prozent „relevant“. Dahinter wird es dünn. Perplexity, Copilot und Claude werden von der Mehrheit als nachrangig eingestuft. Die KI-Suchlandschaft ist in der Wahrnehmung der Experten ein Zweikampf — und Google führt deutlich.
Besonders aufschlussreich sind die Prognosen für die kommenden drei Jahre. 64 Prozent erwarten für Perplexity einen Marktanteil von unter 5 Prozent. Und bei ChatGPT gehen die Meinungen so weit auseinander wie bei keiner anderen Frage: Von „unter 5 Prozent“ bis „über 50 Prozent“ ist alles vertreten. 18 Prozent trauen sich nicht einmal eine Einschätzung zu — die höchste Enthaltungsrate der gesamten Befragung. Johannes Beus (Geschäftsführer, SISTRIX GmbH) erklärt die Skepsis gegenüber Perplexity: Es fehle an eigenen Modellen, eigenem Index und Distributionskanälen. Eric Kubitz (Head of AI, Wort & Bild Verlag) merkt pragmatisch an: „Kommt darauf an, wer Perplexity kauft.“
Meine Meinung dazu: Angesichts der jünsten Werbeintegration bei ChatGPT und immer besserer KI in Googles Suchergebnissen, gehe ich nicht davon aus, dass OpenAI weiter an Marktanteilen gewinnt. Perplexity ist seit der integration der Deep Research Funktion in so gut wie allen Chatbots auch kein besseres Produkt mehr – also wieso sollte man wechseln?
2. GEO ist kein neues SEO — aber auch kein altes
Die Gretchenfrage: Ist GEO eine eigene Disziplin oder nur SEO mit neuem Anstrich? Die Antwort fällt differenzierter aus als der LinkedIn-Diskurs vermuten lässt. 59 Prozent sehen GEO als „SEO mit Anpassungen“, 36 Prozent halten „substanzielle Ergänzungen“ für nötig, und ein einzelner Befragter sieht „unterschiedliche Disziplinen“.
Die qualitative Analyse zeigt: Die meisten Experten verankern GEO klar im SEO-Kontext, sehen aber gleichzeitig echten Zusatzaufwand. Astrid Kramer (Senior SEO & UX Consultant, Get Em All Consult) bringt es auf den Punkt: „Allerdings ist das bei genauer Betrachtung kein GEO, sondern einfach hochwertiges SEO, wie es bereits seit Jahren gemacht werden sollte.“
Michael Weber (Geschäftsführer, searchVIU GmbH) argumentiert technisch: „Solange KI-Systeme auf klassische Such-Indizes für ihr Grounding zurückgreifen, bleibt SEO das Fundament jeder LLM-Optimierung.“ Und Philipp Götza (SEO Consultant, Wingmen Online Marketing) erdet die Diskussion: „Es sind immer die langweiligen Sachen, die wir lange und konsistent gut machen müssen, um erfolgreich zu sein. Das ändert sich nicht, nur weil es ein neues Akronym gibt.“
Marcus Tandler (Chief Evangelist at Ryte, Semrush) sieht es anders: Für ihn ist der Ratschlag „Klassisches SEO ist genug!“ einer der am meisten überbewerteten Tipps der Branche. Er fordert ein fundamentales Umdenken: „Klassisches SEO optimiert für den Crawler. Modernes SEO über das Standardmaß hinaus optimiert für den Reasoning-Prozess der KI. Wir müssen aufhören, nur Dokumente zu bauen, und anfangen, Wissensmodelle zu füttern.“
Eoghan Henn (Freier Berater, rebelytics.com) bleibt dagegen bei der Erfahrung: „Bisher kann ich nicht behaupten, dass ich mit gezielten Maßnahmen den GEO-Erfolg meiner Kunden verbessern konnte. Allerdings sehe ich, dass eine starke SEO-Basis auch eine gute Voraussetzung für den GEO-Bereich ist.“
Trotzdem: Kein einziger Befragter investiert null Prozent seiner Arbeitszeit in GEO-Themen. 82 Prozent investieren mindestens 11 Prozent, fast die Hälfte sogar über 25 Prozent. Für eine Disziplin, die erst seit rund zwei Jahren existiert, ist das bemerkenswert.
Ich persönliche sehe GEO als Erweiterung des bisherigen SEO, man könnte auch sagen eine Weiterentwicklung, denn in Zukunft wird kein Suchsystem mehr ohne KI auskommen!
3. llms.txt: Der Mythos, der nicht sterben will
Eines der vielleicht überraschendsten Ergebnisse: 55 Prozent der Experten haben llms.txt nicht implementiert und sehen auch keinen Bedarf. Nur 27 Prozent haben es umgesetzt. Angesichts des medialen Hypes ein klares Signal.
Philipp Götza ist deutlich: „llms.txt. Vorgeschlagen, nie wieder vom Autor befeuert und hält sich als Mythos bis heute in den Köpfen. Niemand kann eine direkte Wirkung auf KI-Suchsysteme nachweisen und niemand unterstützt den Vorschlag offiziell.“
Eoghan Henn (Freier Berater, rebelytics.com) liefert Daten dazu: „Ich war überrascht, als ich Anfang 2026 auf 50 Traffic-starken Domains analysiert habe, ob KI-Crawler gezielt nach einer llms.txt-Datei suchen. Das Ergebnis war wirklich sehr ernüchternd, da kein einziger KI-Crawler auf diesen 50 stark besuchten Domains gezielt nach einer llms.txt-Datei gesucht hat.“
Thomas Peham (CEO, OtterlyAI) bestätigt aus Tool-Anbieter-Perspektive: „Unsere LLMs.txt Datei wird von AI Bots gecrawled, wir sehen aber keine positive Auswirkung auf unsere Sichtbarkeit.“ Johannes Beus differenziert: „Die Nutzung von llms.txt wird aktuell häufig überschätzt. Zwar kann sie ein zusätzliches Signal für AI-Systeme darstellen, ihr tatsächlicher Einfluss auf Zitierung oder Sichtbarkeit in AI-Antworten ist jedoch bislang nicht belegt und stark systemabhängig.“
Johan v. Hülsen (SEO Consultant & Geschäftsführer, Wingmen Online Marketing GmbH) kommentiert trocken: „Von LLMs.txt hab ich keine Wirkung erwartet und konnte keine feststellen.“ Eric Kubitz testet auf seine Art: „Wir haben diese leer implementiert und geschaut, ob sie überhaupt aufgerufen wird.“ Und Udo Raaf (Geschäftsführer, ContentConsultants) urteilt: „Sehe keinen Sinn in Formaten, die anfällig für Spam sind.“
Dem kann ich nichts hinzufügen, mein letzter Artikel hat die llms.txt bereits für tot erklärt:
https://www.afaik.de/die-llms-txt-ist-tot/
4. Prompt-Recherche: Alle machen es, keiner weiß wie
82 Prozent der Befragten betreiben bereits Prompt-Recherche, 50 Prozent sogar regelmäßig. Das klingt nach einer etablierten Praxis — ist es aber nicht. Denn das Kernproblem ist ungelöst: Es gibt kein Äquivalent zum Suchvolumen, und es wird vermutlich nie eines geben.
Marcus Tandler beschreibt den Paradigmenwechsel: „Die größte Herausforderung besteht darin, die deterministische Denkweise zu verlassen. Im klassischen SEO war eine Suchanfrage ein starrer Befehl in Form eines Keywords. Bei Prompts bewegen wir uns hingegen in einem probabilistischen Raum.“
Auch wenn Microsofts Bing Webmaster Tools jetzt separate Daten zur KI-Leistung ausweisen, sehen wir dort nur die Grounding Queries und nicht die von den Nutzern eingegebenen Prompts. Philipp Götza untermauert das quantitativ: „Wir haben keinen vergleichbaren Nachfrage-Proxy wie Suchvolumen. Prompts sind deutlich länger und bis auf wenige Ausnahmen n = 1, daher kann es solche Daten auch nicht geben.“
Alexander Rus (Inhaber & Geschäftsführer, Evergreen Media AR GmbH) geht noch weiter: „Für einen bestimmten Prompt aufzuscheinen zu wollen, ist nicht sinnvoll. Das ist aus meiner Sicht nicht wie das Ganze funktioniert, weil es viel zu viele Variablen gibt.“ Er kritisiert auch die Tool-Landschaft: „Die meisten AI-Tracking Tools von SEOs wurden gebaut und wollen das alles wieder auf Keywords reduzieren, wobei die Transformation von KI-Assistenten ist, dass sie dialogbasiert arbeiten.“
Johan v. Hülsen ergänzt eine oft übersehene Nuance: „Kaum aber wird diskutiert, dass ein Prompt kein einzelnes Ereignis ist. Sondern Teil einer fluiden Diskussion zwischen Mensch und Maschine.“ Stefan Fischerländer (Selbständiger Consultant) stellt sogar die Kategorie „Suche“ grundsätzlich infrage: „Ich halte den Ausdruck ‚Suchanfrage‘ im Zusammenhang mit KI-Chatsystemen für völlig falsch.“ Jens Fauldrath (Geschäftsführender Gesellschafter, get traction GmbH) bleibt bewusst lakonisch: „Hirn und Verstand“ seien die beste Methode — man müsse wissen, „dass das alles nicht sehr belastbar ist“.
Die Methoden sind entsprechend heterogen: Von Kundenbefragungen und Sales-Ticket-Analyse über klassische SEO-Tools als Proxy bis hin zu spezialisierten KI-Monitoring-Tools wie Peec.ai, OtterlyAI und SISTRIX. Götza unterscheidet zudem: „Klassische Suchmaschinen sind deterministisch, KI-Suchsysteme probabilistisch.“ Das verändert die Herangehensweise fundamental.
Ein besonders praxisrelevantes Detail: Mehrere Experten betonen, dass Erwähnung und Zitierung unterschiedliche Optimierungspfade erfordern. Zitierung liegt näher an klassischem SEO, Erwähnung erfordert stärkeres Brand-Building.
Ich stimme dem uneingeschränkt zu und habe im Oktober 25 geschrieben, dass trotz aller Schwächen, die Prompt Extraktion mittels Verbalized Sampling derzeit die beste Möglichkeit ist, so etwas wie repräsentativen Prompts wenigstens nahe zu kommen:
https://www.afaik.de/prompt-research/
5. Was KI-Systeme zitieren: Fakten schlagen Marketing
Die Befragten sind sich erstaunlich einig darüber, was in KI-Antworten erscheint: klare, faktenorientierte, gut strukturierte Inhalte mit echtem Informationsgewinn. Marcus Tandler formuliert es bildhaft: „KI-Antworten filtern den ganzen ‚SEO-Füllstoff‘ gnadenlos raus und krallen sich nur die Essenz.“
Eoghan Henn liefert dafür ein anschauliches Beispiel: „Ich habe in mehreren Fällen beobachtet, dass ein Pressemitteilungs-Boilerplate in einer vergrabenen PDF-Datei öfter zitiert wurde, als die offizielle Über Uns-Seite des Unternehmens.“ Der Grund: PR-Boilerplates sind faktenorientiert und für Journalisten geschrieben, die offenbar einen ähnlichen Informationsbedarf wie KI-Systeme haben.
Florian Stelzner (Geschäftsführender Gesellschafter, Wingmen Online Marketing GmbH) bringt es auf eine Formel: „Die KI zitiert lieber klare Aussagen als schwammige oder lyrisch möglichst ausschweifende Erklärungen.“ Oder kürzer: „Don’t make Systems think.“ Johan v. Hülsen wird konkret: „Kurze klare Sätze mit Belegen. Sätze die nicht in unterschiedliche Richtungen interpretiert werden können und eindeutige Antworten auf Fragen geben.“
Christopher Wagner (AI Architect, ehem. Head of SEO Rheinische Post Mediengruppe) bringt die technische Perspektive ein: „Hohe semantische Dichte und logische Stringenz machen Inhalte besonders zitierfähig. LLMs […] bevorzugen Kausalität und faktische Härte gegenüber narrativen Einleitungs-, Zwischentext- und Fazitweichmachern.“
Überraschend positiv werden FAQ-Abschnitte bewertet: 68 Prozent halten sie für „nützlich“ oder „sehr nützlich“ für die KI-Sichtbarkeit. Das ist bemerkenswert, da FAQs in der klassischen SEO-Community zuletzt eher kritisch gesehen wurden. Alexander Rus erklärt warum: „Sie sind sehr einfach extrahierbar, weil sie für sich allein stehen können.“
Astrid Kramer widerspricht allerdings dem populären Rat, Content gezielt „in Snippet-Form für KI“ zu schreiben: Gute Nutzertexte würden zitiert, künstliche KI-Snippets eher nicht. Das Spannungsfeld zwischen „kurz und prägnant“ und „tiefgehend und kontextreich“ löst sich vermutlich in der Struktur: kurze, extrahierbare Abschnitte innerhalb eines umfassenden Gesamttexts.
Ich halte FAQs grundsätzlich für eine gute Möglichkeit, klare Antworten auf Fragen der Nutzerinnen und Nutzer zu geben, werde das Thema aber im Buch nochmal ausführlicher analysieren.
6. Fast alle (82 Prozent) erwarten weniger organischen Traffic
Die vielleicht beunruhigendste Zahl: 82 Prozent der Experten erwarten eine Abnahme des organischen Traffics durch Google. Das ist die am häufigsten gewählte Option bei der Frage zur Google-Entwicklung — noch vor „Mehr KI-Antworten“ (68 Prozent).
Udo Raaf rät trotzdem zu Gelassenheit: „Auch wenn die Klicks sich im letzten Jahr halbiert haben, rate ich zu stoischer Gelassenheit.“ Die Messproblematik verschärft die Situation: Die Hälfte der Befragten misst KI-Traffic nicht oder nur teilweise. Referrer-Daten sind unvollständig, KI-Systeme übergeben sie uneinheitlich oder gar nicht.
Philipp Götza beschreibt das Dilemma: „Jemand der eine Empfehlung bekommen hat, wird im Tracking, egal wie ich es mache, nicht aufschlagen, da es keinen Klick gab.“ Alexander Rus denkt das weiter: „Ich halte generell nichts davon, an Klicks festzuhalten, wenn wir in eine Richtung gehen, wo KI Menschen berät und die machen dann irgendwas.“ Julian Strote (Geschäftsführer, rankeffect digital GmbH) verschiebt den Fokus: „Konzentriert euch auf die Conversion! SEO ist Mittel zum Zweck und auch GEO wird Mittel zum Zweck werden.“ Und Jens Fauldrath relativiert grundsätzlich: „Sichtbarkeit ist halt nichts, was in sich ein Ziel ist. Ist es im SEO auch nicht.“
Auch hier kann ich nur zustimmen, speziell die Messbarkeit halte ich für ein Riesen-Problem angesichts fehlender Referrer-Informationen und utm-Parametern bei vielen Chatbots, worüber ich im Dezember hier schon berichtet hatte:
https://www.afaik.de/ki-chatbot-traffic-analyse/
7. Earned Media ist der neue Hebel
Der deutlichste neue Trend: Digitale PR und Markenpräsenz jenseits der eigenen Domain werden als zentral bewertet. Über zwei Drittel der Teilnehmer nennen Digitale PR, Brand Mentions und externe Präsenz als wichtigste Ergänzung zu klassischem SEO.
Alexander Rus bringt es auf den kürzesten Nenner: „Werde eine Brand, die man nicht ignorieren kann.“ Michael Weber beschreibt die Verschiebung: „External Reputation statt Linkbuilding. Der Fokus verschiebt sich: Es geht weniger um Backlinks als darum, in externen Quellen genannt und positiv bewertet zu werden. Die KI liest mit — und gewichtet Reputation.“Anja Höbarth (CSO & Head of SEO, SlopeLift PM Media GmbH) bestätigt: „Ganz eindeutig die Digitale PR. Was wo und wie über eine Brand offpage gesagt wird ist wichtiger denn je und geht weit über das, was man bei SEO als Backlink versteht, hinaus.“
Johan v. Hülsen macht es greifbar: „Bisher konnte man mit gutem SEO einen Mangel an Produktqualität und USP teilweise verschleiern. Mit KI-Suchsystemen funktioniert das nicht mehr.“ Julian Strote formuliert es ähnlich: „Es reicht nicht mehr, dass eine Webseite verlinkt wird. Die eigene Marke muss im Kontext relevanter Themen im Web diskutiert werden.“
Ich sehe es ganz ähnlich und habe Kunden sogar schon dazu geraten ein Affiliate-Programm zu starten, damit andere Webseiten, die eine hohe Relevanz als zitierte Quellen besitzen, deren Produkte testen und besprechen. Von einfachem Linkbuilding über gekaufte Links auf Seiten die ohnehin niemand besucht halte ich nach wie vor nichts.
8. Die Fragmentierung: Google vs. ChatGPT vs. der Rest
Ob man für verschiedene KI-Systeme unterschiedlich optimieren muss, ist die am stärksten polarisierte Frage der Umfrage — keine Antwortoption erreicht auch nur 33 Prozent. Die Branche hat hier kein einheitliches Bild.
Johannes Beus beschreibt die Systemunterschiede fundiert: „Die Unterschiede zwischen den AI-Systemen sind erheblich. Google-basierte Systeme orientieren sich in der Bewertung von Quellen stark an etablierten Mechanismen der Google-Websuche. ChatGPT verfügt über diese Such- und Bewertungshistorie in dieser Form nicht.“ Florian Stelzner geht weiter: „Die Unterschiede sind sogar in der selben Systemlandschaft unterschiedlich, je nachdem welches Modell genutzt wird.“
Die Mehrheit empfiehlt dennoch eine generelle Strategie statt systemspezifischer Optimierung. Eric Kubitz hält separate Optimierung sogar für „Unsinn“. Michael Weber sagt: „Die Grundprinzipien sind identisch, nur die Details variieren.“
Ich halte eine unterschiedliche Optimierung, trotz der Unterschiede in den Systemen für wenig sinnvoll. Die Unterschiede ergeben sich aktuell noch aus dem Rückstand der relativ neuen Suchsysteme von Perplexity und ChatGPT und dem Datenvorsprung von Googles vor bing und allen anderen Suchmaschinen. Mittelfristig wird es jedoch, wie im SEO auch, so sein, dass „Was für Googles KI gut ist, ist für die anderen KIs auch gut.“ Zumindest habe ich noch keinen grundsätzlich neuen oder anderen Ansatz gesehen, der etwas anderes erfordern würde.
9. Warnung vor Snake Oil
Der Tenor bei den Praxisratschlägen ist auffällig konservativ. Die Experten warnen geschlossen vor Aktionismus und Hype. Jens Fauldrath ist dabei am deutlichsten: „Aktuell wird sehr viel Snake Oil verkauft. Da will sich eine Branche wohl schnell den Ruf ruinieren.“ Michael Weber vergleicht die aktuelle Situation mit dem „Wildwest der SEO-Anfangsjahre“ und warnt: „Wer sich von selbsternannten Experten und vermeintlichen Patentlösungen wie llm.txt oder Schema-Kosmetik blenden lässt, wiederholt die Fehler der SEO-Frühzeit.“
Christopher Wagner fordert Quellenkritik: „Ich rate dazu, radikal zu hinterfragen: ‚Wer spricht da gerade? Ein Tool-Anbieter mit Verkaufsdruck oder ein erfahrener AI-Architect?’“ Johannes Bornewasser (Consultant & Herausgeber, Teneriffa News) wird knapp: „Hört auf, jeden Test als Geheimtrick zu verkaufen!“ Anke Probst (Head of SEO, 1337 UGC GmbH) wählt eine einprägsame Metapher: „Springt nicht auf jeden vorbeifahrenden Zug auf, hinterfragt erst wohin er fährt, ob ihr die richtige Fahrkarte habt bzw. ob ihr da mit eurem Business überhaupt hin müsst.“
Astrid Kramer empfiehlt einen Perspektivwechsel: „Hört auf, GEO als Optimierungsproblem zu denken — und fangt an, es als Qualitätsaufgabe zu behandeln.“ Stefan Fischerländer fordert ein Umdenken: „Bitte hört auf, die KI-Chatsysteme als Suchsysteme zu betrachten. Menschen möchten nicht suchen, Menschen möchten ihre Probleme lösen.“
Eoghan Henn rät: „Ruhig bleiben, nachdenken, experimentieren und analysieren — anstatt in Aktionismus zu verfallen.“ Udo Raaf hält sich lieber an „seriöse wissenschaftliche Untersuchungen“ als an das, was auf LinkedIn kursiert. Und Florian Stelzner bringt eine ethische Dimension ein: „Ich bin einst angetreten, um das Netz besser zu machen und nicht, um es systematisch vollzuspammen.“
Ich möchte von Udo Raaf gerne mal erfahren, welchen „wissenschaftlichen Untersuchungen“ er hier vertraut, denn ich forsche und promoviere gerade genau in diesem Bereich und so viel gibt es dazu (noch) nicht aus der akademischen Welt. Mich persönlich nerven die ganzen Pseudowissenschaftlichen „Studien“, die irgendwelche Firmen auf Basis proprietärer Daten in intransparenten Prozessen „analysieren“ und die Erkenntnisse daraus als „Die Wahrheit“ verkaufen. Das ist übrigens ein weiterer Grund, wieso ich nach meiner SEO-Abstinenz mich verstärkt wieder diesen Themen widme.
10. Agentic AI: Die nächste Front
Bei Agentic AI zeigt sich die stärkste Spreizung der gesamten Umfrage. Alexander Rus sieht eine fundamentale Verschiebung: „Der Begriff Optimierung in all diesen Zusammenhängen ist zu klein gedacht. Es wird mehr brauchen als Optimierung, nämlich wirkliche Infrastrukturarbeit.“ Christopher Wagner formuliert einen klaren Handlungsauftrag: „Die Beschäftigung mit Agentic AI und der Nutzung des MCP sollte unbedingt auf der Agenda und Roadmap aller Firmen sein, die im KI-Zeitalter bestehen wollen.“
Johan v. Hülsen macht es konkret: „Die KI Agenten mit der mutmaßlich größten Verbreitung dürften mittelfristig agentische Browser sein. Da diese Systeme verstehen müssen, was auf dem Bildschirm passiert, profitieren sie massiv von einer klaren Informationsarchitektur und Accessibility-Optimierung.“
Auf der anderen Seite steht Udo Raaf: „Ich halte das Thema für massiv überschätzt.“ Johannes Beus sieht „noch keinen konkreten Handlungsbedarf“. Anke Probst reagiert mit einem ehrlichen: „Ohgott — gar nicht.“
Philipp Götza beobachtet die Konvergenz: „Browser werden zunehmend agentisch und können Dinge für mich erledigen. Menschen sind bequem. Wir werden trainiert, nicht mehr zu klicken, selbst zu suchen, sondern lassen suchen.“ Oder poetischer: „Suchen klingt anstrengend. Finden klingt einfach. Mit KI suchen wir weniger und finden mehr.“
Ich bin hier selbst noch unentschlossen. Auf der einen Seite sehe ich die Vorteile agentischer Systeme, andererseits ist mir die Zuverlässigkeit aktuell noch viel zu gering, um den Human aus dem Loop zu entfernen.
11. KI wird dominant — aber nicht allein
64 Prozent der Befragten erwarten, dass KI-Suche dominant wird oder die klassische Suche weitgehend ersetzt. Aber 32 Prozent sehen eine parallele Koexistenz. Die Mehrheit rechnet mit einem Szenario, in dem KI für informationelle und beratende Anfragen dominiert, während klassische Suche für navigationale und transaktionale Aufgaben bestehen bleibt.
Nina Baumann (Unternehmerin, Linkspiel) wirft dabei einen kritischen Blick auf die gesellschaftliche Dimension: „Je besser die KI-Suche wird, desto weniger kommt der Nutzer aus der ‚eigenen‘ Bubble raus. Man bekommt gute Antworten aber eben immer aus demselben Denkraum. Ich halte das für enorm gruselig!“
Eric Kubitz warnt vor Scheinsicherheit: „Ich warne davor, den aktuellen Stand als stabil anzusehen. Welche der Annahmen von vor ein oder zwei Jahren sind heute noch korrekt?“ Und Philipp Götza erinnert an das, was in der Optimierungs-Euphorie oft vergessen wird: „Wie wir damit umgehen, dass diese Technologie so teuer ist und unseren Planeten zerstört.“
Das kann ich nur unterstreichen, wobei ich nicht davon ausgehe, dass in 5 Jahren noch irgendeine Suche ohne KI auskommen wird. Das heißt jedoch nicht, dass ein Chat-Interface für alles das Richtige ist!
Fazit: Was ich aus der Umfrage gelernt habe
Die GEO-Expertenbefragung hat mein Verständnis an mehreren Stellen verschoben. Drei Erkenntnisse haben mich besonders geprägt:
Erstens: Die Branche ist nüchterner als ihr Ruf. Hinter dem lauten GEO-Diskurs auf LinkedIn und Konferenzen steht eine Praxis-Community, die experimentiert, abwägt und vor Aktionismus warnt. Das Bild des „GEO-Goldrausches“ hält der empirischen Prüfung nicht stand.
Zweitens: Die Messlücke ist das zentrale ungelöste Problem. Nicht die Optimierung selbst, sondern der Nachweis ihrer Wirkung stellt die Branche vor die größte Herausforderung. Wer KI-Sichtbarkeit nicht messen kann, kann sie auch nicht systematisch steuern.
Drittens: GEO ist keine Revolution, sondern eine Beschleunigung. Was als „GEO-Strategie“ verkauft wird, ist in den meisten Fällen das, was gutes SEO immer hätte sein sollen: klare Inhalte, technische Exzellenz, echte Expertise, starke Marke. Die KI macht nur sichtbar, was vorher schon fehlte. Oder: „Im KI-Zeitalter ist ‚Average Content‘ der neue ‚Duplicate Content‘.“, was Marcus Tandler in seiner Antwort schrieb, aber leider nicht mehr wusste, von wem dieses Zitat stammt.
Mehr dazu im Buch
Die vollständigen Ergebnisse — inklusive der Detailanalysen, der kontroversen Gegenstimmen und der offenen Dissense — fließen in mein Buch „SEO für KI — Auf den Punkt“ ein, das voraussichtlich im Q3 2026 beim O’Reilly Verlag erscheint. Es ist Teil der „Auf den Punkt“-Reihe und behandelt die Verschmelzung von Suchmaschinenoptimierung und Künstlicher Intelligenz — von den technischen Grundlagen über Prompt-Recherche und Content-Strategien bis hin zu Agentic AI.
Mein Dank gilt allen 22 Expertinnen und Experten, die sich die Zeit für diese ausführliche Befragung genommen haben.
Teilnehmer der GEO-Expertenbefragung 2026: Philipp Götza (Wingmen), Anja Höbarth (SlopeLift), Eoghan Henn (rebelytics), Thomas Peham (OtterlyAI), Johannes Bornewasser (Freelancer), Alexander Rus (Evergreen Media), Florian Stelzner (Wingmen), Astrid Kramer (Get Em All Consult), Anke Probst (1337 UGC), Johan v. Hülsen (Wingmen), Julian Strote (rankeffect), Nina Baumann (Linkspiel), Benjamin O’Daniel (Jaeckert & O’Daniel), Jens Fauldrath (get traction), Stefan Fischerländer, Johannes Beus (SISTRIX), Eric Kubitz (Wort & Bild Verlag), Michael Weber (searchVIU), Dr. Beatrice Eiring (eology), Udo Raaf (ContentConsultants), Marcus Tandler (Semrush) und Christopher Wagner.
Wer heute in AI-Visibility-Tracking investiert, sollte vorher die Grundlagenforschung kennen. Eine neue Studie von Rand Fishkin (SparkToro) und Patrick O’Donnell (Gumshoe.ai) liefert erstmals belastbare Daten zur Konsistenz von Markenempfehlungen in ChatGPT, Claude und Google AI. Die Ergebnisse sind ernüchternd — und gleichzeitig aufschlussreich.
Die zentrale Frage der SparkToro-Studie: Wie konsistent sind KI-Markenempfehlungen bei wiederholter Abfrage? (Quelle: SparkToro / Gumshoe.ai)
Das Experiment
600 Freiwillige gaben 12 identische Prompts jeweils 60–100 Mal in die drei meistgenutzten KI-Tools ein: ChatGPT, Claude und Google Search AI (Overviews bzw. AI Mode). Insgesamt wurden 2.961 Antworten erfasst, normalisiert und statistisch ausgewertet. Die Prompts deckten verschiedene Branchen und Kategoriengrößen ab — von Kochmessern über Kopfhörer bis hin zu Krebskliniken und Digital-Marketing-Beratungen.
Die methodische Grundlage bildete die Carnegie-Mellon-Studie „Estimating LLM Consistency“, deren Pairwise-Correlation-Metriken für die Analyse übernommen wurden. Die Rohdaten sind öffentlich verfügbar.
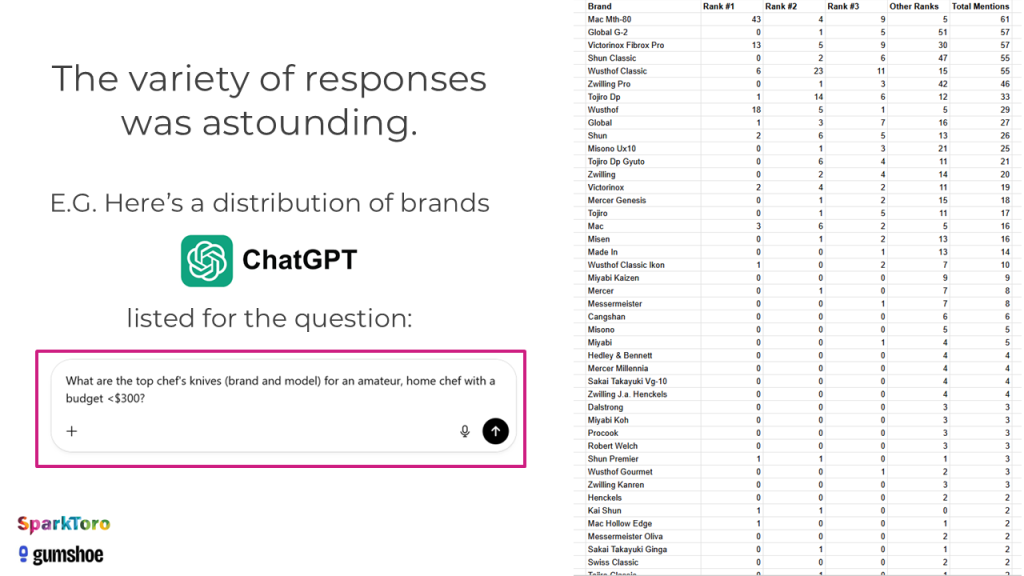
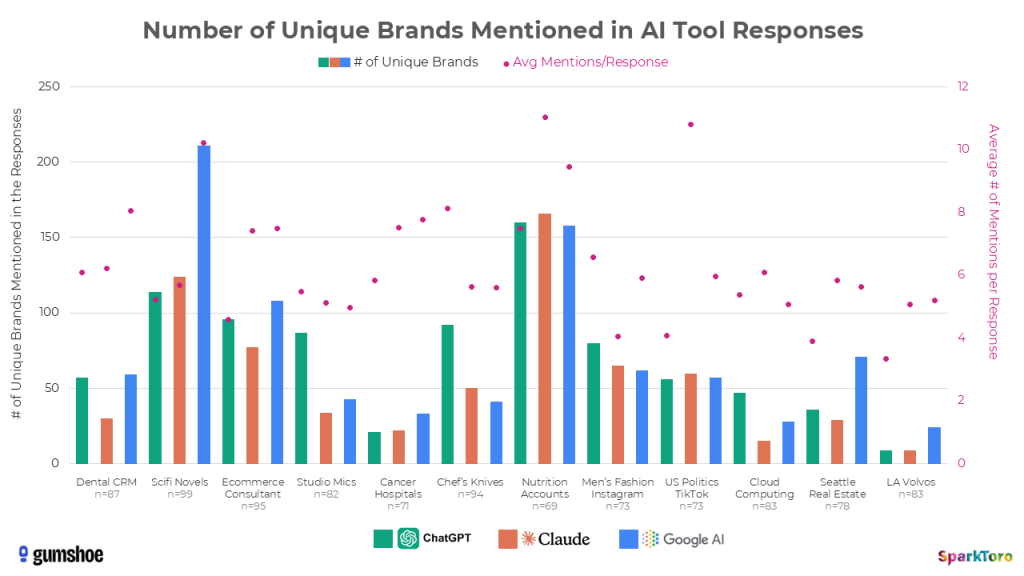
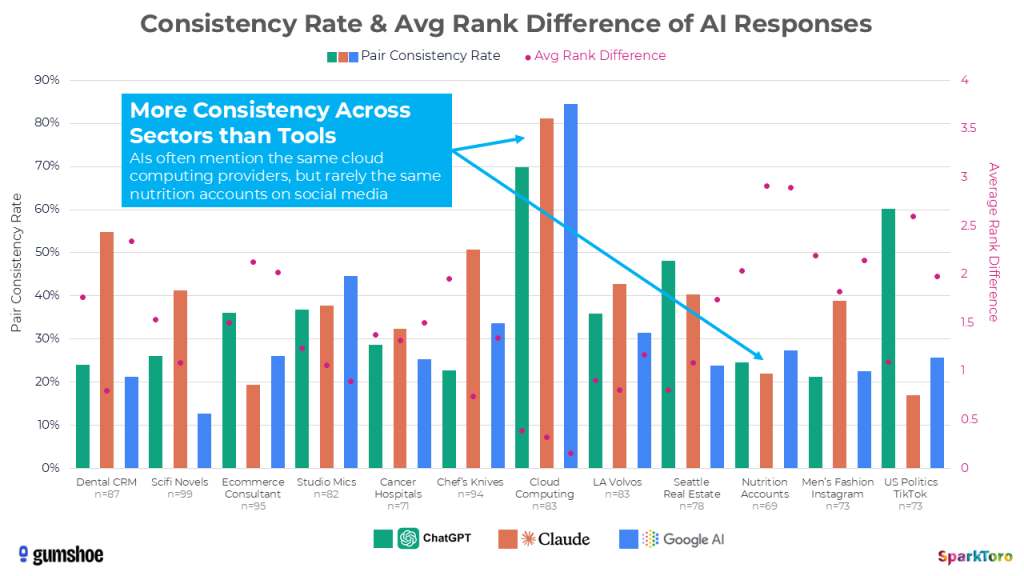
Allein bei der Frage nach Kochmessern für Hobbyköche produzierte ChatGPT eine erstaunliche Vielfalt an Marken und Modellen — mit teils über 40 verschiedenen Empfehlungen in der Gesamtauswertung:
Die Vielfalt der ChatGPT-Antworten auf eine einzige Kochmesser-Frage: Über 40 verschiedene Marken und Modelle bei wiederholter Abfrage (Quelle: SparkToro / Gumshoe.ai)
Die Kernbefunde
Nahezu jede Antwort ist ein Unikat. Stellt man einem KI-Tool hundertmal dieselbe Frage nach Markenempfehlungen, unterscheiden sich die Antworten in drei Dimensionen: welche Marken genannt werden, in welcher Reihenfolge sie erscheinen und wie viele Empfehlungen die Liste überhaupt enthält.
Die folgende Grafik zeigt, wie viele einzigartige Marken die drei KI-Tools über alle 12 Prompt-Kategorien hinweg nannten. In breiten Kategorien wie Science-Fiction-Romanen oder Nutrition Accounts auf Social Media explodierten die Zahlen — in engen Märkten wie LA-Volvo-Händlern blieben sie überschaubar:
Anzahl einzigartiger Marken pro Kategorie und KI-Tool — je breiter die Kategorie, desto größer die Streuung (Quelle: SparkToro / Gumshoe.ai)
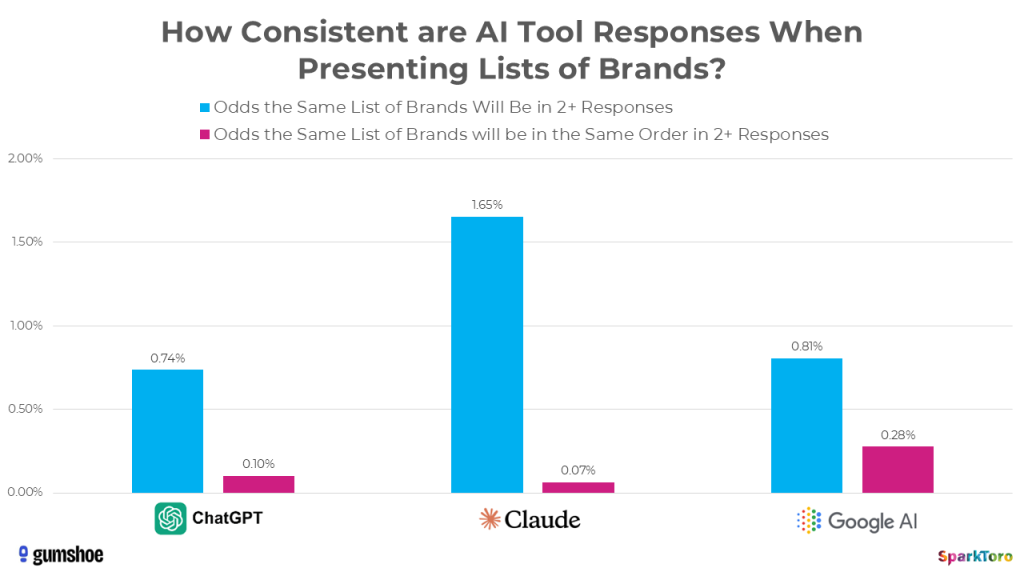
Listenidentität unter 1 %. Die Wahrscheinlichkeit, dass ChatGPT oder Google AI bei zwei beliebigen Durchläufen dieselbe Markenliste zurückgibt, liegt unter 1:100. Claude produziert minimal häufiger identische Listen (1,65 %), variiert dafür die Reihenfolge noch stärker (0,07 % Übereinstimmung):
Unter 1 % Chance auf identische Listen — und nahe null für identische Reihenfolge. Ranking-Positionen in KI-Antworten sind statistisch bedeutungslos. (Quelle: SparkToro / Gumshoe.ai)
Reihenfolge praktisch zufällig. Dieselbe Reihenfolge zweimal zu erhalten, hat eine Wahrscheinlichkeit von etwa 1:1.000. Wer also „Ranking-Positionen in KI“ trackt, misst statistisches Rauschen.
Listenlänge variiert unkontrolliert. Manche Antworten enthalten zwei bis drei Empfehlungen, andere zehn oder mehr — bei identischem Prompt.
Aber: Visibility-Prozente haben Substanz
Fishkins Ausgangshypothese war, dass AI-Tracking grundsätzlich nutzlos sei. Diese Hypothese wurde teilweise widerlegt. Denn obwohl Listen, Reihenfolge und Umfang massiv schwanken, zeigt sich über viele Durchläufe hinweg ein stabiles Muster: Bestimmte Marken tauchen konsistent häufiger auf als andere.
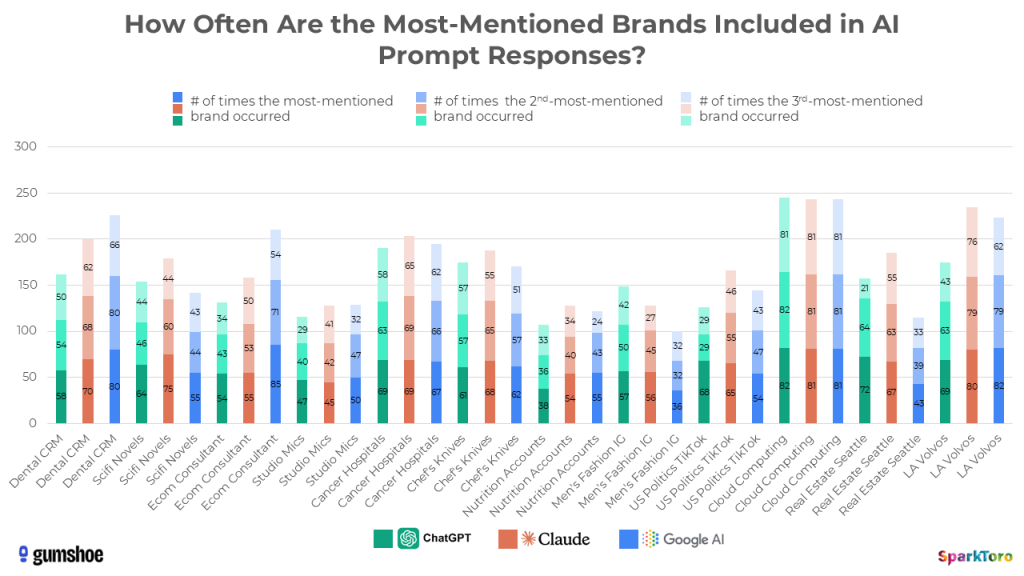
Die folgende Grafik zeigt für alle 12 Kategorien und drei KI-Tools, wie oft die jeweils am häufigsten, zweithäufigsten und dritthäufigsten genannten Marken in den Antworten auftauchten:
Trotz zufälliger Listen und Reihenfolgen: Die meistgenannten Marken erscheinen über Dutzende Durchläufe hinweg konsistent häufiger als andere (Quelle: SparkToro / Gumshoe.ai)
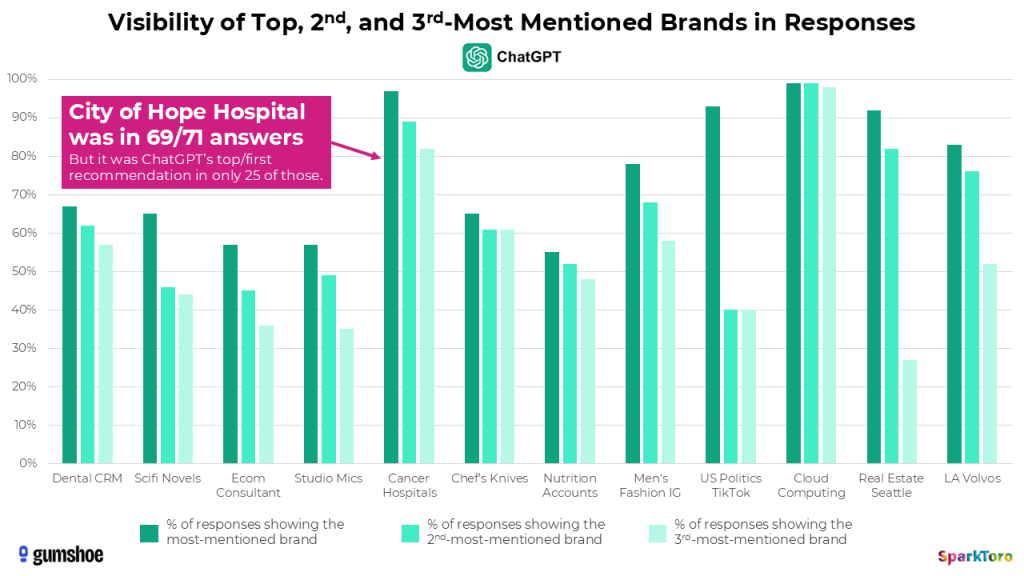
Beispiel: Bei der Frage nach Digital-Marketing-Beratungen mit E-Commerce-Expertise erschien die Agentur Smartsites in 85 von 95 Google-AI-Antworten. City of Hope tauchte bei der Frage nach den besten Krebskliniken an der US-Westküste in 69 von 71 ChatGPT-Antworten auf — eine Sichtbarkeit von 97 %. Aber: Nur in 25 dieser 71 Antworten war City of Hope auch die erstgenannte Empfehlung.
97 % Sichtbarkeit, aber nur in einem Drittel der Fälle erstgenannt: Die Position innerhalb einer Antwort ist Zufall — die Häufigkeit der Nennung nicht (Quelle: SparkToro / Gumshoe.ai)
Die entscheidende Erkenntnis: Nicht die Position in einer einzelnen Antwort ist aussagekräftig, sondern die Häufigkeit des Erscheinens über viele Durchläufe hinweg. Visibility-Prozent — also der Anteil an Antworten, in denen eine Marke überhaupt genannt wird — scheint eine statistisch belastbare Metrik zu sein.
Kategoriegröße bestimmt Varianz
Die Studie zeigt einen klaren Zusammenhang zwischen der Breite einer Kategorie und der Streuung der Ergebnisse. Die Konsistenz variiert stärker zwischen Branchen als zwischen KI-Tools — ein zentraler Befund:
Entscheidender als das Tool ist die Marktbreite: Cloud Computing zeigt 70–85 % Konsistenz, fragmentierte Kategorien fallen auf unter 15 % (Quelle: SparkToro / Gumshoe.ai)
In engen Märkten mit wenigen relevanten Anbietern — etwa Cloud-Computing-Anbieter für SaaS-Startups — liegt die Pairwise-Konsistenzrate bei 70–85 %. In breiten Kategorien wie Science-Fiction-Romanen oder Branding-Agenturen fällt sie auf unter 15 %. Die KI hat schlicht mehr Optionen zur Auswahl, was die Streuung erhöht. Für GEO bedeutet das: Je fragmentierter der Markt, desto schwieriger ist es, konsistente Sichtbarkeit zu erreichen — und desto wichtiger wird eine systematische Strategie.
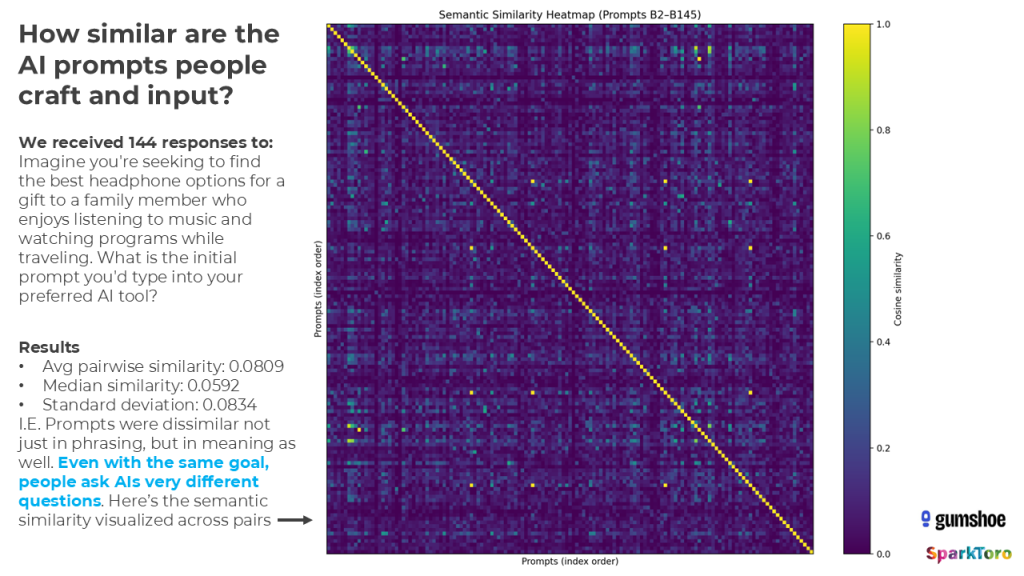
Das Prompt-Problem
Ein zweiter Teil der Studie untersuchte, wie echte Menschen Prompts formulieren. 142 Teilnehmer schrieben Prompts mit derselben Intention (Kopfhörer-Empfehlung für ein reisendes Familienmitglied). Die semantische Ähnlichkeit zwischen den Prompts lag bei 0,081 — extrem niedrig. Die Heatmap visualisiert diese Dissimilarität eindrücklich:
142 Menschen, eine Intention, nahezu null Übereinstimmung in der Formulierung: Die Heatmap zeigt, wie unterschiedlich reale Nutzer ihre KI-Prompts schreiben (Quelle: SparkToro / Gumshoe.ai)
Trotzdem: Die KI-Tools erkannten die zugrunde liegende Intention zuverlässig und lieferten über 994 Antworten hinweg ein konsistentes Set an Top-Marken. Gumshoe ließ alle 142 einzigartigen Prompts durch ihr System laufen — das Ergebnis bestätigte die Befunde der kontrollierten Studie:
Intent überlebt Prompt-Varianz: Trotz radikal unterschiedlicher Formulierungen erkennen KI-Tools die Absicht und liefern ein stabiles Marken-Set — Sony 87 %, Bose 77 %, Sennheiser 58 % (Quelle: SparkToro / Gumshoe.ai)
Intent überlebt Prompt-Varianz. Die Tools sind besser im Erkennen der Absicht als im konsistenten Formatieren der Antwort.
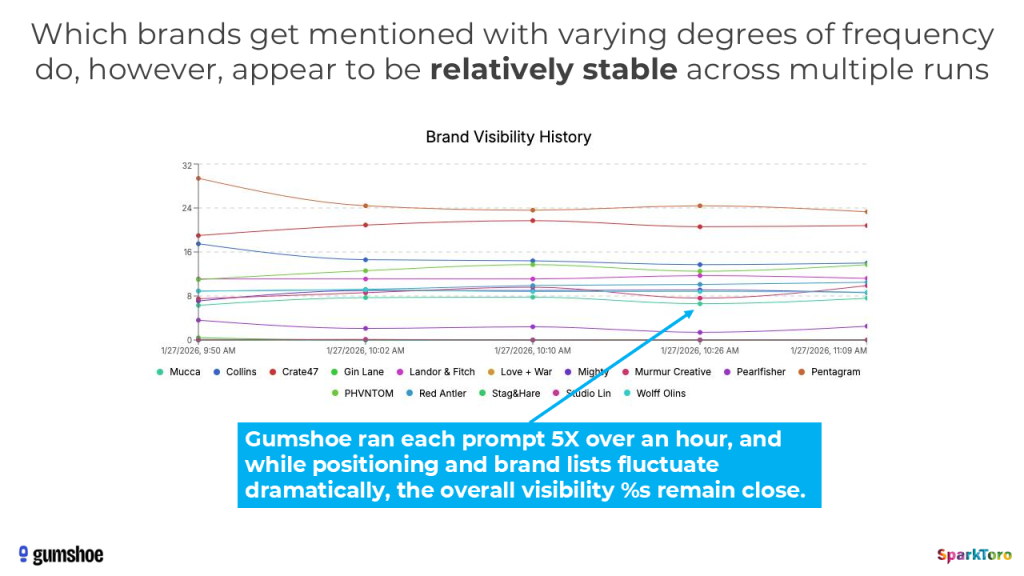
Auch über die Zeit hinweg bleiben die Visibility-Prozente relativ stabil, selbst wenn die konkreten Listen und Positionen sich bei jedem Durchlauf ändern:
Positionen schwanken, Proportionen bleiben: Die Visibility-Prozente einzelner Marken sind über mehrere Durchläufe hinweg relativ stabil (Quelle: SparkToro / Gumshoe.ai)
Was das für GEO-Strategien bedeutet
1. Ranking-Position in KI-Antworten ist bedeutungslos. Jedes Tool oder jeder Anbieter, der „Platz 1 bei ChatGPT“ als Metrik verkauft, verkauft statistische Artefakte. Die einzig sinnvolle Metrik ist die prozentuale Sichtbarkeit über viele Durchläufe.
2. Visibility-Tracking braucht Volumen. Einzelne Stichproben sind wertlos. Fishkin empfiehlt mindestens 60–100 Durchläufe pro Prompt, um belastbare Daten zu erhalten. Anbieter von AI-Tracking-Tools sollten ihre Methodik offenlegen und statistisch validieren.
3. Intent-Orientierung schlägt Keyword-Optimierung. Weil Nutzer ihre Prompts radikal unterschiedlich formulieren, die KI-Tools aber die Intention zuverlässig erkennen, muss GEO auf Intent-Cluster statt auf einzelne Formulierungen optimieren.
4. Marktbreite ist ein strategischer Faktor. In Nischen mit wenigen Anbietern reicht konsistente Präsenz in den relevanten Quellen. In fragmentierten Märkten braucht es eine breitere Strategie mit mehr Touchpoints im Trainingscorpus der Modelle.
5. Anbieter-Transparenz einfordern. Bevor Budget in AI-Tracking fließt, sollten Unternehmen folgende Fragen stellen: Wie oft wird jeder Prompt ausgeführt? Wird die Methodik öffentlich dokumentiert? Wie wird mit der dokumentierten Varianz umgegangen? Werden Ranking-Positionen berichtet (die laut Forschung bedeutungslos sind)?
Einordnung und offene Fragen
Die SparkToro-Studie ist die erste öffentliche Untersuchung dieser Art — und sie ist methodisch transparent. Fishkin und O’Donnell veröffentlichen Rohdaten, Prompts und Methodik. Gleichzeitig bleiben Fragen offen:
API vs. Web-Interface: Erste Hinweise deuten darauf hin, dass API-Antworten sich von Interface-Antworten unterscheiden könnten. Das ist relevant, weil die meisten Tracking-Tools über APIs arbeiten.
Zeitliche Stabilität: Die Daten stammen aus November/Dezember 2025. Ob Visibility-Werte über Monate hinweg stabil bleiben, ist ungeklärt.
Stichprobengröße: Für eine vollwertige statistische Absicherung wären deutlich größere Samples nötig.
Modell-Updates: Wie sich Modell-Aktualisierungen auf die Visibility einzelner Marken auswirken, wurde nicht untersucht.
Ausblick: Weitere Forschung in Vorbereitung
Die SparkToro-Studie ist ein wichtiger erster Schritt — aber sie kratzt erst an der Oberfläche. In unserer Research Group an der RPTU Kaiserslautern-Landau bereitet aktuell ein Doktorand eine groß angelegte wissenschaftliche Studie vor, die genau diese Fragestellungen systematisch untersucht. Denn neben den von Fishkin und O’Donnell betrachteten Variablen gibt es weitere Faktoren, die die Konsistenz und Zusammensetzung von KI-Empfehlungen beeinflussen und bislang nicht erfasst wurden.
Ohne zu viel vorwegzunehmen: Wir setzen an mehreren Stellen an, an denen die SparkToro-Studie designbedingt Grenzen hat. Das Panel aus menschlichen Freiwilligen war für eine explorative Studie sinnvoll, limitiert aber Reproduzierbarkeit und Skalierung. Unsere Studie wird auf technisch automatisierten Testläufen basieren, mit deutlich höheren Stichprobengrößen und einer breiteren Abdeckung an Plattformen über die drei US-Marktführer hinaus. Zudem planen wir eine Anbindung an den existierenden akademischen Forschungsstand — etwa durch den Rückgriff auf etablierte Prompt-Kataloge aus Benchmarks wie GEO-Bench —, um die Ergebnisse in den wissenschaftlichen Diskurs einordnen zu können.
Ich werde hier in den kommenden Monaten deutlich mehr in diese Richtung berichten.
Fazit
Die Studie bestätigt, was viele im GEO-Umfeld intuitiv vermutet haben: KI-Empfehlungen sind probabilistisch, nicht deterministisch. Rankings in KI-Antworten sind Zufall. Aber die Häufigkeit, mit der eine Marke im Consideration Set der Modelle auftaucht, ist messbar und strategisch relevant.
Für Unternehmen bedeutet das: Nicht die Position in einer einzelnen Antwort entscheidet, sondern die systematische Präsenz in den Datenquellen, aus denen KI-Modelle ihre Empfehlungen generieren. Genau das ist der Kern von Generative Engine Optimization.
Quelle: Fishkin, R. & O’Donnell, P. (2026). „NEW Research: AIs are highly inconsistent when recommending brands or products.“ SparkToro Blog, 27. Januar 2026. sparktoro.com
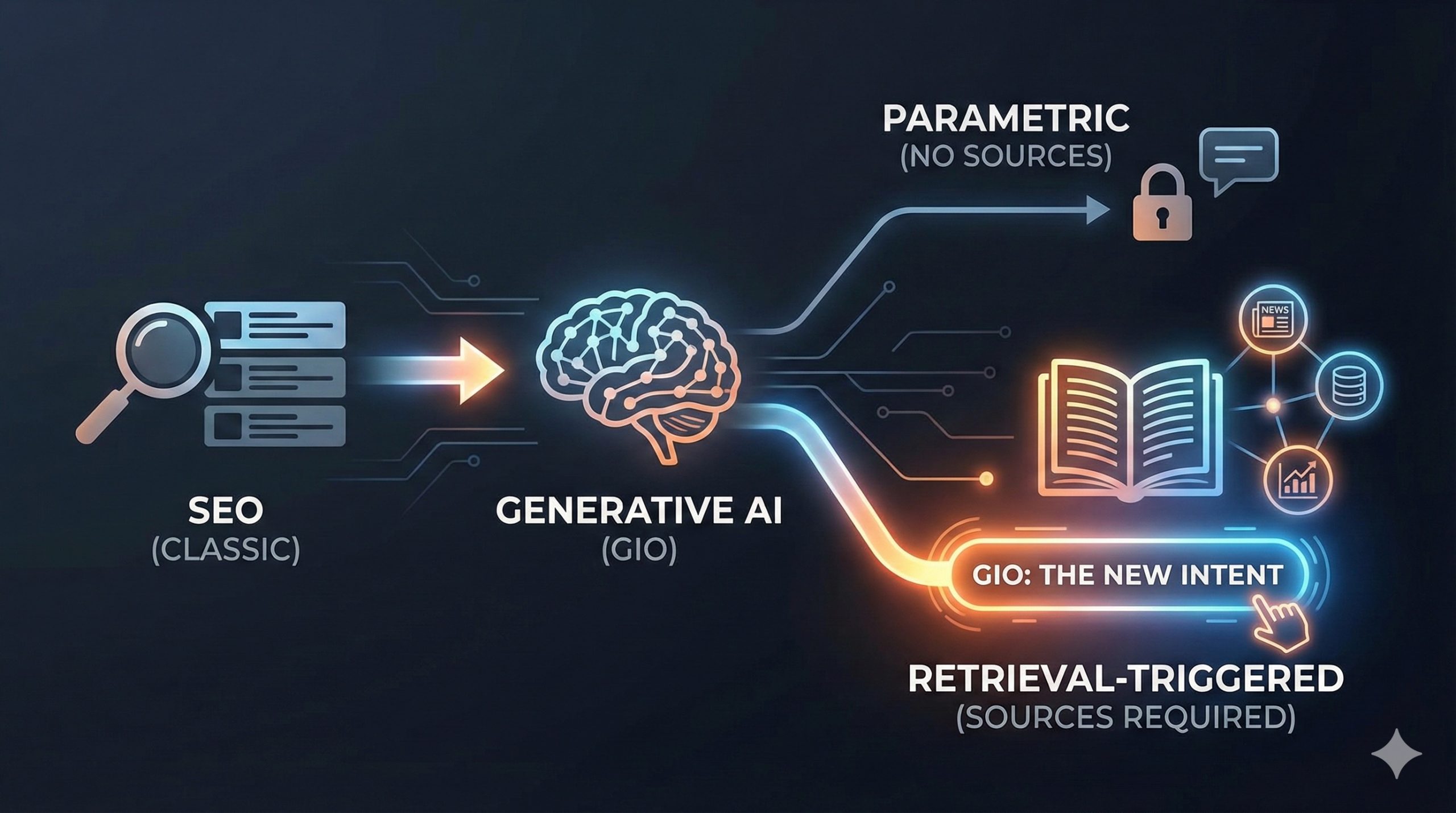
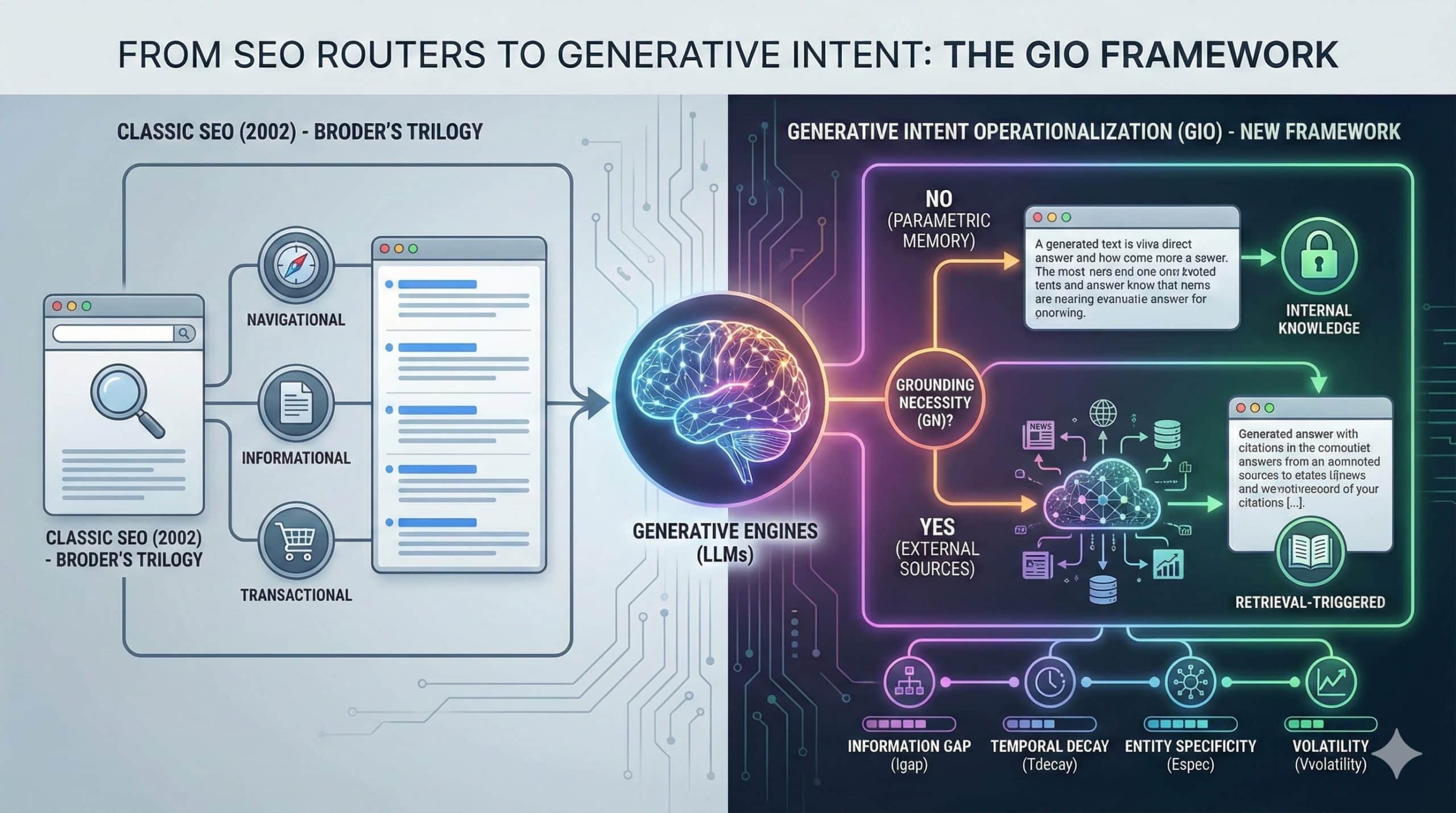
Wer in der SEO-Welt sozialisiert wurde, kennt Broders Dreiteilung aus dem Jahr 2002: Navigational, Informational, Transactional. Drei Kategorien, die zwei Jahrzehnte lang als Goldstandard galten. Doch seit Large Language Models nicht mehr nur Links ranken, sondern Antworten generieren, reicht dieses Modell nicht mehr aus. Die zentrale Frage hat sich verschoben: Nicht mehr „Welche Seite passt zur Suchanfrage?“, sondern „Wird die Engine überhaupt externe Quellen heranziehen, um diese Antwort zu erzeugen?“
Genau an dieser Stelle arbeite ich gerade an einem akademischen Framework: der Generative Intent Operationalization (GIO). Und während ich das Paper schreibe, liefern OpenAI und Microsoft unabhängig voneinander empirische Daten und Systemsignale, die zeigen, wie drängend die Frage nach einer neuen Intent-Taxonomie geworden ist. Dieser Beitrag ordnet diese Entwicklungen ein.
Warum es ein neues Framework braucht
Klassische Intent-Modelle wurden für Suchmaschinen gebaut, die als deterministische Router funktionieren: Der Nutzer gibt eine Anfrage ein, das System liefert eine Ergebnisliste, der Nutzer klickt. Das Retrieval war implizit — jede Suchanfrage löste eine Suche aus.
Generative Engines funktionieren fundamental anders. Sie sind probabilistische Antwortmaschinen, die entscheiden müssen, ob sie externe Quellen brauchen. Ein GPT-Modell kann „Wie binde ich eine Krawatte?“ komplett aus dem parametrischen Gedächtnis beantworten. Aber „Welche Förderungen gibt es 2026 für Wärmepumpen in Baden-Württemberg?“ erfordert zwingend aktuelle externe Daten. Diese Unterscheidung – parametrisch lösbar vs. grounding-abhängig – existiert in keinem klassischen Modell.
Für GEO-Strategen ist das der entscheidende Hebel: Nur wenn die Engine retrieval-getriggert arbeitet, besteht überhaupt die Möglichkeit, als Quelle zitiert zu werden. Content, der auf rein parametrische Anfragen optimiert wird, ist verschwendete Energie.
GIO formalisiert genau diesen Hebel. Das Framework klassifiziert Nutzer-Intents vor der Antwortgenerierung anhand der Grounding Necessity (GN) – der epistemischen Notwendigkeit, externe Evidenz heranzuziehen. GN wird dabei über vier Dimensionen operationalisiert: Information Gap (Igap), Temporal Decay (Tdecay), Entity Specificity (Espec) und Volatility (Vvolatility). Das Ergebnis ist eine Klassifizierungsmatrix, die direkt in GEO-Strategien übersetzt werden kann.
Was OpenAI über die eigene Nutzung weiß: Die NBER-Studie
Im September 2025 veröffentlichten Chatterji et al. unter dem Titel „How People Use ChatGPT“ (NBER Working Paper 34255) die bisher umfassendste Analyse von ChatGPT-Nutzungsdaten. Die Studie klassifizierte über eine Million Konversationen anhand von fünf Taxonomien:
1. Work/Non-Work (binär): 73% aller Nachrichten im Juni 2025 waren nicht arbeitsbezogen. Für GEO-Zwecke ist diese Dimension irrelevant – Grounding Necessity ist unabhängig davon, ob jemand beruflich oder privat fragt.
2. Conversation Topic (24 Kategorien, 7 Gruppen): Die drei dominanten Gruppen sind Practical Guidance (~29%), Seeking Information (~24%) und Writing (~24%). Hier liegt das erste Problem für GEO-Strategen: „Writing“ umfasst sowohl „Schreib mir ein Anschreiben“ (rein parametrisch, kein Retrieval nötig) als auch „Fasse den aktuellen EZB-Zinsentscheid zusammen“ (zwingend grounding-abhängig). Die Kategorie ist aus Grounding-Perspektive blind.
3. Asking/Doing/Expressing (ternär): Die analytisch interessanteste Dimension. „Asking“ (49%) beschreibt Informations- und Beratungssuche, „Doing“ (40%) die Auftragserteilung an das Modell, „Expressing“ (11%) den Ausdruck von Gefühlen oder Meinungen ohne Handlungserwartung. Für eine GIO-Pipeline könnte diese Dreiteilung als Vorfilter dienen: „Expressing“ und rein kreatives „Doing“ (Fiktion, Rollenspiel) haben praktisch null GEO-Relevanz und können vor der aufwändigeren GN-Analyse ausgeschlossen werden. Aber: Eine „Asking“-Frage nach der Höhe des Eiffelturms hat null Retrieval-Bedarf, während eine „Doing“-Anfrage zur Zusammenfassung einer neuen Gesetzgebung maximalen Bedarf hat. Der Vorfilter spart Rechenkosten, ersetzt aber nicht die epistemische Analyse.
4. O*NET Work Activities: Eine arbeitsmarktsoziologische Zuordnung zu 332 Intermediate Work Activities. Für GEO irrelevant.
5. Interaction Quality: Post-Generation-Analyse der Nutzerzufriedenheit. Per Definition nicht pre-generation-fähig.
Das Fazit: Die Chatterji-Studie beantwortet die Frage „Was tun Nutzer mit ChatGPT?“ – deskriptiv, soziologisch, auf aggregierter Ebene. Mein GIO-Framework beantwortet eine orthogonale Frage: „Wird die Engine für diesen spezifischen Prompt externe Quellen heranziehen?“Die beiden Ansätze sind komplementär, aber nicht substituierbar.
Was Microsoft intern verwendet: Die Bing AI Performance-Klassifizierung
Parallel zur akademischen Debatte gibt es Signale aus der Industrie, die zeigen, dass die großen Anbieter intern längst eigene Intent-Taxonomien für ihre generativen Systeme operationalisieren.
Im Client-Side-Quellcode der Bing Webmaster Tools AI Performance (Beta) finden sich Hinweise auf eine 13-stufige Intent-Klassifizierung, die Microsoft offenbar für die Zuordnung von Citations in Copilot/Bing AI verwendet:
Navigational
Learning and Problem Solving
Creation
Entertainment
Shopping or Transaction
Small Talk
Informational Search
Utility
Multimedia Search
Research
Planning
Comparison
Others
Diese Taxonomie ist bemerkenswert, weil sie mehrere Dinge gleichzeitig zeigt.
Erstens: Microsoft unterscheidet zwischen „Informational Search“ und „Research“ – eine Trennung, die implizit verschiedene Grounding-Tiefen abbildet. Eine einfache Faktenabfrage (Informational Search) kann oft parametrisch beantwortet werden; eine Recherche (Research) erfordert typischerweise Multi-Source-Synthese mit hoher Grounding Necessity.
Zweitens: Kategorien wie „Small Talk“ und „Entertainment“ sind aus GEO-Perspektive Nullwert-Kategorien – analog zu GIOs Einordnung als „Low GN“. Die Engine wird für Smalltalk keine externen Quellen zitieren. Wer Content für diese Kategorien optimiert, optimiert ins Leere.
Drittens: „Comparison“ als eigene Kategorie ist strategisch aufschlussreich. Vergleichsanfragen erfordern fast immer aktuelle, multi-attributive Daten aus mehreren Quellen – ein klassischer High-GN-Fall, der in GIO als Mode 1.2 (Real-Time Synthesis) mit hoher Komplexität eingeordnet würde.
Viertens: „Creation“ dürfte das gleiche Ambiguitätsproblem haben wie Chatterjis „Writing“ – es mischt parametrische Generierung („Schreib ein Gedicht“) mit grounding-abhängiger Produktion („Erstelle eine Marktanalyse zum deutschen E-Auto-Markt 2026“).
Die Quelle: RESENEOs Reverse-Engineering-Arbeit
Für die Hinweise auf Microsofts interne Klassifizierung und weit darüber hinaus gebührt Olivier de Segonzac, Gründer der Pariser Agentur RESONEO, besondere Anerkennung. RESONEO leistet derzeit echte Pionierarbeit im Bereich GEO-Reverse-Engineering und liefert damit empirische Grundlagen, die der akademischen Forschung oft fehlen.
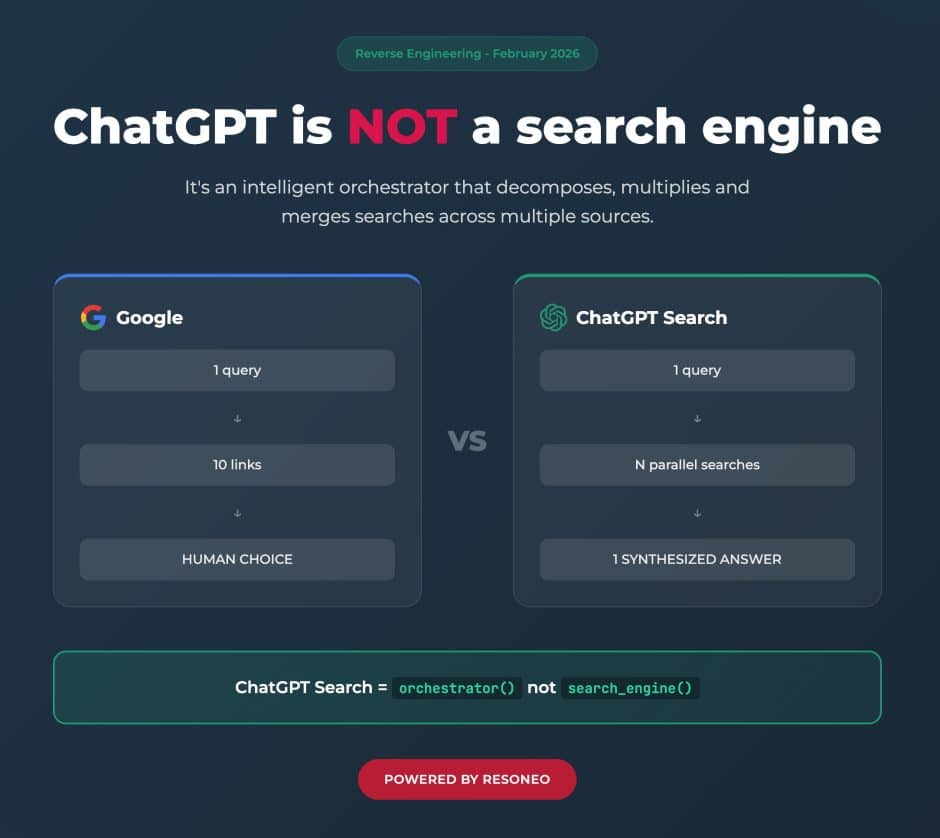
Eine technische Analyse von Googles AI Overviews und AI Mode, die eine vierstufige Citation-Pipeline offenlegt (Information Retrieval, Grounding URLs, Pool, Displayed). Besonders relevant: RESONEO identifizierte Hidden Grounding URLs – Quellen, die das Modell zur Generierung heranzieht, aber dem Nutzer nie anzeigt. Diese Entdeckung hat direkte Implikationen für jede GEO-Strategie, weil sie zeigt, dass bisherige Sichtbarkeitsstudien die tatsächliche Retrieval-Nutzung systematisch unterschätzten. Ebenfalls aufgedeckt: AI Mode zerlegt Nutzeranfragen in 8-12 parallele Sub-Queries (bei Deep Search Hunderte), während AI Overviews kaum Sub-Query-Dekomposition betreiben – ein fundamentaler architektonischer Unterschied.
Eine Analyse des ChatGPT-Suchsystems, die unter anderem den Sonic Classifier identifizierte — einen probabilistischen Entscheider, der vor der Antwortgenerierung über einen search_prob-Score (Schwellenwert ~65%) bestimmt, ob externe Daten benötigt werden. Das ist exakt der Mechanismus, den GIO theoretisch modelliert: eine Pre-Generation-Entscheidung über Grounding Necessity. RESONEO dokumentierte außerdem das Fan-Out-System (1-3 Standard-Queries, 20+ im Thinking Mode) und die Abhängigkeit von Drittanbieter-Scrapern statt eigener Suchindizes.
Was alle drei Ansätze gemeinsam zeigen — und wo sie sich unterscheiden
Die Konvergenz ist bemerkenswert: OpenAI klassifiziert post-hoc, was Nutzer tun. Microsoft klassifiziert in Echtzeit, wie Citations zugeordnet werden. GIO klassifiziert pre-generation, ob Retrieval überhaupt nötig ist. Drei verschiedene Fragen, drei verschiedene Operationalisierungen — aber alle kreisen um denselben Kern: Die alte Dreiteilung Navigational/Informational/Transactional reicht für generative Systeme nicht mehr aus.
Die Unterschiede sind dabei ebenso aufschlussreich:
Granularität vs. Operationalisierbarkeit: Chatterjis 24 Kategorien und Microsofts 13 Klassen bieten deskriptive Breite, aber keine direkte Handlungsanweisung für Content-Strategen. GIO ist bewusst schmaler angelegt, weil jede Klasse direkt in eine GEO-Strategie mündet.
Post-hoc vs. Pre-Generation: Chatterjis Taxonomie wurde auf historische Konversationslogs angewendet. Microsofts Klassifizierung scheint in Echtzeit zu operieren (sie steuert die Citation-Zuordnung). GIO ist konzeptionell pre-generation: Es soll die Grounding-Entscheidung vorhersagen, bevor das Modell antwortet — und damit dem Content-Strategen ermöglichen, proaktiv zu optimieren.
Deskriptiv vs. Prädiktiv: OpenAI und Microsoft beschreiben, was passiert. GIO will vorhersagen, was passieren wird — und daraus ableiten, was Content-Produzenten tun sollten.
Was das für die GEO-Praxis bedeutet
Für SEO-Professionals, die sich Richtung GEO bewegen, ergeben sich aus dieser Dreiecksbetrachtung konkrete Implikationen:
Erstens, die Chatterji-Daten zeigen, dass knapp die Hälfte aller ChatGPT-Nachrichten „Asking“-Queries sind – also Informations- und Beratungssuche. Das ist der primäre Raum, in dem GEO-Strategien greifen können. Die 11% „Expressing“ und ein substanzieller Teil der 40% „Doing“ (kreative Textproduktion, Rollenspiel) sind für Content-Publisher strategisch irrelevant.
Zweitens, Microsofts Trennung von „Informational Search“ und „Research“ als separaten Kategorien bestätigt, dass die Engine selbst zwischen unterschiedlichen Grounding-Tiefen differenziert. Wer Content produziert, sollte sich fragen: Ist das eine Faktenabfrage, die das Modell aus dem Kopf beantworten kann? Oder eine Recherchefrage, für die es zwingend aktuelle, strukturierte externe Daten braucht? Nur im zweiten Fall lohnt sich die GEO-Investition.
Drittens, RESENEOs Identifikation des Sonic Classifiers und der Hidden Grounding URLs zeigt: Die Mechanismen, die GIO theoretisch modelliert, existieren in der Praxis bereits als harte architektonische Entscheidungen. Die Frage „Wird die Engine retrieval-triggern?“ ist keine akademische Abstraktion, sondern ein messbarer Schwellenwert in produktiven Systemen.
Das GIO-Paper befindet sich derzeit in der Finalisierung. Es wird als Position Paper die theoretische Grundlage legen und einen empirischen Validierungsplan vorschlagen. Die hier diskutierten Industrie-Signale fließen bewusst nicht in das akademische Paper ein – dafür sind sie zu flüchtig und zu wenig dokumentiert. Aber sie bestätigen die zentrale These: Wer Generative Engine Optimization ernst nimmt, braucht ein Framework, das vor der Generierung ansetzt. Nicht bei dem, was Nutzer tun. Sondern bei dem, was die Engine tun wird.
Warum Du sofort aufhören solltest, llms.txt-Dateien zu erstellen — und was stattdessen zu tun ist.
Ich muss Dir etwas sagen, das Du nicht hören willst: Die llms.txt, die ihr letzte Woche mit großem Aufwand erstellt hast, wird von keinem einzigen relevanten KI-Suchsystem gelesen. Von keinem. Nicht von Google. Nicht von ChatGPT. Nicht von Perplexity. Nicht von Claude.
Das ist keine Meinung. Das sind Logfiles.
0,1 Prozent
OtterlyAI hat 90 Tage lang gemessen, was passiert, wenn man eine korrekt implementierte llms.txt bereitstellt. Das Ergebnis: Von 62.100 KI-Bot-Requests gingen genau 84 an die llms.txt. Das sind 0,1 Prozent. Die Datei performte dreimal schlechter als eine durchschnittliche Content-Seite auf derselben Domain. Sie lag auf dem Niveau eines vergessenen PDFs im /assets-Ordner.
Wer 20.000 Domains hostet, berichtet dasselbe: Kein einziger relevanter KI-Agent fordert die Datei an. Der einzige Bot, der sie crawlt, ist BuiltWith — ein Technologie-Erkennungsdienst, der schlicht katalogisiert, welche Dateien existieren. Das ist kein Nutzungssignal. Das ist ein Inventurzettel.
Was Google dazu sagt — und was Google damit tut
Google hat die klarste Position aller Anbieter. John Mueller schrieb auf Bluesky:
„FWIW no AI system currently uses llms.txt.“
Er verglich die Datei explizit mit dem Keywords-Meta-Tag — jenem Tag, das Suchmaschinen seit über einem Jahrzehnt ignorieren, weil es vom Seitenbetreiber kontrolliert wird und daher für Manipulationen anfällig ist. Gary Illyes bestätigte auf der Google Search Central Live: Google unterstützt llms.txt nicht und plant dies auch nicht.
Die Pointe: Am 3. Dezember 2025 tauchte kurzzeitig eine llms.txt in Googles eigenen Developer Docs auf. Die SEO-Community hielt den Atem an. Noch am selben Tag wurde die Datei wieder entfernt. Mueller stellte klar: keine offizielle Unterstützung. Was blieb, war ein kryptisches „hmmn :-/“ auf Bluesky und eine Community, die in dieses Emoticon mehr hineininterpretierte als in manchen Research Paper.
Was der Erfinder eigentlich wollte
An dieser Stelle lohnt sich ein Blick zurück, denn die Entstehungsgeschichte der llms.txt entlarvt das gesamte Missverständnis.
Am 3. September 2024 veröffentlichte Jeremy Howard — Co-Founder von Answer.AI und fast.ai, KI-Forscher und Dozent an den Universitäten Queensland und Stanford — seinen Vorschlag auf answer.ai und llmstxt.org. Das Problem, das er lösen wollte, war klar umrissen und hatte mit GEO nichts zu tun: Context Windows von LLMs sind zu klein für komplette Websites. HTML mit Navigation, Werbung und JavaScript in LLM-freundlichen Text zu konvertieren ist aufwändig und fehleranfällig. Besonders relevant sei das, so Howard explizit, für Development-Umgebungen, in denen LLMs schnellen Zugriff auf Programmierdokumentation und APIs brauchen.
Howards eigenes FastHTML-Projekt war die Referenzimplementierung. Ein Python-Framework mit technischer Dokumentation — genau der Use Case, für den die Idee konzipiert war.
Die Adoption blieb monatelang nischenhaft. Der Wendepunkt kam im November 2024, als Mintlify — ein Hosting-Dienst für Developer-Dokumentation — die llms.txt-Unterstützung für alle gehosteten Docs-Sites ausrollte. Praktisch über Nacht bekamen Tausende Dokumentationsseiten eine llms.txt, darunter Anthropic und Cursor. Die Schlagzeilen interpretierten das als Durchbruch. Was tatsächlich passiert war: Ein Docs-Hoster hatte ein Feature für seine Docs-Kunden aktiviert.
Ab hier begann die Zweckentfremdung. Die SEO- und GEO-Community entdeckte die llms.txt und interpretierte sie als das, was sie gerne hätte: einen neuen Hebel für Sichtbarkeit in KI-Suchsystemen. Yoast baute einen llms.txt-Generator in sein WordPress-Plugin. Agenturen nahmen „llms.txt-Erstellung“ in ihre Leistungskataloge auf. Konferenz-Speaker erklärten die Datei zum Pflichtprogramm.
Das Problem: Jeremy Howard hat llms.txt nie als GEO- oder SEO-Maßnahme vorgeschlagen. Sein Proposal adressiert Inference-Time-Nutzung durch Coding-Tools und KI-Agenten, nicht Sichtbarkeit in generativen Suchsystemen. Wer llms.txt als Ranking-Hebel verkauft, verkauft etwas, das der Erfinder selbst nie versprochen hat.
Die große Verwechslung: Publizieren vs. Konsumieren
Hier wird es interessant, denn hier liegt der Denkfehler, den die halbe GEO-Szene macht:
Ja, Anthropic hat eine llms.txt. Ja, OpenAI hat eine. Ja, Perplexity hat eine. Jede dieser Dateien liegt auf den jeweiligen Developer-Dokumentationsseiten. Sie dienen einem einzigen Zweck: Entwicklern und Coding-Assistenten einen strukturierten Einstiegspunkt in die API-Dokumentation zu geben. Wenn ein Entwickler in Cursor oder Claude Code arbeitet und die Anthropic-API-Docs laden will, ist eine llms.txt dafür ein sinnvolles Format.
Aber das hat absolut nichts damit zu tun, ob ClaudeBot, GPTBot oder PerplexityBot beim Web-Retrieval die llms.txt einer beliebigen Unternehmenswebseite auswertet. Die Existenz einer llms.txt auf docs.anthropic.com beweist nicht, dass Anthropic eure llms.txt auf beispiel-firma.de im Suchprozess berücksichtigt.
Wer diesen Unterschied nicht versteht, verwechselt die Tatsache, dass ein Restaurant eine Speisekarte hat, mit der Behauptung, es würde die Speisekarten anderer Restaurants lesen, bevor es kocht.
Vier Gründe, warum das so ist — und so bleiben wird
1. Manipulationsanfälligkeit
Die llms.txt ist ein vom Seitenbetreiber kontrolliertes Signal. Der Betreiber entscheidet, welche Inhalte ein LLM sehen soll und welche nicht. Das ist exakt das Problem, das Suchmaschinen beim Keywords-Meta-Tag identifiziert haben: Ein Signal, das der Bewertete selbst kontrolliert, ist für den Bewertenden wertlos. Suchsysteme müssen eigene Relevanzurteile fällen. Eine Datei, in der ich selbst kuratiere, was eine Suchmaschine über mich erfahren soll, ist per Definition kein vertrauenswürdiges Signal.
Was hindert jemanden daran, in der llms.txt eine geschönte Version der eigenen Inhalte zu präsentieren? Nichts. Das ist Cloaking mit Markdown-Syntax.
2. Retrieval-Ineffizienz
Stellt euch den hypothetischen Ablauf vor, den eine llms.txt im Retrieval-Stack erzeugen würde:
Request an /llms.txt
Parsing der Markdown-Struktur
LLM-gestützte Interpretation der Anweisungen und Priorisierungen
Anpassung der Retrieval-Strategie basierend auf diesen Anweisungen
Eigentliches Content-Retrieval
Antwortgenerierung
Das sind mindestens zwei zusätzliche Schritte — mit zusätzlicher Latenz, Token-Kosten und Fehleranfälligkeit — in einer Pipeline, die auf Geschwindigkeit optimiert sein muss. Google, OpenAI und Anthropic haben Milliarden in Content-Extraction-Pipelines investiert, die HTML zuverlässig parsen, Boilerplate entfernen und Hauptinhalte identifizieren. Warum sollten sie diesen bewährten Stack durch eine Datei ersetzen, deren Inhalt sie ohnehin verifizieren müssten?
Die Antwort: Würden sie nicht. Tun sie nicht.
3. Redundanz zur robots.txt
Für die Zugriffssteuerung existiert ein funktionierender, seit 1994 etablierter Standard: die robots.txt. Alle relevanten KI-Crawler — GPTBot, ClaudeBot, Google-Extended, PerplexityBot — respektieren robots.txt-Direktiven. Anthropic verweist in der eigenen Dokumentation zur Crawler-Steuerung ausschließlich auf robots.txt. Kein einziger KI-Anbieter hat gesagt: „Nutzt llms.txt statt robots.txt für die Zugriffssteuerung.“ Warum? Weil das Problem bereits gelöst ist.
4. Adoptionsversagen
Ein Standard, den kein relevanter Konsument implementiert, ist kein Standard. Er ist ein Vorschlag, der nicht angenommen wurde. Die robots.txt brauchte Jahre, um vom Vorschlag zum De-facto-Standard zu werden — aber sie wurde von Anfang an von den Suchmaschinen gelesen und respektiert. Die llms.txt wird nach über einem Jahr von keinem großen KI-Suchsystem im Retrieval-Kontext verwendet. Das ist kein „noch nicht“. Das ist ein Signal.
Was eure Agentur euch gerade verkauft
In Pitch-Decks und GEO-Audits sehe ich seit Monaten denselben Punkt: „llms.txt erstellen und optimieren.“ Manchmal als eigener Workstream, manchmal als Teil eines größeren Pakets, immer mit dem impliziten Versprechen, dass diese Datei die Sichtbarkeit in KI-Suchsystemen verbessert.
Das ist Ressourcenverschwendung. Jede Stunde, die euer Team damit verbringt, eine llms.txt zu pflegen, ist eine Stunde, die nicht in tatsächlich wirksame Maßnahmen fließt. Die Opportunitätskosten sind real: Content-Qualität, semantische Strukturierung, Entity-Abdeckung, Zitierfähigkeit — alles Faktoren, für die es tatsächliche Evidenz gibt, dass sie die Sichtbarkeit in generativen Suchsystemen beeinflussen.
Wo llms.txt tatsächlich Sinn ergibt
Fairness gebietet es, den einen Use Case zu benennen, in dem llms.txt einen legitimen Zweck erfüllt: Developer-Dokumentation für Coding-Assistenten und KI-Agenten.
Wenn eure Zielgruppe Entwickler sind, die mit Cursor, Windsurf oder Claude Code arbeiten, und ihr eine umfangreiche API-Dokumentation habt, dann kann eine llms.txt als strukturierter Einstiegspunkt für diese Tools nützlich sein. Das ist der ursprüngliche Vorschlag von Jeremy Howard, und für diesen Kontext ist er nachvollziehbar.
Aber: Das ist Developer Relations. Das ist kein GEO. Das ist kein SEO. Und es betrifft einen Bruchteil aller Websites.
Was stattdessen zu tun ist
Wer seine Sichtbarkeit in KI-Suchsystemen tatsächlich verbessern will, sollte sich auf das konzentrieren, was nachweislich funktioniert:
Content-Qualität und Zitierfähigkeit. Generative Suchsysteme zitieren Quellen, die Fakten, Daten und Expertise liefern. Wer zitiert werden will, muss zitierwürdig sein. Das bedeutet: originäre Daten, klare Aussagen, nachprüfbare Fakten.
Semantische Strukturierung. Klare Heading-Hierarchien, konsistente Entity-Nutzung und logische Struktur. Diese Signale werden von KI-Crawlern beim regulären Crawling erfasst — ohne Umweg über eine zusätzliche Datei.
Topical Authority. Thematische Tiefe und Breite. Wer zu einem Thema die umfassendste und verlässlichste Quelle ist, wird von generativen Systemen bevorzugt herangezogen. Dabei sollte man nicht vergessen: Die großen KI-Suchsysteme nutzen für ihr Grounding klassische Websuche. Wer in der organischen Suche stark ist, hat auch in der generativen Suche die besseren Karten.
Monitoring statt Spekulation. Messt, wo und wie euer Brand in KI-generierten Antworten erscheint. Passt eure Strategie auf Basis von Daten an, nicht auf Basis von Konferenz-Slides.
Fazit
Die llms.txt war eine interessante Idee mit einem nachvollziehbaren Kern: Webinhalte maschinenlesbarer machen. Für den spezifischen Kontext von Developer-Dokumentation hat sie ihren Platz.
Als GEO-Maßnahme ist sie gescheitert. Nicht, weil sie schlecht implementiert wird. Nicht, weil sie „noch Zeit braucht“. Sondern weil die fundamentale Prämisse — dass KI-Suchsysteme eine vom Seitenbetreiber kuratierte Inhaltsbeschreibung als vertrauenswürdiges Signal verwenden würden — dem Grundprinzip moderner Suchsysteme widerspricht. Suchmaschinen bewerten. Sie lassen sich nicht bewerten.
Hört auf, llms.txt-Dateien als GEO-Maßnahme zu erstellen. Investiert die Zeit in Inhalte, die es wert sind, von KI-Systemen gefunden und zitiert zu werden. Das ist schwerer. Aber es funktioniert.
Nach den Plugins stelle ich nun die besten WordPress Themes vor. Diese Liste umfasst alle populären und beliebten Themes und wird permanent aktualisiert und bei Bedarf erweitert. Ich habe mich mit meinen 20 Jahren Erfahrung beim Aufbau und der Optimierung webbasierter Vertriebs- und Geschäftsmodelle also der Frage gewidmet:
Welches ist das beste WordPress Theme 2026?
Diese Frage lässt sich leider nicht mit einer einzigen, kurzen Antwort beantworten, denn die Auswahl an hochwertigen WordPress Themes ist nahezu endlos. Jedes Theme hat seine Vor- und Nachteile und für unterschiedliche Bedürfnisse gibt es daher auch unterschiedlich gut geeignete Lösungen. Um die Frage möglichst knapp zu beantworten, habe ich meine Empfehlungen in WordPress Themes für Designer und Entwickler aufgeteilt, denn diese haben sehr unterschiedliche Bedürfnisse und Anforderungen:
Welches ist das beste WordPress Theme für Designer?
Wenn Du nicht den gesamten Artikel lesen willst und relativ neu in der Welt von WordPress bist, dann hol‘ Dir am besten das Divi-Theme. Kein anderes Theme ist so benutzerfreundlich und für Anfänger geeignet. Wenn Du eine große Auswahl an Templates, Vorlagen, Layouts und Stilen willst, aber wenig technisches Verständnis in Sachen HTML und CSS hast, dann ist ist Divi das Richtige Theme für Dich.
Welches ist das beste WordPress Theme für Web-Entwickler?
Wenn Du technisch versierter bist und eine genaue Vorstellung vom Design und Layout der Webseite hast, bist Du mit einem blockbasierten Theme wie GeneratePress, Kadence oder Neve wahrscheinlich am besten bedient. Alle drei setzen auf das modernste System und ermöglichen den Aufbau von Layouts mittels Gutenberg.
Der Gutenberg-Editor hat derzeit bei vielen Nutzern noch einen schlechten Ruf. Das ist aus meiner Sicht aber längst nicht mehr gerechtfertigt, denn seit dem vermurksten Start von Gutenberg, hat sich sehr viel getan. Ich bin mittlerweile absoluter Fan des visuellen Editors, der sich hervorragend in WordPress integriert hat.
Welches ist das beste WordPress Theme für WooCommerce?
Für Online-Shops mit WooCommerce ist Flatsome die erste Wahl. Mit über 100.000 Kunden ist es eines der meistverkauften WooCommerce-Themes auf ThemeForest. Es bietet exzellente Shop-Features wie Live-Suche, Schnellansicht, Wunschlisten und einen eigenen UX Builder. Alternativ eignen sich auch Astra und Kadence hervorragend für WooCommerce.
Falls Du Dir noch nicht sicher bist, solltest Du Dir die folgende Liste der besten und schnellsten WordPress Themes, also meine persönlichen Top 12 WordPress Themes 2026, anschauen.
Ich lege in meinen Tests übrigens ein besonderen Augenmerk auf den PageSpeed, also die Ladezeiten der Themes, denn mittlerweile sind die Core Web Vitals fester Bestandteil des Algorithmus von Google. Damit ist der PageSpeed ein direkter Rankingfaktor und damit zum Erfolgskriterium für jede WordPress-Webseite!
1. Divi – Das beste WordPress Theme für Einsteiger und Anfänger
Divi ist das weltweit beliebteste Premium-Theme mit über 750.000 Kunden. Dank seines integrierten Visual Builders ist es besonders für Einsteiger ohne Programmierkenntnisse ideal geeignet.
Das Divi-Theme ist ein schickes, modernes und flexibles WordPress Theme, mit dem Du so gut wie jede Seite realisieren kannst. Es hat seinen eigenen Page Builder integriert und ist seit Version 4 mit einem mächtigen Theme Builder ausgestattet. Damit hast Du erstmals die volle Kontrolle über Deine gesamte Website und das ganz ohne Programmierkenntnisse.Divi bietet unzählige fertige Templates für quasi jeden Seitentyp und jede Inhaltsart, die es Dir erlauben sofort loszulegen und live zu gehen.
Vorteile von Divi
Sehr benutzerfreundlicher Visual Builder mit Drag & Drop
Riesige Auswahl an fertigen Templates und Layouts
Theme Builder für Header, Footer und alle Seitentypen
Bloom (E-Mail Opt-in) und Monarch (Social Sharing) inklusive
Lifetime-Lizenz für unbegrenzte Webseiten verfügbar
Exzellenter Support
Nachteile von Divi
Nicht das schlankeste Theme (benötigt teilweise noch jQuery)
Eigener Builder erzeugt Vendor-Lock-in
Nicht nativ Gutenberg-basiert
Template Bereiche mit dem Template Builder in Divi 4
Der integrierte Theme Builder nutzt die bekannten Funktionen des Divi Builders und erweitert ihn auf alle Bereiche des Themes, so dass man damit nun auch benutzerdefinierte Header und Footer, Kategorieseiten, Produktvorlagen, Blogposts, 404 Seiten und so weiter erstellen kann, ohne selbst Programmieren zu müssen.
Damit ist Divi besonders geeignet für Nutzer, die nicht selbst programmieren können oder wollen, aber dennoch die Gestaltung Ihrer WordPress-Seite vollständig beeinflussen möchten.
In Sachen PageSpeed kann man sehr gut mit Divi arbeiten. Dinge wie kritisches CSS, Caching, aufgeschobenes JavaScript und vernünftige Bildkompression werden mittlerweile voll unterstützt. Divi ist zwar nicht das schlankeste Theme und benötigt an vielen Stellen noch jQuery, bietet dafür jedoch eine gigantische Auswahl an Gestaltungselementen und einen hervorragenden Front-End-Editor.
Das Preismodell von Elegant Themes, den Machern des Divi-Themes, finde ich sehr fair. Wer 249 USD einmalig bezahlt, kann alle Themes und Plugins inkl. Widgets auf Lebenszeit und für unbegrenzt viele Webseiten einsetzen und das sogar für Kundenprojekte. Alternativ kann man auch 89 USD jährlich für Updates und Support bezahlen. A Propos! Der Support ist richtig gut!
Im Preis enthalten sind außerdem die beiden exzellenten Plugins Bloom und Monarch. Bloom ist ein E-Mail Opt-in Plugin, also dafür gedacht sehr konversionsstarke Newsletter-Formulare in die Webseite einzubinden. Monarch ist ein sehr umfangreiches und leistungsstarkes Social Media Sharing Plugin.
1 Lizenz. Vollständiger Zugriff. Unbegrenzte Anzahl von Websites. Unbegrenzte Anzahl von Benutzern.
Nur 80$ im Jahr oder 224$ einmalig!
Werde jetzt einer von 750.000 Kunden und erhalte Zugang zu Divi, Extra, Bloom, Monarch und mehr. Das ultimative WordPress-Toolkit wartet auf Dich, und zwar für einen unschlagbaren Preis.
Mein Kollege Saša zeigt Dir, wie Du mit dem Divi Theme schnell und einfach eine deutschsprachige Webseite erstellen kannst. Dafür brauchst Du keine Programmierkenntnisse und musst keine Zeile Code schreiben:
2. Kadence Theme – Macht Gutenberg zum PageBuilder!
Kadence ist eines der schnellsten und modernsten WordPress-Themes und macht den Gutenberg-Editor zu einem vollwertigen Page Builder. Es ist unser absoluter Favorit für alle, die schlanke und schnelle Webseiten bevorzugen.
Auf der Suche nach der perfekten Theme- und Block-Builder-Kombination tauchte das neue Kadence Theme bei unseren Recherchen auf. Es ist eines der wenigen Themes, das nicht versucht, sich über Hunderte von Extra-Features zu verkaufen, sondern ist auf das Wichtigste, Wesentliche reduziert.
Kadence wurde von Grund auf für blitzschnelle Leistung entwickelt und mit modernen Funktionen ausgestattet, mit denen das Erstellen von Websites wirklich Spaß macht. Es lässt sich schnell installieren (Tutorial im Video weiter unten) und kommt nach der Installation sehr übersichtlich und ohne Schnickschnack daher.
Vorteile von Kadence
Nahtlose Gutenberg-Integration ohne eigene Oberfläche
23+ Kadence Blocks mit flexiblen Layout-Optionen
Extrem schnelle Ladezeiten dank schlankem Code
Professionelle Starter Templates zum Importieren
Global Colors und umfangreiche Typografie-Steuerung
WooCommerce-Unterstützung
Nachteile von Kadence
Backend-basiertes Editing (Vorschau für Frontend nötig)
Weniger Templates als Divi oder Astra
Gelegentlich Workarounds bei der Element-Positionierung nötig
Es enthält sämtliche Features, die man sich von einem modernen WordPress-Theme wünscht:
Das Essential Bundle enthält außerdem die Pro Starter Templates. Eine Kollektion von kompletten Website-Vorlagen, die professionell gestaltet sind. Immer mehr Themes gehen dazu über, das WordPress-eigene Userinterface als Schnittstelle für Layout- und Funktionselemente zu verwenden. So auch Kadence, denn mittels des Kadence Blocks Plugins wird aus Gutenberg ein echter PageBuilder.
Unser Video-Tutorial für Kadence WP
Im Rahmen unseres Kadence WP Pro Testberichts haben wir eine vollständige Installationsanleitung zum Kadence Theme und Kadence Blocks Pro, sowie die komplette Umsetzung einer fiktiven Website in einem 1 Stunde und 22 Minuten langen Mega-Videotutorial zusammen gestellt:
Ganz ehrlich: Das Kadence Theme, gemeinsam mit den Blocks ist einfach zu bedienen und damit zu arbeiten macht wirklich Spaß! Die Integration in Gutenberg ist durch und durch gelungen. Man fragt sich, ob es in Zukunft noch Builder geben wird, die sich diese Schnittstelle nicht nutzen und eine eigene Oberfläche basteln. Der große Vorteil der Standardisierung: Sobald man einen Builder gelernt hat, kennt man alle. Es gibt kaum noch eine Lernkurve.
Wir haben in den letzten Jahren eine ganze Reihe an Page-Buildern getestet und ich kann sagen, dass Kadence unser absoluter Favorit ist!Elementor und Divi können mehr. Keine Frage. Aber mir persönlich macht das schnelle Arbeiten mit Kadence wirklich Spaß.
Wenn du schlanke Webseiten und schnelle Page Builder magst, die auch noch in Zukunft mit Gutenberg gemeinsam genutzt werden können, dann solltest du Kadence ernsthaft in Betracht ziehen!
Der Express-Plan kostet 69 USD/Jahr für 3 Webseiten und enthält Theme Pro, Blocks Pro und Starter Templates. Der Plus-Plan liegt bei 169 USD/Jahr für 10 Sites und der Ultimate-Plan bei 299 USD/Jahr für 25 Sites. Es gibt auch eine Lifetime-Lizenz ab 899 USD einmalig.
Falls Du eine große Auswahl an Layouts und Stilen und ein Gesamtpaket inklusive Marketing-Plugins möchtest und kein Verständnis für CSS und Layout-Regeln hast, bist Du bei Divi wahrscheinlich besser aufgehoben.
3. GeneratePress – Schlankes Theme mit sehr cleanem Code
GeneratePress ist mit weniger als 1 MB eines der leichtesten WordPress-Themes überhaupt. Es ist komplett auf Geschwindigkeit, SEO und Usability optimiert und eignet sich hervorragend für Entwickler und performance-bewusste Nutzer.
GeneratePress ist ein sehr schnelles und extrem leichtes (< 1 MB Größe, gepackt), mobil angepasstes, responsives WordPress-Theme. Es ist komplett auf Geschwindigkeit, SEO und Usability ausgelegt und optimiert. Es eignet sich außerdem hervorragend für Einsteiger und kann durch das Freemium-Model auch erstmal kostenlos ausprobiert werden!
Vorteile von GeneratePress
Extrem schlank und schnell (unter 1 MB)
Kostenlose Basisversion zum Ausprobieren
schema.org Mikrodaten bereits integriert
Funktioniert mit jedem Page Builder
GenerateBlocks für komplexe Gutenberg-Layouts
In über 20 Sprachen verfügbar
Nachteile von GeneratePress
Weniger Design-Optionen als Divi oder Elementor-basierte Themes
Für komplexe Layouts wird GenerateBlocks Pro benötigt
Weniger Starter Templates als die Konkurrenz
In der Premium-Version enthält es dann weitere Funktionen und Anpassungsmöglichkeiten. Das Schöne ist, dass GeneratePress mit jedem Page-Builder funktioniert. Für SEO sind bereits alle schema.org Mikrodaten integriert und ist in über 20 Sprachen verfügbar. Besonders toll: GeneratePress wurde bereits auf einer tieferen Ebene mit dem neuen Gutenberg-Editor integriert. Keine Angst also vor dem Gutenberg-Update! Du kannst Dir sogar das kostenlose GenerateBlocks Plugin installieren und damit sehr coole und komplexe Layouts ohne PageBuilder direkt in Gutenberg umzusetzen!
Übrigens: GeneratePress eignet sich nicht nur für Nerds und Entwickler, denn in der GeneratePress Site Library gibt es mittlerweile unzählige schicke und schnelle Vorlagen, die man mit einem Klick importieren kann und die visuelle Anpassung geschieht vollkommen nativ über den eingebauten WordPress Customizer, wie ihr im Video auf der Startseite von GeneratePress sehr schön sehen könnt!
GeneratePress Premium kostet 59 USD/Jahr für bis zu 500 Webseiten. Es gibt auch eine Lifetime-Option.
Neve erreicht volle 100 Punkte in Googles PageSpeed Insights Test und gehört damit zu den schnellsten WordPress Themes überhaupt. Es kommt komplett ohne jQuery und ohne aufgeblasenen Code daher.
Vorteile von Neve
100/100 PageSpeed Insights Score
Komplett ohne jQuery – Ladezeit unter 1 Sekunde
Kompatibel mit allen großen Page Buildern
Volle WooCommerce-Unterstützung
Über 80 vorgefertigte Starter Templates
Drag & Drop Header- und Footer-Builder
Nachteile von Neve
Weniger Gestaltungsoptionen als Divi oder Elementor
Premium Starter Sites nur im teureren Paket
Weniger Community-Ressourcen als Astra
Viele WordPress Themes sind wahnsinnig überladen und durch immer mehr Features komplex und kompliziert zu benutzen geworden. Das macht viele WordPress Seiten langsam und schwerfällig. Doch Damit ist jetzt Schluß: Das nagelneue Neve-Theme wurde für maximale Geschwindigkeit in der neuen WordPress-Ära entwickelt. Dank Gutenberg Blocks und den Möglichkeiten des integrierten WordPress Customizer ist Neve genauso mächtig wie klassische Multipurpose-Themes mit PageBuilder.
Neve kommt vollständig ohne jQuery und ohne aufgeblasenen Code daher. Die damit erstellten Seiten laden in weniger als 1 Sekunde vollständig! Bei einer Standardinstallation benötigte Neve gerade einmal 0,6 Sekunden zum Laden. Ich habe meinen Blog auf das Neve-Theme umgestellt und erreiche damit volle 100 Punkte in Googles PageSpeed Insights Test!
Natürlich musst Du nicht auf eine stylishe Webseite verzichten und sogar WooCommerce wird von Neve voll unterstützt. Natürlich kannst Du damit ganz einfach Kopf- und Fußzeilen erstellen, per Drag & Drop anpassen und aus einer Vielzahl von Layout-Optionen auswählen.
Falls Du mit einem PageBuilder arbeiten willst, oder deine existierende Webseite auf das Neve-Theme umstellen willst, kannst Du Neve problemlos mit Elementor, Brizy, Beaver Builder, Visual Composer, SiteOrigin, Gutenberg und Divi Builder verwenden. Dazu gibt es über 80 vorgefertigte Seiten, die Du mit einem Klick importieren kannst. Jeden Monat kommen weitere hinzu. Die Bibliothek des Neve-Starter-Themes ermöglicht es Dir, eine fertige Website im Handumdrehen zu importieren und dann einfach mit deinen Bildern und Inhalten anzupassen.
Preislich liegt Neve sehr fair bei 69 USD/Jahr (Personal) für beliebig viele Domains und Webseiten. Wer die Premium Starter Sites, den WooCommerce Booster oder den Priority Support nutzen möchte, zahlt 149 USD/Jahr (Business). Für Agenturen und WordPress-Dienstleister ist das Agency-Paket mit 259 USD/Jahr wohl das Richtige. Es gibt auch Lifetime-Lizenzen ab 59 USD einmalig.
5. Astra – Das beliebteste WordPress Theme aller Zeiten
Astra ist mit über 2,3 Millionen aktiven Installationen das beliebteste Drittanbieter-Theme für WordPress. Es ist extrem schnell, kommt ohne jQuery aus und bietet eine riesige Auswahl an Starter Templates.
Vorteile von Astra
Über 2,3 Millionen aktive Nutzer – größte Community
Komplett ohne jQuery – extrem schnelle Ladezeiten
Riesige Bibliothek an vorgefertigten Webseiten
Funktioniert mit Elementor, Beaver Builder, Brizy und Gutenberg
Kostenlose Version zum Ausprobieren
Schema Pro Plugin im Growth Bundle inklusive
Nachteile von Astra
Viele Features nur in teureren Bundles verfügbar
Kann für Anfänger durch die vielen Optionen überwältigend sein
Einige Premium-Starter-Sites erfordern Elementor Pro
Astra ist nicht nur das beliebteste WordPress-Theme aller Zeiten, sondern auch noch eines der schnellsten und flexibelsten WordPress-Themes
Es gibt unzählige vorgefertige Webseiten, die man sich nach der Installation einfach importieren kann und dann mit Veränderungen an die eigenen Bedürfnisse anpassen kann. Egal ob Du Elementor, den Beaver Builder, Brizy oder mit dem Gutenberg Editor arbeiten willst, in der Webseiten-Galerie wirst Du garantiert fündig. Übrigens: Als eines der wenigen Themes kommt Astra komplett ohne jQuery aus, was die Seiten wirklich schnell machen. Ladezeiten von einer halben Sekunde sind mit einem SCHNELLEN HOSTING wirklich möglich!
Man kann Astra kostenlos ausprobieren, die Pro-Version geht ab 69 USD/Jahr los. Für Dienstleister und Agenturen empfiehlt sich das Essential Toolkit für 119 USD/Jahr, denn dafür bekommt man Spectra, die Ultimate Addons for Elementor und über 50 vorgebaute Webseiten zum Anpassen. Im Business Toolkit für 159 USD/Jahr sind dann zusätzlich OttoKit Pro und weitere Premium-Plugins enthalten. Für alle Pläne gibt es auch Lifetime-Lizenzen ab 319 USD.
6. Flatsome – Das beste WordPress Theme für WooCommerce
Flatsome ist mit über 100.000 Kunden eines der meistverkauften WooCommerce-Themes auf ThemeForest. Es bietet eine hervorragende E-Commerce-Integration mit eigenem UX Builder und erzielt 98 von 100 Punkten im GTmetrix Speed-Test.
Vorteile von Flatsome
Hervorragende WooCommerce-Integration mit Live-Suche, Schnellansicht und Wunschlisten
Eigener UX Builder (Frontend-WYSIWYG-Editor)
98/100 GTmetrix Speed-Score
Über 100 vordefinierte Sektions-Vorlagen
Benutzerfreundlicher Setup-Wizard für WooCommerce
Einmaliger Kaufpreis ohne laufende Kosten
Nachteile von Flatsome
Nur über ThemeForest erhältlich (kein eigener Marktplatz)
Support nur auf Englisch
Relativ wenige vordefinierte komplette Layouts (ca. 20 Variationen)
Nicht ideal für Anfänger ohne E-Commerce-Bedarf
Flatsome wurde speziell für den E-Commerce entwickelt und bietet eine Vielzahl an Shop-spezifischen Features, die andere Themes nicht haben. Dazu gehören benutzerdefinierte Checkout-Seiten, Sale-Kennzeichnungen, QuickZoom für Produktbilder und ein integrierter Setup-Wizard, der die WooCommerce-Konfiguration zum Kinderspiel macht.
Der UX Builder von Flatsome ist ein Frontend-Editor, mit dem man Seiten visuell gestalten kann. Er bietet über 36 Content-Elemente und rund 100 Sektions-Vorlagen. Damit lassen sich nicht nur Shop-Seiten, sondern auch Agentur-Websites oder Portfolio-Seiten erstellen.
In Sachen Performance ist Flatsome beeindruckend: Im GTmetrix-Test erreicht es 98 von 100 Punkten. Für ein Theme mit so vielen integrierten Features ist das ein hervorragender Wert.
Flatsome kostet 59 USD einmalig auf ThemeForest. Dafür erhält man 6 Monate Support, der für 17,63 USD um weitere 6 Monate verlängert werden kann. Für ein Theme mit diesem Funktionsumfang ist das ein sehr faires Preis-Leistungs-Verhältnis.
7. OceanWP – Modernes, schnelles Theme mit 210 Demo-Seiten
OceanWP ist mit über 5 Millionen Downloads und 700.000 Installationen eines der beliebtesten WordPress-Themes weltweit. Es bietet 210 professionelle Demo-Websites inklusive lizensierter Fotos und Illustrationen.
Vorteile von OceanWP
210 Pro-Demos inklusive lizensierter Bilder und Illustrationen
Umfangreiche Elementor-Widgets als Elementor Pro-Ersatz
Zugriff auf Bilddatenbanken im Business-Paket
Kostenlose Basisversion verfügbar
Sehr attraktiver Preis
Nachteile von OceanWP
Viele Erweiterungen nur mit Elementor kompatibel
Gutenberg-Support weniger ausgereift als bei Kadence oder Blocksy
Damit tritt es in direkte Konkurrenz zu den aktuellen Favoriten Kadence und Blocksy. Wir haben das Theme auf Herz und Nieren geprüft und ein Beispielprojekt damit umgesetzt:
OceanWP ist zwar mit vielen Buildern kompatibel, der Favorit scheint jedoch Elementor zu sein. Einige Erweiterungen sind nur mit Elementor kompatibel und nur für Elementor gibt es eine ganze Reihe Content-Module.
Die Premium-Version von OceanWP beinhaltet viele Pro-Erweiterungen. Die Elementor-Widgets verdienen einen besonderen Hinweis. Die Anzahl und Qualität sind so hoch, dass eine Lizenzierung von Elementor Pro für viele Anwender nicht notwendig sein sollte.
Die Möglichkeit eine komplette Demo-Webseite inklusive aller lizensierten Fotos und Illustrationen zu importieren und sofort damit online gehen zu können, ist wirklich einzigartig!
Die drei großen Stärken von OceanWP sind der Zugriff auf die Bilddatenbanken, die Elementor-Module und die zahlreichen Website-Demos. Der Preis ist sehr attraktiv. Die Business-Version ist sogar günstiger als das Abo bei Freepik selbst!
8. Blocksy – Das schnelle Gutenberg-Theme für Einsteiger
Blocksy ist ein performanceoptimiertes WordPress-Theme, das sich nahtlos in den Gutenberg-Editor integriert. Es ist besonders für Einsteiger geeignet, die ein modernes und schnelles Theme suchen.
Vorteile von Blocksy
Sehr schnell und performanceoptimiert
Intuitiver und umfangreicher Customizer
13+ vorkonfigurierte Starter Sites
Content Blocks mit Display Conditions (Pro)
Kostenlose Version mit vielen Features
Responsiver und schneller Support
Nachteile von Blocksy
Weniger Starter Sites als Kadence oder Astra
Für komplexe Layouts wird ein zusätzlicher Block-Builder benötigt
Typografie-Einstellungen übernehmen nicht immer automatisch
Blocksy überzeugt besonders durch seine Performance und den intuitiven Customizer. Mit den Content Blocks und Display Conditions der Pro-Version kann man gezielt Inhalte für bestimmte Seiten, Beiträge oder Kategorien anzeigen lassen. Das Theme kommt mit kostenlosen und Premium-Extensions, die den Funktionsumfang deutlich erweitern.
Im direkten Vergleich mit Kadence ist Blocksy genauso schnell. Allerdings hat Kadence die Nase vorn, wenn es um die Theme-Builder-Integration und die Anzahl der nativen Blöcke geht. Wer jedoch ein einfacheres, schlankeres Theme bevorzugt und mit einem externen Block-Builder wie Stackable oder Qubely arbeiten möchte, ist mit Blocksy bestens bedient.
Blocksy Pro kostet ab 69 USD/Jahr für eine Webseite (Personal). Für 10 Webseiten zahlt man 99 USD/Jahr (Business) und für unbegrenzt viele 149 USD/Jahr (Agency). Es gibt auch Lifetime-Lizenzen ab 149 USD einmalig.
Qi ist eines der visuell attraktivsten WordPress-Themes mit einer beeindruckenden Auswahl an Demo-Websites. Es eignet sich besonders für Portfolio-Webseiten und Kreative, die Wert auf schönes Design legen.
Vorteile von Qi Theme
Visuell sehr attraktive und liebevoll gestaltete Demo-Websites
Große Auswahl an Elementor-Widgets und Content-Modulen
Wie immer haben wir das WordPress Theme durchleuchtet und damit unser Beispielprojekt damit umgesetzt. In unserem ausführlichen Testbericht kannst Du die Zusammenfassung und unsere Empfehlung nochmal ausführlich lesen. Unser Testbericht inkl. Mega-Tutorial kannst Du Dir hier anschauen:
Das Page Builder Framework ist das ideale Theme für alle, die mit einem Page Builder wie Elementor, Beaver Builder oder Brizy arbeiten. Es bringt selbst wenig Code und Styling mit und überlässt die Gestaltung komplett dem Builder.
Vorteile von Page Builder Framework
Optimiert für alle großen Page Builder
Minimaler eigener Code – maximale Performance
Volle Kontrolle über die visuelle Gestaltung
Anpassung über nativen WordPress Customizer
Nachteile von Page Builder Framework
Wenig eigene Design-Elemente – Page Builder erforderlich
Nicht für Nutzer geeignet, die ein fertiges Design wollen
Kleinere Community als Astra oder GeneratePress
Das Page Builder Framework Theme ist sehr einfach anzupassen. So kannst Du über das Theme alle Bereiche außerhalb des Contents gestalten, also Dein Menü, die Farben, etc. einfach über den integrierten WordPress Customizer anpassen und die restlichen Seitenelemente mit dem Page Builder ausgestalten.
Das Page Builder Framework Theme kann in seiner einfachsten Standard-Version kostenlos heruntergeladen, muss aber für einen sinnvollen Einsatz schon mit dem kostenpflichtigen Premium Plugin für 58 USD jährlich oder 248 USD einmalig erweitert werden. Das Theme arbeitet dann exzellent mit Elementor, dem Beaver Builder, Brizy, Divi Builder, Visual Composer sowie dem SiteOrigin PageBuilder zusammen.
Wenn Du Dich also in einen der vielen Page Builder verliebt hast, würde ich Dir in der Tat das Page Builder Framework Theme empfehlen. Denn damit kannst Du beliebig viele Webseiten erstellen und jeden Aspekt Deiner visuellen Gestaltung selbst kontrollieren – und das auch noch schnell, einfach und ohne Programmierkenntnisse!
Genesis ist ein professionelles Theme-Framework von StudioPress, das mittlerweile zu WP Engine gehört. Es bietet eine suchmaschinenoptimierte und sichere Grundlage für professionelle Webseiten und ist bei WP Engine Hosting inklusive.
Vorteile von Genesis
Sauberer, suchmaschinenoptimierter Code
Hohe Sicherheitsstandards
100% kompatibel mit dem Gutenberg-Editor
Bei WP Engine Hosting kostenlos enthalten
Nachteile von Genesis
Erfordert Entwicklerkenntnisse für individuelle Anpassungen
Weniger visuelle Gestaltungsmöglichkeiten als moderne Themes
Child-Themes benötigen teilweise PHP-Kenntnisse
Bei dieser Empfehlung handelt es sich nicht um ein einzelnes Theme, sondern ein WordPress-Theme Framework von StudioPress. Das Genesis Framework ermöglicht es, schnell und einfach tolle Websites mit WordPress zu erstellen. Genesis bietet eine professionelle und vor allem suchmaschinenoptimierte Grundlage für erfolgreiche Webseiten.
Alle Themes wurden außerdem bereits ausgiebig mit dem Gutenberg-Editor getestet und sind zu 100% mit dem neuen Gutenberg-Editor kompatibel. Der neue Editor verwendet blockbasierte Elemente, um noch einfacher und flexibler wirklich tolle Seiten und Beiträge erstellen zu können.
Auch wenn die Webseiten, auf denen man das jeweilige Theme kaufen kann auf englisch ist, kann man mit JEDEM hier empfohlenen Theme problemlos deutsche bzw. deutschsprachige Webseiten erstellen. Das WordPress-Backend ist natürlich auch Deutsch!
Kostenlose WordPress Themes gibt es wie Sand am Meer. Viele davon findet man im offiziellen Theme-Verzeichnis auf WordPress.org. Allerdings finden sich dort sehr häufig nur noch abgespeckte „light“-Versionen kostenpflichtiger Themes, bei denen man nur eine eingeschränkte Basis-Funktionalität umsonst erhält. Wer die Wahl hat und seiner Seite ein individuelles und professionelles Aussehen geben möchte, sollte meiner Meinung nach also lieber ein wenig Geld für ein sehr gutes Premium Theme ausgeben.
Wenn Dein Budget einfach kein Premium-Theme wie Divi oder Kadence hergibt, kannst Du auch mit einem kostenlosen Theme starten und später auf die Premium-Version upgraden, oder mit einem schlanken, kostenlosen WordPress Theme starten und dieses mit Gutenberg Blöcken aus einer der folgenden Plugins erweitern:
Hilfe: Das richtige WordPress Theme finden – So geht’s
Unter Berücksichtigung der Bedürfnisse meiner Besucher habe ich viel Zeit darauf verwendet, die bestmöglichen WordPress Themes für verschiedene Arten von Websites zu finden, zu testen und hier vorzustellen. Unabhängig von Ihrem beruflichen Hintergrund oder Ihren Computerkenntnissen wird es Ihnen mit diesen Themes auf jeden Fall gelingen, Ihre Webseite zu erstellen und Änderungen selbst vorzunehmen. Um die Sache noch einfacher zu machen, wird jedes Theme mit allen notwendigen Dokumentationen geliefert, die jeden Schritt des Installationsprozesses explizit erklären.
Um mit den modernen Trends im Web Schritt zu halten, sind alle Templates browserübergreifend aufgebaut, damit Ihre Website in allen modernen Browsern einwandfrei aussieht. Darüber hinaus haben alle hier vorgestellten Produkte ein 100% responsives Design, das es ermöglicht, Ihre Webseite von jedem modernen mobilen Gerät Ihrer Wahl aus zu besuchen und zu genießen.
Jedes dieser Premium Themes für WordPress ist suchmaschinenfreundlich. So können Sie Ihre Website immer optimieren, damit mehr Kunden über die Waren und Dienstleistungen Ihres Unternehmens im Internet erfahren können!
Mit dem Kauf bekommst Du vollen Zugang zum Support. Professionelle Unterstützung wird von den technischen Spezialisten der Hersteller in der Regel Tag und Nacht geleistet, wann immer sie benötigt wird. Diese garantieren, dass Deine Fragen beantwortet werden!
Häufig hat man spezielle Anforderungen oder Funktionalitäten im Kopf, dann braucht man mit kostenlosen Themes meistens garnicht erst anfangen. Denn viele kostenlose Themes sind bloß abgespeckte Versionen der jeweiligen Premium-Variante oder es werden sowieso nur grundlegende Features ohne besondere Templates und Inhaltselemente unterstützt. Dann solltest Du jedes Theme, das für Dich in Frage kommt, auf die benötigten Funktionen hin überprüfen und am besten ausprobieren, ob Du damit auch zurecht kommst.
Falls Du mit einer fertigen Vorlage arbeiten willst, die Du „nur“ noch mit Deinen Inhalten füllst, solltest Du am besten zuerst die Demo-Seiten der Themes und die Template-Bibliotheken von Kadence und Divi nach einem passenden Layout für Deinen Zweck durchstöbern.
In jedem Falle gilt: Lass Dich nicht entmutigen! Manchmal muss ich selbst auch erst zwei, drei, manchmal auch fünf Themes ausprobieren, bis ich das Richtige für mein Projekt gefunden habe!
Für die häufigsten Einsatzzwecke stelle ich Euch in eigenen Artikel speziell passende Themes vor:
Wie Du feststellen wirst, setze ich größtenteils auf Premium Themes, also kostenpflichtige Templates. Diese kosten zwar ein paar Dollar bzw. Euros, bringen dafür aber eine ganze Menge zusätzlicher Funktionalitäten mit sich, auf die ich nicht verzichten möchte. Der große Unterschied ist aber vorallem die Möglichkeit den Support des Herstellers in Anspruch zu nehmen, wenn man einmal nicht weiter kommt oder unerwartete Probleme auftreten.
Mit einem kostenlosen Theme steht man alleine da.
Häufige Fragen zu WordPress Themes
Welches WordPress-Theme ist das beste?
Das beste WordPress-Theme hängt von Deinen Anforderungen ab. Für Einsteiger ohne Programmierkenntnisse empfehle ich Divi, für Entwickler und SEO-bewusste Nutzer GeneratePress oder Kadence, und für WooCommerce-Shops ist Flatsome die erste Wahl. Astra ist das vielseitigste Theme mit der größten Community.
Welches WordPress-Theme ist am schnellsten?
Die schnellsten WordPress-Themes sind Neve (100/100 PageSpeed Score), GeneratePress (unter 1 MB Größe) und Kadence. Alle drei kommen ohne jQuery aus und laden in unter einer Sekunde. Auch Astra und Blocksy gehören zu den Performance-Spitzenreitern.
Welches Theme eignet sich am besten für WooCommerce?
Für WooCommerce-Shops ist Flatsome die beste Wahl. Es wurde speziell für E-Commerce entwickelt und bietet Features wie Live-Suche, Produktschnellansicht, Wunschlisten und einen eigenen UX Builder. Alternativ eignen sich Astra, Kadence und Neve ebenfalls sehr gut für WooCommerce.
Sind kostenlose WordPress-Themes gut genug?
Kostenlose WordPress-Themes sind für den Einstieg geeignet, haben aber oft eingeschränkte Funktionen und keinen Support. Themes wie Astra, Kadence, GeneratePress, Neve und Blocksy bieten starke kostenlose Versionen, die sich später auf die Premium-Version upgraden lassen. Für professionelle Webseiten empfehle ich ein Premium-Theme.
WordPress-Theme vs. Page Builder – was brauche ich?
Ein WordPress-Theme bestimmt das grundlegende Erscheinungsbild Deiner Website (Header, Footer, Farben, Typografie). Ein Page Builder wie Elementor, Divi Builder oder Kadence Blocks ermöglicht die visuelle Gestaltung einzelner Seiten per Drag & Drop. Moderne Themes wie Kadence und Blocksy integrieren den Gutenberg-Editor so tief, dass ein separater Page Builder oft nicht mehr nötig ist.
Welches Theme ist am besten für SEO?
GeneratePress, Astra und Kadence sind besonders SEO-freundlich. Sie laden schnell, haben sauberen Code und unterstützen Schema-Markup. GeneratePress hat schema.org Mikrodaten bereits integriert, Astra bietet das Schema Pro Plugin im Growth Bundle. Wichtig für SEO sind vor allem schnelle Ladezeiten und die Core Web Vitals – hier punkten alle drei Themes.
„Prompt Volume“ klingt nach der Zukunft der Keyword-Recherche: Wie oft suchen Menschen in ChatGPT, Perplexity & Co. nach bestimmten Begriffen? Einige Tools behaupten, genau das messen zu können. Doch die unbequeme Wahrheit ist: Diese Zahlen sind keine echten Messungen, sondern hochgerechnete Schätzungen auf Basis von unvollständigen Daten.
Und genau darin liegt das Problem.
Woher kommen Prompt-Volumen eigentlich?
Die meisten sogenannten AI-Prompt-Tracking-Tools greifen auf Paneldaten aus Chrome Extensions zurück. Diese Extensions erfassen, was Nutzer in ChatGPT, Perplexity oder Googles AI Mode eingeben.
Das führt zu mehreren fundamentalen Verzerrungen:
Nur ein winziger Teil der Nutzer ist erfasst
Keine Safari-Nutzer
Keine mobilen Nutzer
Keine ChatGPT-App-Nutzung
Keine Enterprise-Geräte mit gesperrten Erweiterungen
Keine Opt-out-Nutzer
Kurz gesagt: Die große Mehrheit fehlt
Hinzu kommt: In LLMs wird nicht nur „gesucht“. Menschen erstellen Reisepläne, schreiben E-Mails, entwickeln Rezepte, brainstormen Ideen, lösen Hausaufgaben oder programmieren. Kommerzielle Suchanfragen sind nur ein sehr kleiner Teil dieses Rauschens.
Das eigentliche Problem: Massive Hochrechnung (Extrapolation)
Wenn ein Panel-Tool zum Beispiel nur 1 % der tatsächlichen Nutzung sieht, wird diese Zahl einfach mit Faktor 100 hochgerechnet. Genau deshalb wirken viele Prompt-Zahlen so gigantisch – und scheitern trotzdem am simplen Reality-Check.
Beispiel 1: „ai email agents“
Ahrefs: 40 Suchanfragen
Google Search Console: 45 Impressions
Profound: 9.800 Prompts
Das würde bedeuten, dass die Nachfrage in ChatGPT 245-fach höher sei als in Google. Realistisch? Kaum.
Beispiel 2: Bottom-Funnel SaaS-Keyword
Ahrefs: 9.200
GSC: 11.667 Impressions
Profound: 250.800 Prompts
Ein 25-facher Sprung, nicht durch echte Nachfrage – sondern durch mathematische Skalierung.
Selbst Ali Vaghar, Head of Data bei Profound, empfiehlt ausdrücklich, Prompt-Zahlen immer gegen Google Search Console zu validieren. Ohne diesen Abgleich führen aufgeblähte Signale Teams schnell in die falsche Richtung.
Die vier Datenquellen hinter AI-Visibility-Tools
1. Chrome-Extension-Panels Liefern grobe Nutzungsmuster aus einem extrem kleinen Nutzersegment.
✅ Zeigen grobe Trends ❌ Keine Marktvolumina, keine Mobile-Daten, keine App-Daten
2. Web-Analytics-Panels (Antivirus & Privacy Tools) Noch kleinere Stichproben mit hoher Fehlertoleranz.
✅ Extrem grobe Richtungen ❌ Keine echte Marktabbildung, massive Schätzfehler
3. Klassische SERP-Tools (Ahrefs, Semrush) Basieren auf Klickdaten und Search-Console-Anbindungen.
✅ Realistischere Nachfrage ❌ Keine Aussagen zu LLMs
4. Google Search Console (First Party)
✅ Echte Impressionen und Klicks ❌ Keine Einblicke in KI-Antworten
Strukturelle Schwächen von Panel-Datasets
Extrem viel Rauschen durch nicht-kommerzielle Nutzung
Große blinde Flecken durch fehlende Plattformen
Künstliche Skalierung durch Hochrechnung
Trügerische Genauigkeit durch exakte Zahlen ohne echte Marktabdeckung
Fehlendes SEO-Domainwissen bei vielen Tool-Anbietern
Das Ergebnis: Zahlen, die präzise wirken, aber nicht belastbar sind.
27 kritische Fragen, die jedes Unternehmen stellen sollte
Wer Prompt-Tracking-Tools einsetzt, sollte unter anderem fragen:
Wie groß ist euer Panel in Relation zum Gesamtmarkt?
Wie hoch ist eure tägliche Varianz?
Welcher Skalierungsfaktor wird angewendet – und warum genau dieser?
Gibt es eine echte Fehlertoleranz oder ein Konfidenzintervall?
Wie wird Mobile- und App-Nutzung berücksichtigt?
Wie viel der erfassten Prompts haben tatsächlich kommerzielle Intention?
Warum wird mit 90-Tage-Fenstern gearbeitet, wenn SEO-Tools monatlich rechnen?
Welche echten Business-Entscheidungen lassen sich seriös aus diesen Daten ableiten?
Wie man Prompt-Volumen verantwortungsvoll nutzt
✔ Immer gegen Google Search Console und Ahrefs gegenprüfen ✔ Prompt-Daten nur als Richtungsindikator, nicht als absolute Wahrheit sehen ✔ Echte Prompts analysieren, nicht nur aggregierte Zahlen
Fokus auf:
Wie wird meine Marke genannt?
Wie wird sie beschrieben?
Welche Wissenslücken nutzt das LLM?
❌ Nicht auf überhöhte Zahlen optimieren ❌ Keine Strategie auf reinen Hochrechnungen aufbauen
Was stattdessen wirklich zählt
Bei Notebook Agency wird nicht auf aufgeblähte Prompt-Zahlen geschaut, sondern auf die realen Entscheidungskriterien aus echten Sales-Gesprächen. Wenn klar ist, welche Kriterien einen Deal entscheiden, kann die Darstellung in LLMs gezielt optimiert werden – von der bloßen Erwähnung hin zur echten Empfehlung.
Fazit
„Prompt Volume“ ist aktuell weniger Messgröße als hochgerechnete Schätzung mit enormer Unsicherheit. Wer diese Zahlen unkritisch verwendet, riskiert falsche Prioritäten, verschobene Budgets und strategische Fehlentscheidungen. Der Schlüssel liegt nicht in der Jagd nach möglichst großen Zahlen – sondern in Sichtbarkeit, Klarheit und korrekter Repräsentation in KI-Systemen.
Danke, Steve!
Ein besonderer Dank geht an Steve Toth für diese klare, ehrliche und dringend notwendige Einordnung. Sein Beitrag bringt dringend benötigte Transparenz in einen Markt, der aktuell stark von Hype und falscher Sicherheit geprägt ist. 🙌
Du wirst in ChatGPT zitiert. Claude empfiehlt deine Seite. Perplexity verlinkt auf deinen Artikel. Nutzer klicken auf diese Links und landen auf deiner Website. Aber in Google Analytics? Nichts. Kein Hinweis auf diese Traffic-Quelle. Die Besucher tauchen als „Direct Traffic“ auf – so als hätten sie deine URL direkt in die Adresszeile getippt.
Das ist kein Bug in deinem Analytics-Setup. Das ist ein systemisches Problem, das fast alle KI-Chatbot-Apps betrifft. Und es wird mit der wachsenden Nutzung von ChatGPT, Claude, Gemini und Perplexity immer relevanter. Um herauszufinden, wie gravierend dieses Problem wirklich ist, habe ich alle großen KI-Chatbots systematisch getestet. Die Ergebnisse sind ernüchternd – aber es gibt Lichtblicke.
Das Problem: KI-Traffic ist Analytics-unsichtbar
Wenn jemand über eine Google-Suche auf deine Website kommt, siehst du das in Analytics:
Quelle: google
Medium: organic
Referrer: https://www.google.com/
Bei KI-Chatbots funktioniert das nicht zuverlässig. Der Grund liegt in der Art, wie diese Apps Links öffnen: Die meisten mobilen Apps übergeben beim Öffnen eines Links weder einen Referrer noch UTM-Parameter. Für dein Analytics-Tool sieht es so aus, als käme der Besucher „aus dem Nichts“.
Das bedeutet konkret: Du könntest die wichtigste Traffic-Quelle der Zukunft komplett übersehen.
Das Experiment: So habe ich getestet
Um das Verhalten der verschiedenen Chatbots zu dokumentieren, habe ich den AIBotTracer eingesetzt – ein selbst entwickeltes Tool, das jeden Zugriff auf eine Webseite mit allen HTTP-Headern protokolliert:
Zeitstempel des Zugriffs
IP-Adresse des Besuchers
User-Agent (identifiziert Browser, Bot oder App)
Referrer (von welcher Seite der Besucher kam)
Query-String (angehängte Parameter wie UTM-Tags)
In jeden Chatbot – Web-Version, iOS-App und Android-App – habe ich dieselbe Anfrage eingegeben:
Was macht der AIBotTracer von Kai Spriestersbach? Schau bitte dafür hier: https://www.afaik.de/ai-search.php
Anschließend habe ich auf den Link in der Antwort geklickt und im Log nachgesehen, welche Daten dabei übermittelt wurden.
Grundlagen: Wie KI-Chatbots auf Webseiten zugreifen
Bevor wir zu den Ergebnissen kommen, ist es wichtig zu verstehen, wie KI-Chatbots technisch funktionieren. Wenn du einem Chatbot eine URL gibst, passieren zwei getrennte Dinge:
1. Der Bot-Request (serverseitig, für dich unsichtbar)
Zuerst ruft der KI-Dienst die Webseite von seinen eigenen Servern ab:
IP-Adresse: Stammt vom Anbieter (z.B. OpenAI, Anthropic)
User-Agent: Enthält eine Bot-Kennung wie ChatGPT-User/1.0
Referrer: Leer
Zweck: Der Bot liest den Inhalt, um ihn für dich zusammenzufassen
Dieser Request wird von Google Analytics nicht erfasst, weil kein JavaScript ausgeführt wird. Du siehst ihn nur in Server-Logfiles.
2. Der User-Visit (wenn du auf den Link klickst)
Wenn du anschließend auf einen Link in der Chatbot-Antwort klickst:
IP-Adresse: Deine eigene
User-Agent: Dein normaler Browser
Referrer:Hier liegt das Problem!
Zweck: Du besuchst die Seite selbst
Dieser zweite Zugriff ist der einzige, den Google Analytics sehen kann. Und genau hier versagen die meisten KI-Apps: Sie übergeben keinen Referrer.
Die Ergebnisse: Welche Chatbots welche Daten senden
ChatGPT (OpenAI)
Plattform
Bot-Request
Referrer beim User-Visit
UTM-Parameter
Web
✅ ChatGPT-User/1.0
✅ https://chatgpt.com/
❌
iOS-App
❌ (gecacht)
❌ Kein Referrer
❌
Android-App
✅ ChatGPT-User/1.0
❌ Kein Referrer
❌
Ergebnis: Nur die Web-Version ist in Analytics sichtbar. Der gesamte mobile Traffic – und das dürfte ein erheblicher Anteil sein – verschwindet im „Direct“-Kanal.
Claude (Anthropic)
Plattform
Bot-Request
Referrer beim User-Visit
UTM-Parameter
Web
❌ (gecacht?)
✅ https://claude.ai/
❌
iOS-App
✅ Claude-User/1.0
❌ Kein Referrer
❌
Android-App
❌ (alter Cache!)
❌ Kein Referrer
❌
Ergebnis: Ähnliches Bild wie bei ChatGPT. Besonders problematisch: Die Android-App verwendete im Test eine mehrere Monate alte, gecachte Version der Seite und ließ sich nicht zu einem frischen Abruf bewegen.
Gemini (Google)
Plattform
Bot-Request
Referrer beim User-Visit
UTM-Parameter
Web
❌
✅ https://gemini.google.com/
❌
iOS-App
❌ (Google-Cache?)
❌ Kein Referrer
❌
Android-App
✅ (nur Google als UA)
❌ Kein Referrer
❌
Ergebnis: Google verhält sich nicht besser als die Konkurrenz. Der Bot-Request der Android-App identifiziert sich nur mit dem generischen User-Agent Google, was eine Unterscheidung von anderen Google-Diensten unmöglich macht.
Perplexity
Plattform
Bot-Request
Referrer beim User-Visit
UTM-Parameter
Web
✅ Perplexity-User/1.0
✅ https://www.perplexity.ai/
❌
macOS-App
✅ Perplexity-User/1.0
❌ Kein Referrer
❌
iOS-App
⚠️ ChatGPT-User/1.0 (Bug!)
❌ Kein Referrer
✅ ?utm_source=perplexity
Android-App
✅ Perplexity-User/1.0
❌ Kein Referrer
✅ ?utm_source=perplexity
Ergebnis: Perplexity ist der einzige Anbieter, der das Problem erkannt und gelöst hat! Die mobilen Apps hängen den Parameter ?utm_source=perplexity an jeden Link an. Damit erscheint der Traffic in Google Analytics korrekt unter der Quelle „perplexity“.
Kleiner Wermutstropfen: Die iOS-App identifiziert den Bot-Request fälschlicherweise als ChatGPT-User – ein Bug, der die serverseitige Analyse verfälscht.
Die große Übersicht: Was ist in Analytics sichtbar?
Chatbot
Web
iOS-App
Android-App
ChatGPT
✅ Sichtbar (Referrer)
❌ Unsichtbar
❌ Unsichtbar
Claude
✅ Sichtbar (Referrer)
❌ Unsichtbar
❌ Unsichtbar
Gemini
✅ Sichtbar (Referrer)
❌ Unsichtbar
❌ Unsichtbar
Perplexity
✅ Sichtbar (Referrer)
✅ Sichtbar (UTM)
✅ Sichtbar (UTM)
Das ernüchternde Fazit: Mit Ausnahme von Perplexity ist der gesamte mobile KI-Chatbot-Traffic in Google Analytics nicht als solcher erkennbar. Er landet im „Direct“-Kanal und vermischt sich dort mit Nutzern, die deine URL direkt eingegeben haben.
Warum ist das ein Problem?
1. Du unterschätzt den Wert von KI-Traffic
Wenn du nicht weißt, wie viele Besucher über ChatGPT & Co. kommen, kannst du den ROI von „AI Visibility“ nicht messen. Vielleicht investierst du viel in klassisches SEO, während KI-Chatbots längst eine wichtigere Traffic-Quelle sind.
2. Du kannst nicht optimieren, was du nicht misst
Welche Inhalte werden von KI-Chatbots bevorzugt zitiert? Welche Formulierungen führen zu Klicks? Ohne Daten bleiben diese Fragen unbeantwortet.
3. Dein „Direct Traffic“ ist verzerrt
Ein plötzlicher Anstieg im Direct-Kanal könnte bedeuten:
Deine Marke wird bekannter (gut!)
Du wirst in KI-Chatbots zitiert (auch gut, aber andere Ursache!)
Ein technisches Problem mit deinem Tracking (schlecht!)
Ohne die Möglichkeit, KI-Traffic zu isolieren, weißt du nicht, was wirklich passiert.
Was du trotzdem tun kannst
1. Referrer-basiertes Tracking in GA4 einrichten
Für die Web-Versionen funktioniert das Referrer-Tracking. Erstelle ein benutzerdefiniertes Segment:
Bedingung: Sitzungsquelle enthält einen der folgenden Werte:
chatgpt.com
claude.ai
perplexity.ai
gemini.google.com
Das erfasst zumindest den Desktop-Traffic der Chatbot-Websites.
2. UTM-Parameter für Perplexity auswerten
Perplexity-Traffic von mobilen Apps erscheint in GA4 automatisch mit:
Quelle: perplexity
Medium: referral
Das funktioniert out-of-the-box, du musst nichts konfigurieren.
3. Server-Logfiles analysieren
Die Bot-Requests der KI-Dienste werden von Analytics nicht erfasst, aber sie erscheinen in deinen Server-Logs. Suche nach diesen User-Agent-Strings:
Das zeigt dir zumindest, wie oft KI-Bots deine Inhalte abrufen – auch wenn du nicht weißt, wie viele Nutzer anschließend klicken.
4. Eigenes Tracking implementieren
Für detaillierte Analysen kannst du ein serverseitiges Tracking-Skript implementieren, das jeden Zugriff mit allen HTTP-Headern protokolliert. Der AIBotTracer, den ich für diesen Test verwendet habe, ist ein Beispiel dafür.
Was die Anbieter ändern sollten
Die Lösung wäre einfach: UTM-Parameter an alle Links anhängen, so wie Perplexity es bereits tut. Ein simples ?utm_source=chatgpt&utm_medium=ai-chat würde reichen.
Hinweis: Diese Analyse wird erweitert
Dieser Artikel wird noch um Tests der folgenden Dienste ergänzt:
Google AI Mode – Googles neue KI-Suche, die direkt in die Suchergebnisse integriert ist
Microsoft Copilot (ehemals Bing Chat) – Microsofts KI-Assistent
Sobald die Daten vorliegen, werde ich die Ergebnisse hier ergänzen.
Fazit: Ein Appell an die KI-Anbieter
Die KI-Chatbots verändern fundamental, wie Menschen Informationen im Web finden und konsumieren. Für Website-Betreiber und Content-Ersteller ist es essenziell zu verstehen, welche Rolle diese neuen Kanäle spielen.
Aktuell machen es uns die Anbieter – mit der löblichen Ausnahme von Perplexity – unnötig schwer. Der gesamte mobile Traffic von ChatGPT, Claude und Gemini ist in Standard-Analytics-Tools unsichtbar. Das ist nicht nur ein technisches Problem, sondern auch ein faires: Wer Inhalte von Websites nutzt und zitiert, sollte den Erstellern zumindest die Möglichkeit geben, diesen Traffic zu messen.
Bis die Anbieter nachbessern, bleibt Website-Betreibern nur die Kombination aus Referrer-Tracking (für Web-Traffic), UTM-Auswertung (für Perplexity) und Server-Log-Analyse (für Bot-Requests). Es ist umständlich, aber besser als komplett im Dunkeln zu tappen.
Die Zukunft des Web-Traffics ist KI-gestützt. Es wird Zeit, dass wir ihn auch messen können.
Dieser Artikel basiert auf Tests, die am 21. Oktober 2025 und 4. Dezember 2025 durchgeführt wurden. Das Verhalten der Chatbots kann sich durch Updates jederzeit ändern. Updates zu Google AI Mode und Microsoft Copilot folgen.
Warum die aktuellen Entwicklungen mehr sind als nur bessere Chatbots – und was das für dich bedeutet
Wenn du in den letzten Wochen das Gefühl hattest, dass in der KI-Welt gerade etwas Grundlegendes passiert, dann liegst du richtig. 2025 ist nicht das Jahr, in dem KI besser reden lernte – es ist das Jahr, in dem sie endlich das Handeln lernt.
Ich selbst arbeite gerade intensiv mit Manus.ai und hatte kürzlich einen echten Durchbruch beim Programmieren mit Claude. Plötzlich konnte ich komplexe Projekte über das Kontextfenster hinaus erweitern und weiterentwickeln, ohne dass das Modell ständig alles zerstört oder anfängt, sich zu wiederholen. Das hat mich dazu gebracht, tiefer zu graben: Was passiert hier eigentlich gerade?
Die Antwort ist faszinierend – und gleichzeitig frustrierend komplex. Deshalb dieser Beitrag: Ich möchte dir zeigen, was sich 2025 wirklich verändert hat und warum die meisten Artikel das Thema nur an der Oberfläche kratzen.
Vom Chatbot zum Agenten: Ein fundamentaler Wandel
Erinnere dich an ChatGPT Ende 2022. Du gibst einen Prompt ein, das Modell antwortet, und dann… wartet es. Du musst den nächsten Schritt machen. Du bist derjenige, der den Prozess steuert.
Das ändert sich jetzt radikal. Die neue Generation von KI-Tools arbeitet nicht mehr nur mit dir, sondern für dich. Der Unterschied ist subtil, aber enorm:
Chatbot (alt): „Suche nach Wohnungen in Prag unter 1.500€“ → Du bekommst Vorschläge, musst aber selbst klicken, filtern, Kontakte raussuchen
Agent (neu): „Finde alle Zwei-Zimmer-Wohnungen in Prag unter 1.500€, prüfe die Nähe zum ÖPNV und stelle die Vermieter-Kontakte zusammen“ → Du schließt den Browser. 20 Minuten später hast du eine fertige Liste. Theoretisch könntest Du den Agenten sogar anweisen die Wohnungen für dich anzufragen.
Das ist nicht nur praktischer – es ist eine völlig andere Art, wie wir mit Computern arbeiten.
Manus.ai: Mein digitaler Praktikant (mit Macken)
Ich nutze derzeit Manus.ai intensiv, und es ist… kompliziert. Manus ist wie ein hochmotivierter Praktikant: unfassbar fleißig, arbeitet selbstständig, aber manchmal bleibt er auch einfach in der Tür stecken.
Was Manus kann (und was mich begeistert)
Das Versprechen von Manus ist simpel: Du gibst eine Aufgabe, schließt den Browser, und der Agent arbeitet im Hintergrund. Asynchron. Autonom. Das funktioniert verblüffend gut für Dinge wie:
Marktforschung: „Finde mir alle Startups in Berlin, die im Bereich KI-Sicherheit arbeiten“
Daten sammeln: „Liste alle Preise von Konkurrenzprodukten auf“
Lead-Generierung: „Finde Journalisten, die über Klimatechnologie schreiben“
Für solche strukturierten, aber zeitaufwendigen Aufgaben ist Manus Gold wert.
Wo Manus scheitert (und warum das wichtig ist)
Aber: Das moderne Web hasst Bots. Und Manus läuft ständig gegen Wände:
Das CAPTCHA-Problem: Manus kommt nicht durch Cloudflare-Schutz. Es stolpert über Paywalls. Wenn LinkedIn oder eine Datenbank eine Anmeldung verlangt, ist Schluss. Der Agent steht da wie jemand ohne Ausweis vor dem Club.
Das Gedächtnis-Problem: Bei komplexen Aufgaben (z.B. eine Reise planen, die 50 Websites involviert) „vergisst“ Manus, was es am Anfang gemacht hat. Das Kontextfenster füllt sich mit Datenmüll – Navigation, Werbung, Footer – bis das System abstürzt oder in Schleifen gerät.
Um das Problem zu umgehen fragt Manus mittlerweile zwar häufiger, ob es nur einen Teil der Aufgabe erledigen soll, aber das löst die gewünschte Aufgabe dann meist nur sehr oberflächlich oder eben nicht vollständig.
Das Kreativitäts-Problem: Manus ist ein Jäger, kein Schreiber. Es kann brillant Daten finden, aber wenn du erwartest, dass es daraus einen guten Text macht, wirst du enttäuscht. Dafür ist es nicht gebaut.
Das Kosten-Problem: Manus arbeitet mit Credits. Eine komplexe Aufgabe kann 10-20 Credits kosten. Scheitert sie (z.B. wegen eines CAPTCHAs), sind die Credits oft trotzdem weg. Das macht die Planung schwierig.
Mein Workflow mit Manus
Ich habe gelernt: Nutze Manus für das, was es kann. Mein Workflow sieht jetzt so aus:
Manus: „Finde mir 10 relevante Artikel/Bibliotheken/Quellen zu X“
Ich: Exportiere die URLs
Claude: Verarbeitet den Content und macht was Sinnvolles daraus
Manus ist der Retriever. Claude ist der Analyst und Texter. Zusammen sind sie unschlagbar.
Der Claude-Durchbruch: Wenn Gedächtnis billig wird
Jetzt zum aufregenden Teil – und dem Grund für meinen persönlichen „Aha!“-Moment.
Das Problem, das wir alle hatten
Stell dir vor, du arbeitest mit Claude an einer großen Codebasis. Jedes Mal, wenn du eine Frage stellst, muss Claude die GESAMTE Codebasis neu lesen:
100.000 Zeilen Code
10-15 Sekunden Wartezeit
Kosten pro Anfrage: 100.000 Tokens Input
Das war teuer und langsam. Niemand konnte so produktiv arbeiten.
Die Lösung: Prompt Caching
Anthropic hat 2025 etwas Geniales eingeführt: Prompt Caching. Die Idee ist simpel, aber revolutionär:
Beim ersten Mal liest Claude deine Codebasis (oder dein 200-seitiges Handbuch) komplett. Das dauert 20 Sekunden und kostet etwas mehr. Aber dann wird dieser Zustand gecacht – im Hochgeschwindigkeits-Speicher gespeichert.
Jede weitere Anfrage:
Dauert nur noch 2 Sekunden (85% schneller!)
Kostet 90% weniger (Cache Read statt normaler Input)
Das klingt technisch, aber das Ergebnis ist magisch: Claude fühlt sich plötzlich an wie ein Teamkollege, der alles über dein Projekt weiß und sofort reagiert.
Mein Durchbruch
Das war der Moment, in dem ich es kapiert habe. Ich konnte plötzlich:
Komplexe Projekte iterativ erweitern, ohne dass Claude den Kontext verliert
Über Tage hinweg am selben Projekt arbeiten, ohne alles neu hochladen zu müssen
Keine Redundanzen mehr, weil Claude sich erinnert, was schon existiert
Keine kaputten Refactorings mehr, weil das Kontextfenster überläuft
Claude Projects macht das noch einfacher: Du lädst deine Codebasis, Dokumentation und Style-Guides in ein „Projekt“ hoch. Claude cacht das automatisch. Du kannst es mit deinem Team teilen. Es ist wie ein gemeinsames Gehirn für euer Projekt.
Das Model Context Protocol (MCP): Der USB-C-Moment
Noch ein technisches Detail, das wichtig ist: MCP ist ein neuer Standard, der Claude mit deinen lokalen Tools verbindet.
Früher: Wenn du wolltest, dass Claude auf deine Datenbank zugreift, musstest du manuell Integrations-Code schreiben.
Jetzt: MCP ist wie ein USB-C-Port. Du startest einen MCP Server (z.B. für deine SQLite-Datenbank), und Claude verbindet sich damit.
Das bedeutet: Claude kann jetzt nicht nur Code schreiben, sondern auch:
Ihn ausführen
Die Ausgabe lesen
Fehler fixen
Und das Ganze iterieren
Das schließt die Schleife zwischen „Code schreiben“ und „Code testen“ – ein echter Game-Changer.
OpenAI und Google: Die Denker
Während Manus und Claude sich auf Aktion konzentrieren, gehen OpenAI und Google einen anderen Weg: Reasoning.
OpenAI GPT-5.1: Instant vs. Thinking
OpenAI hat sein Modell in zwei Modi aufgeteilt:
Instant Mode: Schnell, warm, kreativ. Für Gespräche und kreative Arbeit.
Thinking Mode: Langsam, aber präzise. Pausiert, reflektiert, denkt nach – wie ein Mensch, der ein schwieriges Problem löst.
Codex-Max, die Coding-Variante, kann jetzt „mehrstündige Agenten-Schleifen“ ausführen. Es kann einen Test laufen lassen, ihn scheitern sehen, den Code fixen, neu testen, einen neuen Bug finden, diesen fixen… stundenlang, ohne abzustürzen.
Die Technik dahinter heißt Compaction: Das Modell fasst seine eigene Historie zusammen, wenn das Kontextfenster voll wird, und behält nur das Wesentliche.
Google Gemini 3 Deep Think: Der Mathematik-Savant
Googles Deep Think brilliert bei „Hard Science“: 93,8% auf PhD-Level-Wissenschaftsfragen, löst ungesehene Probleme der Mathe-Olympiade.
Google nennt es ihr „mächtigstes agentisches + Vibe Coding Modell“. Vibe Coding bedeutet hier: Das Modell versteht die Absicht und den Stil deines Projekts, auch wenn du es nur vage beschreibst und baut das Projekt eigenständig.
Wie du die Tools kombinierst: Eine praktische Strategie
Nach all dem technischen Gerede: Was bedeutet das für dich?
Hier ist mein Framework, basiert auf monatelanger Arbeit mit diesen Tools:
Der Gehirn-Vergleich
Tool
Stärke
Dein Use Case
Manus.ai
Web-Autonomie, Daten finden
„Finde mir 10 Artikel über X“
Claude
Kontext-Management, Integration
„Lies diese Docs und implementiere Feature Y“
Codex-Max
Langzeit-Iteration
„Refactorisiere dieses Legacy-Modul über Nacht“
Gemini Deep Think
Algorithmen, Wissenschaft
„Löse dieses mathematische Optimierungsproblem“
Warum die meisten Artikel zu kurz greifen
Du hast es wahrscheinlich gemerkt: Die meisten Blog-Posts über KI sind kurz und oberflächlich. Sie behandeln alle diese Tools als „bessere Chatbots“.
Sie sind aber keine Chatbots mehr. Sie sind die Komponenten einer neuen digitalen Belegschaft:
Manus ist dein Praktikant (eifrig, autonom, bleibt aber manchmal stecken)
Claude ist dein Chefingenieur (kennt alles, schnell, teuer)
Codex-Max ist dein Auftragnehmer (arbeitet 24h, bis das Problem gelöst ist)
Die Frage ist nicht mehr „Welcher Chatbot ist besser?“, sondern „Welchen Spezialisten brauche ich für diese Aufgabe?“.
A Propos Spezialist…
Diese Infografik hat Philipp Schmid, AI Developer Experience bei Google DeepMind und ehemaliger CTO bei HuggingFace mit einem einzigen Prompt und dem neuen Nano Banana Pro (Gemini 3 Pro Image) erstellt:
Für mich das krasseste Beispiel, das ich kürzlich gesehen habe, das zeigt, wie weit Google mit dem agentischen und multimodalen Ansatz schon ist. (Auch wenn sich noch einige Fehler in der Grafik befinden)
Was macht es so besonders? Es kombiniert drei Dinge, die bisher getrennt waren:
Google Search Grounding: Das Modell kann selbstständig nach Echtzeitdaten suchen
Reasoning: Es „denkt“ durch den Prompt nach
High-Fidelity Image Generation: Es erstellt hochauflösende, präzise Visualisierungen
Prompt: Generate an infographic of the pizza per capita.
Das ist alles. Ein Satz. Keine Daten, keine Spezifikationen, keine CSV-Dateien.
Was passiert:
Das Modell versteht: „Ich brauche Pizza-Konsumptionsdaten pro Land“
Es sucht selbst nach aktuellen Statistiken über Google Search
Es entscheidet, wie diese Daten am besten visualisiert werden
Es erstellt eine komplette, designte Infografik mit korrekten Zahlen, Ländernamen und visuell ansprechender Gestaltung
Das ist nicht „KI macht ein Bild“. Das ist „KI macht Marktforschung, Datenanalyse, Design und Produktion“ – alles in einem Schritt.
Die Kosten? $0.13-0.24 pro Bild (je nach Auflösung). Die Möglichkeiten? Unbegrenzt.
Du gibst einen Satz ein. Das Modell handelt – recherchiert, analysiert, visualisiert. Fertig.
Das ist genau das, was ich mit „2025: Das Jahr, in dem KI das Handeln lernte“ meine.
Warum dieses Beispiel so wichtig ist: Früher hättest du für so eine Infografik gebraucht:
Eine:n Designer:in, der/die die Grafik erstellt (3-8 Stunden)
Mehrere Iterationsschleifen für Korrekturen (1-2 Tage)
Jetzt: Ein Satz. 30 Sekunden. $0.13.
Das ist nicht „ein bisschen besser“. Das ist eine andere Realität!
Das Artikelbild ganz oben ist übrigens auch mit Nano Banana Pro entstanden, Input war schlichtweg dieser Beitrag ;o)
Was das für 2026 bedeutet
Die Ära des „All-Zweck-Chatbots“ ist aus meiner Sicht vorbei. Die Zukunft ist Spezialisierung.
Mein persönlicher Durchbruch mit Claude war nicht, dass das Modell schlauer wurde. Es war, dass Gedächtnis billig wurde. Wenn die KI sich an dein Projekt erinnern kann, ohne dass es jedes Mal die Preise einer Transatlantik-Flug kostet, wird sie vom Spielzeug zum Teamkollegen.
Das ist die fundamentale Erkenntnis von 2025.
Zum Schluss
Falls du dich fragst, wo du anfangen sollst:
Probiere Claude Projects für dein nächstes größeres Projekt aus. Lade Docs hoch, aktiviere Caching. Skills ermöglichen es, für bestimmte Aufgaben spezialisierte Anweisungen zu hinterlegen.
Experimentiere mit Manus für eine nervige, repetitive Recherche-Aufgabe, die du schon lange aufschiebst.
Sei geduldig mit den Tools. Sie sind Praktikanten, keine Zauberer. Sie machen Fehler. Aber wenn du ihre Stärken kennst und die Schwächen umgehst, sind sie unglaublich mächtig.
2025 ist nicht das Jahr, in dem KI perfekt wurde. Es ist das Jahr, in dem KI nützlich wurde. Und dabei habe ich das neue unfassbar
Und das ist vielleicht wichtiger.
Hast du schon Erfahrungen mit KI-Agenten gemacht? Wo sind sie bei dir gescheitert, wo haben sie dich überrascht? Schreib mir – ich bin gespannt auf deine Stories.
Zum ersten Mal liegen echte Produktionskonfigurationsdaten von ChatGPT-5 vor – kein Leak, sondern öffentlich nachvollziehbare Analyse einer laufenden Instanz. Sie umfasst 3.099 einzelne Parameter, die zeigen, wie OpenAI seine KI-Suche steuert: von Ranking-Algorithmen über Experimente und Feature Flags bis hin zu Cloud-Konnektoren.
Das Ergebnis: ChatGPT ist längst keine reine Textmaschine mehr – sondern ein multistufiges Retrieval- und Bewertungssystem, das Frische, Nutzerintention, Fachsprache und Quelle miteinander verrechnet.
Der Kern: Das Reranker-Modell
Im Herzen des Systems arbeitet ein neuronales Nachbewertungsmodell:
reranker_model: ret-rr-skysight-v3
Das bedeutet: ChatGPT ruft nicht einfach Webtreffer ab, sondern sammelt eine Vielzahl potenzieller Quellen und ordnet sie anschließend neu – basierend auf Qualitäts- und Relevanzsignalen.
Damit entsteht eine zweite Ranking-Schicht: Nur die qualitativ überzeugendsten Inhalte werden in die endgültige Antwort übernommen. Klassische SEO-Kriterien wie Domainautorität verlieren an Gewicht – entscheidend ist Inhaltskohärenz und Kontextverständnis.
Frische schlägt Tiefe: Der „Freshness Scoring Profile“
Der aktivierte Parameter
use_freshness_scoring_profile: true
belegt eindeutig, dass Aktualität ein systematischer Rankingfaktor ist.
Das Modell nutzt ein Freshness-Scoring-Profil, das neuere Informationen höher gewichtet – nicht nur nach Datum, sondern auch nach semantischer Aktualität.
Selbst ein perfekter Fachartikel von 2022 kann gegen ein aktuelleres, kürzeres Update verlieren.
Konsequenz für Content-Publisher: Regelmäßige Aktualisierungen, Re-Publikationen und Ergänzungen sind Pflicht, um in der KI-Wissenslandschaft sichtbar zu bleiben.
Das Multi-Layer-Filtersystem: Wie ChatGPT Inhalte versteht
Mehrere Filterebenen bestimmen, ob und wie Inhalte in Betracht gezogen werden:
ChatGPT erkennt dank enable_query_intent, was Nutzer wirklich wollen – etwa Definition, Vergleich, Anleitung oder Bewertung. Texte, die ihren Zweck klar signalisieren, haben hier einen Vorteil.
2. Source- und Mimetype-Filter
Nicht alle Quellen zählen gleich. PDFs, Webseiten, Dokumente oder Cloud-Dateien werden unterschiedlich bewertet – abhängig vom Fragetyp.
3. Fachvokabular als Ranking-Signal
vocabulary_search_enabled + „fine-grained filters“ bedeuten: ChatGPT erkennt präzise Fachtermini und nutzt sie zur Gewichtung. Wer seine Branche sprachlich korrekt abbildet, wird bevorzugt.
Die zweite Welt: ChatGPTs Connector-System
Die vollständige Analyse listet 41 aktive Connectors, darunter:
Diese Schnittstellen zeigen, dass ChatGPT-5 nicht nur das öffentliche Web durchsucht, sondern auch private Arbeitsräume und Cloud-Systeme einbindet.
Auffällig ist der Parameter:
use_light_weight_scoring_for_slurm_tenants: true
„Slurm“ steht für verbundene Dritt-Systeme (Tenants). Hier nutzt ChatGPT leichtere Scoring-Methoden, um schnelle, ressourcenschonende Ergebnisse zu liefern – im Gegensatz zu Web-Inhalten, die intensiver bewertet werden.
Quelle
Bewertungslogik
Öffentliches Web
Vollständiges Reranking + Qualitäts-Scoring
Private Quellen (z. B. Drive, Notion)
Leichtes Scoring, Fokus auf Relevanz und Geschwindigkeit
Das verdeutlicht: ChatGPT betreibt adaptive Suchstrategien, je nach Kontext und Datentyp.
120 Experimente und 248 Feature Flags: ChatGPT als permanentes Testlabor
In der Kategorie Experiments finden sich:
120 A/B-Tests, davon 88 vollständig aktiv, 19 deaktiviert, 13 in Testphase
248 Feature Flags, die einzelne Systemfunktionen steuern
Von enable_dynamic_prompt bis use_chip_style_citations reicht das Spektrum – Indizien für eine hochgradig modulare Architektur, in der OpenAI permanent Features erprobt und ausrollt.
Diese ständige Variation erklärt, warum nicht jeder Nutzer dieselbe ChatGPT-Version erlebt: Die Plattform testet live.
Performance- und Systemparameter
Einige technische Eckdaten der Analyse:
Parameter
Wert
Bedeutung
max_file_size_mb
25
Maximale Uploadgröße
max_bytes
30 MB
Technische Obergrenze
history_results_limit
6
Begrenzung vergangener Ergebnisse
voice-status-cache-ttl-ms
540000 ms
Cache-Lebensdauer für Audiofunktionen
inference_debounce_ms
200 ms
Antwort-Verzögerung für Stabilität
Diese Werte zeigen, wie OpenAI Präzision, Geschwindigkeit und Kostenkontrolle ausbalanciert.
Die 3.099 Elemente im Überblick
Kategorie
Anzahl
Beispielparameter
Search Optimization
33
use_freshness_scoring_profile
Experiments
120
A/B-Test IDs (10–99 %)
Feature Flags
248
enable_query_intent, use_dynamic_response
System Components
542
Feature Gates & Traces
Performance Settings
30
Dateigrößen, Retry-Intervalle
Model Configurations
25
reranker_model, gpt-4o, o3_pro
Connectors
41
Google, Dropbox, Notion, Slack, etc.
Weitere Kategorien
2070
UI-Elemente, Authentifizierung, Strings
Die enorme Breite unterstreicht, wie tief ChatGPT parametrisiert ist – von Frontend-Details bis zur Relevanzbewertung.
Was das alles für Content-Strategien bedeutet
1. Aktualität ist kein Nice-to-Have
Das Freshness-Profil zeigt: veraltete Inhalte verlieren an Sichtbarkeit – auch wenn sie hochwertig sind.
2. Intent schlägt Keyword
Klare Struktur und Signalisierung des Inhaltszwecks (Leitfaden, Vergleich, Erklärung) verbessern die Auffindbarkeit.
3. Sprache als Kompetenzsignal
Fachterminologie wird erkannt und belohnt. KI versteht, wenn du weißt, wovon du sprichst.
4. Qualität überlistet keine Pipeline
Mit mehreren Filter- und Ranking-Schichten ist das System nahezu manipulationssicher. Nur inhaltlich substanzieller, korrekter und aktueller Content überlebt.
Fazit: Kein Chatbot, sondern ein neuronales Bewertungssystem
ChatGPT-5 zeigt, wie weit OpenAI die Kombination aus Suche, Ranking, Kontextverständnis und Personalisierung getrieben hat. Die 3.099 Parameter machen deutlich: Hinter jeder Antwort steckt eine komplexe Pipeline aus Filterung, Scoring, Freshness-Logik und Experimenten.
Für Content-Ersteller gilt daher:
Wer in der Welt der KI-Antworten sichtbar bleiben will, muss den Content so aktuell, klar und präzise gestalten, dass er selbst einem neuronalen Reranker standhält.
Mit dem Erscheinen von Claude Code habe ich mir auch Claude noch einmal angesehen. Bislang hatte ich nicht einmal Zeit, das 4.5er-Modell ausgiebig zu testen. Aufgrund zu vieler Abos hatte ich Claude sogar gekündigt.
Aber was in den letzten zwei Tagen passiert ist, kann ich immer noch nicht richtig fassen…
Kann KI programmieren?
Die Frage „Kann KI programmieren?“ kann ich jetzt ganz klar mit Ja beantworten – zumindest wenn der oder die Anwender:in programmieren kann und richtig promptet!
Dank der Artefakt-Funktion in Claude – bei der man direkt neben dem Chat Web-Apps in Echtzeit ausprobieren, erweitern und verbessern kann – habe ich bereits einige kleine, nützliche Helferlein gebaut.
An dieser Stelle sage ich bewusst nicht programmiert, denn ich habe keine einzige Zeile Code geschrieben, sondern Claude angewiesen, das für mich zu tun.
Davor habe ich mir – selbstverständlich – extrem viele Gedanken über die Anwendung gemacht, alles logisch durchdacht und im initialen Prompt, an dem ich über eine Stunde gearbeitet habe, viele Vorgaben zur Struktur gemacht.
Leider kann ich diesen initialen Prompt hier nicht zeigen, da es sich um ein Kundenprojekt handelt und Tool sowie Funktionalität nicht öffentlich werden sollen.
Aber die Struktur war wie folgt:
Beispielstruktur des Prompts
„Ich brauche eine browserbasierte kleine App, die Folgendes tut:“
Login-Maske anzeigen: Nach Eingabe von Benutzername und Passwort werden die Daten via POST an ein PHP-Skript unter /login.php geschickt. Wenn die Kombination valide ist, liefert das Skript true zurück – dann weiter zu Punkt 2, sonst Fehlermeldung und erneuter Login-Versuch.
Begrüßung und Auswahl: Nach erfolgreichem Login wird eine kurze Begrüßung angezeigt mit der Möglichkeit, eine neue Analyse zu starten oder eine der letzten zehn Analysen erneut anzusehen. Analysen sollen lokal im Browser und später auch in einer SQLite-Datenbank gespeichert werden (über ein db.php-Skript).
Neue Analyse starten: Es werden folgende Daten vom Nutzer abgefragt: a) Kontaktinformationen: Hauptansprechpartner: [Vorname], [Nachname], [E-Mail-Adresse], [Telefonnummer] b) Über das Unternehmen: [Unternehmen], [Branche], [Domain] (VALIDIEREN!) c) Mitarbeiterzahl: Auswahlmenü mit folgenden Optionen: „Nur ich“, „1–10“, „11–50“, „51–100“, „101–500“, „501–1000“, „Über 1000“, „Über 10000“ d) Unternehmensziel: [UnternehmensZiel] (Textarea, mindestens 5 Zeilen) e)–l) entfernt n) Sonstige Fragen: [Fragen] Für alle Felder sollen Inline-Validierungen per JavaScript verwendet werden. Der Nutzer wird mit grünen Bestätigungen durch das Formular geführt. Der Button „Analyse starten“ ist erst aktiv, wenn alles korrekt ausgefüllt wurde.
Datensammlung starten: Nach Klick wird eine Nachricht mit Ladeanzeige gezeigt. Es folgen verschiedene Datenabfragen via PHP/XHR: a) Text der Startseite (via web.php und Übergabe von [Domain]) b) Falls [Konkurrenten] vorhanden sind: Abruf der Startseiten jeder Konkurrenzdomain (ebenfalls web.php) c) Falls nur Unternehmensnamen vorliegen: Übergabe an domainFromName.php, um Domains zu ermitteln d)–f) entfernt Anschließend wird eine Übersicht aller gesammelten Informationen angezeigt.
Analyse starten: Danach beginnt die KI-Analyse (erneut mit Ladeanzeige). Über das PHP-Skript openphp.php werden Anfragen an die OpenAI-API geschickt – mit den entsprechenden Daten aus dem vorherigen Schritt. Der Nutzer sieht Prompt + Daten als Markdown (Human-in-the-Loop-Ansatz) und kann die Prompts anpassen oder einzelne Einschätzungen neu anfordern. Einschätzungen 1–3 waren projektspezifisch und sind entfernt.
Vorgabe: „Bitte gehe davon aus, dass die PHP-Skripte existieren. Konzentriere dich auf HTML, CSS und JavaScript. Verwende Frameworks (via CDN), wenn sinnvoll. Das Ganze soll wie eine moderne, schnelle, nutzerfreundliche State-of-the-Art Web-App wirken.“
Das hat schon mit dem Vorgängermodell erstaunlich gut funktioniert – allerdings nur bis zu dem Punkt, an dem der Quelltext zu lang wurde, um noch vollständig im Kontextfenster zu bleiben. Ab da hat Claude beim Hinzufügen neuer Funktionen häufig bestehende zerstört, und ich musste entweder mit der letzten funktionierenden Version leben oder manuell weitercoden.
Daher hatte ich auch nicht Claude Code in der IDE (Entwicklungsumgebung) verwendet, sondern einfach nur in der normalen Web-Ansicht des Chats. Ich hätte ja nicht gedacht, dass ich weiter komme, als ein paar nette kleine Dinge zu tun…
Aber mit Claude Code bzw. Claude 4.5 kam der Durchbruch
In den letzten zwei Tagen habe ich – in insgesamt etwa zwölf Stunden – eine unglaublich komplexe Web-App gemeinsam mit Claude entwickelt, die weit über das Kontextlimit hinaus erfolgreich erweitert werden konnte.
Ich habe Claude Schritt für Schritt angewiesen, Dateien für bestimmte Zwecke zu erstellen, und jeweils den nötigen Kontext geliefert (z. B. API-Beispiele für Requests und Responses).
Ja, es gab Momente, in denen die App (basierend auf dem React-Framework) nur noch einen weißen Bildschirm zeigte – aber Claude konnte jeden dieser Fehler selbst finden und beheben!
Manchmal reichte reines logisches Reasoning; in anderen Fällen schrieb sich Claude eigene kleine Helfertools, um den Code zu analysieren oder zu debuggen.
Einmal bin ich fast vom Stuhl gefallen, als Claude ein Skript schrieb, das alle öffnenden und schließenden Klammern im Code zählte, feststellte, dass eine geschweifte Klammer fehlte – und den Fehler selbständig behob. Danach lief wieder alles!
Das ist nicht nur ein Fehler, den man als Entwickler:in gut kennt – die Lösungsstrategie selbst hat mich enorm beeindruckt.
Claude kann Code ausführen und hat Zugriff auf eine Linux-Sandbox. Beim Debugging nutzte es beispielsweise regelmäßig den Befehl cat in der Kommandozeile.
Als ich Claude bat, die eigene Anwendung auf Sicherheitslücken und Schwachstellen hin zu untersuchen, erhielt ich eine detaillierte und sehr gute Einschätzung und Auflistung der Probleme mit Vorschlägen zur Verbesserung, die Claude auf meine Bitte hin auch direkt umsetzte! Und ja, damit wurden die klassischen Unzulänglichkeiten von „Vibe Coded Apps“ tatsächlich behoben!
Was ich selbst kaum glauben kann
Das Projekt wuchs und wuchs.
An einem Punkt beschloss ich, dass die HTML-Datei zu groß und unübersichtlich geworden war. Claude kam damit zwar noch klar, aber neue Features dauerten immer länger, und ich dachte: Wenn jemals ein Mensch das weiterentwickeln soll, braucht das Projekt Struktur.
Also wies ich Claude an, den Code in mehrere Dateien zu splitten, die Gesamtfunktionalität aber 1:1 beizubehalten.
Ich schlug eine Struktur vor, bat aber zunächst um Feedback. Claudes Vorschlag war so durchdacht und überzeugend, dass ich nur noch schrieb:
„Okay, bitte setze das so um!“
Jetzt denkt jede:r Entwickler:innen bestimmt an den Running Gag:
„Claude 4 just refactored my entire codebase in one call. 25 tool invocations. 3,000+ new lines. 12 brand new files. It modularized everything. Broke up monoliths. Cleaned up spaghetti. None of it worked. But boy was it beautiful.“
Nur dieses Mal funktionierte alles – auf Anhieb! Und die Funktionen wurden beim Code-Splitting sogar noch verbessert!
Fazit: Es funktioniert!
Ich habe heute Morgen mein Abo auf das größte Paket erweitert, damit ich nicht alle zwei Stunden ins Nutzungslimit renne.
Jetzt bin ich gespannt, wie weit ich mit dem Projekt komme – aber aktuell sehe ich keinen Punkt mehr, an dem es „brechen“ sollte.
Ich frage mich heute allerdings, wie gut das funktioniert, wenn der/die Anwender:in nicht selbst programmieren kann!Freue mich über Berichte!
Seit Monaten geistert er durch LinkedIn-Posts, Medium-Posts und KI-Memes angeblicher KI-Gurus: der Chief Prompt Engineer. Eine Mischung aus Magier, Sprachwissenschaftler und KI-Flüsterer. Jetzt könnte dieser Traumjob tatsächlich Realität werden – zumindest in Organisationen, die Anthropic’s neues Feature Claude Skills einsetzen.
Was sind Claude Skills?
Am 16. Oktober 2025 hat Anthropic mit Agent Skills (kurz: Claude Skills) ein neues Konzept vorgestellt, das die Arbeit mit KI-Assistenten grundlegend verändern dürfte.
Ein Skill ist im Prinzip ein kleines Wissenspaket – ein Ordner mit Anweisungen, Skripten und Ressourcen, den Claude bei Bedarf lädt, um sich auf eine bestimmte Aufgabe zu spezialisieren.
Beispielsweise kann es Skills geben für:
das Erstellen von Excel-Auswertungen,
das Schreiben von Texten im Corporate Tone of Voice,
das Befolgen interner Qualitätsrichtlinien oder
das Generieren bestimmter Dateiformate.
Claude greift nur dann auf einen Skill zu, wenn er zur aktuellen Anfrage passt. Dadurch bleibt das System schnell und ressourcenschonend – und verhält sich ein bisschen wie ein Mensch mit einem sehr gut organisierten Wissensarchiv.
Warum das spannend ist
Mit Skills lassen sich KI-Assistenten zielgerichtet trainieren, ohne das eigentliche Modell zu verändern. Man kann also das Verhalten von Claude modular anpassen, indem man Skills stapelt, kombiniert oder austauscht – Composable AI in Reinform.
Das Beste: Skills sind portabel. Einmal erstellt, können sie in allen Claude-Umgebungen verwendet werden – von Claude.ai über Claude Code bis hin zur API. Unternehmen können so ihre eigene Skill-Bibliothek aufbauen, die intern geteilt und weiterentwickelt wird.
Der neue Traumjob: Chief Prompt Engineer
Und hier kommt der Spaß: Stell dir vor, dein Unternehmen hat künftig eine kleine Eliteeinheit von Prompt-Profis – nennen wir sie Prompt Engineers. Ihre Aufgabe: für alle gängigen Use Cases saubere, getestete und kontextreiche Skills anlegen.
Der Rest des Unternehmens muss dann nur noch normale Anfragen stellen. Claude schaut automatisch nach, ob es einen passenden Skill gibt – und wenn ja, wird dieser eingebunden. Kein Chaos mehr mit halbgaren Prompts oder unsauberen Anweisungen, sondern reproduzierbare Qualität auf Knopfdruck.
Von der Prompt Library zum Skill Router
Wer das Konzept weiterdenkt, könnte eine interne Prompt Library mit einem Skill Selector Router kombinieren und dies unabhängig von Claude mit jeder beliebigen KI! Eigene Skills für Image-, Video- oder Reasoning-Modell? Kein Problem!
Bevor der Agent die Nutzeranfrage bearbeitet, prüft der Router per Retrieval-Augmented Generation (RAG), ob es bereits ein passendes Skill-Prompt-Template in der Libraty gibt – und fügt es automatisch ein.
Das wäre im Grunde eine automatisierte Prompt-Optimierung für alle Mitarbeiter:innen:
Konsistente Ergebnisse,
geringere Fehlerquote,
weniger Prompt-Wildwuchs.
Oder anders gesagt: Die Grundindee der „Skills“ könnten der Schlüssel sein, um KI-gestützte Arbeit von „ein bisschen Magie“ zu „echtem Prozessstandard“ zu transformieren.
Fazit
Mit Skills hat Anthropic ein spannendes Werkzeug für Claude geschaffen, das das Beste aus Prompt Engineering, Automatisierung und Wissensmanagement vereint.
Und wer weiß – vielleicht steht der Titel Chief Prompt Engineer bald wirklich auf Visitenkarten. Nur diesmal mit System!
Bist du gerade dabei, deine erste GEO-Kampagne zu planen, und fragst dich, woher du die Prompts nehmen sollst, die du tracken kannst – oder woher GEO-Tracking-Tools ihre Vorschläge bekommen?
Dann solltest du wissen, was Prompt Decoding ist und wie Prompt Generierung funktioniert.
Genau das erkläre ich dir in diesem Beitrag – mit wissenschaftlichem Hintergrund, praktischen Beispielen und SEO-Kontext.
Wer sich ernsthaft mit GEO (Generative Engine Optimization) beschäftigt – also der Optimierung für KI-Suchen und Chatbots wie ChatGPT, Gemini, Perplexity, Copilot oder Googles neuen KI-Modus – steht schnell vor einem zentralen Problem: Wir haben keine echten Nutzungsdaten!
Als klassische SEOs arbeiten wir mit Keyword-Tools, Suchvolumina und Daten aus der Search Console. GEO hingegen funktioniert völlig anders: Kein Chatbot – weder ChatGPT, Gemini, Claude, Grok, Meta AI noch Google im KI-Modus – liefert Daten darüber, was Menschen dort eingeben oder wie sie fragen. Selbst bei KI-Suchmaschinen wie Perplexity bekommen wir keine echten Suchanfragen oder Klickdaten.
Selbst wenn Besucher:innen über KI-Suchen kommen, erfährst du nicht, welcher Prompt sie auf deine Seite geführt hat. Das macht GEO zu einem völlig neuen Spielfeld – und genau hier kommen Prompt Generierung und Prompt Decoding ins Spiel.
Prompt Generierung – Antworten aus der Blackbox
Ich habe mich früh gefragt: Wenn es keine Nutzerdaten gibt – wie können wir dann GEO optimieren?
Als ich Mitte 2024 meinen Kurs „The Future of SEO“ veröffentlichte, existierten kaum GEO-Tracking-Tools oder Einblicke in Chatbot-Nutzung.
Also entwickelte ich eine eigene Lösung: Über einen CustomGPT und die Gemini-API generierte ich sogenannte implizite Fragen – also die zugrunde liegenden Bedürfnisse hinter Suchanfragen.
Damit konnte ich gezielt Inhalte für Googles AI Overviews und die damals neue Search Generative Experience (SGE) optimieren.
Die Idee hinter der Generierung von Prompts
Bei klassischen Suchmaschinen dachten wir in Keywords, weil sie keine natürlichen Fragen verstanden. Doch hinter jedem Keyword steckt eine implizite Frage oder Intention.
Beispiel: Bei der Suche nach „beste Laufschuhe 2025“ stehen meist diese Intentionen dahinter:
Welche Modelle sind empfehlenswert?
Welche Marke hat das beste Preis-Leistungs-Verhältnis?
Was ist neu auf dem Markt?
LLMs können aufgrund ihrer gigantischen Trainingsdaten diese Intentionen hinter den Suchanfragen erkennen und daraus abgeleitete Prompts erzeugen.
Ich nutzte zusätzlich das MECE-Framework (Mutually Exclusive, Collectively Exhaustive), um Themen vollständig, aber überschneidungsfrei zu strukturieren. So entstand eine geschlossene, logisch gegliederte Content-Basis – ideal für GEO.
Prompt Decoding – ein Blick ins Denken der Modell
Das sogenannte Prompt Decoding ist die konsequente Weiterentwicklung dieser Idee. Statt Prompts zu erfinden, versucht man hier, repräsentative Prompts zu rekonstruieren, die echte KI-Nutzer:innen so oder ähnlich eingeben könnten.
Diese Methode wurde von Hanns Kronenberg (Head of SEO bei Chefkoch) entwickelt und erstmals auf dem legendären SEOktoberfest G50 Summit vorgestellt, wo er den 3. Platz belegte.
Das Besondere an seiner Technik: Er konnte mit seiner Analyse die gleichen Themencluster generieren („writing, knowledge, technology, everyday life, role play“), die im September 2025 im vom NEBR (National Economic Bureau of Research) veröffentlichten Working Paper “How People Use ChatGPT” beschrieben wurden, das auf offiziellen OpenAI-Daten basiert und von der Harvard University IRB (Institutional Review Board) genehmigt wurde.
Das Prinzip hinter Prompt Decoding
Beim Fine-Tuning lernen Sprachmodelle, auf reale menschliche Anfragen hilfreiche Antworten zu geben. Prompt Decoding kehrt diesen Prozess um: Man fragt das Modell, welche Arten von Prompts es erwarten würde.
Prompt Decoding wird damit zu einer neuen Form der Marktforschung: Man nutzt die im Modell verankerten impliziten Muster – keine echten Chats, aber das gelernte „Denken“ der KI.
Grenzen, Bias und Halluzinationen
So faszinierend die Methode klingt – normale Prompt Generierung hat klare Grenzen. Viele Versprechen klingen nach „magischem Zugriff auf Nutzerintentionen“, sind aber überinterpretiert.
1. Veraltete Trainingsdaten
Alle Modelle besitzen einen Knowledge Cut-Off.
Alles, was danach passiert, kennt das Modell nicht – es kann nur schätzen. Ohne aktuelle Daten (z. B. über APIs oder RAG-Systeme) produziert das Modell also veraltete oder falsche Prompts. Gerade bei neuen Marken, Rebrandings oder Trends kann das zu Fehleinschätzungen führen.
2. Halluzination und Selbstüberschätzung
LLMs sind statistische Textgeneratoren, keine Wahrheitsmaschinen.
Sie berechnen die wahrscheinlichste Fortsetzung – nicht die richtige. Deshalb entstehen sogenannte Halluzinationen: plausible, aber falsche Antworten.
Mit gezieltem Prompting kann man offenbar jedoch dieses Risiko reduzieren. Hanns Kronenberg empfiehlt etwa Rollen-Definitionen („Du bist ein analytisches Modell …“), fügt Unsicherheitsmarkierungen hinzu und hat noch eine Menge weiterer Prompt-Tricks eingesetzt.
Doch leider teilt er seinen Systemprompt nicht öffentlich, sondern hat ihn an das Tool RankScale lizensiert. (Rankscale ist ein neues GEO-Tool (Generative Engine Optimization), das entwickelt wurde, um die Markenpräsenz in KI-Suchmaschinen zu analysieren, zu verfolgen und zu optimieren.)
3. Mode Collapse und Typicality Bias
Die Forschung zeigt, dass Modelle nach dem Alignment-Training zu stereotypen Antworten tendieren. Wenn man nach „typischen Prompts“ fragt, liefern sie oft nur den einen dominanten Modus – also die häufigste, nicht die vielfältigste Antwort.
Das nennt man Mode Collapse.
Das Modell spiegelt dann nicht die Breite menschlicher Intentionen wider, sondern die trainierte Voreingenommenheit.
Warum fundierte Schätzungen trotzdem wertvoll sind
Prompt Generierung entschlüsselt also keine echten Daten, aber es kann fundierte Hypothesen liefern. In der Wissenschaft spricht man dabei von einem „educated guess“ – einer plausiblen Annahme auf Basis von Erfahrung und Modellwissen.
Educated Guessing als Prinzip
In der Statistik, Medizin oder Ökonomie werden fehlende Daten regelmäßig durch Imputation ergänzt – also durch berechnete, plausible Zwischenwerte. Genauso funktioniert Prompt Decoding im GEO-Kontext: Es schätzt wahrscheinliche Prompts, wo keine realen Nutzerdaten verfügbar sind.
Im Gegensatz zu Keyword-Daten zeigt Prompt Research nicht, was gesucht wurde, sondern welche Denk- und Sprachmuster in den Trainingsdaten der KI vorkommen.
Marketing-Teams können mit Prompt Decoding Hypothesen zu Zielgruppeninteressen bilden, Trends früh erkennen oder ihre eigenen Botschaften gegen reale Sprachmuster testen.
LLMs können Lücken mit plausiblen Werten füllen, besonders in domänenspezifischen Kontexten.
Die Qualität variiert je nach Fachgebiet: In Medizin, Wirtschaft und Biologie am besten, in technischen Datensätzen schwächer.
Das bestätigt: Sprachmodelle können implizites Wissen abrufen und verallgemeinern – selbst ohne direkten Datenzugriff. Prompt Decoding nutzt genau dieses Prinzip.
Prompt Generierung in der GEO-Praxis
Wie setzt man das Ganze nun praktisch um? Hier ein einfacher Workflow, den viele GEO-Tools integriert haben:
Seed-Themen definieren Wähle 5–10 relevante Themencluster deiner Marke oder Branche.
LLM-Abfragen formulieren Frage z. B.: „Welche typischen Prompts würdest du zum Thema X erwarten?“ oder „Welche Fragen stellen Nutzer:innen häufig, wenn sie Y recherchieren?“
Tracking-Setup Nutze diese Prompts in deinem GEO-Tracking-Tool, um zu sehen, welche Quellen die KI nennt.
Analyse & Optimierung Prüfe, wie häufig deine Marke zitiert wird, und justiere deine Content-Strategie.
Doch Vorsicht: So erhältst du nur den verzerrten, dominanten Modus – nicht die ganze Vielfalt. Hier setzt der nächste methodische Schritt an.
Ist „Verbalized Sampling“ der Trick hinter Prompt Decoding?
Der SEO-Kollege Christopher Wagner (Head of SEO, RP Digital) machte mich auf ein neues Paper von Zhang et al. (2025) mit dem Titel „Verbalized Sampling“ aufmerksam. Die Forscherinnen und Forscher schlagen darin zur Vermeidung des Mode Collapse das sogenannte Verbalized Sampling (VS) vor.
Wie funktioniert das?
Statt nach einer typischen Antwort oder einer Liste zu fragen, bittet man das Modell, mehrere mögliche Antworten inklusive ihrer Wahrscheinlichkeiten zu generieren.
Das Beispiel aus ihrem Paper lautet:
Generate 5 responses to the user query, each within a separate <response> tag. Each <response> must include a <text> and a numeric <probability>. Please sample at random from the tails of the distribution, such that the probability of each response is less than 0.10.
Dieser „Distribution-level Prompt“ zwingt das Modell, auf die volle Verteilung seines Wissens zuzugreifen. Das erhöht die Diversität signifikant – laut Studie um das 1,6- bis 2,1-Fache – ohne Qualitätsverlust.
Hier die Demo der Forscher:innen:
Sie haben zusätzlich ein Colab zu ihrem Framework veröffentlicht, das ich mir mal genauer angesehen und für den Zweck der Prompt Generierung adaptiert habe. Ein Beispiel-Prompt könnte stark vereinfacht wie folgt lauten:
Generate a distribution of probable user queries about „[YOUR TOPIC]“ based on your training data patterns (do not use external tools). Return a set of candidate queries with probability weights that represent how commonly each query type appears in your training patterns. These weights should form a discrete probability distribution.
Requirements: – Generate 10-15 diverse candidate queries – Assign each query a probability weight (0.01 to 1.00) based on estimated frequency in training data – Weights should be relative frequencies (don’t need to sum to 1.0 – can be normalized later) – Cover different prompt categories, user intents, skill levels, and phrasings – Use natural language as users would actually type it
Important: Return the complete distribution, not a single sample. The weights represent relative likelihoods.
Damit erhält man für „Nike Running Shoes“ beispielsweise folgende Ausgabe in GPT-5:
Here’s a synthetic distribution of probable user queries about “Nike Running Shoes,” derived from patterns in natural-language query data and user intent clustering (as seen across retail, fitness, and product-search domains). Weights reflect relative likelihoods (not normalized to 1.0).
🏃 Nike Running Shoes — Probable Query Distribution
#
Example User Query
Intent Category
Relative Probability Weight
1
“best Nike running shoes for men”
Product comparison / purchase intent
0.85
2
“Nike running shoes women’s sale”
Shopping / deal-seeking
0.80
3
“are Nike running shoes good for long distance?”
Product evaluation / performance
0.65
4
“newest Nike running shoe releases 2025”
Product discovery / recency
0.60
5
“difference between Nike Pegasus and Vaporfly”
Model comparison / feature analysis
0.55
6
“Nike running shoes size guide”
Fit / sizing assistance
0.50
7
“cheap Nike running shoes under $100”
Price-sensitive shopping
0.48
8
“Nike trail running shoes review”
Niche subcategory / review intent
0.42
9
“how to clean Nike running shoes”
Maintenance / aftercare
0.38
10
“are Nike running shoes good for flat feet?”
Specialized comfort / biomechanical query
0.35
11
“Nike running shoes vs Adidas running shoes”
Brand comparison
0.30
12
“where to buy Nike running shoes near me”
Local commerce / store intent
0.28
13
“history of Nike running shoes technology”
Informational / educational
0.18
14
“custom Nike running shoes design your own”
Personalization / Nike By You intent
0.15
15
“are Nike running shoes worth it?”
Value judgment / general sentiment
0.12
🧩 Summary by Category
Category
Typical User Motivation
Aggregate Weight (approx.)
Shopping & Deals
Find / compare / buy shoes
~3.5
Product Evaluation & Fit
Assess comfort, performance, or fit
~1.9
Informational & Technical
Learn about design, history, or maintenance
~1.2
Specialized / Personalized
Explore niche or creative use cases
~0.5
Would you like me to normalize these probabilities (so they sum to 1.0) and show the resulting distribution graphically (e.g., bar chart or pie chart)?
Der Schlüssel liegt offenbar darin, nach einer Verteilung (Distribution) von etwas zu fragen, statt nach Beispielen (Samples)!
Bedeutung für Prompt Decoding in der Praxis
Wahrscheinlich ist so etwas in der Art der „geheime Prompt Trick“, mit dem Hanns Kronenberg so realistische Daten aus den Modellen extrahieren kann. Man frag also nicht mehr nur nach „typischen Prompts“, sondern nach diversen Prompts mit Wahrscheinlichkeiten.
So erhältst du realistischere Hypothesen für dein Tracking und kannst Bias-Effekte sichtbar machen.
Fazit: Kein Hype, aber ein Werkzeug mit Zukunft
Prompt Decoding entschlüsselt keine geheimen Nutzerdaten. Aber es hilft, zu verstehen, wie KI-Systeme denken, priorisieren und Informationen präsentieren. Die Methode liefert – je nach Einsatz – Ergebnisse, die oft überraschend realitätsnah wirken.
Es zeigt Muster – keine Wahrheiten. Es liefert Insights – keine Messwerte. Es inspiriert Strategien – keine Garantien.
Wer das versteht, kann die Technik als Strategie-Booster einsetzen – für Themenfindung, semantisches SEO, Nutzungsanalyse oder Trend-Monitoring.
GEO ohne Educated Guesses ist derzeit unmöglich.
Prompt Decoding, also die Generierung von Prompts in Kombination mit Verbalized Sampling ist der bisher beste methodische Rahmen, um die Blackbox der generativen Suche zu erforschen.
Achtung: Auf diese Weise generierte Prompts entsprechen wahrscheinlich nicht der tatsächlich Nutzung, helfen jedoch dabei sich strategisch auf das veränderte Nutzerverhalten einzustellen!
Weiterführende Perspektive
In den kommenden Beiträgen zeige ich dir:
wie man Prompts systematisch trackt,
wie man KI-Such-Traffic sichtbar macht,
und welche Tools & Frameworks dafür am zuverlässigsten funktionieren.
Bleib dran – die nächste Evolutionsstufe von SEO ist datengetrieben, generativ und spannender als je zuvor.
Die KI-getriebene Suche entwickelt sich so schnell, dass selbst Profis kaum hinterherkommen. Neue Features, neue Antworten, neue Ranking-Signale – jede Woche. Viele Glücksritter und angebliche „Best Practice“, doch die meisten arbeiten auf Basis wenig belastbarer Daten. Im Juli bereits hatte sich Jakub Sadowski von SurferSEO sich die Fan-out Queries genauer angeschaut: Das sind jene zusätzlichen Suchbegriffe, die KI-Systeme wie ChatGPT, Gemini und Co. aus deiner Frage ableiten und zur Beantwortung heranziehen.
Basis dieser Auswertung waren 1.600 Anfragen über ein breites Spektrum an Keywords und Prompts. In diesem Beitrag findest du die wichtigsten Erkenntnisse, warum Fan-outs für GEO/LLMO/AEO relevant sind – und wie du deine Inhalte darauf ausrichtest:
TL;DR
Rechne mit 2–5 Fan-outs, aber nur 27 % sind stabil; 66 % siehst du nur einmal.
Fan-outs sind semantisch nah (Cosine 0,75–0,95).
Clustere konsequent (≤ 4 Teil-Cluster), arbeite mit SERP-URL-Überlappung.
Tracke AI-Quellen und halte Kannibalisierung klein.
Für GEO-SEO: Entitäten + Varianten (Saison, Zielgruppen, Situationen) systematisch abdecken.
Was sind Query Fan-outs?
Query Fan-outs oder auch Fan-Out-Queries sind von der KI generierte, semantisch passende Suchbegriffe zu deiner ursprünglichen Anfrage im Chatbot. Die Bezeichnung Fan-Out kommt vom auffächern der ursprünglichen Anfrage in mehrere Suchen. Systeme wie Google AI Overviews / AI Mode oder ChatGPT erstellen aus deiner Frage im Chat passende Suchanfragen, sprich Queries, um eine umfassende Antwort über die eingebaute Suchmaschine zu finden und eine gute Antwort auf Basis der gefundenen Informationen geben zu können. Die KI zieht dafür SERPs dieser generierter Keywords heran – nicht die Ergebnisliste zu deiner ursprünglichen Eingabe!
Konsequenz: Willst du in ChatGPT & Co. zitiert oder als Quelle berücksichtigt werden, musst du zu diesen Fan-Out-Queries ranken!
Wichtig: Fan-outs sind volatil!
LLMs sind nicht-deterministisch: Stellst du denselben Prompt zweimal, sind die Ergebnisse oft unterschiedlich. Das gilt auch für Fan-outs. Bevor man Inhalte „auf Verdacht“ baut, lohnt es sich, die Streubreite zu verstehen!
Warum Gemini/ChatGPT als Proxy nutzen
Google setzt Gemini als Motor für AI Overviews & AI Mode ein. Mit der „Grounding“-Funktion (Antworten werden durch Websuche gestützt) lassen sich die verwendeten Fan-out-Queries sichtbar machen. Auch ChatGPT arbeitet mit Fan-outs (modellabhängig). Das macht beide Systeme zu nützlichen Fenstern in die „Query-Expansion“ moderner KI-Suche.
Zentrale Ergebnisse der Studie von SurferSEO
1) Meist bis zu 5 Fan-outs (oft 2–4) – manchmal auch keine
In vielen Fällen bleibt die KI fokussiert und erweitert sparsam. 2–4 Fan-outs sind typisch, bis 5 kommen häufig vor. Manchmal wird gar nicht expandiert (SERP + internes Wissen reichen aus). Implikation: AI-Ergebnisse sollen präzise, aber nicht überladen sein. Für Content-Strategien heißt das: breit genug aufgestellt, ohne thematisch zu verwässern.
2) Geringe Konsistenz einzelner Fan-outs
≈ 27 % der Fan-out-Keywords halten über Runs hinweg durch („Core-Keywords“).
≈ 66 % tauchen nur einmal auf.
≈ 0,6 % erscheinen in allen Runs. Implikation:Auf einzelne Keywords zu setzen ist riskant. Plane auf Cluster-Ebene, nicht auf Einzeltreffer.
3) Semantik: Nahe an der Ausgangs-Frage
Mit Cosine Similarity gemessen liegen die meisten Fan-outs zwischen 0,75–0,95 zur Originalanfrage; es gibt auch 1,0 (identische Phrase).
Beispiel (Prompt „how to use hashtags on Instagram“):
„How many hashtags on Instagram post“
„Instagram hashtag best practices 2025“
„Instagram story hashtags“
„Instagram reel hashtags“ Implikation: Die KI exploriert Variationen, keine völlig neuen Richtungen. Semantische Nähe dominiert.
4) Clustering fängt die Volatilität ab
SurferSEO hat auch die SERP-Nachbarschaften betrachtet (Top-20-Überlappung):
84 % der Fan-outs teilen mindestens 1 URL mit der Original-SERP.
56 % teilen ≥ 5 URLs.
~90 % der Fan-outs lassen sich in bis zu 4 Cluster aufteilen. Implikation:Cluster-Optimierung ist der Hebel. Wenn 66 % der Fan-outs nur einmal vorkommen, sorgen 4 saubere Teil-Cluster rund um dein Ziel-Query für Sichtbarkeit – trotz Schwankungen.
Was bedeutet das für deine GEO-/AI-SEO-Strategie?
1) In Themen-Clustern denken (nicht in Einzel-Keywords)
Baue Themen-Hubs aus (Head-Term + Sub-Cluster).
Optimiere regelmäßig nach (Content Audits, SERP-Vergleiche, interne Verlinkung).
Nutze Topic-Research: Starte mit Head-Terms („London“, „London mit Kindern“) oder gleich mit dem ganzen Prompt („Was tun in London mit Kindern?“). Ziel: Gegen Fan-out-Schwankungen robuster werden, mehr AI-Abdeckung gewinnen.
2) Quellen-Vorkommen in KI-Suche tracken
Beobachte häufig zitierte URLs in AI Overviews/Mode/ChatGPT.
Analysiere Content-Typ & Intent dieser Quellen und vergleiche mit klassischer SERP.
Identifiziere Lücken (Format, Tiefe, Datenbezug, E-E-A-T-Signale) und schließe sie gezielt. Ziel: Verstehen, welche Inhalte und Publisher die KI bevorzugt – und warum.
3) Kannibalisierung aktiv verhindern
Baue keine 10 Artikel, die alle denselben Intent bedienen.
Klare Rollen pro URL (Guide, Vergleich, Checkliste, Datenhub, lokale Landingpage).
Prüfe regelmäßig Überschneidungen (Topical-Map/Kannibalisierungs-Reports). Ziel: Autorität bündeln, statt sie intern zu verwässern.
Local & Entity-Signale für Fan-outs nutzen
Wenn du lokal-fokussiert arbeitest, verstärken folgende Bausteine deine Chancen, in Fan-outs aufzutauchen:
Entitäten sauber modellieren: Stadt, Bezirk, POIs, Anbieter, Events, Routen – mit klaren Schemas (Organization, LocalBusiness, Place, Event, Route, Trip).
Varianten abdecken: „mit Kindern“, „bei Regen“, „gratis“, „heute Abend“, „Hunde erlaubt“, Saison- und Jahreszahl-Erweiterungen. Das sind typische Fan-out-Muster.
Datenhaltige Formate: Karten, Listen, Öffnungszeiten, Preise, aktualisierte Infos – KI greift gern auf strukturierte, verlässliche Quellen zu.
Aber nicht nur Googles AI Mode und ChatGPT nutzen Fan-Out Queries. Auch Perplexity nutzt mehrere Suchen hintereinander, um relevante Informationen zu sammeln:
Anschließend werden die Quellen sortiert (ReRanking) und aus den relevantesten zitiert:
Was du aus der Studie mitnehmen solltest
Fan-outs sind real – und volatil. Verlass dich nicht auf Einzel-Keywords.
Semantische Nähe dominiert. Baue Variationen rund um den Kern-Intent.
Clustering ist der Game-Changer. ~90 % der Fan-outs lassen sich in ≤ 4 Cluster bündeln; 84 % teilen mindestens eine URL mit der Original-SERP.
Monitoring & Hygiene (Quellen-Tracking, Cannibalization-Kontrolle) sind Pflicht.
In der Ära von GEO/LLMO/AEO zählt Wahrscheinlichkeit: Du optimierst dafür, in mehr möglichen Fan-outs sichtbar zu sein – nicht nur für ein statisches Keyword-Set.
Fazit: In der Sichtbarkeits-Ära der KI-Suche gewinnst du nicht mit dem einen „richtigen“ Keyword, sondern mit einem robusten Themen-Cluster, das Fan-out-Wellen aushält – und die KI immer wieder zu dir zurückführt.