Über die Google Search Console gibt es die Möglichkeit die URL-Parameter einer Seite für das Crawling durch Google einzustellen. Damit hilft man Google dabei, die Website effizienter zu crawlen, indem man angibt, wie Parameter in Ihren URLs gehandhabt werden sollen. In diesem Beitrag erkläre ich die Möglichkeiten die das Tool bereit hält, wie man die häufigsten Parameter richtig einstellt und gehe dabei auf gängige Probleme und Fallstricke ein.
Wieso gibt es das Tool überhaupt?
URL-Parameter erzeugen häufig sog. Duplicate Content. Wenn Google duplizierte Inhalte erkennt, kann das nachteilig für das Ranking einer Webseite sein. Zwar gruppiert ein Google-Algorithmus die duplizierten URLs in einem Cluster und wählt eine URL aus, die das Cluster in den Suchergebnissen vermutlich am besten repräsentiert. Allerdings kann Google oft nicht alle URLs in einem Cluster finden, oder die automatisch ausgewählte Seite ist nicht die beste Landingpage oder gewünschte Zielseite für den Nutzer. Zudem kann Google doppelte Inhalte sogar als Betrugsversuch werten, wenn zu viele Seiten mit immer wieder gleichen Inhalten in den Index gelangen.
Unterschied zwischen Crawling und Indexierung
Ein ganz wichtiger Unterschied, den man verstehen muss, besteht zwischen dem Crawling einer URL und der Indexierung dieser. Das Crawling ist zunächst lediglich der Abruf der Inhalte der URL durch den Google-Bot. Diesen Abruf kann man bereits mittels robots.txt unterbinden, dann kann die URL überhaupt nicht ausgelesen werden, wird jedoch dennoch in den Index aufgenommen falls sie verlinkt ist, wenn auch ohne Inhalte oder Informationen darüber.
Anschließend wird die gecrawlte URL und deren Inhalte in den Index aufgenommen, wenn dies nicht durch den Robots-Meta-Tag „noindex“ unterbunden wurde, oder die URL über den Canonical-Tag auf eine andere kanonische URL verweist.
Mit dem URL-Parameter Tool steuert man das Crawling von URLs, nicht jedoch die Indexierung!
Wann soll eine Seite gecrawlt werden und wann indexiert?
Generell kann man sagen, dass eine Seite gecrawlt werden sollte wenn:
- Entweder: Die URL eingehende Links besitzt, egal ob interne oder externe Verlinkung, damit der Linkjuice weiter gegeben werden kann.
- Oder: Die URL Verlinkungen enthält, die für eine Indexierung weiterer Seiten benötigt werden.
- Oder: Die URL in den Index aufgenommen werden und ranken soll.
Dagegen sollte eine Seite indexiert werden, wenn:
- Die Seite einzigartige Inhalte enthält und zugleich
- Nutzer in der Suchmaschine nach diesen Inhalten suchen.
Wie entstehen URL-Parameter?
URL-Parameter kommen aus den unterschiedlichsten Gründen zustande. Ganz einfach gesprochen reicht es schon, als Nutzer an die URL einer Seite per Hand mit „?parameter=wert“ einen Parameter anzuhängen und diesen zu verlinken und schon findet die Suchmaschine eine neue URL, die mit großer Wahrscheinlichkeit jedoch identische Inhalte ausliefert, wie die selbe URL ohne den Parameter. Greift nun keine sinnvolle Regel durch den Meta-Robots-Tag oder den Canonical-Tag kommt es bereits zur Indexierung doppelter Inhalte.
Wie konfiguriert man nun richtig?
Die erste Frage, die Google einem beim Hinzufügen eines neuen Parameters stellt lautet:
Ändert dieser Parameter den Seiteninhalt, der dem Nutzer angezeigt wird?
Die Frage ist also, ob der Parameter auf einen beliebigen Wert zurückgesetzt werden kann, ohne dass sich der Seiteninhalt ändert.
1. Fall: Der Inhalt ändert sich nicht
Konfiguriert diesen Parameter entsprechend, crawlt Google nur ein Einzige der URLs mit diesem Parameter. Nachfolgend einige Beispiele dazu:
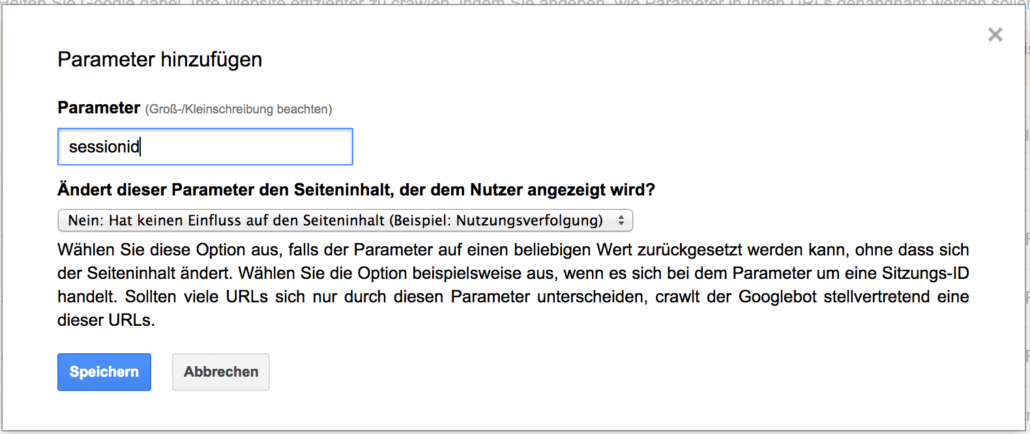
Session-IDs
Auf vielen Websites werden dieselben Inhalte über unterschiedliche URLs bereitgestellt, beispielsweise mithilfe von Sitzungs-IDs oder anderen URL-Parametern. Eine Sitzungs-ID ist eine Nummer, die an einen URL-Pfad angehängt wird. Auf diese Weise wird eine neue Seite erstellt, die dem Besucher der Website, der dieser ID entspricht, eine personalisierte Erfahrung bietet. So ermöglichen Sitzungs-IDs beispielsweise einer Shopping-Website, zwischen Kunden zu unterscheiden, sodass jede Person beim Stöbern im Websitekatalog sehen kann, was sich in ihrem Warenkorb befindet.
Tracking-Parameter
In Google Analytics kann man beispielsweise das Tool zur Kampagnen URL Erstellung benutzen, um den eigenen URLs benutzerdefinierte Kampagnenparameter hinzuzufügen. Wenn Nutzer auf einen der benutzerdefinierten Links klicken, werden die eindeutigen Parameter an das jeweilige Google Analytics-Konto gesendet. So kann man besser heraus finden, welche Quellen bzw. Kampagnen den meisten bzw. besten Traffic geliefert haben.
Diese Parameter können daher mit „Nein“ eingestellt werden:
Ausnahmen
Ausnahmen von dieser Regel sind URLs mit diesem Parameter, die externe Links erhalten haben. Diese möchte man crawlen lassen, damit die Kraft der externen Links auch auf die Seite übergehen kann. Dabei ist jedoch darauf zu achten, dass die Seite dann entweder mittels Robots-Meta-Tag „noindex“ oder durch den Einsatz eines Canonical-Tags nicht in den Index aufgenommen wird!
2. Fall: Der Inhalt ändert sich
Konfiguriert den Parameter entsprechend, crawlt Google jede URL mit diesem Parameter. Nachfolgend einige Beispiele dazu:
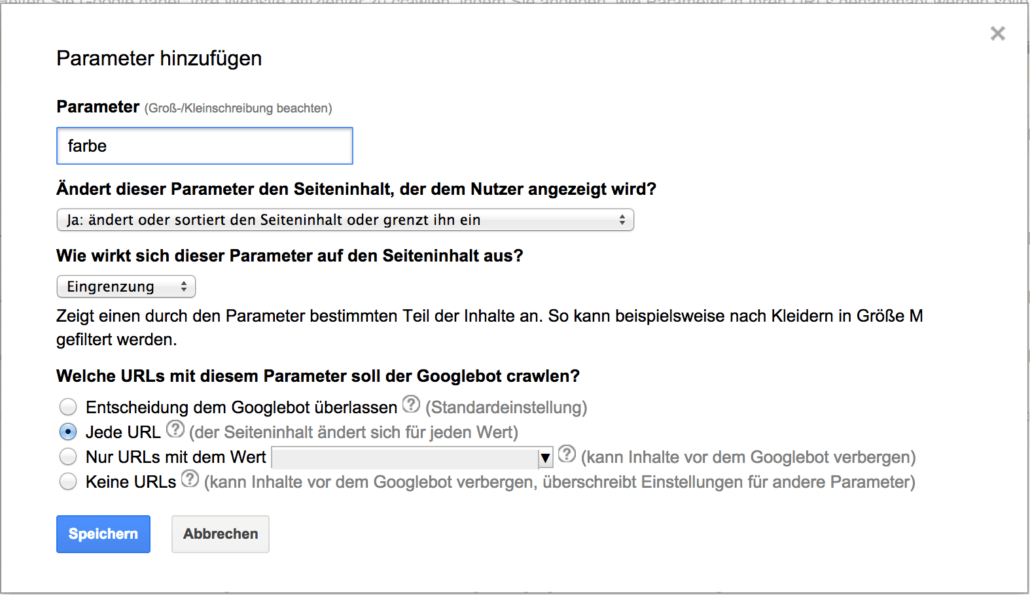
Präzisierung und Eingrenzung
Filter-Parameter sind nicht auf einzelne Kunden ausgerichtet: Angenommen, ein Kunde sucht auf der Website eines Shops nach „Stiefeln“ und hat die Möglichkeit, seine Ergebnisse nach Farbe, Größe, Material und Preisspanne zu filtern. Jede Kombination dieser Filter stellt dann jeweils eine andere URL dar, da die Filter neue Zeichenfolgen oder Parameter an den ursprünglichen URL-Pfad anhängen, um die für den Kunden dargestellte Seite anzupassen.
Diese Seiten werden häufig intern verlinkt und können je nach Suchvolumen auch im Mid- bis Long-Tail in der Breite relevanten Traffic liefern. Daher sollten diese Parameter … konfiguriert werden und mittels Robots-Meta-Tag oder Canonical-Tag die Seiten die einzigartig genug sind und einen Mehrwert für Suchende darstellen indexiert werden:
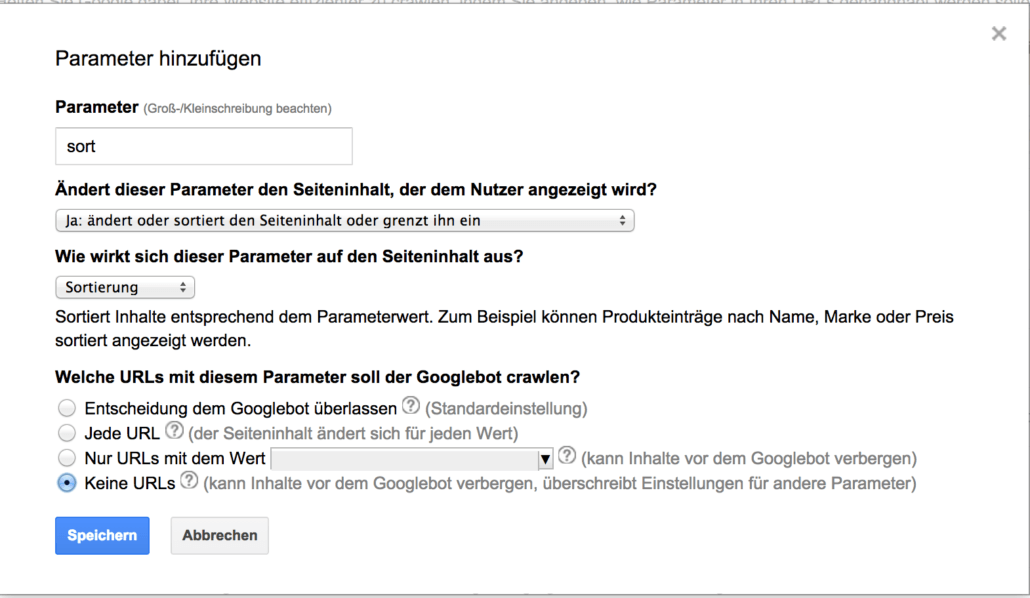
Sortierung
Anders sieht es dagegen bei der Sortierung aus. Hier ändert sich zwar der Seiteninhalt, aber nur die Reihenfolge der angezeigten Elemente. Der Inhalt als solches ist also identisch, daher sollten Sortierparameter vom Crawling ausgeschlossen werden und im besten Fall intern erst gar nicht angelinkt werden:
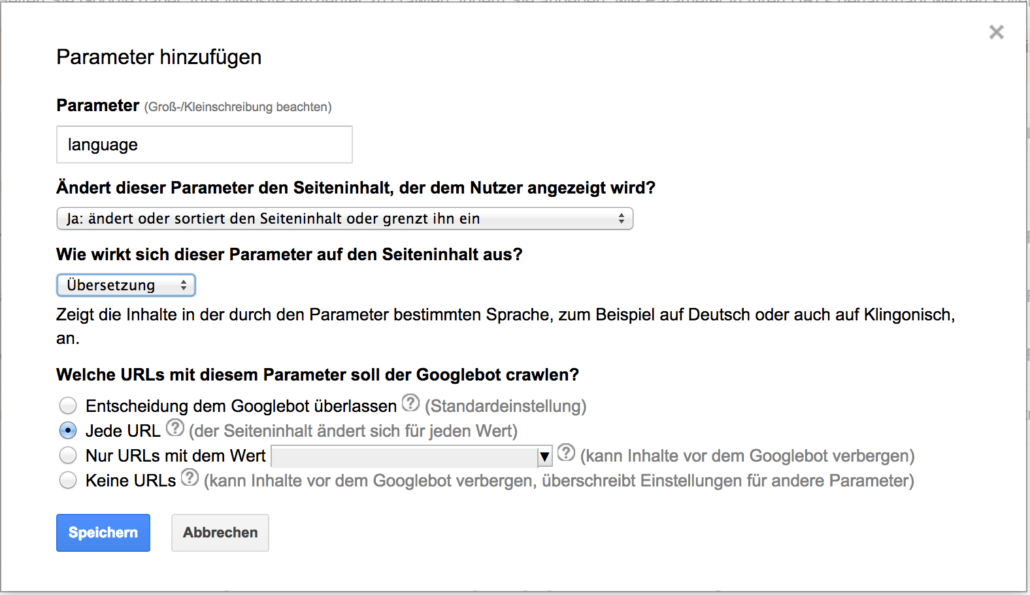
Übersetzung
Handelt es sich bei einer Seite um eine internationale Webseite mit mehrsprachigen Inhalten, kann es sein, dass durch einen Sprach-Parameter die jeweilige Sprache des Nutzers festgelegt wird. Hierbei handelt es sich klar um einzigartige Inhalte, deren URLs sowohl gecrawlt, als auch indexiert werden sollten:
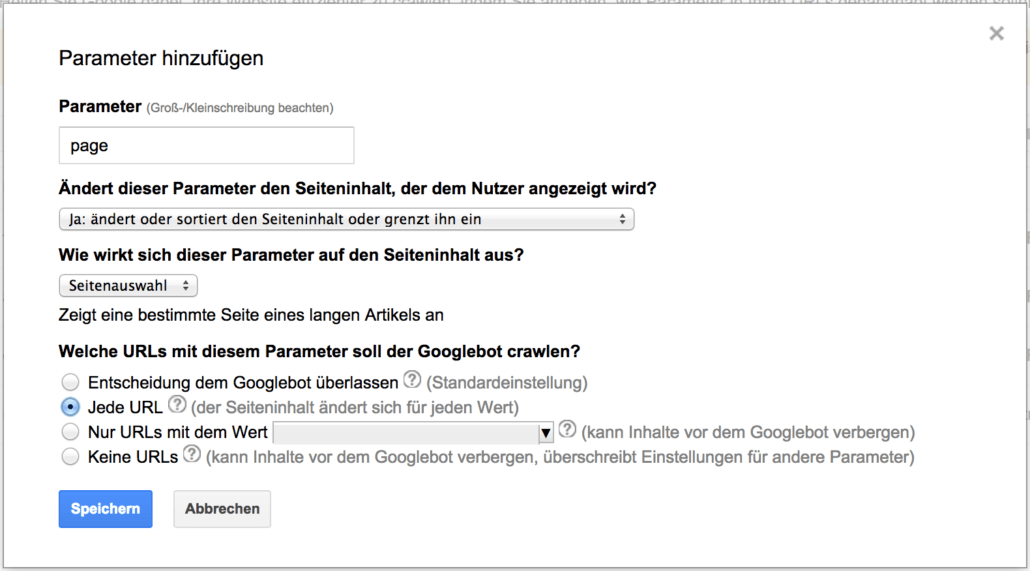
Seitenauswahl
Werden lange Artikel auf mehrere Seiten aufgeteilt, wird hierfür häufig ebenfalls ein URL-Parameter eingesetzt, der angibt auf welcher Seite des Artikels der Leser sich gerade befindet. Natürlich sind die Inhalte der Seiten unterschiedlich und sollten auch gecrawlt und ggf. indexiert werden:
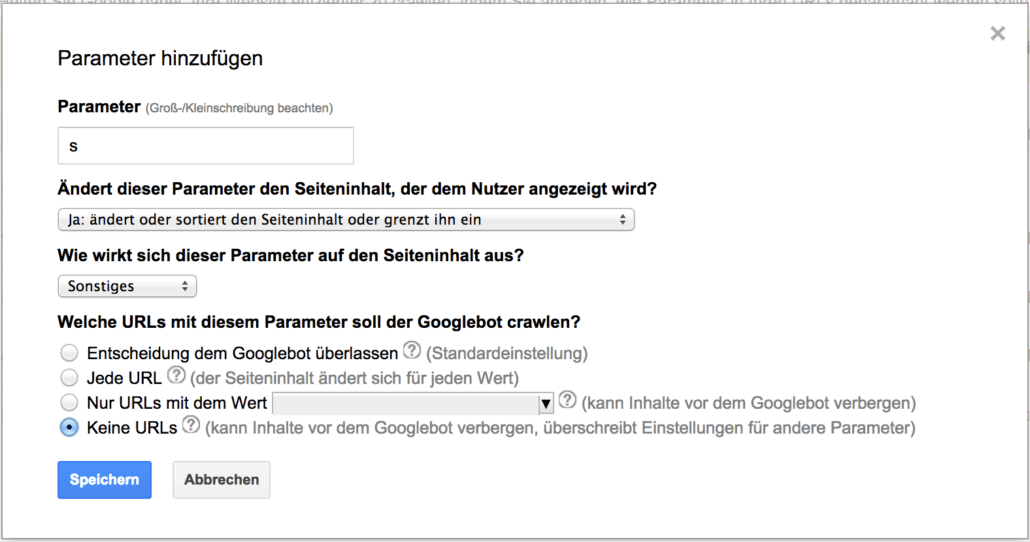
Suche
Die Suchfunktion wird sehr häufig über einen Parameter wie „s“ oder „search“ realisiert. Dabei entsteht jedoch durch jede Suchanfrage eines Nutzers eine neue URL, die in der Regel doppelte Inhalte der Webseite enthält. In der Regel erhalten Suchergebnisseiten keine externen Links, sind intern nicht verlinkt und sollen auch nicht in den Index aufgenommen werden.
Daher kann dieser Parameter unter „Sonstiges“ mit „keine URLs“ konfiguriert werden:
Probleme und Fallstricke
Wie ich schon deutlich gemacht habe, konfiguriert das URL-Parameter Tool nur das Crawling der URLs und hat damit keinen Einfluss auf die Indexierung der Seiten.
Was definitiv nicht passieren sollte:
- Crawling unterbinden von Seiten die man im Index haben möchte
- Crawling unterbinden von Seiten, die wichtig für die interne Verlinkung sind
Außerdem ersetzt das Parameter-Handling bei der Einstellung „Ja, Inhalt ändert sich“ NICHT die Indexierungssteuerung mittels Robots-Meta-Tag oder durch den Canonical-Tag! Es gibt eben Seiten die gecrawlt aber nicht indexiert werden sollten.
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.




