
Die Grundlage jeder SEO-Maßnahme stellt die Auswahl der Suchbegriffe dar, die zur jeweiligen Webseite und dem Angebot des Betreibers passen. Jedoch ist es für die Priorisierung von Themen und die Optimierung der Inhalte von zentraler Bedeutung, die Bedürfnisse der Suchenden zu kennen und diese bei der Gestaltung der Webseite und deren Inhalte zu berücksichtigen. Wer also weiß was die Suchenden als relevantes Ergebnis von der Suchmaschine erwartet, kann sein Ranking zielgenau verbessern.
Für Web-Suchmaschinen ist das Verständnis der latenten Intentionen der Nutzer hinter den Suchanfragen ebenso von entscheidender Bedeutung, denn diese verwenden je nach Bedürfnis die unterschiedlichsten Daten und Algorithmen für die Ergebnisgenerierung und -sortierung, um eine möglichst hohe Nutzerzufriedenheit und damit Kundenbindung zu erreichen.
Die dabei verwendeten Taxonomien für Suchanfragen der Suchmaschinenentwickler stellt sich bei genauer Betrachtung als hochentwickelt und sehr differenziert heraus und geht weit über die bekannten Klassen heraus. Ein Blick in meine Bachelorarbeit, die im Grin Verlag erschienen ist zeigt, dass es für SEOs hier wesentlich mehr zu entdecken gibt und sich eine Auseinandersetzung mit den Forschungsarbeiten im Bereich Information Retrieval sehr lohnen kann!
Die Taxonomie Broders
Um die unterschiedlichen Anforderungen an eine Suchmaschine verstehen zu können, entwickelte der spätere IBM Research-Mitarbeiter Andrei Broder bei AltaVista eine Taxonomie für Suchbegriffe in Web-Suchen, die das Bedürfnis hinter einer Suchanfrage in drei Klassen teilt, die bis heute ihre Gültigkeit behalten haben.
Jede Suchanfrage, die ein Nutzer an die Suchmaschine richtet, impliziert demnach eine konkrete Frage und gibt mehr oder weniger Aufschluss über die Motivation und Erwartungen an die Suchergebnisse. Je nach Intention der Suchenden, lassen sich Suchanfragen unterscheiden und in folgende drei Anfragetypen unterteilen:
- Navigationsorientierte Suchanfragen (eng.: Navigational search queries)
- Informationsorientierte Suchanfragen (eng.: Informational search queries)
- Transaktionsorientierte Suchanfragen (eng.: Transactional search queries)
Broder führt diese wie folgt aus:[1]
“In the web context[sic!] the ‘need behind the query’ is often not informational in nature. We classify web queries according to their intent into 3 classes:
– Navigational. The immediate intent is to reach a particular site.
– Informational. The intent is to acquire some information assumed to be present on one or more web pages.
– Transactional. The intent is to perform some web-mediated activity.“
Broder, 2002
Festzuhalten sei an dieser Stelle, dass nicht immer ein relevantes Dokument zur Befriedigung des Informationsbedürfnisses notwendig ist, denn auch ein Wegweiser zur gesuchten Information kann bereits ein gutes Suchergebnis ausmachen, wie Broder ebenfalls feststellte:
„It is interesting to note, that in almost 15% of all searches the desired target is a good collection of links on the subject, rather than a good document. (A good hub, rather than a good authority, in the language of Kleinberg)”
Die von Broder aufgeführten Beispiele sollen als alternative Erklärung der Klassen dienen und werden hier zum besseren Verständnis aufgeführt. Er beginnt zunächst mit der Erläuterung der navigationsorientierten Suchanfragen:
“Navigational queries. The purpose of such queries is to reach a particular site that the user has in mind, either because they visited it in the past or because they assume that such a site exists. Some examples are
- Greyhound Bus. Probable target http://www.greyhound.com
- Probable target http://www.compaq.com.
- national car rental. Probable target http://www.nationalcar.com
- american airlines home. Probable target http://www.aa.com
- Don Knuth. Probable target http://www-cs-faculty.stanford.edu/~knuth/
This type of search is sometimes referred as ‘known item’ search in classical IR, but is mostly used in the evaluation of various systems. (…) These types of queries are essentially navigational queries.”
Die aus Sicht des Autors wichtigste Aussage über die sogenannten navigational queries trifft Broder mit dem Satz: “With respect to evaluation, navigational queries have usually only one ‚right‘ result.” (Ebenda) Dies legt, aus Sicht des Verfassers den Schluss nahe, dass eindeutig als navigationsorientiert identifizierte Suchanfragen kein sinnvolles Optimierungspotential aus Sicht der Suchmaschinenoptimierung darstellt.
Anschließend verdeutlicht Broder die Absicht hinter den informationsorientierten Suchen wie folgt:
“Informational queries. The purpose of such queries is to find information assumed to be available on the web in a static form. No further interaction is predicted, except reading. By static form we mean that the target document is not created in response to the user query.” (Ebenda)
Außerdem verdeutlicht er die Bandbreite des potentiellen Informationsbedarfs:
“What is different on the web is that many informational queries are extremely wide, for instance cars or San Francisco, while some are narrow, for instance normocytic anemia, Scoville heat units.” (Ebenda)
Die Klasse der aus Sicht der Suchmaschinenoptimierung interessantesten Suchanfragen, nämlich Suchanfragen mit klarer Kaufabsicht beschreibt Broder wie folgt:
“Transactional queries. The purpose of such queries is to reach a site where further interaction will happen. This interaction constitutes the transaction defining these queries.” (Ebenda)
Neben den Kaufabsichten, schließt Broder jedoch auch die Suche nach Downloads, Webdiensten, Datenbankabfragen oder Servern für Onlinespiele explizit mit ein. Für die Betrachtung der Klasse aus Sicht der Suchmaschine macht Broder eine interessante Anmerkung hinsichtlich der Evaluierbarkeit derartiger Ergebnisse:
“The results of such queries are very hard to evaluate in terms of classic IR. Binary judgment might be all we have, say appropriate, non-appropriate. However most external factors important for users (e.g. price of goods, speed of service, quality of pictures, etc[sic!]) are usually unavailable to generic search engines.” (Ebenda)
Diese Aussage zeigt, dass Broder das Ziel der transaktionsorientierten Suchanfrage in der Interaktion mit einer Entität außerhalb des Suchmaschinenindizes begreift.
Diese drei Klassen bilden also das Spektrum von der Eingabe einer komplexen Fragestellung über die Anfrage ein bestimmtes Produkt online zu kaufen, bis hin zu gezielten Suchen nach einer bestimmten Webseite ab, wofür sich jeweils unterschiedliche Ranking-Algorithmen besser bzw. schlechter zu eignen scheinen.[2] In dieser Arbeit beschreibt Broder, dass bis 2002 drei Entwicklungsstufen von Web-Suchmaschinen identifiziert werden konnten. Jede dieser Suchmaschinen-Generationen war, nach seinen Aussagen, in der Lage eine weitere Klasse seiner Taxonomie sinnvoll zu beantworten:
- Die erste Generation verwendete lediglich die on-Page-Daten, also den Text und dessen Auszeichnungen und ähnelt klassischen Information-Retrieval-Systemen sehr stark. Firmen wie AltaVista, Excite, WebCrawler und andere setzen diese Form der Websuche als State-Of-The-Art-Technologie etwa von 1995 bis 1997 ein. Dieser Ansatz funktionierte laut Broder lediglich für die Klasse sogenannter informational queries.
- Die zweite Generation zog off-Page-Daten heran, beispielsweise Link-Analysen, Link-Texte und Click-Through-Daten. So verwendete Google zum Beispiel Link-Analysen als erste Suchmaschine überhaupt als primären Rankingfaktor. DirectHit setzte seinerzeit [Anmerkung des Verfassers: 1998-1999] stärker auf Click-Through-Daten und ging später in Ask Jeeves auf. [3] Neben den informational queries sollte diese zweite Generation auch für die sogenannten navigational queries Mittlerweile verwenden laut Broder alle großen Suchmaschinen diese Daten für ihr Ranking. Insbesondere die Link-Analyse und die Link-Texte scheinen laut Broder unabdingbar für die Klasse der navigational queries zu sein.[4]
- Als dritte Generation, die sich laut Broder gerade erst entwickeln [Hinweis des Autors: Dies war bereits 2002], scheinen Daten aus unterschiedlichsten Quellen zu vermischen, um damit das Bedürfnis hinter der Suchanfrage zu beantworten. Als Beispiel führt er die Suchanfrage „San Francisco“ an, für diese die Suchmaschine möglichweise Links zu einer Hotelreservierung in San Francisco, einem Kartendienst, dem Wetter und weiteren Funktionen anzeigen könnte. Derartige Suchergebnisse lassen sich laut Broder durch eine Loslösung von einem festen Korpus mittels semantischer Analyse, Kontext-Erkennung, dynamischer Auswahl der Datenbasis, etc. erreichen. Weiter postuliert Broder, dass diese dritte Generation sich insbesondere mit dem effizienten Umgang mit transaktionsorientierten Suchanfragen auseinandersetzen. Einerseits da die Nutzerbedürfnisse dies schlichtweg verlangen und andererseits, da sich transactional queries sich besonders gut monetarisieren lassen.[5]
Weiterentwicklung Broders Taxonomie
Der Taxonomie Broders haben sich diverse Wissenschaftler und Entwickler auf Seite der Suchmaschinen angeschlossen.[6] Kofler et al. (Kofler, C., Larson, M. & Hanjalic, A., 2016. „User intent in multimedia search: A survey of the state of the art and future challenges“. „ACM Comput. Surv. “, S. 36.) machten in ihren Studien vergleichbare Beobachtungen und konnten Broders Taxonomie bestätigen.[7] Sie beschrieben ebenfalls den sogenannten Intent, als das zugrundeliegende Ziel einer Websuche. Auch Lorigo et al. stellten 2006 (Lorigo, L. et al., 2006. „The influence of task and gender on search and evaluation behavior using Google“. „Information Processing and Management“, S. 1123-1131.) fest, dass Broders Taxonomie breite Anerkennung findet und auch von Kang & Kim (Kang, I.-H. & Kim, G.C., 2004. „Integration of multiple evidences based on a query type for web search“. „Information Processing and Management“, S. 459–478.) bestätig werden konnte:
„Navigational tasks are tasks where the users[sic!] intent is to find a particular web page, such as a homepage; informational tasks arise when the intent is to find information about a topic that may reside on one or more web pages; and transactional search tasks reflect the desire of the user to perform an action, such as an online purchase.” [8]
Im Laufe der letzten zehn Jahre konnte diese Dreiteilung ergänzt, erweitert und stärker ausdifferenziert werden. Lewandowski et al. (Lewandowski, , Drechsler, & von Mach, S., 2012. „Deriving query intents from web search engine queries“. „Journal of the American Society for Information Science and Technology “, S. 1773-1788.) fügen den drei Klassen von Broder zwei weitere hinzu. Diese ergeben sich aus der Ausdifferenzierung der Suchmaschinen im Hinblick auf die Integration von Werbeanzeigen und lokalen Ergebnissen und wurden als kommerziell, sowie lokalisiert beschrieben:
„Commercial, where the query has “commercial potential” (i.e., the user might be interested in commercial offerings). This also can be an indicator whether to show advertisements on the search engine results page (SERP).” (Ebenda) “Local, where the user is searching for information near his or her current geographic position.” (Ebenda).
Rose & Levinson verfeinerten Broders Ansatz und stellten 2004 in Ihrer ein eigenes Framework für Ziele der Suchenden vor (Abbildung 1). Dabei schufen sie innerhalb der Klasse Informational weitere Unterklassen, um den Informationsbedarf des Nutzers noch genauer spezifizieren zu können. So beschreibt 2.1.1 der Hierarchie beispielsweise eine geschlossene Frage, die laut Rose & Levinson nur eine einzige und eindeutige Antwort hat.[7] Die Klasse der transaktionsorientierten Suchanfragen von Broder wird in diesem Framework durch die unkommerzielle Klasse der Resource abgebildet und erhält zusätzliche Subklassen für Interaktion, Download, Unterhaltung und Beschaffung.
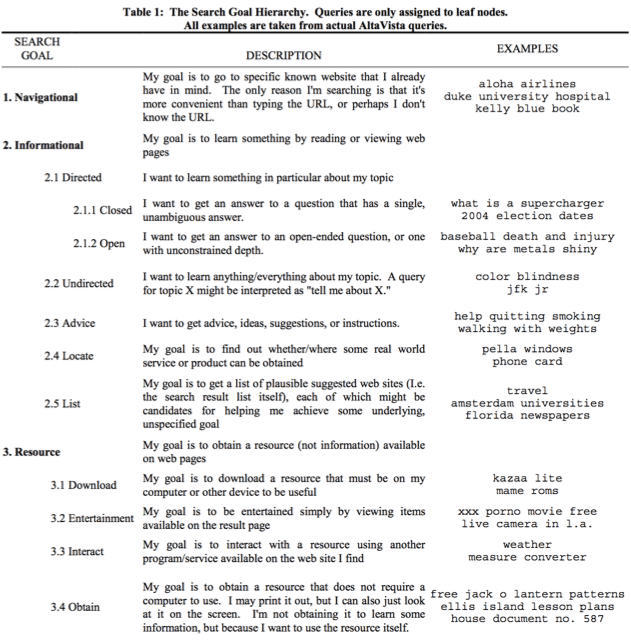
Die drei Ebenen der Klassifikation
Die aus Sicht des Verfassers zentrale Arbeit im Bereich der Keyword-Klassifikation, stellt die Studie von Jansen et al. (Jansen, B.J., Booth, D.L. & Spink, A., 2008. „Determining the informational, navigational, and transactional intent of Web queries“. „Information Processing and Management: an International Journal“, S. 1251-1266.) dar. Die Forscher stellen darin ein detailliertes Klassifikationssystem für den User Intent von Websuchen vor, welches sie auf eigenen Analysen und vorhergegangen Arbeiten aufbauen. Diese Arbeit eine Synthese sämtlicher bisherigen Arbeiten zu diesem Thema dar und liefert in der folgenden Tabelle einen Überblick über die Hierarchien des eigenen Frameworks mit drei weiteren Betrachtungsebenen, sowie die Analogien und Abweichungen der vorherigen Arbeiten hierzu.
Im Gegensatz zu vorherigen Arbeiten, die meist nur Beispiele nennen, ohne Details über die Klassifikationsmethoden zu nennen, werden bei Jansen et al. die Kategorien auch operationalisiert. Die Software, welche von den Forschern entwickelt wurde, klassifiziert automatisch Keywords mittels Suchanfragen aus dem Logs von Web-Suchmaschinen.
Diese Ergebnisse wurden mittels 400 manuell klassifizierten Begriffen validiert und zeigten eine Genauigkeit von 74%. [9] Bei den verbleibenden Suchanfragen ist die Suchintention laut Aussagen der Forscher entweder relativ vage, oder hat unterschiedliche Facetten [10] Eine weitere Besonderheit dieser Studie sind, laut der Autoren, der Umfang und die Vielfältigkeit der verwendeten Daten. Diese nutzten über anderthalb Millionen Suchanfragen, frühere Arbeiten jeweils nur wenige Hundert bis einige Tausend.[11] In deren Definition der informationsorientierten Suchanfragen, taucht außerdem erstmals der Begriff Multimedia auf. Neben reinen Texten und Dokumenten sollten auch Daten oder Audio- bzw. Videomaterial zur Befriedigung des Informationsbedürfnisses eine Rolle spielen:
“Informational searching: The intent of informational searching is to locate content concerning a particular topic in order to address an information need of the searcher. The content can be in a variety of forms, including data, text, documents, and multimedia. The need can be along a spectrum from very precise to very vague.“ [12]
In der Definition der navigationsorientierten Suchanfragen findet sich ebenfalls eine nennenswerte Neuerung, nämlich die Erweiterung auf eine Suchanfrage, bei der der Suchende davon ausgeht, dass eine bestimmte Webseite existiert:
“Navigational searching: The intent of navigational searching is to locate a particular Website. The Website can be that of a person or organization. It can be a particular Web page, site or a hub site. The searcher may have a particular Website in mind, or the searcher may just ‘think’ a particular Website exists.“ [13]
Bei der transaktionsorientierten Suche schließen sich die Forscher wieder den vorherigen Arbeiten an:
„Transactional searching: The intent of transactional searching is to locate a Website with the goal to obtain some other product, which may require executing some Web service on that Website. Examples include purchase of a product, execution of an online application, or downloading multimedia.“ [14]
In der Taxonomie wird die Informationssuche in fünf Unterkomponenten unterteilt (directed, undirected, find, list, sowie advice). und die Navigationssuche in zwei Unterkategorien (Navigation zu einer Transaktionsseite oder Navigation zu einer Informationsseite). Laut Jansen et al. kann es aus Nutzersicht auch Folgeziele geben, sobald der Nutzer an seinem vermeintlichen Ziel angekommen ist. So kann die Navigationssuche als Ausdruck einer Zwischenabsicht betrachtet werden, die auf die Befriedigung eines größeren Suchziels abzielt.[15] Die transaktionsorientierte Suche wird in der Arbeit mit vier Unterkategorien (Erhalten, Herunterladen, Interagieren sowie Suchmaschinen-Ergebnisse) ebenfalls differenziert dargestellt. Besonders interessant in diesem Zusammenhang ist die letzte Unterkategorie „Suchmaschinen-Ergebnisse“, da sie die Möglichkeiten direkter Antworten durch die Web-Suchmaschinen bereits inkludiert. Diese Klasse umfasst diejenigen Suchanfragen, bei denen die Ergebnisseite der Web-Suchmaschine das Endziel ist. Bei dieser Art der Suche erscheint die „Antwort“ direkt auf der Ergebnisseite der Suchmaschine, z. B. Vorschläge für die korrekte Schreibweise oder als Begriffe bereits im Titel, der URL oder dem Snippet des Ergebnisses.
Dem besseren Verständnis der von Jansen et al. verwendeten Klassifikationen dient folgende Tabelle. Diese enthält alle drei Spezifikationsebenen (Levels) und liefert für jede Klasse ein Beispiel (Abbildung 2). Alle Suchanfragen-Beispiele in der Tabelle aus Abbildung 2 stammen aus dem Dogpile Transaktionsprotokoll, dass in der Arbeit zur automatischen Klassifizierung von Jansen et al. verwendet wurde.

Quellen
- [1 – 5] Broder, A., 2002. „A taxonomy of web search“. „SIGIR Forum“, S. 3-10.
- [3] CNET, o. V., 2002. „Ask Jeeves to acquire Direct Hit for $506 million“. https://www.cnet.com/news/ask-jeeves-to-acquire-direct-hit-for-506-million/ (Abgerufen am 13.09.2017).
- [6 + 8] Kang, I.-H. & Kim, G.C., 2004. „Integration of multiple evidences based on a query type for web search“. „Information Processing and Management“, S. 459–478; Choudhari, K. & Bhalla, V.K., 2015. „Video Search Engine Optimization Using Keyword and Feature Analysis“. „Procedia Computer Science“, S. 691-697.
- [7] Rose, D.E. & Levinson, D., 2004. „Understanding user goals in web search“ in „Proceedings of the 13th international conference on World Wide Web“. New York, NY, USA, 2004. ACM, S. 13-19.; Jones, R. & Klinkner, K.L., 2008. „Beyond the session timeout: Automatic hierarchical segmentation of search topics in query logs“ in „In Proceedings of the 17th ACM Conference on Information and Knowledge Management“. New York, NY, USA, 2008. ACM, S. 699-708 sowie Strohmaier, M. & Kröll, M., 2012. „Acquiring knowledge about human goals from search query logs“. „Information Processing & Management“, January. S. 63–82.
- [9-16] Jansen, B.J., Booth, D.L. & Spink, A., 2008. „Determining the informational, navigational, and transactional intent of Web queries“. „Information Processing and Management: an International Journal“, S. 1251-1266.
Abonniere das AFAIK-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz im Online Marketing!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen Rund um KI aus den Bereichen Online-Marketing, SEO, GEO, WordPress und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Monat eine E-Mail von mir. Versprochen.