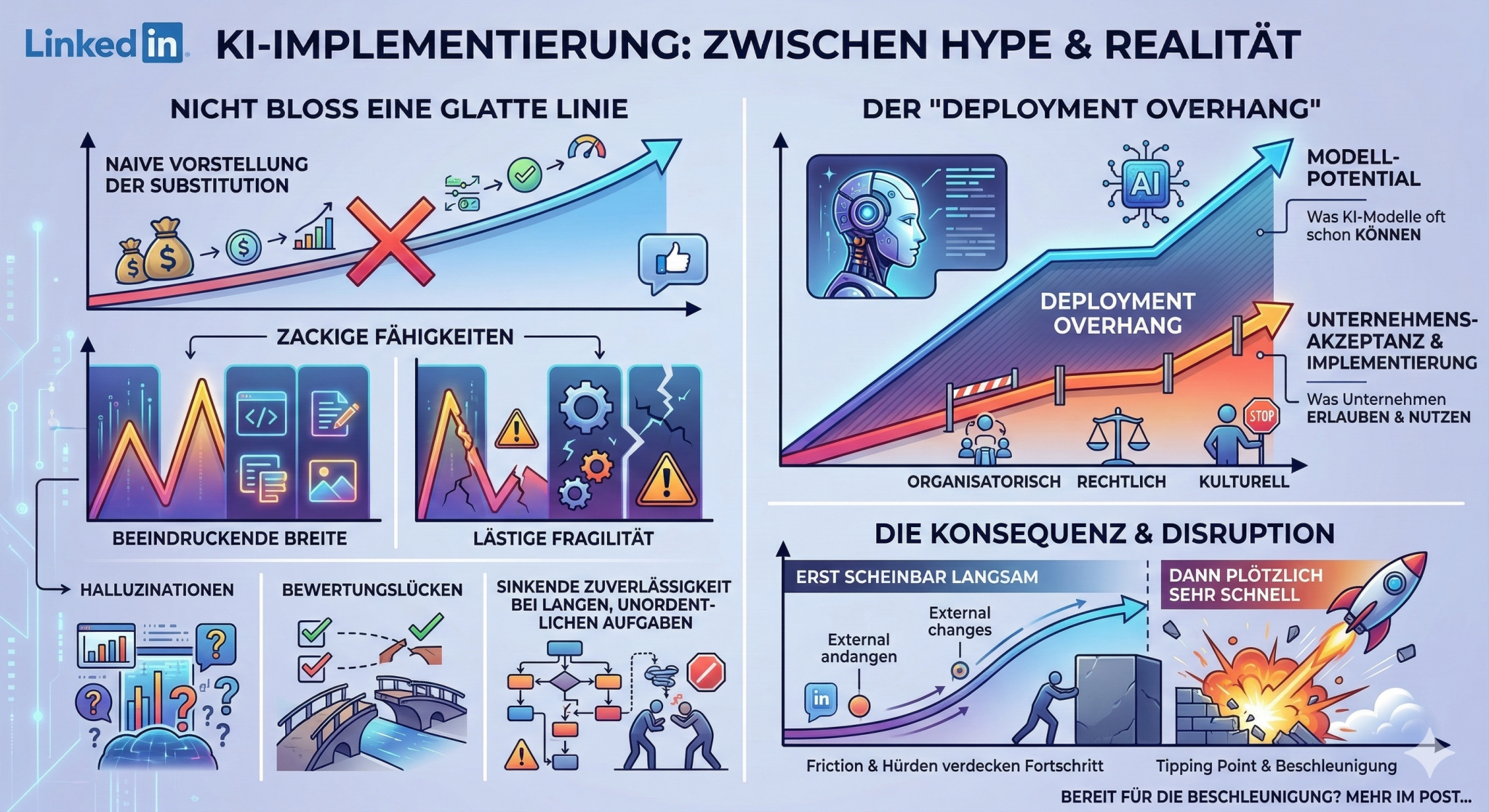
Die Diskussion um AI-Agenten hat sich verschoben. Vor einem Jahr klang vieles noch nach Modellvergleich: Welches LLM plant besser? Welches schreibt besseren Code? Welches halluziniert weniger? Inzwischen wird klarer: Die entscheidende Frage ist nicht nur, wie gut das Modell ist, sondern in welchem System es arbeitet.
Genau hier setzt Harness Engineering an.
Ein Agent ist eben nicht einfach ein Chatbot mit mehr Kontext. Sobald er Tools nutzen, Dateien ändern, Tests starten, Browser bedienen, Deployments vorbereiten oder Entscheidungen über mehrere Arbeitsschritte hinweg treffen soll, braucht er eine Umgebung, die ihn führt, begrenzt und überprüfbar macht. Der Harness ist diese Umgebung: Instructions, State, Verification, Scope und Session Lifecycle – also die Regeln, das Gedächtnis, die Prüfmechanismen, die Grenzen und die Übergaben, innerhalb derer ein Agent arbeitet. Das Projekt Learn Harness Engineering beschreibt diesen Ansatz als systematisches Design von Environment, State Management, Verification und Control Systems, um Coding Agents wie Codex oder Claude Code zuverlässiger zu machen.
Der Harness besteht selbst als fünf Subsystemen: Instructions, State, Verification, Scope und Session Lifecycle. Wichtig ist dabei die Formulierung: Das Modell entscheidet, welchen Code es schreibt; der Harness regelt, wann, wo und wie es schreibt. Der Harness macht das Modell also nicht klüger, sondern macht seine Arbeit kontrollierbarer und überprüfbarer.
Damit ist Harness Engineering mehr als „bessere Prompts schreiben“. Es ist der Übergang von Prompting zu Infrastruktur. OpenAI beschreibt diese Verschiebung sehr deutlich: In einer agentenorientierten Entwicklungswelt besteht die Arbeit des Engineering-Teams nicht mehr nur darin, selbst Code zu schreiben, sondern Umgebungen zu entwerfen, Intentionen zu spezifizieren und Feedback-Loops zu bauen, in denen Codex-Agenten zuverlässig arbeiten können. Ein zentrales Muster ist dabei: Das Repository wird zum „System of Record“, während AGENTS.md eher als Karte oder Inhaltsverzeichnis dient, nicht als allwissendes Handbuch.
Auch Anthropic argumentiert in eine ähnliche Richtung. In den Arbeiten zu long-running agents geht es nicht nur darum, ein Modell länger laufen zu lassen, sondern Fortschritt über Kontextfenster, Sessions und Teilaufgaben hinweg kontrollierbar zu machen. Dazu gehören Initialisierung, Feature-Listen, Übergabeartefakte, Browser-Validierung, QA-Agenten und explizite Verifikationsschleifen. Gleichzeitig zeigen diese Arbeiten auch die Grenze: Selbst bessere Harnesses stoßen an Decken, etwa wenn Evaluatoren zu großzügig urteilen, UI-Zustände nicht beobachtbar sind oder das System zwar viel schafft, aber nicht sicher weiß, ob es das Richtige geschafft hat.
Das macht die aktuelle Debatte so interessant: Harness Engineering ist einerseits eine der praktischsten Antworten auf die Unzuverlässigkeit von AI-Agenten. Es reduziert Kontextverlust, Scope Creep, ungeprüfte Annahmen, „fertig“-Behauptungen ohne Evidenz und gefährliche Tool-Nutzung. Andererseits darf man es nicht mit einer Sicherheitsgarantie verwechseln.
Ein Harness kann erzwingen, dass ein Agent Tests ausführt.
Er kann aber nicht garantieren, dass diese Tests die richtigen Dinge prüfen!
Er kann Rechte beschränken.
Er kann aber nicht automatisch erkennen, ob eine fachliche Entscheidung ethisch, rechtlich oder geschäftlich sinnvoll ist.
Er kann einen Agenten auditable machen.
Er kann ihn nicht unfehlbar machen!
Gerade deshalb ist die Sicherheitsdiskussion so wichtig. OWASP beschreibt für AI-Agenten Risiken, die über klassische Prompt Injection hinausgehen: Tool Abuse, Privilege Escalation, Memory Poisoning, Excessive Autonomy, Goal Hijacking und Cascading Failures. Sobald ein Agent nicht nur Text erzeugt, sondern Handlungen ausführt, reicht es nicht mehr, ihn gut zu instruieren. Man muss ihn wie einen potenziell fehlbaren, potenziell manipulierbaren Prozess behandeln – mit Least Privilege, Isolation, Monitoring, Approval Gates und Rollback.
Der entscheidende Punkt ist also: Ein guter Harness macht AI-Agenten nicht magisch zuverlässig. Er macht sie sichtbar, begrenzt, prüfbar, reversibel, eskalierbar und lernend. Das ist enorm viel. Es ist wahrscheinlich der Unterschied zwischen „ein Modell macht irgendetwas“ und „ein Agent kann produktiv in einem echten Workflow arbeiten“. Aber es bleibt ein Unterschied zwischen kontrollierter Autonomie und garantierter Korrektheit.
Wer AI-Agenten produktiv einsetzen will, sollte deshalb nicht nur fragen: „Welches Modell nehmen wir?“ Die bessere Frage lautet: Welche Arbeitsumgebung bauen wir, damit Fehler früh sichtbar werden, Schaden begrenzt bleibt und menschliche Urteilskraft dort eingreift, wo sie wirklich gebraucht wird?
Denn am Ende ist der Harness kein Schutzengel. Er ist ein Betriebssystem für begrenzte Autonomie.
Was ein optimaler Harness sehr gut kann
Er kann viele typische Agentenfehler fast mechanisch reduzieren: Kontextverlust, „ich bin fertig“-Behauptungen ohne Beweis, Scope Creep, Arbeiten auf kaputtem Ausgangszustand, vergessene Tests, fehlende Handoffs. Die mitgelieferte AGENTS.md-Vorlage verlangt zum Beispiel, vor Codeänderungen den Arbeitsstand zu lesen, init.sh auszuführen, Smoke- oder E2E-Verifikation zu starten und bei fehlschlagender Baseline erst den Ausgangszustand zu reparieren.
Er kann auch verhindern, dass „fertig“ nur ein Sprachakt ist. Die Vorlage definiert Done erst dann, wenn Zielverhalten implementiert ist, die Verifikation tatsächlich lief, Evidenz dokumentiert wurde und das Repository wieder vom Standardpfad startbar ist.
Und er kann Architektur, Security- und Qualitätsregeln teilweise aus dem menschlichen Gedächtnis in mechanische Gates verschieben. OpenAI beschreibt genau diesen Weg: kurze AGENTS.md als Router, Repo-Dokumente als System of Record, mechanische Linter, strukturelle Tests und Custom-Lints, um Invarianten durchzusetzen.
Die harte Grenze: Der Harness kann nur prüfen, was spezifiziert, beobachtbar und testbar ist
Die wichtigste Grenze ist das Oracle-Problem: Woher weiß das System, was richtig ist?
Ein Harness kann sagen: „Führe Tests aus.“ Er kann nicht automatisch sicherstellen, dass die Tests vollständig, relevant und richtig sind. Er kann sagen: „Arbeite nur an Feature X.“ Er kann nicht garantieren, dass Feature X fachlich sinnvoll, moralisch akzeptabel, rechtlich zulässig oder im Produktkontext die richtige Priorität ist.
Deshalb würde ich sagen:
Ein Harness kann Prozess- und Zugriffsgarantien geben.
Er kann Evidenz erzwingen.
Er kann Blast Radius begrenzen.
Er kann aber nicht aus unvollständiger Spezifikation vollständige Wahrheit machen.
Anthropic zeigt das sehr plastisch: Harnesses verbesserten Long-running Agents stark, aber auch mit Browser-Automation und Tests blieben blinde Flecken, etwa weil bestimmte UI-Zustände nicht sichtbar waren oder Browser-Automation nicht alles erfassen konnte.
Grenze 1: Unvollständige oder falsche Ziele
Ein Agent kann perfekt gegen die falsche Spezifikation arbeiten. Wenn die Akzeptanzkriterien fehlen, falsch sind oder wichtige Stakeholder-Anforderungen nicht im Repo stehen, optimiert der Harness auf eine Scheingenauigkeit.
OpenAI formuliert es sinngemäß so: Was Codex nicht im Kontext sehen kann, existiert für das System nicht; Wissen in Slack, Google Docs oder in Köpfen muss in repo-lokale, versionierte Artefakte übersetzt werden.
Das heißt: Der Harness schützt nicht vor fehlenden Prämissen. Er kann nur erzwingen, dass der Agent vorhandene Prämissen liest und nutzt.
Grenze 2: Tests sind Evidenz, keine Wahrheit
„Alle Tests grün“ heißt: Das System hat eine endliche Menge erwarteter Fälle bestanden. Es heißt nicht: keine Bugs, keine falschen Annahmen, keine Security-Lücken, keine ungesehenen Randfälle.
Das gilt besonders bei UX, Security, Datenqualität, Nebenwirkungen, Race Conditions, Performance unter Last, realen Nutzerdaten und externen APIs. Anthropic beschreibt, dass selbst ein getunter QA-Agent subtile Bugs und tiefer verschachtelte Features übersehen kann; außerdem war Claude als QA-Agent „out of the box“ zu großzügig und musste explizit auf skeptisches Prüfen getunt werden.
Ein optimaler Harness kann hier nur besser werden durch stärkere Oracles: Property-based Tests, Fuzzing, formale Spezifikationen, Golden Datasets, Replay realer Traces, unabhängige Evaluatoren, Canary Deployments, Monitoring und Rollback. Aber auch das bleibt Abdeckung, nicht Allwissenheit.
Grenze 3: LLM-Evaluatoren teilen oft dieselben Schwächen
Multi-Agent-Harnesses klingen attraktiv: Planner, Generator, Evaluator. Das hilft. Aber der Evaluator ist oft wieder ein LLM. Damit entstehen korrelierte Fehler: beide Modelle übersehen dasselbe, teilen dieselben Annahmen, lassen sich von plausiblen Erklärungen überzeugen oder bewerten oberflächlich.
Anthropic sagt explizit, dass Agenten bei Selbstbewertung dazu tendieren, ihre eigene Arbeit zu positiv zu beurteilen; ein separater Evaluator hilft, aber eliminiert die Tendenz nicht automatisch.
Darum: Ein Evaluator-Agent ist gut. Ein mechanischer, adversarialer, unabhängiger Evaluator ist besser. Ein menschlicher Fachexperte bleibt bei offenen Urteilsfragen noch einmal eine andere Qualität.
Grenze 4: Sicherheit kann nicht nur prompt-basiert sein
Ein Harness, der sagt „lösche keine Dateien“, ist schwach. Ein Harness, bei dem der Agent technisch keine Dateien außerhalb eines erlaubten Pfads löschen kann, ist stark.
Die große Grenze ist: Sobald der Agent Tools, Credentials, Shell, Browser, E-Mail, Datenbanken oder Deploy-Rechte hat, wird Fehlverhalten operativ relevant. OWASP nennt für Agenten unter anderem Prompt Injection, Tool Abuse, Privilege Escalation, Data Exfiltration, Memory Poisoning, Goal Hijacking, Excessive Autonomy und Cascading Failures als zentrale Risiken.
Prompt Injection ist besonders wichtig: OWASP beschreibt im Detail, dass manipulierte Inputs das Modellverhalten unerwartet verändern können und dass RAG oder Fine-Tuning solche Angriffe nicht vollständig entschärfen. Außerdem sei unklar, ob es narrensichere Prävention gibt; empfohlen werden daher Schadensbegrenzung, Least Privilege, Output-Validierung, Trennung untrusted content und Human Approval für Hochrisikoaktionen.
Praktisch heißt das: Der Harness darf dem Modell nicht vertrauen. Er muss den Agenten wie einen potenziell kompromittierten Prozess behandeln.
Grenze 5: Schaden entsteht oft außerhalb des Codes
Ein Coding-Harness kann Codequalität verbessern. Aber Schaden kann auch entstehen durch:
falsche Nutzerkommunikation, fehlerhafte fachliche Empfehlung, Datenschutzverletzung, Diskriminierung, falsche Priorisierung, unzulässige Automatisierung, falsche Eskalation, unbemerkte Kostenexplosion oder eine Entscheidung, die technisch korrekt, aber organisatorisch falsch ist.
NIST beschreibt Trustworthy AI nicht nur als Validität und Reliability, sondern auch als Safety, Security/Resilience, Accountability/Transparency, Explainability/Interpretability, Privacy und Fairness. NIST betont außerdem, dass das einzelne Adressieren dieser Eigenschaften nicht automatisch Vertrauenswürdigkeit garantiert, weil Trade-offs und Kontextentscheidungen bleiben.
Das ist eine wichtige Grenze für Harness Engineering: Ein Harness kann technische Gates bauen, aber nicht alle sozialen, rechtlichen und ethischen Trade-offs wegautomatisieren.
Grenze 6: Drift und Entropie bleiben
Ein Agent kopiert vorhandene Muster. Sind die Muster gut, skaliert Qualität. Sind sie schlecht, skaliert Müll.
OpenAI beschreibt genau das als neues Problem vollständiger Agentenautonomie: Codex repliziere vorhandene, auch suboptimale Patterns, was über Zeit zu Drift führt; dagegen wurden „Golden Principles“, Qualitätschecks und wiederkehrende Cleanup-Prozesse eingeführt.
Ein optimaler Harness braucht also nicht nur „Do the task“, sondern auch permanente Müllabfuhr: Qualitätsmetriken, Architektur-Reviews, Tech-Debt-Tracker, Refactoring-Routinen, Dokumentationspflege, Regressionstests und Mechanismen gegen veraltete Regeln.
Grenze 7: Menschliche Urteilskraft verschwindet nicht, sie wandert nach oben
Der Mensch schreibt weniger Code, aber entscheidet stärker über Ziele, Constraints, Akzeptanzkriterien, Risikoappetit und Eskalation. OpenAI beschreibt, dass Menschen im Loop bleiben, aber auf anderer Abstraktionsebene: priorisieren, User Feedback in Acceptance Criteria übersetzen und Outcomes validieren.
Das ist aus meiner Sicht die produktivste Lesart:
Der Harness soll Menschen nicht komplett ersetzen, sondern ihre Aufmerksamkeit an die Stellen verschieben, an denen sie am meisten Wert hat.
Was ein Harness tatsächlich garantieren kann
Stark garantierbar sind Dinge wie:
| Art der Garantie | Kann ein guter Harness leisten? |
|---|---|
| Agent darf bestimmte Tools nicht nutzen | Ja, wenn technisch enforced, nicht nur prompt-basiert |
| Agent darf nur in Sandbox schreiben | Ja, über Dateisystem-/Containerrechte |
| Kein Merge ohne CI | Ja, über Branch Protection |
| Kein Deploy ohne Human Approval | Ja, über Deployment-Gates |
| Keine Arbeit ohne Baseline-Check | Weitgehend, wenn der Workflow technisch erzwingt |
| Keine „Done“-Meldung ohne Evidenz | Weitgehend, wenn Done-Status maschinell validiert wird |
| Keine fachlich falsche Entscheidung | Nein, nicht allgemein |
| Keine falsche Annahme | Nein, nur reduzierbar |
| Keine ungetesteten Nebenwirkungen | Nein, nur durch bessere Abdeckung reduzierbar |
| Kein Schaden | Nein, nur Risiko und Blast Radius reduzierbar |
Der Unterschied ist: Zugriff, Prozess und Artefakte lassen sich hart kontrollieren. Bedeutung, Wahrheit, Priorität und Werturteile nur begrenzt.
Meine Kurzformel
Ein optimaler Harness macht den Agenten nicht unfehlbar. Er macht ihn:
- sichtbar: Was wurde getan, warum, mit welcher Evidenz?
- begrenzt: Was darf der Agent technisch überhaupt tun?
- prüfbar: Welche Tests, Logs, Traces, Screenshots, Reviews existieren?
- reversibel: Kann man Fehler zurückrollen?
- eskalierbar: Wann muss ein Mensch entscheiden?
- lernend: Werden Fehler in neue Regeln, Tests und Dokumente überführt?
Für harmlose oder gut testbare Coding-Aufgaben kann das reichen, damit man „reviewt statt rettet“. Für sicherheitskritische, rechtliche, medizinische, finanzielle oder reale Aktionsräume reicht es nicht als Autonomiebeweis. Dort sollte der Harness den Agenten eher als assistierendes System mit harter Sandbox, Least Privilege, Audit Trail und Human Approval behandeln. NIST formuliert für AI-Risikomanagement ebenfalls, dass bei Fehlern, die das System nicht erkennen oder korrigieren kann, menschliche Intervention nötig sein kann.
Fazit
Ein sehr guter Harness kann Zuverlässigkeit massiv erhöhen, aber er kann nicht garantieren, dass ein Agent „keine Fehlentscheidungen“ trifft. Er verschiebt das Problem: weg von „das Modell improvisiert frei“ hin zu „wir erzwingen Prozess, Kontext, Grenzen, Evidenz und Eskalation“. Das ist ein großer Fortschritt, aber kein Beweis für Wahrheit, Sicherheit oder gute Urteilsfähigkeit.