

Update vom 23. März 2026: Kevin Indig hat inzwischen auch den zweiten Teil seiner Reihe veröffentlicht: The science of how AI picks its sources. Und der ist tatsächlich interessant – nicht, weil er alle offenen Fragen löst, sondern weil er die Perspektive verschiebt.
Während Teil 1 vor allem fragte, wo auf einer Seite ChatGPT bevorzugt zitiert, geht es jetzt um eine andere Ebene: Welche Seiten, Domains und URL-Typen kommen überhaupt regelmäßig in den Kandidatenpool? Laut Artikel analysiert Teil 2 „over 21K citations“; in den ausgewiesenen Teilanalysen arbeitet Indig unter anderem mit 21.482 ChatGPT-Citation-Rows für die Konzentrationsanalyse und 42.460 matched citations für die Positionsanalyse.
Teil 2 ist erschienen – und er verschiebt die Debatte
Der wichtigste Punkt zuerst: Teil 2 widerspricht meiner Kritik am ersten Text nicht. Er macht die Arbeit nützlicher, aber nicht automatisch allgemeingültiger. Denn beobachtet werden hier ChatGPT-Zitationen, nicht „KI-Suche“ als Ganzes.
Und wie schon beim ersten Teil gilt: Die große Zahl sorgt für Aufmerksamkeit, die eigentliche Aussagekraft steckt in den kleineren, engeren Teilstichproben.
Genau deshalb bleibt es sinnvoll, das Ganze eher als proprietäre Benchmark denn als wissenschaftliche Letztbegründung zu lesen.
Der eigentliche Fortschritt liegt im Ebenenwechsel.
Sein erster Text war vor allem eine Analyse der Passage-Selection: Warum werden bestimmte Sätze, Absätze oder Blöcke eher zitiert als andere? Teil 2 geht eine Stufe höher und schaut auf Source-Selection: Welche Domains tauchen überhaupt wiederholt auf, welche URL-Typen funktionieren, und wie verteilt sich Zitationssichtbarkeit über Themenräume hinweg? Das ist für GEO extrem relevant, weil damit plötzlich nicht nur Schreibstil und Textstruktur zählen, sondern auch Seitentyp, Query-Breadth und Content-Architektur.
Besonders spannend ist die Frage nach der Marktkonzentration. In der dafür ausgewiesenen Teilstichprobe ziehen die Top-10-Domains 46 Prozent aller Zitationen, die Top 30 sogar 67 Prozent.
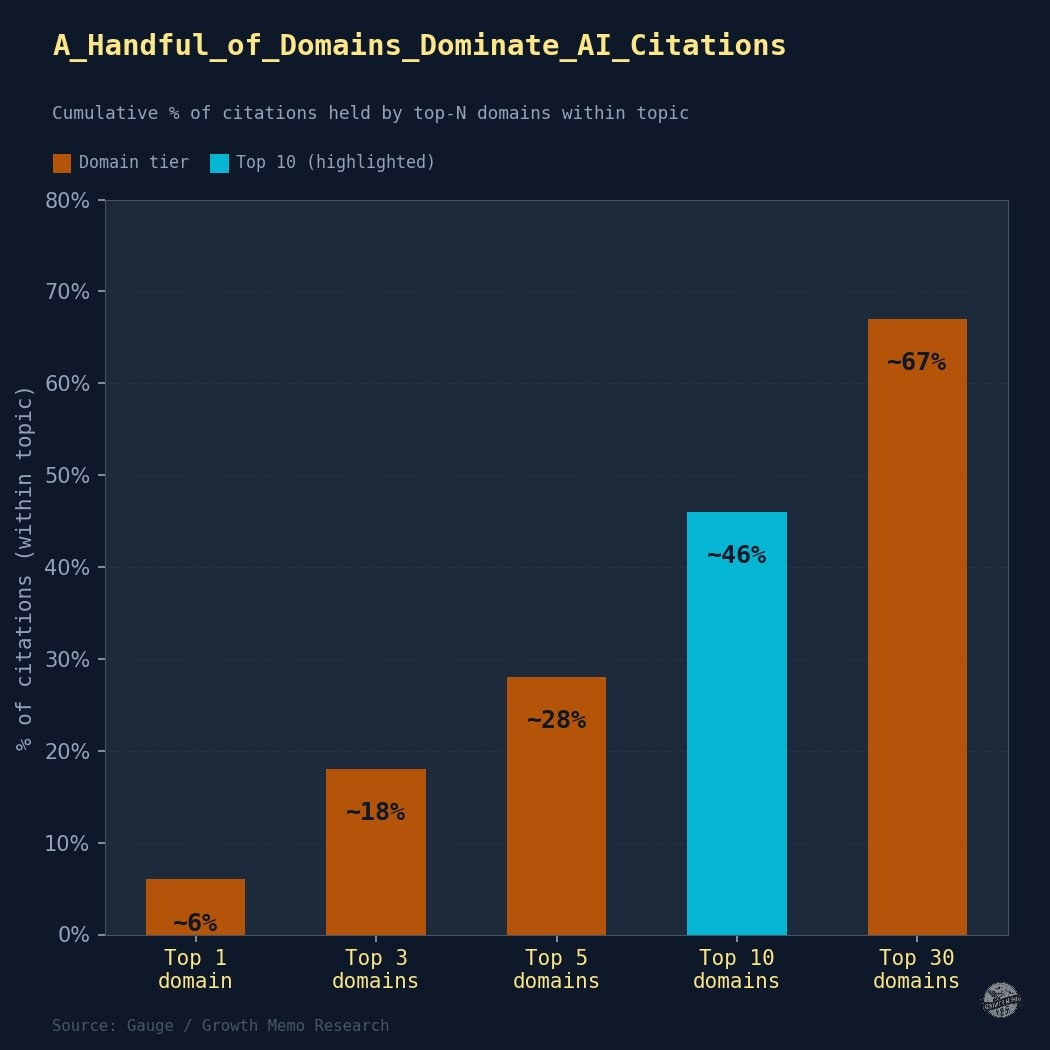
Das ist keine kleine Schieflage, sondern ein echter Konzentrationseffekt.
Gleichzeitig variieren die Verticals massiv: Education ist stark konzentriert, Healthcare deutlich offener, CRM/SaaS und HR Tech eher diffus.
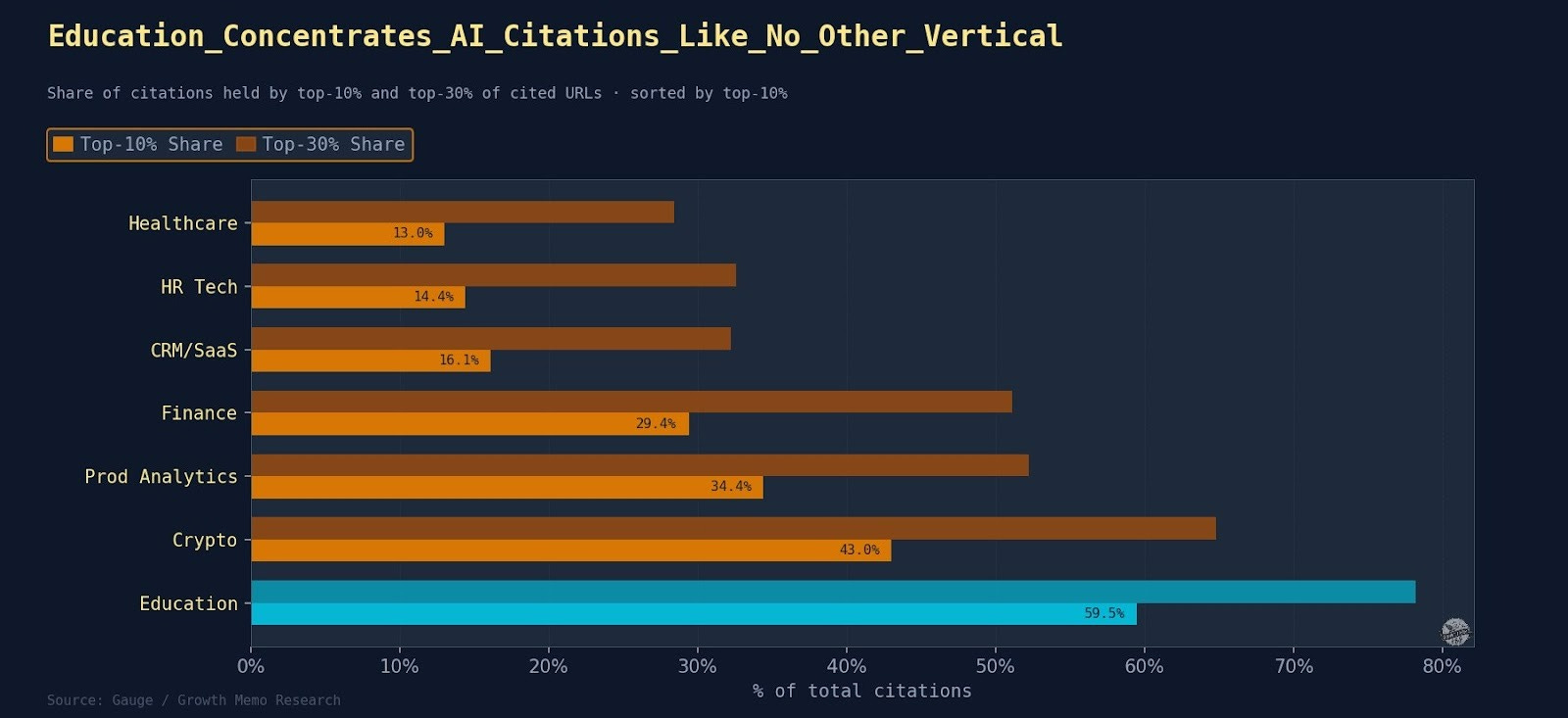
Die praktische Konsequenz daraus ist simpel:
Es gibt kein universelles GEO-Playbook. Was in Education funktioniert, kann in Healthcare schon wieder komplett anders aussehen.
Noch interessanter finde ich den URL-Befund: Laut Teil 2 erscheinen im Durchschnitt 67 Prozent der zitierten URLs nur in genau einem Prompt.
Die kleine Spitzengruppe mit echter Wiederholbarkeit sieht dagegen fast immer ähnlich aus: Vergleichsseiten, Category-Level-Guides oder Verzeichnis-/Listing-Seiten, die mehrere benachbarte Nutzerfragen auf einer URL bündeln.
Indig formuliert das ziemlich klar: Die Top-4,8 Prozent der URLs, die in 10 oder mehr Prompt-Kontexten zitiert werden, sind durchgehend Seiten, die „Was ist das?“, „Wer nutzt das?“, „Wie wählt man es aus?“ und „Was kostet es?“ gemeinsam auf einer Adresse beantworten.
Das ist ein wichtiger Shift für GEO:
Nicht nur einzelne Absätze müssen zitierfähig sein – ganze URLs müssen mehrere relevante Intents glaubwürdig abdecken.
Der Front-Loading-Effekt aus Teil 1 wird in Teil 2 bestätigt, aber zugleich präzisiert. Das unterste Seiten-Decile ist für ChatGPT fast totes Land: Je nach Vertical landen dort nur 2,4 bis 4,4 Prozent der Zitationen. Gleichzeitig liegt der eigentliche Peak laut Teil 2 häufig nicht im allerersten Decile, sondern eher im Bereich 10 bis 20 Prozent der Seite.
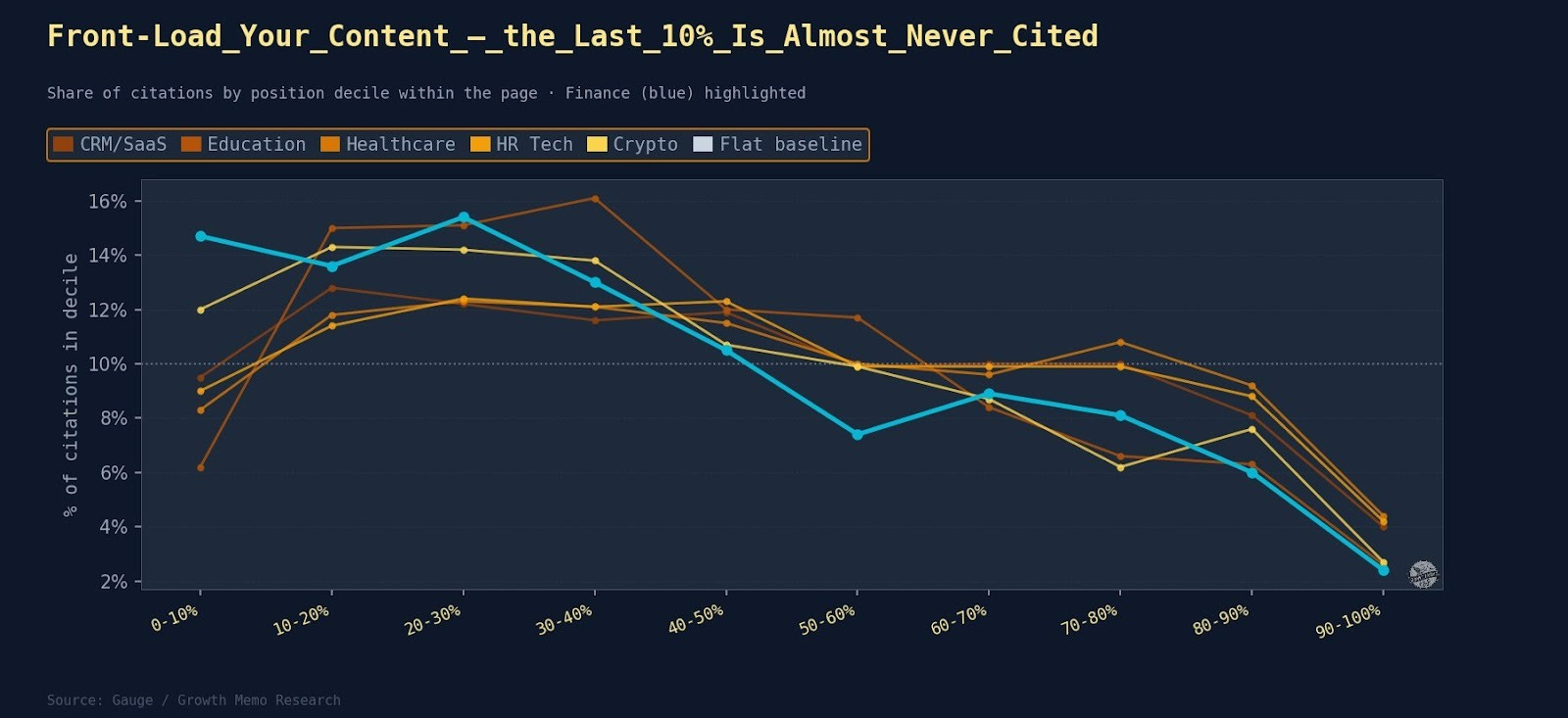
Der Grund ist plausibel: Die ersten 10 Prozent sind oft Navigation, Überschrift, Intro-Fluff und Boilerplate. Heißt praktisch: Nicht einfach „möglichst ganz oben“, sondern möglichst früh im ersten gehaltvollen Inhaltsblock müssen Definitionen, Zahlen, Vergleiche und klare Aussagen stehen.
Auch die Längenfrage wird durch Teil 2 eher differenzierter als simpler. Der Artikel zeigt zwar grundsätzlich einen positiven Zusammenhang zwischen Seitenlänge und Zitationshäufigkeit, betont aber selbst, dass der Effekt vertikalabhängig ist.
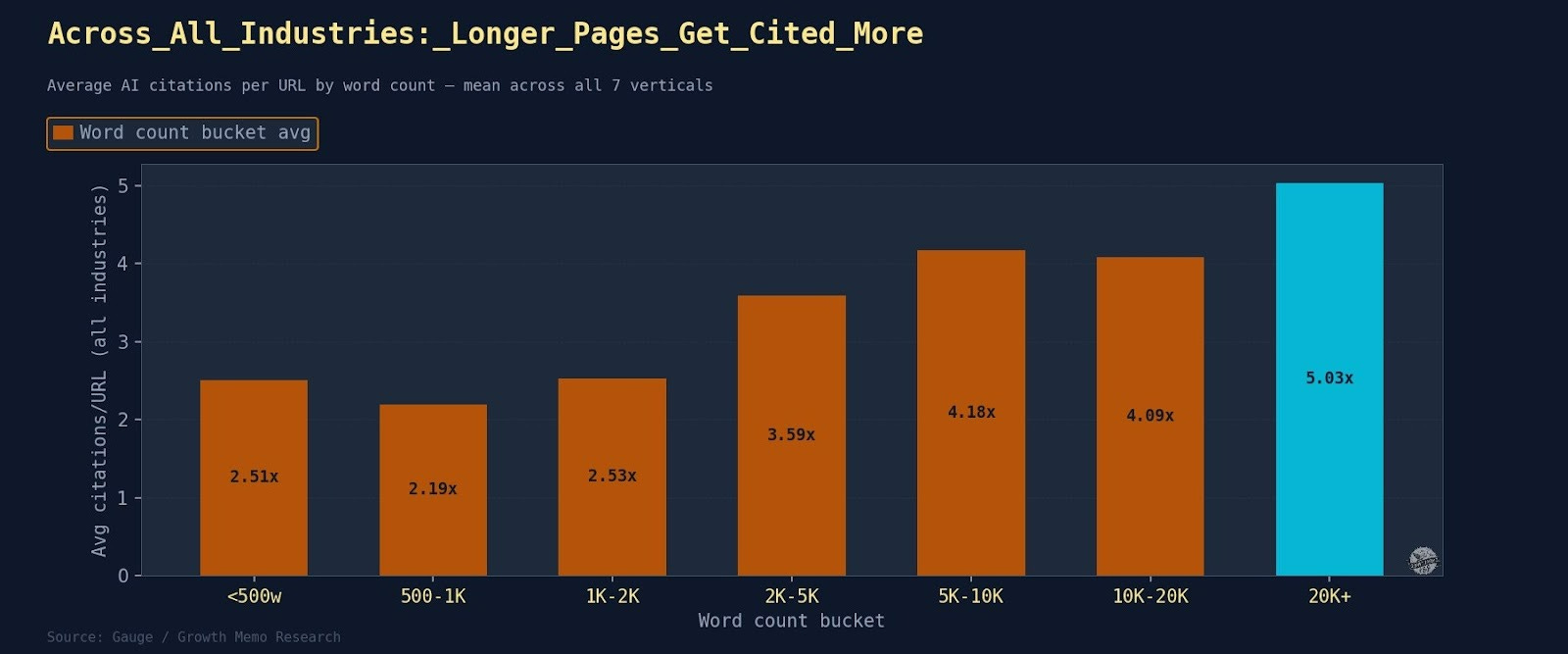
Für sehr kurze Seiten unter 1.000 Wörtern sieht es in allen Verticals schlecht aus. Aber schon bei Finance kippt die Logik teilweise: Dort schneiden kompaktere, autoritative Seiten, Tabellen und regulatorische Zusammenfassungen besser ab als immer längere Guides. In Education, Crypto und Product Analytics hilft Länge stärker; in SaaS zählt Struktur offenbar mehr als reine Wortmasse.
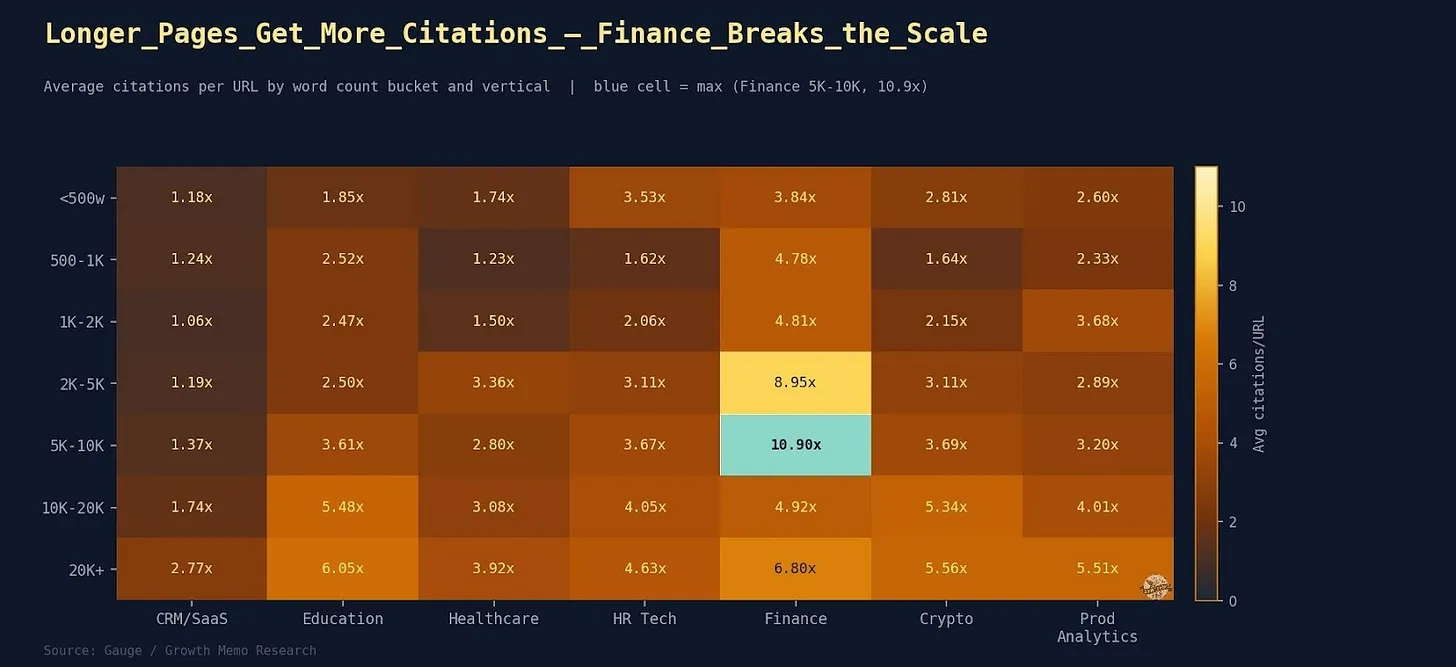
Auch hier ist die Lehre also nicht „mach es länger“, sondern „triff die Formatlogik deines Themas“.
Was in Teil 2 weiterhin fehlt, ist eine echte Trennung zwischen Retrieval, Auswahl und Zitat.
Genau da hilft die ergänzende AirOps-Analyse vom 12. März 2026 weiter. Sie basiert auf 15.000 Originalprompts, 43.233 Original- plus Fan-out-Queries und 548.534 abgerufenen Seiten. Das Ergebnis ist ziemlich ernüchternd: 85 Prozent der von ChatGPT abgerufenen Seiten werden nie zitiert. Auf 89,6 Prozent der Suchen erzeugt ChatGPT zwei oder mehr Fan-out-Queries, und 32,9 Prozent der zitierten Seiten, die überhaupt in Top-20-SERPs auftauchen, wurden ausschließlich über solche Fan-out-Suchen sichtbar.
Übersetzt: Gute Copy allein reicht nicht. Wer gar nicht erst im erweiterten Recherchepfad auftaucht, kann noch so schön formulieren – zitiert wird er trotzdem nicht.
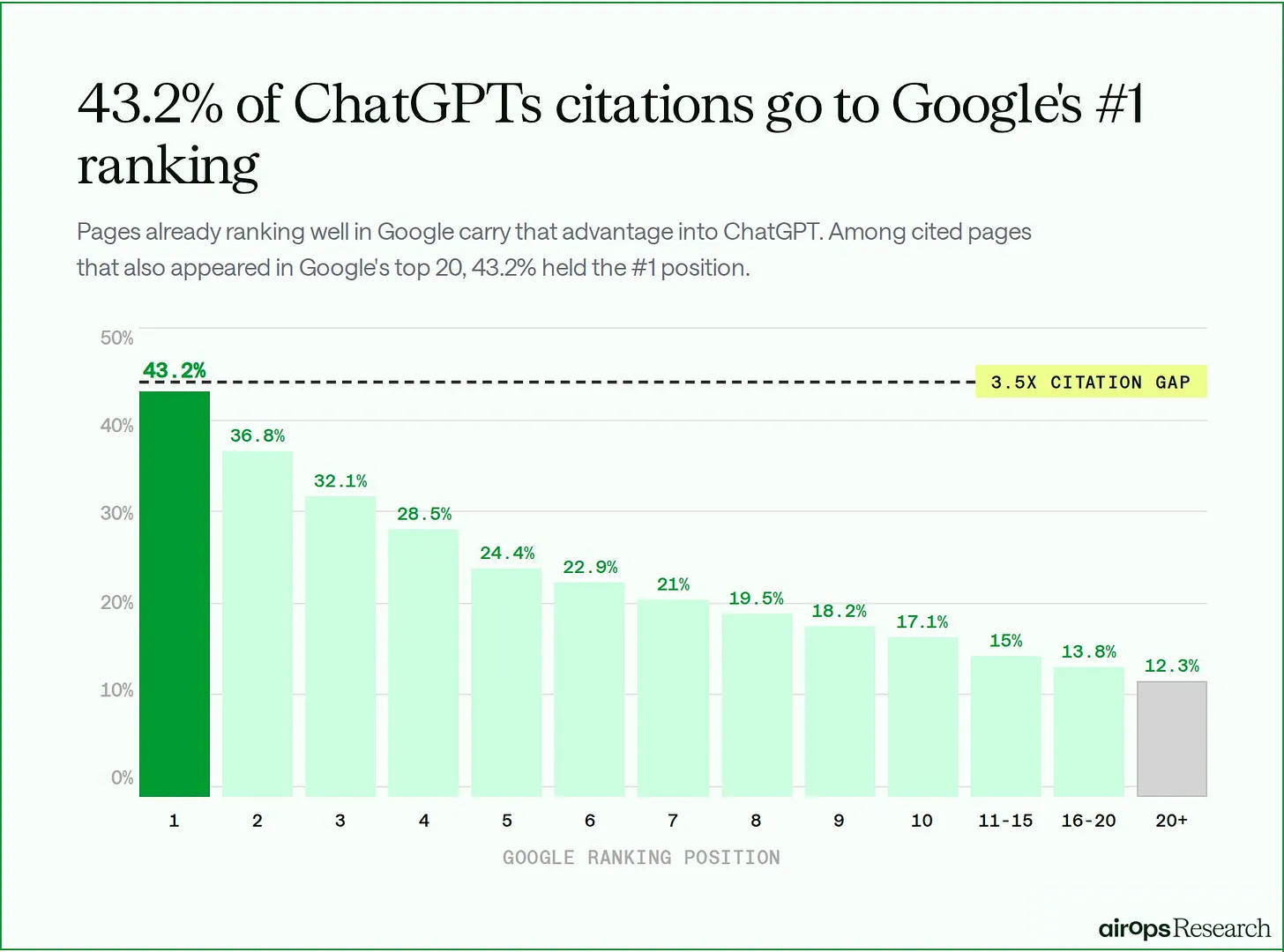
Genau deshalb ist Teil 2 für die Praxis wertvoller als Teil 1 allein. Er zeigt, dass GEO auf mindestens drei Ebenen stattfindet: Passage, URL und Themenraum.
- Auf Passage-Ebene bleiben die alten Regeln gültig: Klarheit, frühe Platzierung, hohe Entitätsdichte, konkrete Aussagen.
- Auf URL-Ebene gewinnen Seiten, die mehrere benachbarte Fragen strukturiert bündeln.
- Und auf Themenraum-Ebene entscheidet die Marktstruktur darüber, ob du in einem offenen Feld spielst oder gegen eine Handvoll bereits zementierter Gewinner antreten musst.
Diese drei Ebenen gehören zusammen. Wer nur schöner schreibt, verliert. Wer nur breiter clustert, aber keine zitierfähigen Passagen liefert, ebenfalls.
Trotzdem bleibt methodische Vorsicht angebracht. Der frei zugängliche Text des zweiten Teils enthält selbst kleine definitorische Stolperstellen: Eine Überschrift spricht davon, dass 58 Prozent der zitierten URLs nur einmal auftauchen, im Ergebnisteil stehen dann 67 Prozent. Außerdem springt die Längenpassage zwischen Wörtern und Zeichen.
Das sind keine vernichtenden Einwände, aber sie sind ein guter Reminder: Wir lesen hier keine peer-reviewte Grundlagenforschung, sondern eine nützliche, proprietäre Branchenanalyse. Und genau so sollte man sie auch behandeln.
Mein Fazit nach Veröffentlichung von Teil 2
Die ursprüngliche Kernthese bleibt richtig, wird aber breiter.
Ja, ChatGPT bevorzugt klare, frontgeladene und gut strukturierte Inhalte. Aber Sichtbarkeit in KI-Antworten entsteht nicht nur auf Satzebene.
Sie entsteht auch auf der Ebene von Seitentypen, Query-Clustern und ganzen Themenarchitekturen.
GEO ist damit weder bloß „schreib sauberer“ noch bloß „bau Pillar Pages“.
Es ist die Verbindung aus zitierfähiger Passage, intelligenter URL-Architektur und strategischer Themenabdeckung.
Methodische Einordnung: Was ist Teil 2 wissenschaftlich wert?
Weil ich den ersten Teil ausführlich methodisch zerlegt habe, ist es nur fair, auch Teil 2 nach denselben Maßstäben einzuordnen. Und das Ergebnis ist differenzierter, als ein einfaches Daumen-hoch oder -runter vermuten lässt.
Am treffendsten ist Teil 2 als explorative, nicht-experimentelle Beobachtungsanalyse mit proprietärer Datenbasis einzuordnen.
Der Text erscheint als Growth-Memo-Beitrag, nicht als Fachpublikation. Im Methodikteil beschreibt Indig rund 98.000 ChatGPT-Citation-Rows aus etwa 1,2 Millionen ChatGPT-Antworten über sieben Verticals. Die einzelnen Kernaussagen operieren aber mit ganz unterschiedlichen Teilstichproben: 21.482 Citation-Rows und 670 Domains für die Konzentrationsanalyse, 42.460 matched citations für die Positionsauswertung, 2.344 URLs und 127 Prompts an anderer Stelle. Als Analyseverfahren kommen unter anderem Structural Parsing, Jaccard-Sliding-Window-Similarity für die Positionszuordnung sowie Entity- und Sentiment-Extraktion per Google Natural Language API und TextBlob zum Einsatz.
Was gut dokumentiert ist – und was nicht
Für die Einordnung eignet sich die STROBE-Leitlinie als Maßstab. Wichtig: STROBE ist kein Gütesiegel für Methodenqualität, sondern ein Standard dafür, was Leserinnen und Leser über Design, Variablen, Bias, Studiengröße, statistische Methoden und Limitationen erfahren sollten.
Nach diesem Maßstab ist Teil 2 besser dokumentiert als viele reine SEO-Meinungsstücke – aber er bleibt deutlich unter dem Niveau einer voll transparent berichteten Beobachtungsstudie.
Was da ist: Datengröße, Verticals, einzelne Analyseverfahren.
Was fehlt: Der Sampling-Frame der Prompts, Ein- und Ausschlussregeln, der genaue Erhebungszeitraum, systematische Bias-Adressierung, Sensitivitätsanalysen und Präzisionsmaße.
Das Reproduzierbarkeitsproblem
Die größte methodische Schwäche betrifft die unabhängige Prüfbarkeit. Die National Academies unterscheiden zwischen direkter rechnerischer Reproduzierbarkeit und indirekter Transparenzprüfung – und betonen, dass Reproduktionen oft schon an zu wenig Detail zu Daten, Code und Workflow scheitern.
Im Fall von Teil 2 werden weder Rohdaten noch Code offengelegt. Die zugrunde liegende Datenbasis stammt aus Gauge, einer proprietären Plattform.
Eine unabhängige Reproduktion der Ergebnisse ist für Dritte damit derzeit praktisch nicht möglich.
Korrelation, nicht Kausalität
Beobachtungsstudien sind nicht randomisiert und deshalb grundsätzlich anfällig für Confounding. Ohne explizite Adjustierungen lassen sich aus ihnen primär Assoziationen ableiten, keine belastbaren Ursache-Wirkung-Aussagen.
Teil 2 berichtet zwar Unterschiede nach Seitenlänge, URL-Typ und Position auf der Seite – aber keine multivariaten Adjustierungen, Konfidenzintervalle oder Robustheitsanalysen. Aussagen wie ein angeblicher „citation advantage“ ab einer bestimmten Textlänge sollte man deshalb als deskriptive Korrelationen in diesem Datensatz lesen, nicht als Nachweis einer isolierten kausalen Wirkung von Textlänge.
Externe Validität: gemischt
Positiv ist, dass die Analyse sieben Verticals separat betrachtet – ausdrücklich, um themenspezifische Muster nicht in einer Gesamtauswertung zu verwischen. Gleichzeitig bleibt der Geltungsbereich eng: Untersucht werden ChatGPT-Zitationen aus einer proprietären Gauge-Datenbasis, nicht mehrere Modelle unter identischen Bedingungen und auch nicht „KI-Suche“ im Allgemeinen.
Die Ergebnisse sind am überzeugendsten als ChatGPT-nahe Marktbeobachtung und als Hypothesengenerator zu lesen – nicht als universelles Gesetz darüber, wie „AI“ allgemein Quellen auswählt.
Ein Wort zur Unabhängigkeit
STROBE verlangt ausdrücklich Angaben zur Finanzierung und zur Rolle der Geldgeber. Im Beitrag wird Gauge als Datenquelle genannt; zugleich enthält derselbe Abschnitt eine Rabattaktion für Growth-Memo-Abonnenten auf Gauge. Das beweist keinen Fehler in den Ergebnissen – aber es erhöht aus wissenschaftlicher Sicht den Bedarf an sauberer Offenlegung, externer Validierung und unabhängigen Replikationen.
Mein nüchternes Urteil
Teil 2 ist keine „Studie“ im starken Sinn eines transparent reproduzierbaren Fachartikels. Er ist eine explorative, proprietäre Beobachtungsanalyse mit hohem Praxiswert und begrenzter Beweiskraft.
Stark genug, um Hypothesen zu generieren, Muster sichtbar zu machen und operative Benchmarks für GEO zu liefern. Für robuste kausale Aussagen oder allgemein verbindliche Regeln wären offenere Daten, vollständigeres Reporting, Unsicherheitsmaße, Sensitivitätsanalysen und unabhängige Replikationen notwendig.
Abonniere das AFAIK-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz im Online Marketing!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen Rund um KI aus den Bereichen Online-Marketing, SEO, GEO, WordPress und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Monat eine E-Mail von mir. Versprochen.