

Als ich Anfang 2023 mein Buch über ChatGPT & Co. geschrieben habe, habe ich mich auch damit auseinander gesetzt, ob Suchmaschinen wie Google oder Lehrkräfte an Schulen und Hochschulen zuverlässig erkennen können, ob ein Text vollständig oder teilweise von einer generativen KI geschrieben wurde.
GPTZero, eine der ersten Ansätze, die mir in meiner Recherche aufgefallen sind, war zum damaligen Zeitpunkt noch nicht öffentlich verfügbar, also habe ich mich mit den theoretischen Hintergründen und dem aktuellen Stand der KI-Forschung beschäftigt und mir die Frage gestellt, ob es überhaupt möglich sein kann und ob sich der Aufwand einer AI-Content-Erkennung, beispielsweise für Suchmaschinen überhaupt lohnt:
Lassen sich KI-generierte Texte erkennen?
In meinem Buch schrieb ich damals:
Die rasanten Fortschritte in letzter Zeit führen dazu, dass immer mehr Texte von Sprachmodellen generiert werden und in den unterschiedlichsten Bereichen eingesetzt werden. Da drängt sich die wichtige Frage auf, ob man solche Texte automatisch erkennen kann? Nach derzeitigen Erkenntnissen scheint dieser Kampf jedoch eine Sisyphos-Aufgabe zu sein, denn KI-Detektoren stehen vor großen Herausforderungen: Ein Team von Forschern der Universität von Maryland [1] fand heraus, dass selbst die besten Detektoren, keine absolute Sicherheit bieten können.
So können bereits einfache Umformulierungen oder kleinere Änderungen an den generierten Texten die Detektoren täuschen. Selbst die besten Detektoren schneiden kaum besser ab als ein rein zufälliger Klassifikator. Man könnte also genauso gut eine Münze werfen und sich auf diese Weise entscheiden, ob ein Text KI-generiert ist oder nicht.
OpenAI arbeitet derzeit zwar an einem Tool, das die Ausgaben eines Text-KI-Systems mit unsichtbaren Wasserzeichen versieht [2], doch auch hier gibt es Schwachstellen: Die Forscher meinen, dass Menschen in der Lage sein könnten, die Wasserzeichen zu entschlüsseln und sie in andere, nicht von einer KI geschriebene Texte einzufügen. Dadurch würden die Erkennungsmechanismen ad absurdum geführt.
Es ist offensichtlich, dass eine verlässliche und einfache Lösung für das Erkennen von KI-generierten Texten derzeit nicht in Sicht ist. Die ethische und verantwortungsvolle Nutzung von solchen Texten sollte dennoch oberste Priorität haben.
Für mich persönlich spielt es keine Rolle, ob ein Text von einer KI oder einem Menschen geschrieben wurde. Entweder es ist ein guter Text oder es ist kein guter Text. So sieht es auch aus Sicht der Suchmaschine aus. Entweder es ist Spam oder es ist kein Spam. Menschengeschriebener Spam ist genauso schlecht für die Qualität der Suchergebnisse wie KI-geschriebener Spam. Und ein richtig guter Artikel, der von der KI geschrieben wurde, ist genauso gut, wie wenn ihn ein Mensch geschrieben hätte.
Falls du dich also fragst, ob deine KI-generierten Texte in den Suchmaschinen gefunden werden, solltest du die Inhalte auf faktische Korrektheit überprüfen und dafür sorgen, dass deine Inhalte einen echten Nutzen für den Besucher bieten und ein Informationsbedürfnis erfüllen. Dann werden diese auch nicht abgestraft – warum sollten sie?
Auszug aus meinem Buch „Richtig texten mit KI“
[1] Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, Soheil Feizi: „Can AI-Generated Text be Reliably Detected?“, arXiv Pre-Print, abgerufen am 05.04.23, online abrufbar unter: https://kai.im/ai-text-detection
[2] Kyle Wiggers: „OpenAI’s attempts to watermark AI text hit limits“, Techcrunch, abgerufen am 14.02.23, online verfügbar unter: https://kai.im/openai-watermark
Was ist seit dem passiert?
Seit dem Erscheinen meines Buches hat OpenAI seinen AI Classifier bereits Mangels Treffsicherheit zurück gezogen. Das Programm sollte KI-erzeugte Texte erkennen. Das klappte jedoch nicht zuverlässig genug: „Der AI Classifier ist nicht mehr verfügbar aufgrund seiner geringen Genauigkeit“, gesteht OpenAI ein.
Daher hatte ich für mich mit dem Thema abgeschlossen und als nicht weiter interessant betrachtet. Doch mich hat ein Kollege darauf aufmerksam gemacht, dass offenbar immer häufiger Texte von Vorgesetzten oder Kunden abgelehnt werden, weil diese angeblich mittels künstlicher Intelligenz geschrieben wurden und große Sorge darüber besteht, dass man hierfür womöglich rechtliche Konsequenzen oder gar eine Abstrafung seitens der Suchmaschinen befürchten müsste.
In den Fachabteilungen macht man sich offenbar Gedanken darüber, wie man verhindern kann, dass die eigenen Inhalte als KI-generiert erkannt werden – Was mich an die Bemühungen erinnert, gekaufte Links oder ganze Linkprofile als möglichst „organisch“ erscheinen zu lassen.
Als Beispiel für ein derartiges Tool, das KI-Texte erkennen soll, wurde mir copyleaks genannt. Das musste ich mir also umgehend ansehen, immerhin bezeichnet sich das Unternehmen selbst als die „einzige Enterprise KI-Erkennungslösung“ und verspricht:
Von der Sicherstellung der Cyber-Compliance bis zur Verhinderung von Urheberrechtsverletzungen ist es entscheidend zu wissen, welche Inhalte von Menschen erstellt wurden und welche von KI. Mit einer Genauigkeit von 99,1 % und einer vollständigen Modellabdeckung, einschließlich GPT-4 und Bard, ist der Copyleaks AI Content Detector die umfassendste und genaueste Lösung auf dem Markt.
Auszug aus der Webseite von copyleaks

Man sei dabei die einzige Plattform, die KI-Inhalte in mehreren Sprachen erkennt, eine genaue Wahrscheinlichkeitsbewertung von KI-Inhalten liefert und sogar die spezifischen Teile eines Textes hervorhebt, die von einem Menschen geschrieben wurden, und die, die von KI geschrieben wurden. Ja sogar umgeschriebene Inhalte will man erkennen können!
Wow, das klingt beeindruckend. Und sieht auf den ersten Blick auch irgendwie überzeugend aus, immerhin vertrauen „führende Organisationen und Institutionen“ offenbar auf copyleaks:

Doch auf den zweiten Blick werde ich hier stutzig: Wieso werden hier nur unbedeutende Colleges und Universitäten aufgeführt und keine aus der Ivy League?
Der erste WTF-Moment kam mir direkt im nächsten Abschnitt der Webseite:
Man arbeit seit fast einem Jahrzehnt an der KI-Erkennungslösung!
Seit 2015 lernt die Copyleaks-KI-Engine, wie Menschen schreiben, indem sie Billionen von Seiten aus verschiedenen Quellen sammelt und analysiert, darunter: Arbeiten von Tausenden von Institutionen und Millionen von Schülern aus Bildungsinstitutionen sowie Marketinginhalte, Whitepaper und Forschungsarbeiten aus über 300 Unternehmen.
Auszug aus der Webseite von copyleaks
Wer die Entwicklung von generativer KI über die letzten 10 Jahre verfolgt hat weiß, dass das entscheidende Paper „Attention Is All You Need“ jedoch erst 2017 von Google-Forschern veröffentlich wurde und alle Modelle vor GPT-2 weit entfernt davon waren, Texte zu schreiben, die man für menschengeschrieben halten könnte.
Ich finde es extrem problematisch, wenn der Eindruck erweckt wird, man könnte KI-Texte zuverlässig erkennen. Eines der Hauptprodukte von copyleaks ist immerhin die Bewertung von Aufsätzen und studentischen Arbeiten für Bildungseinrichtungen und da will ich mir garnicht vorstellen, was es bedeutet, wenn jemand wegen einer fehlerhaften Erkennung Probleme mit der Prüfungskommission bekommen könnte. Erste Berichte über falsche Anschuldigungen machten bereits die Runde.
copyleaks behauptet auf seiner Webseite selbstbewusst:
Wir haben mehr als 20.000 von Menschen verfasste Beiträge getestet und die Rate der Falschmeldungen lag bei 0,2 % – die niedrigste Falschmeldungsrate aller Plattformen. Außerdem testen wir unser KI-Modell ständig und trainieren es mit neuen Daten und Feedback, um die Genauigkeit zu verbessern.
Damit müsse „niemand Angst vor falschen Positivmeldungen haben, die zu falschen Anschuldigungen führen können“.
Doch ist das wirklich so?
Ansätze für die Erkennung und deren Grenzen
Die Fähigkeit, Texte zu erkennen, die von Künstlicher Intelligenz (KI), insbesondere von großen Sprachmodellen (LLMs), generiert wurden, ist ein sich schnell entwickelndes Forschungsgebiet mit weitreichenden Implikationen für Bereiche wie Cybersicherheit und akademische Integrität. Mit der zunehmenden Verfeinerung der LLMs wird die Unterscheidung zwischen von Menschen verfassten und von KI generierten Inhalten jedoch immer schwieriger.
Dennoch existieren zahlreiche Ansätze, die zum Teil weit entwickelt und ständig verfeinert werden. Diese lassen sich in technische und stilometrische Methoden unterteilen, um unterschiedliche Aspekte der Textgenerierung und -modellierung zu nutzen.
Die Erkennung KI-generierter Texte in Zeiten großer Sprachmodelle stellt jedoch eine zunehmende Herausforderung dar, bei der die Praktikabilität und Zuverlässigkeit der verschiedenen Ansätze kritisch betrachtet werden muss. Jede Methode hat ihre spezifischen Einschränkungen, die ihre Effektivität und Anwendbarkeit in realen Szenarien beeinflussen können.
Technische Ansätze
Maschinenlern-Klassifikatoren
Durch das Training von Maschinenlernmodellen mit großen Datensätzen von von Menschen geschriebenen und KI-generierten Texten können Forscher:innen Klassifikatoren entwickeln, die den Ursprung eines neuen Textes vorhersagen. Merkmale, die von diesen Modellen verwendet werden, können Textkohärenz, Komplexität, die Verwendung bestimmter Phrasen oder syntaktische Muster umfassen, die in KI-generierten Texten häufiger vorkommen.
Probleme dabei:
- Das Training effektiver Klassifikatoren erfordert umfangreiche und vielfältige Datensätze, die sowohl von Menschen geschriebene als auch KI-generierte Texte umfassen. Die Beschaffung und Aufrechterhaltung dieser Datensätze ist ressourcenintensiv.
- Klassifikatoren können durch die schnelle Evolution der KI-Modelle schnell veralten. Zudem besteht die Gefahr, dass sie durch innovative Textgenerierungsmethoden, die bestehende Erkennungsmuster umgehen, getäuscht werden.
Statistische Mustererkennung
KI-generierte Texte können statistische Anomalien aufweisen oder die Variabilität vermissen lassen, die in von Menschen geschriebenen Texten zu finden ist. Techniken wie die Analyse von N-Gramm-Häufigkeiten, Variationen der Satzlänge und andere statistische Merkmale können genutzt werden, um Muster zu identifizieren, die charakteristisch für KI-generierte Inhalte sind.
Das Problem dabei: Große Sprachmodelle werden darauf trainiert, menschliche Variabilität in Texten zu imitieren, wodurch die Unterscheidungskraft statistischer Muster verringert wird.
Wasserzeichen
Einige Forscher erkunden die Möglichkeit, Wasserzeichen in die Ausgaben von LLMs einzubetten. Diese Wasserzeichen, die subtile Muster in der Wortwahl oder Satzstruktur sein könnten, würden die Lesbarkeit des Textes nicht beeinträchtigen, könnten jedoch von spezialisierten Algorithmen erkannt werden. Die Implementierung von derartigen Wasserzeichen erfordert grundsätzlich Zugriff auf den Entwicklungsprozess der Modelle, was bei proprietären Systemen nicht immer möglich ist.
Das Hauptproblem: Wasserzeichen können umgangen, entfernt oder sogar in menschliche Texte eingebaut werden, sobald die Methoden ihrer Einbettung bekannt sind.
Stilometrische Ansätze
Konsistenz- und Kohärenzanalyse
KI-generierte Texte, insbesondere längere, können Schwierigkeiten haben, thematische oder faktische Konsistenz aufrechtzuerhalten. Eine Analyse eines Textes auf wiederholte oder widersprüchliche Informationen kann ein Indikator für eine KI-Autorschaft sein.
Die Durchführung einer gründlichen Konsistenzprüfung erfordert fortschrittliche Analysetools und kann bei längeren Texten herausfordernd sein. Neuere KI-Modelle verbessern ständig ihre Fähigkeit, kohärente und thematisch konsistente Texte zu generieren, was die Wirksamkeit dieser Methode in den letzten Jahren stark eingeschränkt hat.
Stilistisches Fingerprinting
Jeder Autor hat einen einzigartigen Schreibstil, einschließlich Vorlieben für bestimmte Phrasen, Interpunktion und Struktur. Durch den Vergleich des stilistischen Fingerabdrucks eines Textes mit bekannten menschlichen und KI-Fingerabdrücken ist es möglich, eine fundierte Vermutung über dessen Ursprung anzustellen.
Dieser Ansatz benötigt umfangreiche Vergleichsdatenbanken mit menschlichen und KI-Stilen, deren Aufbau und Pflege aufwendig sein kann. Außerdem können KI-Systeme, die auf die Nachahmung spezifischer Schreibstile trainiert sind, stilistische Fingerabdrücke effektiv imitieren, was die Zuordnung erschwert.
Was sagt die Fachwelt dazu?
Im Dezember 2023 trafen sich auf der Neurips-Konferenz in New Orleans führende KI-Forscher, um über das brandaktuelle Thema der Erkennung von Deep-Fakes und anderen KI-generierten Betrügereien zu diskutieren. Die Konferenz beleuchtete die Bemühungen von Unternehmen wie Intel und Microsoft, die mittels spezieller Software solche Täuschungen aufspüren wollen. Parallel dazu wird an Techniken gearbeitet, um echte Bilder, Videos und Texte durch „Wasserzeichen“ von KI-generierten Medien zu unterscheiden.
Eine Umfrage des Economist unter Konferenzteilnehmern zeigte jedoch eine skeptische Stimmung: 17 von 23 Befragten glauben nicht an die langfristige Erkennbarkeit KI-generierter Medien. Nur ein Einziger äußerte Optimismus bezüglich zuverlässiger Erkennungsmethoden.
Die derzeitige Erkennungssoftware basiert auf der Annahme, dass KI-Modelle erkennbare Spuren hinterlassen. Früher konnten Menschen solche Fehler leichter erkennen, wie z.B. missgebildete Hände in Bildern. Heute jedoch werden diese Unzulänglichkeiten immer seltener, und die Software muss subtilere Merkmale identifizieren.
Die Erkennungstechnik ist jedoch nicht fehlerfrei und neigt zu falsch-positiven sowie falsch-negativen Ergebnissen. Studien, wie eine von Zeyu Lu der Shanghai Jiao Tong University, belegen, dass selbst leistungsfähige Programme KI-generierte Bilder nicht immer korrekt identifizieren. Ähnlich unbefriedigend sind die Ergebnisse bei Texterkennung.
Eine alternative Methode ist das Einbetten digitaler Wasserzeichen in KI-generierte Medien. Diese Technik, vorgeschlagen von Forscherteams der University of Maryland und der University of California, Santa Barbara, nutzt subtile Unterscheidungsmerkmale, die jedoch offensichtlich werden, wenn man danach sucht. Eine weitere Methode, das „Tree-Ring“-Wasserzeichen, wird während der Erstellung des digitalen Bildes angewendet, um die Erkennung auch nach Bearbeitung des Bildes zu ermöglichen.
Trotz dieser Innovationen bleibt die Frage der Effektivität offen. Forscher der Harvard University und der University of Maryland haben bereits Methoden entwickelt, um solche Wasserzeichen zu entfernen oder zu umgehen.
Die amerikanische Regierung hat im Juli 2023 „freiwillige Verpflichtungen“ mit mehreren KI-Firmen, darunter OpenAI und Google, angekündigt, um die Forschung in diesem Bereich zu fördern. Dies zeigt, dass auch unvollkommene Schutzmechanismen als besser angesehen werden als gar keine. Dennoch scheint es, als hätten die Fälscher aktuell die Oberhand im Kampf gegen die Detektive.
Einblicke in aktuelle KI-Forschung
Mittlerweile beschäftigt sich neues Gebiet der Forschung mit Fragen wie „Lassen sich KI-Texte zuverlässig erkennen?“. In den letzten Monaten wurden dazu sehr interessante Paper veröffentlicht.
KI-Firmen aber auch KI-Forscher haben verschiedene Methoden entwickelt, um KI-Texte zu identifizieren. Manche fügen beispielsweise unsichtbare Wasserzeichen in die Texte ein. Andere analysieren statistische Eigenschaften wie die Zufälligkeit der Wörter. Wieder andere vergleichen neue Texte mit bereits bekannten KI-Texten. Diese Detektoren erreichen teilweise schon beeindruckende Erkennungsraten.
Doch neue Studien zeigen auch ihre Grenzen auf. Oft reicht es aus, wenn man KI-Texte mit einem einfachen Programm umschreibt. Dann fallen die Wasserzeichen und statistischen Marker weg und die Detektoren versagen. Selbst wenn man KI-Texte in einer Datenbank speichert und neue Texte mit diesen vergleicht, können geschickte Umschreibungen die Erkennung austricksen.
Noch grundlegender ist das theoretische Limit, das Forscher errechnet haben: Wenn KI-Systeme immer menschlicher schreiben, werden auch die besten Detektoren irgendwann ratlos. Derzeit kommen die besten Detektoren im Labor auf eine Erkennungsrate von über 90 Prozent. Aber schon bei einer Fehlerrate von nur 10 Prozent wären in der Praxis unzählige Texte falsch eingeschätzt.
Zudem zeigte sich, dass viele Detektoren Texte von Menschen mit schlechten Sprachkenntnissen häufig fälschlicherweise als KI-Text einordnen. Die Systeme sind also nicht nur fehleranfällig, sondern diskriminieren auch bestimmte Gruppen.
Forscher mahnen deshalb, die Fähigkeiten der Detektoren nicht zu überschätzen. Bevor sie in der Praxis eingesetzt werden, müssen sie umfassend getestet werden. Sonst könnten sie mehr Schaden als Nutzen anrichten. Langfristig braucht es wohl neue Ansätze. So könnte man KI-Systeme von vornherein so gestalten, dass ihre Texte nachweisbar von Menschen geschrieben wurden. Vorläufig bleibt es also spannend, ob es künftig gelingt, den stetig verbesserten KI-Textgeneratoren ebenso clevere Detektoren gegenüberzustellen.
Dank Debora Weber-Wulff, einer emeritierten Professorin an der HTW Berlin bin ich auf das Pre-Print „Testing of Detection Tools for AI-Generated Text“ gestoßen. Darin hat sich die „working group on Technology & Academic Integrity at the European Network for Academic Integrity“ mit 12 kostenlosen KI-Checkern und zwei bezahlten KI-Erkennungstools beschäftigt.
Getestet wurden dort die Tools: Check For AI, Compilatio, Content at Scale, Crossplag, DetectGPT, Go Winston, GPT Zero, GPT-2 Output Detector Demo, OpenAI Text Classifier, PlagiarismCheck, TurnItIn, Writeful, GPT Detector, Writer sowie Zero GPT. Copyleaks war zwar nicht Teil dieses Tests, doch die Forscherinnen und Forscher kommen ebenfalls zu dem Schluss, dass die verfügbaren Erkennungswerkzeuge weder genau, noch zuverlässig sind und vor allem dazu neigen, Texte als von Menschen geschrieben zu klassifizieren, anstatt KI-generierten Text zu erkennen.
Diese Arbeitsgruppe arbeitet speziell an der Erprobung von KI-generierten Texterkennungsprogrammen und testet 14 Tools, die allesamt behaupten, KI-generierte Texte zu erkennen. Die Ergebnisse werde gerade auf der ECEIA 2023 vorgestellt, der Pre-Print, sowie die Rohdaten für den KI-Erkennungstest sind bereits veröffentlicht. Außerdem hat das ENAI Empfehlung für den ethischen Einsatz von KI in der Bildung als Leitartikel im „International Journal for Educational Integrity“ veröffentlicht.
Wir dürfen hier weitere Veröffentlichungen erwarten, denn die jüngsten Fortschritte bei großen Sprachmodellen und generativer künstlicher Intelligenz haben gerade in der akademischen Welt viele Bedenken hinsichtlich ihrer ethischen Verwendung und der richtigen Bewertungsstrategien aufgeworfen. Das Hauptaugenmerk der akademischen Integritätsgemeinschaft verschiebt sich daher zunehmend von Plagiaten und Unterschleif auf den Einsatz generativer künstlicher Intelligenz. Die ENAI-Arbeitsgruppe beschäftigt sich daher mit dem Testen von Hilfsmitteln zur Plagiatserkennung und erweiterte hierfür ihren Forschungsbereich um die Bereiche Technologie und akademische Integrität.
Können Menschen KI-Text erkennen?
Bei der ganzen Diskussion um die Zuverlässigkeit von Algorithmen, Tools und Machine Learning Modellen zur Erkennung von KI-generierten Texten stellt sich die berechtigte Frage, ob Menschen fähig sind diese zuverlässig zu identifizieren.
Ein aufschlussreiches Paper mit dem Titel „Do teachers spot AI? Evaluating the detectability of AI-generated texts among student essays“ wirft ein Licht auf die Schwierigkeiten, die Lehrkräfte bei der Unterscheidung zwischen von Schülern verfassten Arbeiten und solchen, die von KI erstellt wurden, erleben.
Die Studie zeigt auf, dass sowohl unerfahrene als auch erfahrene Lehrkräfte gleichermaßen Schwierigkeiten haben, KI-generierte Texte zu erkennen, was die Frage aufwirft, inwiefern Fachwissen tatsächlich eine Rolle bei der Identifizierung solcher Texte spielt. Besonders bei argumentativen Essays waren die Teilnehmer nicht in der Lage, die Herkunft der Texte korrekt zu bestimmen, was auf eine weitverbreitete Unsicherheit in Bezug auf die Erkennung von KI-generierten Inhalten hindeutet.
Interessanterweise zeigte sich, dass erfahrene Lehrkräfte zwar etwas erfolgreicher in der Identifizierung von Texten hoher Qualität waren, dennoch Probleme mit der Erkennung von minderwertigen KI-Texten hatten.
Dies unterstreicht die Komplexität der Thematik und die Notwendigkeit einer umfassenden Auseinandersetzung mit den Möglichkeiten künstlicher Intelligenz im Bildungssektor. Insbesondere betont dies auch die Notwendigkeit, Bewertungspraktiken neu zu überdenken.
KI-Text-Erkennung mit copyleaks im Praxistest
In meinem Test habe ich zunächst einige, zu 100% KI-generierte Texte überprüft, die ich ihm Rahmen eines SEO-Experiments für einen KI-generierten Glossar mittels ChatGPT (GPT-4) erzeugt hatte. Und siehe da, dieser wurde von copyleaks mit 99,9%iger Sicherheit wurde dieser Text als „AI-Inhalt erkannt“:
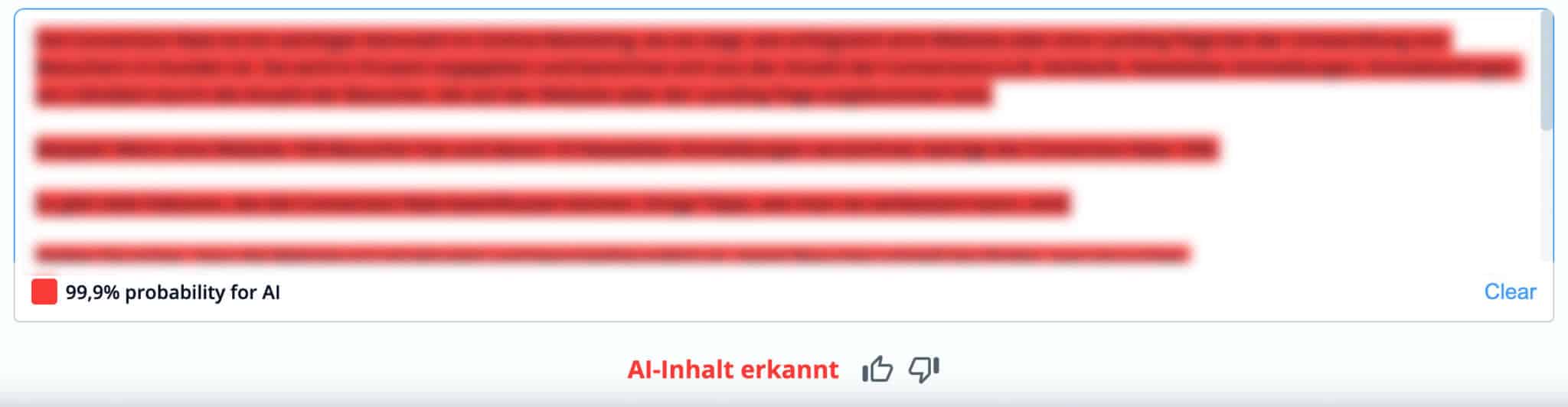
Den Text habe ich unkenntlich gemacht, da ich mein SEO-Ranking-Experiment nicht verfälschen und die Webseite preisgeben möchte.
Wow, das sieht doch wirklich überzeugend aus. Und auch die nächsten 10 KI-generierten Texte wurden als solche erkannt, jedes mal mit einer Wahrscheinlichkeit über 99%.
Der selbe Text wurde von GPTzero übrigens als „wahrscheinlich komplett von einem Menschen geschrieben“ eingestuft:
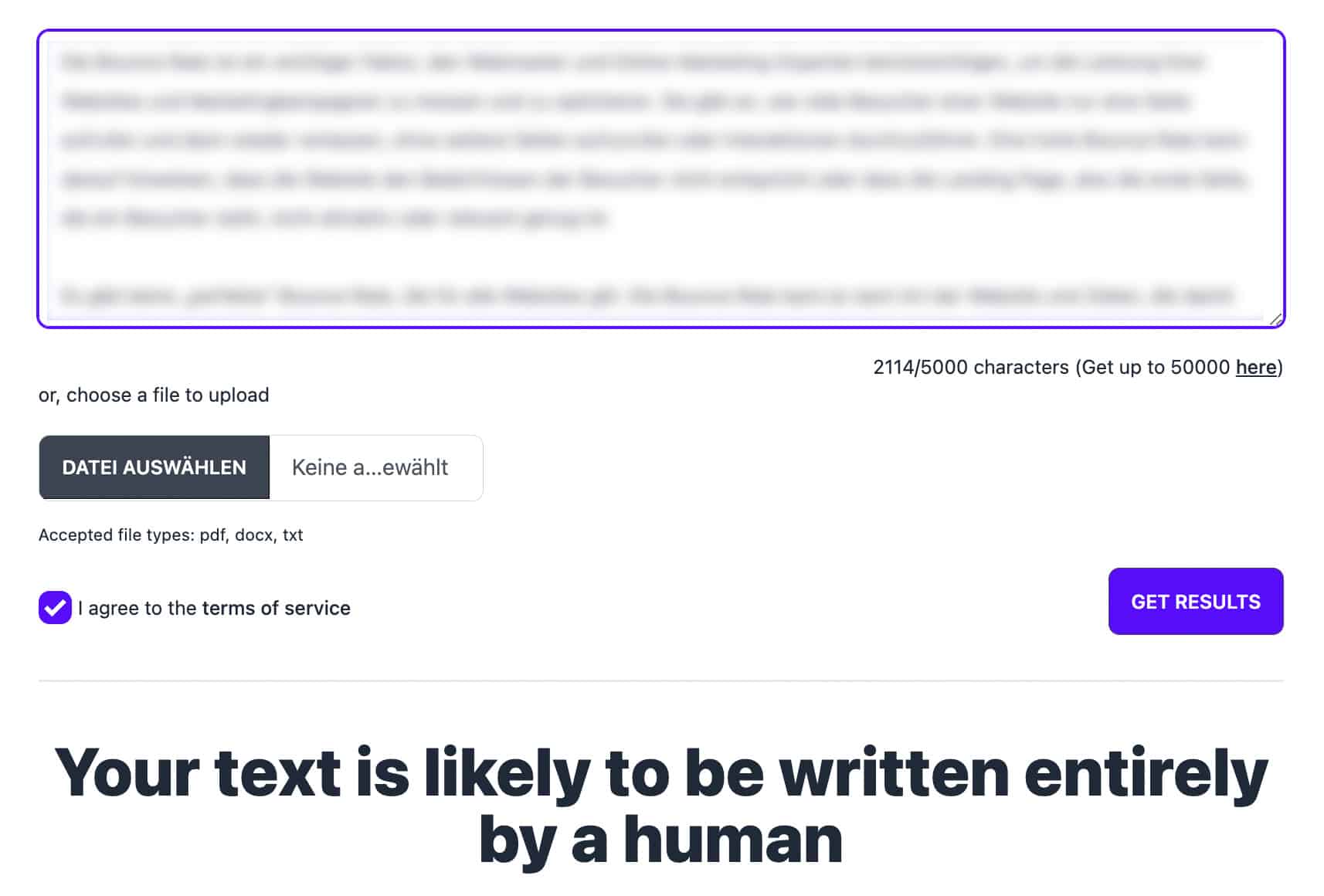
Hatte copyleaks also wirklich geschafft, was ich für nicht machbar gehalten habe?
Wenn das Tool KI-Texte so treffsicher klassifziert, wie sieht es dann mit menschengeschriebenen Texten aus?
Ein erster Test mit dem frisch installierten Browser-Plugin von copyleaks sah vielversprechend aus: Einen Text, den ich selbst im Jahr 2016 geschrieben habe, selbstverständlich ohne Unterstützung einer KI, wurde korrekt als „Menschlicher Text“ klassifiziert:

Doch mein Erstaunen legte sich schnell wieder, als ich die nächsten Absätze überprüfte, die ich persönlich, weit vor der Veröffentlichung jeglicher generativer KI geschrieben hatte:

Plötzlich wurde mitten in meinem Text ein großer Absatz als „KI-Content erkannt“ und ein paar Stichproben später betätigte sich mein Verdacht:
Copyleaks lieferte in meinem Kurztest derart viele „False Positives“ (Texte, die als KI-generiert eingestuft werden, es in Wirklichkeit aber garnicht sind), so dass ich niemandem empfehlen kann, sich darauf zu verlassen.
Kai Spriestersbach
Die Wahrscheinlichkeiten, die mir das Tool hierfür angezeigt haben, lagen bei den Fehleinschätzungen zwischen 99,9% und 85,5%, wie in diesem Beispiel:

In meinem – zugegeben relativ kurzen Test – konnte ich zwar keine False Negatives identifizieren, also KI-generierte Texte, die von copyleaks nicht als solche klassifiziert werden, doch bei einer derart hohen Fehlerrate, ist das für den Einsatz des Tools unerheblich.
Tom Tloks KI-Detektor „Made in Germany“
Auch in Deutschland ist man vor Fehlschlüssen und unterkomplexer Betrachtung nicht gefeit, wie Tom Tlok von der Fachhochschule Wedel derzeit beweist:
Der KI-Detektor, der durch einen modifizierten LLM-Ansatz im Rahmen von Tloks Master-Thesis entstanden ist, erkennt mit einer Zuverlässigkeit von 97,89 Prozent, ob ein deutschsprachiger Text mithilfe von Künstlicher Intelligenz erstellt wurde.
NDR Lokalbericht
Natürlich musste ich diesen direkt testen. Und ja: Bei ein paar Texten scheint es gut zu funktionieren, allerdings dauert es nicht lange, bis man sowohl False Positives, als auch False Negatives erhält:

Diesen Text aus einem meiner Website Boosting Artikel stuft das Tool mit 99,89% korrekt als menschlich geschrieben ein. Sehr vielversprechend…

Und diesen zu 100% mit ChatGPT generierten Text aus einem Experiment stuft das Tool mit 91,88%iger Sicherheit als „KI generiert“ ein. Sehr gut!
Doch bereits bei einem, mittels RAG erstellten Text, ist sich das Tool nicht mehr sicher…

Hier wird nur noch 19,83% KI angezeigt, obwohl der Output 1:1 aus ChatGPT stammt!
Und mit ein bisschen ausprobieren konnte ich sogar für einen, zu 100% mittels ChatGPT generierten Text eine 90,68%ig menschliche Bewertung erhalten:

Ich frage mich, wie hier evaluiert wurde, um auf solche Zahlen zu kommen.
Falls hier ein Teil der Trainingsdaten zur Evaluierung verwendet wurde, liegt wahrscheinlich ein klassischer Selection Bias vor. Bei dem lernt das Modell nicht generell „KI generierte Texte“ zu erkennen, sondern eben nur den bestimmten Typus, der für das Training verwendet wurde. Daraus lässt sich jedoch nicht Generalisieren, ohne dass dies zulasten der Erkennungsrate und -genauigkeit geht.
Gerade in einer Umgebung, in der es wichtig ist, zwischen menschlichen und KI-generierten Texten zu unterscheiden, zum Beispiel in der Wissenschaft oder im Journalismus, könnte eine falsche Identifikation schwerwiegende Konsequenzen haben.
Zwischen Nachrichten über übereifrige Professoren, die eine ganze Klasse durchfallen lassen, weil sie verdächtigt werden, KI-Schreibprogramme zu benutzen, und Kindern, die fälschlicherweise beschuldigt werden, ChatGPT zu benutzen, ist die generative KI im Bildungsbereich in Aufruhr. Manche sprechen von einer existenziellen Krise. Lehrerinnen und Lehrer, die sich auf die Lehrmethoden des letzten Jahrhunderts verlassen, suchen nach Wegen, den Status quo zu erhalten, also sich auf den Aufsatz als Instrument zu verlassen, um die Beherrschung eines Themas zu messen.
Obwohl es verlockend ist, sich auf KI-Tools zu verlassen, um KI-generierten Text zu erkennen, hat sich gezeigt, dass diese nicht zuverlässig sind. KI-Text-Detektoren wie GPTZero, ZeroGPT und der Text Classifier von OpenAI erkennen KI-generierte Texte, nicht zuverlässig, da sie häufig falsch positive Ergebnisse liefern.
Kai Spriestersbach
Ich bin mit dieser Einschätzung nicht alleine: Wenn man Amerikas wichtigstes Rechtsdokument – die US-Verfassung – in ein Tool eingibt, das von KI-Modellen wie ChatGPT geschriebene Texte angeblich erkennt, wird es einem sagen, dass das Dokument mit ziemlicher Sicherheit von einer KI geschrieben wurde. Aber wenn James Madison kein Zeitreisender war, kann das ja garnicht nicht stimmen. Fest steht: KI-Schrifterkennungswerkzeuge liefern falsch-positive Ergebnisse. arstechnica hat dazu mit verschiedenen Experten und dem Erfinder des KI-Schriftdetektors GPTZero gesprochen, um herauszufinden wieso das so ist.
Analyse und Fazit
Wenn generative KI-Modelle verwendet werden, um Texte zu generieren, ist es äußerst schwierig, diese mit Sicherheit zu erkennen. Große Sprachmodelle wurden genau dafür entwickelt, um menschliche Texte zu reproduzieren, also möglichst gut nachzuahmen. Die Lernmethode der KI sorgt zwar dafür, dass sie nur bestimmte Muster abbilden, die signifikant genug in den Trainingsdaten enthalten waren und dementsprechend eine geringere Varianz aufweisen. Dennoch ist es nicht trivial, diese von menschlichen Texten zu unterscheiden.
Denn, selbst wenn wir die Modelle deterministisch machen würden (indem wir eine Temperatur von 0 verwenden), würden sie immer noch eine sehr lange und einzigartige Kette von Token generieren, die zudem Abhängig von deren Input, also dem Prompt des Nutzers ist. Stellen wir uns dazu eine hypothetische Kette aller Möglichkeiten vor, die jeden möglichen Text enthält, den das Modell jemals generieren könnte.
Um zu überprüfen, ob ein bestimmter Text von der KI generiert wurde, müssten wir also die gesamte Tokenkette vorhersagen oder alle möglichen Kombinationen von Token speichern und den zu prüfenden Text damit vergleichen. Dies erfordert enorme Speicher- und Rechenkapazitäten, die praktisch nicht umsetzbar sind.
Darüber hinaus verhalten sich KI-Modelle probabilistisch, nicht deterministisch. Das bedeutet, dass sie die nächsten Token nur mit bestimmten Wahrscheinlichkeiten vorhersagen, aus denen das Modell dann zufällig auswählt. Bei einer Auswahl von zehn möglichen Worten ergeben sich mehr Kombinationsmöglichkeiten als die Anzahl der Atome im Universum!
Es ist auch wichtig zu beachten, dass jedes KI-Modell unterschiedliche Parameter und Gewichtungen besitzt, was zu unterschiedlichen Wahrscheinlichkeiten und Ergebnissen führt. Daher wäre eine Methode, die für ein Modell funktioniert, nicht unbedingt auf andere Modelle anwendbar.
Es bleibt also nur der Ansatz, ein Modell mit KI-Texten und menschlichen Texten zu trainieren, das versucht zu lernen die beiden zu unterscheiden. Hierbei stößt man jedoch auf das Problem, dass das Detektor-Modell mit repräsentativen Daten gefüttert werden müsste, um Muster zu identifizieren, die inhärent durch die Art und Weise wie LLMs Texte erzeugen entstehen und nicht in menschlichen Texten auftreten.
Zusammenfassend lässt sich sagen, dass aufgrund der Natur und Komplexität der generativen KI-Modelle eine sichere Erkennung von KI-generierten Texten quasi unmöglich ist.
Detektorsysteme wie diese verdienen unser Vertrauen nicht. Bei fälschlicherweise erkannten KI-Texten kommt die Frage nach der Genauigkeit und Zuverlässigkeit auf.
Kai Spriestersbach
Mein Tipp lautet daher: Probiert es am besten selbst aus und zeigt Euren Kunden und Vorgesetzten, dass diese Tools grundlegende Schwächen haben.
Solange KI-Detektoren nicht zuverlässig arbeiten und ihre Einschränkungen und potenziellen Fehler transparent machen, halte ich deren Einsatz für deutlich schädlicher als nützlich. Umso wichtiger ist es, dass Nutzer dieser Systeme verstehen, wie sie funktionieren und wie man ihre Ergebnisse interpretiert.
Abonniere das AFAIK-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz im Online Marketing!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen Rund um KI aus den Bereichen Online-Marketing, SEO, GEO, WordPress und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Monat eine E-Mail von mir. Versprochen.