Ein neues Forschungspapier der Stanford University „Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking“ bringt gerade die KI-Welt in Bewegung. Darin wird eine KI beschrieben, die sich im Grunde selbst beibringt, vor dem Sprechen zu denken. Nach Einschätzung von Experten hat dieser Ansatz das Potenzial, die Art und Weise, wie KI Sprache versteht und verarbeitet, tatsächlich zu revolutionieren!
Eine Revolution des selbstgesteuerten Denkens?
Das Herzstück von Quiet-STaR ist das Konzept des autodidaktischen Denkens: Ähnlich wie Menschen (hoffentlich) eine Denkpause einlegen, bevor sie antworten, generiert dieses KI-Modell zunächst eine Reihe interner Argumente, also eine Art von Gedanken, um zukünftige Antworten besser vorherzusagen. Das wäre zwar mit einigen Loops und entsprechenden Prompts auch schon mit klassischen LLMs möglich, allerdings bringt sich Quiet-STaR tatsächlich selbst bei zu denken und welche Art von Argumentationen zur Lösung führen und welche nicht!
Quiet-STaR ist eine Weiterentwicklung des STaR Algorithmus von 2022 aus der gleichen Arbeitsgruppe. Darin wird aus Beispielen bei der Beantwortung von Fragen die impliziten Begründungen abgeleitet und das Modell versucht daraus zu lernen, welche Argumentationen zu einer richtigen Antwort führen. Das funktioniert jedoch nur in manchen Fällen. Im Idealfall könnten Sprachmodelle lernen, unausgesprochene Begründungen aus beliebigen Texten abzuleiten.
Im nun vorgestellten Quiet-STaR Algorithmus versucht man diese Verallgemeinerung von STaR, bei der Sprachmodelle lernen, bei jedem Token Begründungen zu generieren, um zukünftige Texte zu erklären und ihre Vorhersagen darüber zu verbessern. Mit dieser Herangehensweise erreicht es eine allgemeinere Denkfähigkeit, die über die aufgabenspezifische Feinabstimmung klassischer LLMs hinausgeht. Entscheidend ist, dass diese Verbesserungen bei diesen Aufgaben keinerlei Fine-Tuning erfordern. Quiet-STaR ist damit ein Schritt auf dem Weg zu Language Models, die auf eine allgemeinere und skalierbare Weise logisches Denken lernen können.
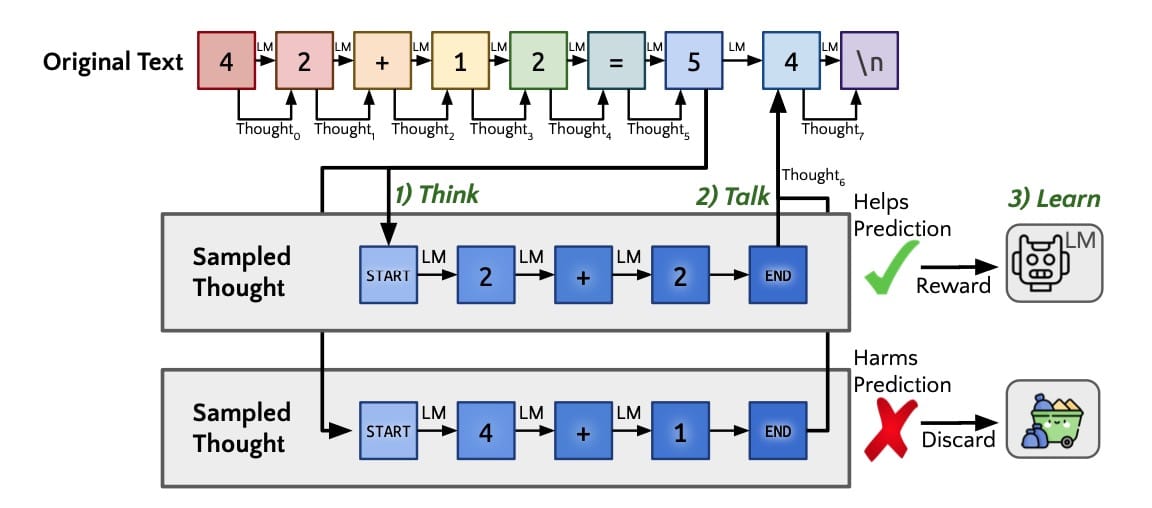
In Abbildung 1 aus dem Paper (arXiv:2403.09629 [cs.CL]) wird der Algorithmus so dargestellt, wie er beim Training auf einen einzelnen Gedanken angewendet wird. Dieser erzeugt parallel Gedanken, die allen Token im Text folgen (Think). Das Modell erzeugt eine Mischung aus seinen Vorhersagen für das nächste Token mit und ohne Gedanken (Talk). Wie bei STaR wird ein REINFORCE Mechanismus verwendet, um die Wahrscheinlichkeit von Gedanken zu erhöhen, die dem Modell helfen, den zukünftigen Text immer besser vorherzusagen, während er Gedanken verwirft, die den zukünftigen Text unwahrscheinlicher machen (Learn).
Diese Entwicklung hat weitreichende Folgen. Wenn KI-Systeme immer besser schlussfolgern, können sie komplexe Probleme besser bewältigen – von der technischen Unterstützung bis zur strategischen Planung. Außerdem kann die KI durch das Denken in Texten ein tieferes Verständnis von Sprache erlangen, was ihre Leistung bei Aufgaben wie Zusammenfassungen, Übersetzungen und der Erstellung von Inhalten verbessert.
Eine der wichtigsten Innovationen von Quiet-STaR dabei ist der parallele Sampling-Algorithmus. Dieser Ansatz ermöglicht es der KI, Begründungen für jedes Token in einem Text gleichzeitig zu generieren, wodurch der Argumentationsprozess skalierbar und effizient wird. Dennoch bleiben andere Herausforderungen, wie der generelle Rechenaufwand für die Generierung von Fortsetzungen, sowie die Tatsache, dass das Modell anfangs nicht weiß, wie es interne Gedanken generieren oder verwenden soll, grundsätzlich bestehen.
Ist Quiet-STaR OpenAIs Q-Star???
Das Ganze könnte besondere Aufmerksamkeit auf sich ziehen, weil man Quiet-STaR auch mit Q-Star oder Q* abkürzen könnte, der Name jenes geheimen Projekts von OpenAI, das nach wie vor für Spekulationen und Kontroversen in der KI-Gemeinschaft sorgt.
Zur Erinnerung: Das Projekt hatte bei Forscherinnen und Forschern von OpenAI Besorgnis ausgelöst, die Berichten zufolge einen Brief an den Vorstand geschrieben haben, in dem sie vor einem Durchbruch der künstlichen Intelligenz warnten. Dieser Brief war eine der wichtigsten Entwicklungen, bevor der Vorstand den CEO von OpenAI, Sam Altman, absetzte, der später wieder eingestellt wurde. Die genauen Einzelheiten der Bedenken, die in dem Brief geäußert wurden, sind nicht öffentlich bekannt, aber es wird vermutet, dass sie mit Sicherheitsbedenken angesichts der schnellen Fortschritte in der KI zusammenhängen.
OpenAI hat offiziell nicht viele Informationen über das Projekt veröffentlicht, aber es wird vermutet, dass es ein bedeutender Fortschritt in Richtung Künstliche Allgemeine Intelligenz (AGI) ist. Berichten zufolge zeigt das Modell fortgeschrittene Denkfähigkeiten und die Fähigkeit, Matheaufgaben auf Grundschulniveau zu lösen – Aufgaben, mit denen aktuelle KI-Modelle Schwierigkeiten haben.
Trotz der Kontroverse und der Spekulationen sind die genaue Natur und die Fähigkeiten von Q* noch weitgehend unbekannt, da es keine offiziellen Informationen von OpenAI gibt.
Auf den ersten Blick, konnte ich keine direkten Verbindungen von Quiet-STaR zu OpenAI finden. Der Hauptautor des Quiet-STaR Papers, Eric Zelikman, ist Doktorand an der Stanford University und fasziniert davon, wie (und ob) Algorithmen sinnvolle Darstellungen und Schlussfolgerungen lernen können. Er arbeitet laut seiner Website unter Nick Haber, Assistenzprofessor an der Stanford Graduate School of Education sowie Noah D. Goodman, Assistenzprofessor für Psychologie, Informatik und Linguistik an der Stanford University.
Allerdings hat man bei OpenAI mit Sicherheit das vorgehende Paper STaR gelesen und vielleicht eine eigene Idee zur Skalierung des Algorithmus gehabt, der ähnlich oder auch komplett anders sein könnte, wie das nun vorgestellte Quiet-STaR.
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.




