Die technische Seite der Suchmaschinenoptimierung ist die Grundlage aller Erfolge. Die Sicherstellung der „Crawlability“ der Inhalte hat daher oberste Priorität. Zudem ist es wichtig, den Crawler nicht an Seiten herankommen zu lassen, die man ohnehin nicht im Index haben möchte und den Index gleichzeitig nicht mit unnützen Seiten zu überfrachten.
Die goldene Regel bei der Steuerung der Indexierung lautet: „Jede Seite im Index muss eine Suchanfrage beantworten, die ein Nutzer so bei Google stellt.“
Ist dies nicht der Fall, erfüllt diese Seite aus Sicht der Suchmaschine keinen Zweck und mindert die Nutzererfahrung und damit die Qualität der indexierten Inhalte einer Domain.
Der zweite wichtige Grundsatz für die Indexierung lautet: „Jeder Inhalt darf nur unter einer einzigen URL abgerufen werden können. Diese URL nennt sich auch die kanonische URL“
Führen mehrere URLs zu gleichen Inhalten entsteht ein Problem durch sog. „Duplicate Content“ und Keyword-Kannibalisierung*. Eine mögliche Lösung für diese Problematik stellt der sog. „Canonical Tag“ dar.
8 wissenswerte Fakten über den Canonical-Tag
- Der Canonical-Tag ist ein HTML-Tag, der von Webmastern verwendet wird, um anzugeben, welche URL als die „Haupt“- oder „Original“-URL für eine bestimmte Seite betrachtet werden soll.
- Der Canonical-Tag wird in der Kopfzeile einer Webseite platziert und sieht in etwa so aus:
<link rel="canonical" href="https://example.com/original-page/" /> - Der Canonical-Tag wird verwendet, um Duplikate von Webseiten zu vermeiden, die möglicherweise durch unterschiedliche URLs verursacht werden, wie zum Beispiel verschiedene Domainnamen oder Links mit und ohne „www“ am Anfang.
- Der Canonical-Tag ist ein Hinweis an die Suchmaschinen und keine Garantie dafür, dass eine Seite nicht mehrfach indiziert wird. Webmaster sollten daher sicherstellen, dass sie alle notwendigen Schritte unternehmen, um sicherzustellen, dass es keine Duplikate ihrer Seiten gibt.
- Der Canonical-Tag kann auch verwendet werden, um Suchmaschinen darüber zu informieren, dass eine Seite Teil einer größeren Sammlung von Seiten ist, wie zum Beispiel einer Kategorie- oder Produktdetailseite. In diesem Fall sollte der Canonical-Tag auf die „Haupt“-URL der Sammlung verweisen, anstatt auf die individuelle Seite.
- Wenn der Canonical-Tag auf eine externe URL verweist, sollte die externe URL auch die gleiche Inhalte wie die ursprüngliche Seite haben. Andernfalls könnte dies für die Suchmaschinen als „Spamming“ oder „Tricksen“ interpretiert werden und zu einer Abstrafung der Seite führen.
- Der Canonical-Tag kann auf Seiten mit dynamischen URLs verwendet werden, um anzugeben, welche URL als die „Haupt“-URL betrachtet werden soll. Zum Beispiel könnte eine Seite mit dynamischen URLs wie „example.com?product=123“ mit einem Canonical-Tag auf „example.com/products/product-123/“ verweisen.
- Der Canonical-Tag sollte auf jeder Seite eindeutig gesetzt werden. Wenn der Canonical-Tag auf mehreren Seiten auf die gleiche URL verweist, könnte dies zu Problemen führen.
Der vergleichsweise neue „Canonical Tag“ ist ein weiterer Schritt der großen Suchmaschinenbetreiber um dem „Duplicate Content“ Herr zu werden. Allerdings ist die Anweisung durch den Canonical-Tags lediglich eine Empfehlung an die Suchmaschine, was bei unsachgemäßem Einsatz, wie z.b. bei der Paginierung auf Ihren Seiten zu einem Problem wird.
Aus diesem Grund habe ich in diesem Artikel die häufigsten Fehler, die beim Einsatz des Canonical-Tags entstehen können aufgeführt und erkläre hierbei wieso dies ein Problem ist und wie es sich vermeiden lässt.
Wie macht man es richtig?
Google selbst** empfiehlt für den Einsatz des Canonicals folgende Best Practice:
- Ein Großteil der Information der Duplikatsseite sollte auf der kanonischen Version enthalten sein.
- Um dies zu überprüfen, empfiehlt Google sich vorzustellen, man verstünde die Sprache der Seite nicht und die kanonische und die duplizierte Seite nebeneinander zu legen und zu überprüfen ob ein sehr großer Teil der Wörter auf beiden Seiten identisch ist.
- Wenn die Seite lediglich thematisch ähnlich sind, aber nicht wortwörtlich übereinstimmen, kann der Canonical-Tag von den Suchmaschinen ignoriert werden!
- Überprüfen Sie stets, dass das Ziel des Canonical-Tags auch tatsächlich existiert
- Überprüfen Sie dass die kanonische URL keinen „noindex“ Robots Meta-Tag enthält
- Ist die kanonische URL die jenige, die auch in den Suchergebnissen erscheinen soll (anstatt der duplizierten URL)
- Der Canonical-Tag kann sich sowohl im <head> Element der Webseite, als auch im HTTP-Antwort-Header befinden.
- Definieren Sie nur EINEN Canonical-Tag. Sollte dieser mehrfach vorhanden sein, werden sämtliche Canonical-Tags ignoriert!
Fehler 1: rel=canonical auf die erste Seite einer Paginierung
Dieser Fehler wird leider immer wieder gemacht. Man möchte natürlich dass die Kategorieseiten gut ranken und so kommen viele SEOs auf die Idee mit Hilfe des Canonical-Tags die paginierten Seiten 2,3,4, etc. auf die erste Seite zu verweisen um dort die maximale Kraft zu bündeln.
Stellen Sie sich vor, sie haben beispielsweise URLs wie:
- example.com/kategoriexyz/
- example.com/kategoriexyz/?seite=2
- example.com/kategoriexyz/?seite=3
und so weiter.
Hier nun den rel=canonical von Seite 2 und den Folgenden auf die erste Seite zeigen zu lassen ist kein korrekter Einsatz des Canonicals, da dies keine Duplikate der ersten Seite sind!
In diesem Beispiel sorgt der Canonical-Tag sogar dafür, dass der gesamte Inhalt dieser Seiten nicht indexiert wird und auch die dort enthaltenen Links auf weitere Produkte etc. nicht von der Suchmaschine gefolgt und damit gewertet werden!
So geht es richtig:
Im Falle von paginierten Seiten, sollten Sie entweder den Canonical-Tag auf eine URL zeigen lassen, auf der alle Produkte gelistet sind, oder alle Seiten ab der zweiten mit den Robots-Tag auf noindex von der Indexierung auszuschließen. Den rel-prev und rel-next Link beachtet Google nicht (mehr).
Fehler 2: Absolute URLs versehentlich als relative URLs verwendet
Der Canonical-Tag akzeptiert grundsätzlich sowohl relative, als auch absolute URLs. Hierbei kann es jedoch zu falscher Verwendung kommen, insbesondere wenn die Seite mit einem <base>-Tag und relativen URLs arbeitet.
<link rel=canonical href="example.com/cupcake.html" />wird fehlerhaft interpretiert, je nachdem in welchem Verzeichnis sich die Seite gerade befindet als:
http://example.com/example.com/cupcake.html oder gar http://example.com/verzeichnis-der-aktuellen-seite/example.com/cupcake.htmlIdealerweise wird die gesamte URL angegeben:
<link rel=canonical href="http://example.com/cupcake.html" />oder die absolute URL ohne Domain angegeben:
<link rel=canonical href="/cupcake.html" />Denn auch bei Verwendung einer relativen URL wie:
<link rel=canonical href="cupcake.html" />kann es in einem Unterverzeichnis dazu kommen, dass die URL falsch zusammengesetzt wird.
Fehler 3: Versehentliche Mehrfachverwendung des Canonical-Tags
Gerade bei selbst entwickelten Content-Management- oder Shop-Systemen kann es passieren, dass mehrere Regeln greifen und der Canonical-Tag dann Doppelt oder gar noch häufiger ausgegeben wird.
Ist dies der Fall ignoriert Google sämtliche Anweisungen und behandelt die Seite wie eine URL ohne Canonical-Tag!
Fehler 4: Canonical-Tag um unterschiedliche Seiten zusammen zu fassen
Insbesondere seit das Page-Rank-Sculpting mit internen Nofollow-Links nicht mehr funktioniert, versuchen viele SEOs die Kraft von Seiten die zwar sehr viele Links erhalten, aber eigentlich gar nicht ranken sollen (Beispiel Impressum, AGB, Datenschutz) mittels Canonical-Tag auf eine gewünschte SEO-Landingpage zu verschieben. Leider ist diese Müh zumeist vergeben, da die Seiten einfach zu unterschiedlich sind und außerdem die Gefahr besteht, dass Google sämtliche Canonical-Tags der Domain ignoriert.
Fehler 5: Der Canonical-Tag im <body> der HTML-Seite
Das Canonical-Tag geört in den <head> Bereich des HTML-Dokuments. Findet die Suchmaschine einen Canonical-Tag im <body> wird dieser schlicht ignoriert. Zu groß wäre hierbei die Gefahr durch eingeschleusten Code von Außen die Kraft der URL abziehen zu können.
Fehler 6: Keinen Rel-Canonical bei URL-Parametern
Bei vielen Seiten ist standardmäßig gar kein Canonical-Tag implementiert. Der Bedarf wird häufig nicht gesehen, doch auch wenn man nicht bewusst mehrere Seiten zusammenführen möchte, sollte der Canonical-Tag stets auf die kanonische URL zeigen, also auf die URL unter der die jeweilige Seite erreichbar ist. Der Grund hierfür sind URL-Parameter, die sich häufig durch Tracking oder andere Gründe in die URL einschleichen und schnell für eine Mehrfacherreichbarkeit sorgen und im schlimmsten Falle Duplicate Content verursachen.
Selbst SEOs machen diesen Fehler, wie man bei einer Abfrage von SEO mit „inurl:utm_source“ leicht herausfinden kann:
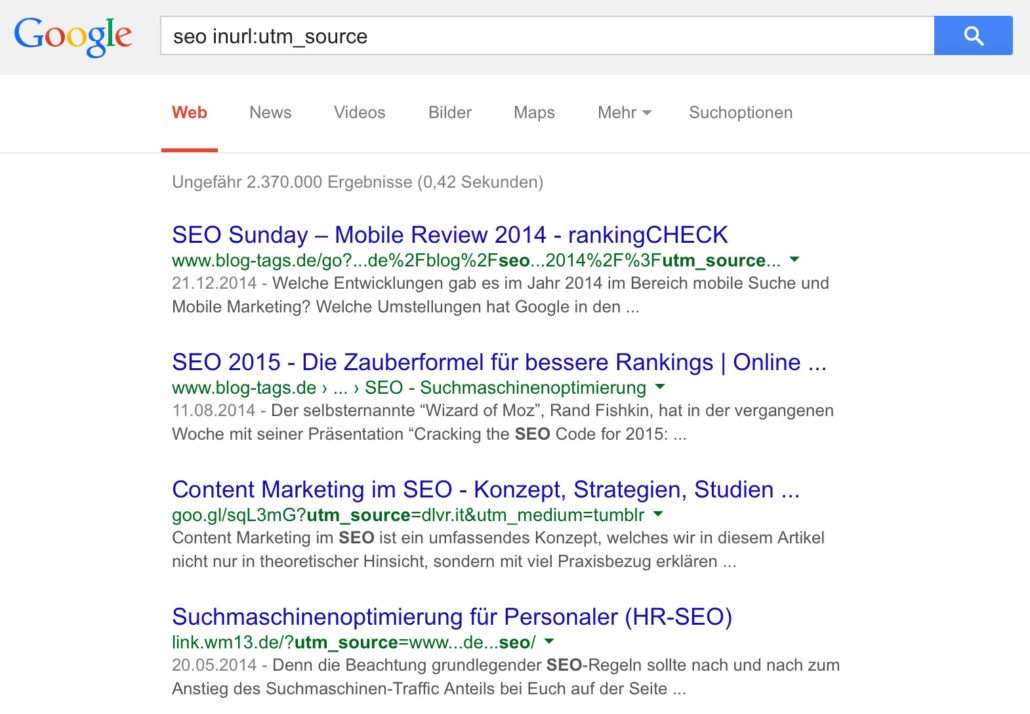
Fehler 7: Keinen Canonical Tag in der Mobilen Webseite
Mobile Webseiten werden immer wichtiger, soviel ist klar. Oft wird die Webseite für mobile Endgeräte unter einer anderen URL ausgeliefert, z.b. m.example.com oder ähnliches. Wichtig hierbei ist es, die mobile Variante nicht nur von der Normalen aus mittels Rel-Alternate anzugeben:
<link rel="alternate" media="only screen and (max-width: 640px)"
href="http://m.example.com/page-1" >Sondern eben auch auf der mobilen Webseite dann die jeweilige URL der Desktop Version im Canonical-Tag anzugeben:
<link rel="canonical" href="http://www.example.com/page-1" >Dies empfiehlt Google auch explizit im Leitfaden für mobile Webseiten:
Google rät davon ab, separate URLs bei der Website-Einrichtung zu verwenden, da diese schwierig zu implementieren und zu verwalten sind. Du kannst stattdessen responsives Webdesign in Betracht ziehen.
Fazit
Ich hoffe dass ich mit diesem Artikel einige Fehlannahmen beseitigen konnte und Ihr nun den Canonical-Tag korrekt einsetzen könnt.
Falls Euch noch häufige Fehler einfallen, oder Ihr Fragen zu konkreten Anwendungsfällen des Canonical-Tags habt, freue ich mich sehr über einen Kommentar!
* Kannibalisierung im Marketing findet statt, wenn sich unterschiedliche Produkte eines Unternehmens in direkter Konkurrenz zueinander befinden, das heißt den gleichen Markt bearbeiten und sich gegenseitig Marktanteile rauben. In Sachen SEO bedeutet die Kannibalisierung auf Keyword-Ebene, dass sich mehrere Seiten gegenseitig im Ranking Konkurrenz machen, da diese zu ähnlich sind und auf die gleichen Begriffe abzielen. Oft treten dadurch negative Effekte auf, so dass keine der Seiten wirklich gut rankt, da die Suchmaschine nicht entscheiden kann, welches die „richtige“ bzw. die beste Seite zu diesem Begriff ist. Daher rankt meist keine der Seiten.
** http://googlewebmastercentral.blogspot.de/2013/04/5-common-mistakes-with-relcanonical.html
Dieser Beitrag ist in ähnlicher Form auch im OMT-Magazin erschienen.
Wie indexiert Google und wie wird die kanonische URL ausgewählt?
In dieser Folge von Ask Google Webmasters erklärt John Mueller, wie Google Search eine kanonische URL aus ähnlichen oder doppelten Seiten auswählt:
Weitere Informationen finden Sie in der Entwickler-Hilfe von Google.
Wie kann ich den Canonical-Tag einer Seite überprüfen?
1. Verwenden Sie die Entwickler-Tools Ihres Browsers: Die meisten modernen Browsers haben Entwickler-Tools, die es ermöglichen, den HTML-Code einer Webseite anzuzeigen. Um den Canonical-Tag einer Seite zu überprüfen, öffnen Sie die Entwickler-Tools und navigieren Sie zur Kopfzeile der Seite. Suchen Sie nach dem Canonical-Tag und überprüfen Sie, ob er korrekt gesetzt ist.
2. Verwenden Sie ein Online-Tool: Es gibt mehrere Online-Tools, die es ermöglichen, den Canonical-Tag einer Seite zu überprüfen. Ein Beispiel ist das „Canonical URL / Location Checker„. Geben Sie einfach die URL(s) der Seite(n) ein, die Sie überprüfen möchten, und das Tool zeigt Ihnen den Canonical-Tag an.
3. Verwenden Sie die Google Search Console: Die Google Search Console ist ein kostenloses Tool von Google, mit dem Webmaster ihre Webseiten überwachen und optimieren können. Um den Canonical-Tag einer Seite zu überprüfen, melden Sie sich bei der Search Console an und wählen Sie die Seite aus, die Sie überprüfen möchten. Klicken Sie dann auf „URL-Informationen“ und überprüfen Sie den Canonical-Tag in der Abschnitt „Canonical URL“.
Was passiert, wenn der Canonical-Tag auf eine externe URL verweist?
Kann ich den Canonical-Tag verwenden, um dynamische URLs zu vereinfachen?
Was passiert, wenn der Canonical-Tag auf mehreren Seiten auf die gleiche URL verweist?
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.
