Das gesamte Jahr 2023 über bestimmten Künstliche Intelligenz (KI) und insbesondere die aktuelle Generation der Large Language Models (LLMs) den öffentlichen Diskurs in vielen Bereichen. KI-Produkte erleben ohne jede Frage einen beispiellosen Aufschwung und lange Zeit sah es so aus, als habe Google das Nachsehen. Ich hatte mich hier im Blog selbst schon darüber gewundert, wieso man sich scheinbar von der Konkurrenz abhängen ließ und die ersten Antworten wie die SGE und Googles BARD mehr peinlich als beeindruckend waren.
Doch wir erleben zum Jahresende nochmal ein spannendes Kopf-an-Kopf-Rennen zwischen den Giganten Google und OpenAI um die Krone der KI. Denn gestern stellte Googles sein neuestes Modell, Gemini vor, welches eine bemerkenswerte Leistung erbrachte und OpenAIs Flaggschiff, GPT-4, als erstes LLM in mehreren Benchmarks übertraf.
Die Bedeutung der Benchmark-Ergebnisse
Zuallererst ist es wichtig, den Kontext von „ein paar Prozent“ Verbesserung in Benchmarks zu verstehen. In der Welt der KI entspricht dies häufig dem Unterschied zwischen durchschnittlichen menschlichen Fähigkeiten und Leistungen innerhalb der besten 0,2% der Menschheit.
Beispielhaft dafür steht AlphaCode 2:
Darüber hinaus zeichnet sich Gemini durch seine ausgeprägten multimodalen Fähigkeiten aus. Diese ermöglichen es dem Modell, komplexe Aufgaben wie die Interpretation von Videos – eine Abfolge von Bildern mit kontextuellem Zusammenhang – zu meistern, wie es Google in einem beeindruckenden Video demonstriert:
Die darin gezeigten Fähigkeiten sind denen aller Konkurrenten deutlich überlegen.
Was sind multimodale Fähigkeiten?
Multimodalität in KI-Modellen bezieht sich auf die Fähigkeit, Informationen aus verschiedenen Modalitäten (wie Text, Bildern und Videos) zu verarbeiten und zu integrieren. Diese Fähigkeit erweitert das Verständnis und die Anwendungsmöglichkeiten von KI erheblich.
Ebenso spannend finde ich die Demo im Bereich der wissenschaftlichen Literatur, denn hierbei hat es Google offenbar geschafft, Halluzinationen zu reduzieren und die Präzision für RAG-Anwendungen deutlich zu verbessern:
Kleinere Modelle, Große Wirkung
Besonders hervorzuheben sind die kleineren Modelle der Gemini-Familie, welche in puncto Effizienz und Leistung beeindrucken. Sie übertreffen OpenAIs Whisper-Modell bei der Spracherkennung und sind dabei so kompakt, dass sie lokal auf Smartphones wie dem Pixel 8 Pro laufen können – ein Durchbruch in Bezug auf Zugänglichkeit und Anwendungsvielfalt.
Daher ist Gemini 1.0 eher als Modellfamilie zu sehen, die in drei verschiedenen Größen daher kommen:
Gemini Ultra – das größte und leistungsstärkstes Modell für hochkomplexe Aufgaben.
Gemini Pro – das beste Modell zur Anwendung in einem breiten Aufgabenspektrum.
Gemini Nano – das effizientestes Modell für Aufgaben, die direkt auf dem Gerät verarbeitet werden.
Gemini Pro ist für englische Accounts in einigen Ländern bereits in Bard integriert und kann ausprobiert werden. Leider steht Bard mit Gemini noch nicht in Europa zur Verfügung. Gemini Ultra wird aktuell noch in Sachen Sicherheit getestet und dessen Verhalten aligned und soll später in einer Bezahlversion von Bard verwendet werden.
Für Gemini Ultra führen wir derzeit umfangreiche Vertrauens- und Sicherheitsprüfungen durch, einschließlich Red-Team-Einsätze durch vertrauenswürdige externe Parteien. Zugleich optimieren wir das Modell vor der breiten Einführung durch Feinabstimmung und Reinforcement Learning aus menschlichem Feedback.
Als Teil dieses Prozesses werden wir Gemini Ultra ausgewählten Kund:innen, Entwickler:innen, Partnern, Sicherheitsteams und Expert:innen für Corporate Responsibility vorab zur Verfügung stellen. Wir werden deren Feedback auswerten, bevor wir das Tool Anfang nächsten Jahres für Entwickler:innen und Unternehmenskunden allgemein verfügbar machen.
Anfang nächsten Jahres werden wir außerdem Bard Advanced auf den Markt bringen: ein neues, innovatives KI-Tool, das euch Zugriff auf unsere besten Modelle und Funktionen bietet, beginnend mit Gemini Ultra.
Sissie Hsiao
Vice President and General Manager, Google Assistant and Bard
https://blog.google/intl/de-de/unternehmen/technologie/gemini-bard/
Ich bin gespannt, ob und wann wir weitere Details über den Aufbau der Modelle, also deren Architektur und Parameteranzahl erfahren werden und wann und wie diese Modelle genutzt werden können.
Stoßen LLMs bereits an Grenzen?
Aufgrund der nur knappen Verbesserungen von Gemini Ultra im Vergleich mit GPT-4 gibt jedoch auch berechtigte Spekulationen darüber, ob LLMs möglicherweise an systemische, also architektonische Grenzen stoßen.
Vielleicht lohnt es sich garnicht, die Menge der Trainingsdaten, die Komplexität der künstlichen neuronalen Netze, also die Anzahl deren Parameter, sowie die eingesetzte Rechenleistung immer weiter zu steigern, weil damit kaum noch Verbesserungen zu erzielen sind.
Obwohl dies eine realistische Möglichkeit darstellt, eröffnen sich gleichzeitig Chancen für innovative Ansätze.
Neue Algorithmen und Architekturen könnten die Tür zu signifikanten Verbesserungen öffnen. Gerüchte um interne Durchbrüche bei OpenAI im Zusammenhang mit Projekten wie Q* und dem Hick-Hack um OpenAIs CEO Sam Altman lassen die Frage aufkommen, ob solche Innovationen bereits in der Entwicklung sind.
Das Potenzial für architektonische Verbesserungen deutet darauf hin, dass aktuelle Entwicklungen vielleicht nur der Anfang sind. Da Google Gemini explizit als Gemini 1.0 bezeichnet, dürfen wir mit Sicherheit schon bald einen Nachfolger erwarten, der womöglich Anfang 2024 mit GPT-5 konkurrieren wird.
Unsere erste Version, Gemini 1.0, ist für verschiedene Größen optimiert: Ultra, Pro und Nano. Dies sind die ersten Modelle der Gemini-Ära und die erste Verwirklichung der Vision, die wir hatten, als wir Anfang dieses Jahres Google DeepMind gründeten.
Sundar Pichai, CEO von Google
Vielleicht sehen wir aber auch im nächsten Jahr vollkommen neue Ansätze, die über die etablierte Transformer-Architektur hinausgehen. Wobei es wirklich beeindruckend ist, wie weit Google mit dieser Architektur in Sachen „Erklären des Denkens in Mathe und Physik“ gekommen ist.
Das Ding ist ein unglaublich guter Nachhilfelehrer!
Wirtschaftliche Überlegungen
Aus wirtschaftlicher Sicht ist die Entwicklung immer größerer Modelle ein enormes finanzielles Risiko, da die zukünftigen Geschäftsfelder noch unklar sind. Die steigende Menge der Trainingsdaten, die Komplexität der künstlichen neuronalen Netze und damit die Anzahl deren Parameter erfordern immer mehr Rechenleistung. Für ein wesentlich größeres Modell existieren derzeit noch nicht einmal die notwendige Hardware, um diese effizient betreiben zu können.
OpenAIs ChatGPT, ursprünglich als Forschungsvorschau gedacht, zeigte das Potenzial von Instruct-GPT auf. Die Herausforderung besteht nun darin, neue Geschäftsmodelle zu entwickeln, insbesondere angesichts des aufkommenden Wettbewerbs durch selbstgehostete Open-Source-Lösungen.
OpenAI hat (auch dank Meta AI) im Vergleich zu selbstgehosteten OpenSource-Lösungen kaum noch einen Wettbewerbsvorteil, der nachhaltige Business Modelle erlaubt.
Der Wettbewerb um Skalierung und Innovation
Google könnte mit Gemini über Google Cloud schneller skalieren und ausrollen als OpenAI/Microsoft mit Azure. Googles proprietäre TPUs könnten dabei einen entscheidenden Vorteil bieten. Dieser Wettbewerb spiegelt sich auch in Microsofts jüngster Ankündigung wider, eigene Chips zu entwickeln.
Abschlussgedanken: Das eigentliche „Endspiel“ der KI
Der aktuelle Stand im Rennen der LLMs ist lediglich die Vorrunde. Das wahre „Endspiel“ der KI wird in Bereichen wie Transfer-Learning, One-Shot-Learning und logischen Argumentationen in selbstlernenden Systemen rund um AGI ausgetragen. Diese könnten zum Beispiel durch Interaktion mit sich selbst oder einer simulierten Welt trainiert werden, anstatt mit existierenden Texten, Bildern und Videos, ähnlich wie DeepMind’s AlphaGo seine übermenschlichen Fähigkeiten erreichte.
Google hat bereits die größte Rechenleistung der Welt, aber mit den Upgrades für das TPU v5e-Rechenzentrum wird Google einen gigantischen Vorsprung in Sachen KI-Training und -Inferenz erreichen.
In einer aktuellen Analyse auf semianalysis zeigen die beiden Autoren sehr schön auf, dass der Zugang zu KI-fähiger Hardware und die damit verbundene Rechenkapazität in den kommenden Monaten einen entscheidenden Wettbewerbsvorteil für Google darstellen kann.
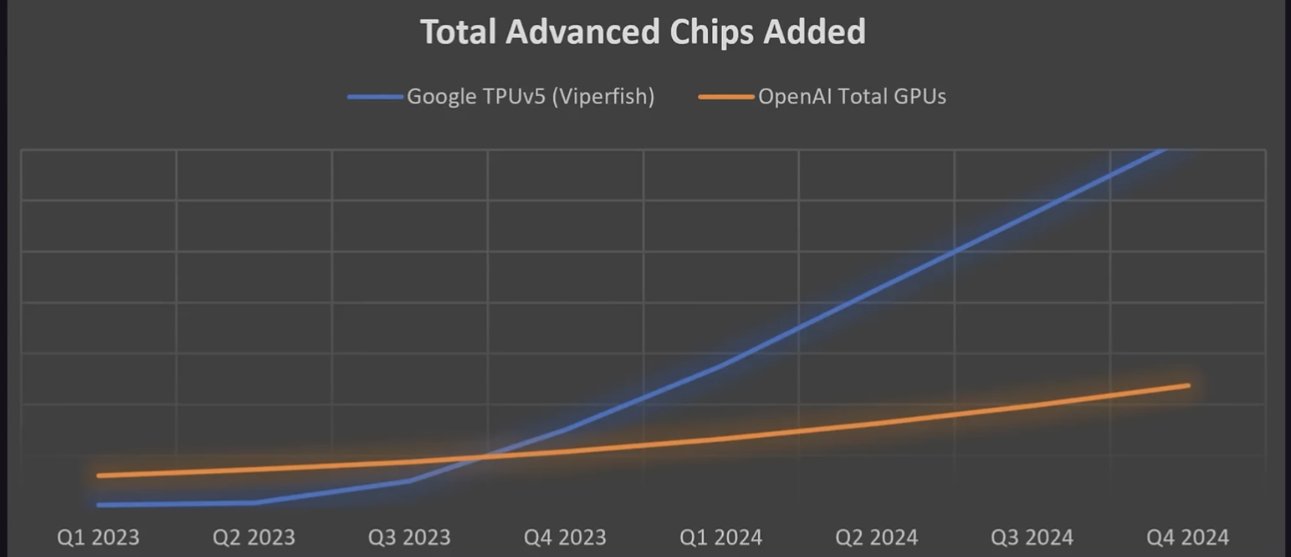
Google trainiert darauf bereits Gemini 2 und es ist sehr wahrscheinlich, dass sie in der Lage sein werden, das größte und leistungsfähigste Sprachmodell zu erstellen.
Das Rennen um die KI-Vorherschaft ist aus meiner Sicht vollkommen offen.
Kai Spriestersbach
Aber wirklich spannend wird zu sehen, wem der nächste große Durchbruch gelingt.
Die Frage ist nicht nur, wer diesen Durchbruch erzielt, sondern auch, wie lange dieses Wissen monopolisiert werden kann, bevor die Konkurrenz aufholt. Wir stehen somit am Anfang einer spannenden, sich ständig weiterentwickelnden Reise in der Welt der KI.
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.




