

Dies ist eine kleine Artikelserie zu ChatGPT, dem aktuell wahrscheinlich spannendsten Thema für viele im Bereich des Online Marketings. In diesem Teil, erkläre ich, was ChatGPT ist, was es nicht ist, was es kann und was es nicht kann. Im zweiten Teil erkläre ich dann wieso Google noch nicht ein solches Interface anbietet und ob bing und You mit Chatbot-Funktionen Google wirklich gefährlich werden kann und im dritten Teil stelle ich zwei Text-Chatbots vor, die bereits heute mehr können, als ChatGPT.
In meinem Artikel zu GPT-3 habe ich bereits erklärt: GPT ist ein Sprachmodell und wurde konzipiert, um natürliche Sprache und dessen Struktur abbilden zu können.
Diese Sprachmodelle lassen sich unterschiedlichen Methoden und Layern „fine-tunen“, in dem man sie dazu „erzieht“ bestimmte Dinge eher zu tun und andere Dinge zu lassen. ChatGPT ist genau ein solches, „finegetuntes“ GPT-3.5.
Wieso benutzt man nicht einfach GPT-3?
Die klassischen GPT-3-Modelle, die man bereits seit einiger Zeit via API bei OpenAI nutzen kann, sind nicht darauf trainiert, Benutzeranweisungen in natürlicher Sprache zu befolgen.

Das derzeit mächtigste Modell von GPT-3 „text-davinci-003“ (auch GPT-3.5 genannt) ist in der Lage bis zu 4.000 Token auf einmal zu verarbeiten, die sich jedoch auf Input und Output gemeinsam beziehen! Das bedeutet: Je länger also die an das Modell gestellte Anfrage ist, desto kürzer wird der mögliche Output, weil das Fenster nicht erweitert werden kann.
Prompt-Engineering als Hürde
Um mit GPT-3 sinnvolle Ergebnisse zu erhalten, muss man also etwas Verständnis und Einarbeitungszeit mit bringen, um das sogenannte Prompt-Engineering zu beherrschen, also die Formulierung von Anfragen an das Sprachmodell. Das erklärt übrigens auch, wieso spezialisierte KI-Text-Tools wie jasper, frase und Co. für viele Nutzer einfacher zu benutzen sind und man damit schneller zu besseren Ergebnissen kommt. Diese nehmen einem quasi das Prompt-Engineering ab und liefern bewährte Templates und optimierte User Interfaces.
Einfache Benutzer scheitern daran
Irgendwann wurde die OpenAI-API dann für alle geöffnet und unbedarfte Nutzer konnten über den Playground plötzlich ohne Vorkenntnisse oder Programmierkenntnisse mit GPT-3 spielen. Dort sind offenbar derart viele Nutzer daran gescheitert, sinnvolle Ergebnisse zu erhalten, weil ihre Prompts einfach schlecht waren, dass man sich bei OpenAI folgendes überlegt hat:
- Man fine-tuned ein vortrainiertes GPT-3-Modell mittels sogenanntem „Reinforcement Learning from Human Feedback (RLHF)“, was nichts anderes bedeutet als, das zunächst menschliche KI-Trainer komplette Gespräche vorgaben, in denen sie beide Seiten spielten, also den Nutzer und einen KI-Assistenten. Diese Daten wurden sozusagen als Grundmodell mittels SFT auf GPT geprägt, damit GPT grundsätzlich Dialoge führen kann.
- Anschließend wurden neue Anfragen an das geprägte Modell gestellt und menschliche Labeler haben die Antworten nach dessen Qualität sortiert. Diese Daten wurden genutzt, um eine Art Belohnungssystem (RM) zu trainieren, das bei besseren Antworten größere Belohnung ausschüttet, als bei schlechten Antworten, damit GPT quasi lernen kann immer bessere Antworten zu liefern.
- Nun konnte die ursprünglich durch Menschen geprägte Policy im ersten PPO-Modell mittels des Feedbacks des trainierten Reward Modells immer weiter verbessert und verfeinert werden.

Dadurch erzeugt ChatGPT viel hilfreichere Ergebnisse als Reaktion auf Benutzeranweisungen als reguläre GPT-3-Modelle. Okay, soweit so gut.
Was kann ChatGPT nicht?
Im Kern ist ChatGPT also eine Art spezialisierte Version von GPT-3.
Wie auch GPT schreibt ChatGPT daher manchmal plausibel klingende, aber falsche oder unsinnige Antworten.
Denn, GPT erzeugt Text einzig und alleine auf der Wahrscheinlichkeit der Reihenfolge von Wörtern.
Dieses Problem zu beheben, ist eine Herausforderung, wie OpenAI selbst schreibt, denn:
Während des fine-tuning des Modells gibt es derzeit keine Quelle der Wahrheit. Daher wurde das Modell darauf trainiert wird, etwas vorsichtiger zu sein, was dazu führt dass es Fragen ablehnt, die es „glaubt“ nicht richtig beantworten zu können, wie man in diesem Beispiel sehen kann:
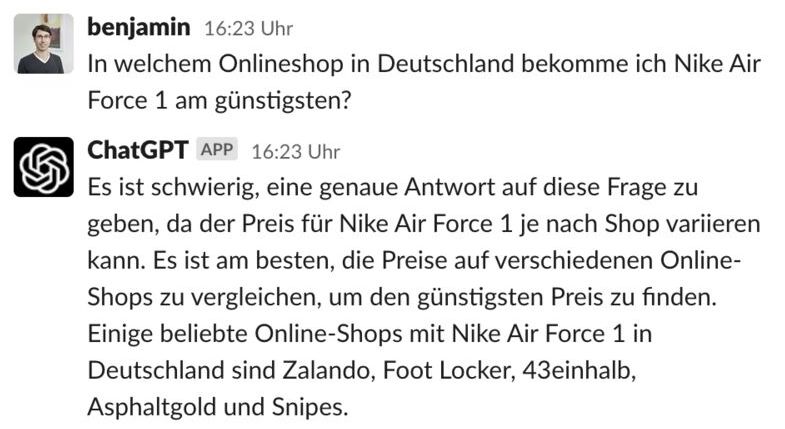
Einschub: Wie kommt mein Unternehmen in ChatGPT?
Die Liste der Shops sind übrigens die am häufigsten in ähnlichem Kontext genannten Onlineshops innerhalb der Trainingsdaten. Falls Du Dich also fragst, wie Dein Unternehmen „in ChatGPT“ kommt:
Sorge dafür, dass Du die bekannteste Marke in Deiner Nische bist, dann ist die Chance hoch, dass das Modell Dich nennt und nicht den weniger häufig genannten Mitbewerber.
Leider führt das überwachte Training das Modell in diesem Konstrukt auch zum Teil in die Irre, weil die ideale Antwort immer davon abhängt, was das Modell weiß, und das Modell nicht wissen kann, was der menschliche Labeler weiß, der die Antworten bewertet.
Achtung: Ohne aktivierte Option „Browse with bing“ ist ChatGPT nicht in der Lage, Information von extern URLs abzurufen oder diese zu validieren!
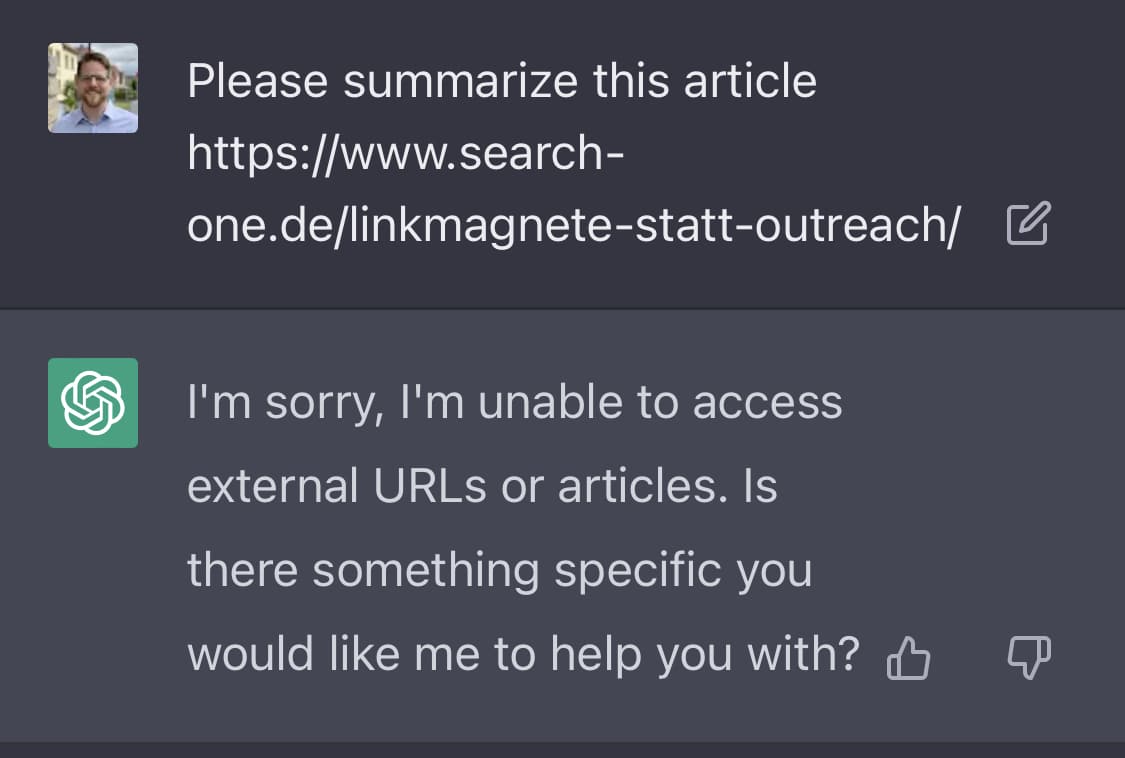
Wenn man also beispielsweise fragt:
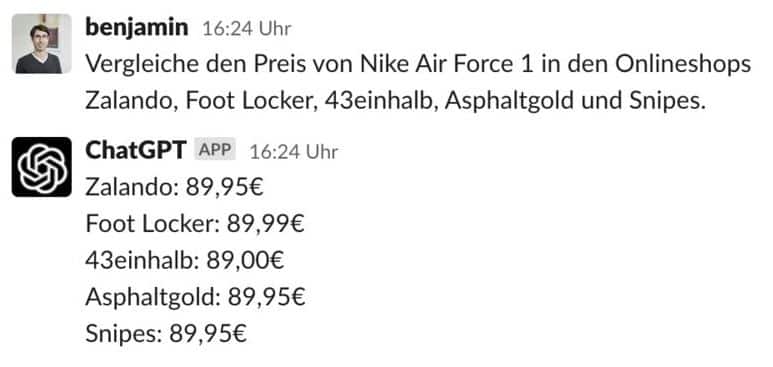
Dann bedeutet dass, die ausgegebenen Preise stammen im besten Falle aus den Trainingsdaten, die aus dem November 2021 sind, im schlimmsten Fall aber, dass diese kompletter Blödsinn sind. Das ist der schlicht der WAHRSCHEINLICHSTE Preis.
In diesem Fall ist es sogar sehr viel wahrscheinlicher, dass die Preise nicht korrekt sind und es auch nie waren. Denn, durch das Training mit der gigantischen Textmenge hinterlassen nur häufig vorkommende Muster ihre Spuren. Ein einzelnes Datum (Singular von Daten) wie ein Preis, kann sich also rein theoretisch garnicht korrekt abbilden, wenn nicht auf hunderten Seiten immer wieder dieser zu finden ist.
Wenn Statistik lügt
Ich habe ein perfektes Beispiel für den Umgang mit Fakten und der Bedeutung der Promts für #ChatGPT gefunden:
Auf die Frage „Wer ist CEO von Twitter“ liefert die KI die (richtige) Antwort Elon Musk, die es eigentlich nicht kennen kann, denn zum Zeitpunkt des Trainings im November 2021 war noch Jack Dorsay der CEO:
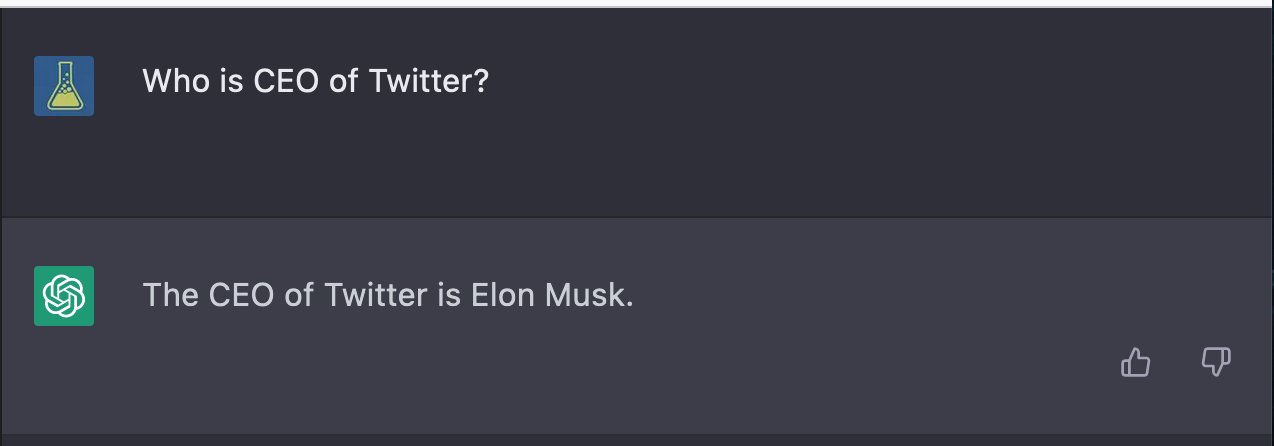
Fragt man allerdings „Wer ist CEO der Twitter, Inc.“ antwortet die KI (in ihrem Kontext korrekt) mit dem Hinweis, dass sich diese Information in der Zwischenzeit geändert haben könnte.
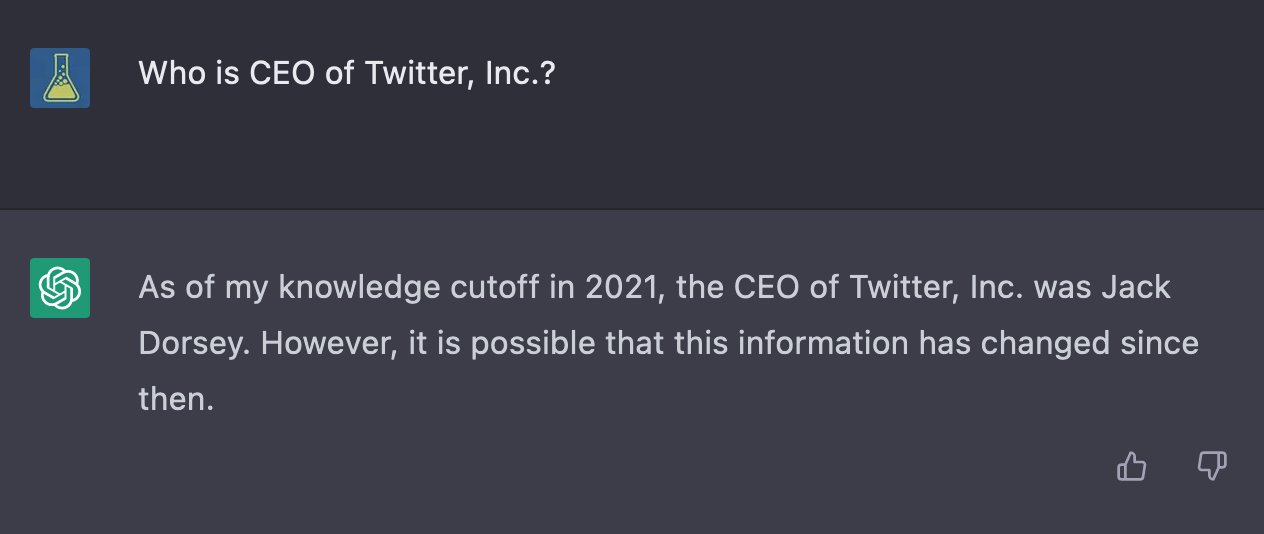
Daraus lässt sich schließen, dass nach den Wörtern „CEO“ und „Twitter“ schlichtweg wahrscheinlicher „Elon Musk“ folgt, weil er mit seinen Eskapaden und Marketing-Stunts rund um Tesla und SpaceX derart viele Erwähnungen im Internet hatte, dass „Jack Dorsay“ dagegen – statistisch gesehen – verliert.
Erst die Spezifizierung auf „Twitter, Inc.“ liefert das korrekte Ergebnis, da es sich um eine andere Entität (Tokenraum) im Bezugssystem handelt.
Wieso „trainiert“ man ChatGPT nicht mit aktuellem Wissen?
Auf meinen Hinweis, dass es sich dabei nicht um korrekte Antworten handelt, kommt oft der Vorschlag, man müsse doch nur das Modell mit aktuelleren Daten trainieren und schon müssten die Informationen doch korrekt sein. Doch das ist nicht richtig. Denn:
Die Art und Weise, wie das Modell aufgebaut ist, ist nicht dazu geeignet, mit aktuellen Fakten nach trainiert zu werden. Es ist schlicht viel zu aufwändig, permanent ein solch gigantisches Neuronales Netz zu trainieren. Außerdem müsste sich ein neuer Fakt, also beispielsweise dass Elon Musk nun CEO von Twitter ist und nicht mehr Jack Dorsay, erstmal in derart vielen Artikeln niederschlagen, damit die Mehrheit aller Dokumente diese Tatsache enthalten, bevor das neuronale Netz dies als richtige Antwort „verinnerlicht“.
Dass GPT-3 überhaupt in der Lage ist, zu vielen Anfragen plausibel klingende und zum Teil auch korrekte Informationen wiederzugeben, ist das Ergebnis der Tatsache, dass diese Information sehr häufig in den Trainingsdaten enthalten war und sich daher (neben der Grammatik der Sprache) im Modell abgebildet wurde.
GPT ist grundsätzlich nicht besonders dazu geeignet Informationen und Fakten abzuspeichern und wiederzugeben! Für einen derartigen Fall gibt es wesentlich bessere und effizientere Methoden.
Im neuronalen Netz werden keine Fakten oder Informationen über die Welt gespeichert. Es speichert nur die Schwellenwerte, an denen ein einzelnes Neuron auf Grundlage seiner Eingangswerte und der Aktivierungsfunktion feuert, oder eben nicht. Ganz ähnlich wie im menschlichen Gehirn und ebenso Fehleranfällig. Wir können als Zeugen eines Unfalls auch nie alle Details wie Farbe und Typ eines Fahrzeuges erinnern und korrekt wiedergeben.
ChatGPT als Suchmaschine?
Aus dem letzten Absatz sollte klar geworden sein, wieso ChatGPT (ohne ein Suchsystem dahinter) nicht dazu geeignet ist, als Suchmaschine verwendet zu werden, auch wenn viele trotzdem tun!
ChatGPT kann weder auf Webseiten zugreifen, noch ist das trainierte Modell dahinter besonders gut dazu geeignet Fakten zu speichern und wiederzugeben.
Es gibt KI-getriebene Suchmaschinen
Besser gesagt gibt es Suchmaschinen-getriebene KI-Chatbots. Googles Bard ist beispielsweise in der Lage über die Google Suche auf Inhalte zuzugreifen und nachdem Microsoft sein Investment in OpenAI auf stolze 49% der Anteile ausweiten konnte, wurde GPT-4 relativ zügig in eine Spezialform der Suche namens „New bing“ integriert. Mittlerweile hat Microsoft das Ganze in einen eigenen Dienst mit dem Namen Copilot ausgelagert.
Wie so etwas aussieht, liesst sich aber schon länger bei der Suchmaschine von KI-Wunderkind Richard Socher unter You.com in Form von You Chat ausprobieren!
Ebenfalls vor bing und Google hat es perplexity geschaft eine sehr vielversprechende Suchmaschine auf Basis von LLMs zu bauen und hat gerade sogar eine große Finanzierungsrunde inkl. Investments von Jeff Bezos und NVIDIA angekündigt, um Google im Suchmarkt angreifen zu können.
Durch den RAG-Ansatz, bei dem die gewünschten Informationen mittels klassischer Information Retrieval Methoden gefunden und diese als Quellen quasi zusammengefasst werden, sind die Informationen deutlich verlässlicher.
Man verwendet hierbei ein zusätzliches Layer, das aus der Nutzeranfrage eine Suchanfrage an die Web Index erstellt. Diese Suchanfrage wird im Hintergrund ausgeführt und die Informationen auf den ersten drei rankenden Webseiten werden extrahiert und wiederum dem Sprachmodell zur Verfügung stellt. Diese erstellt aus der Nutzerfrage und den Inhalten der rankenden Seite schließlich eine Antwort, sozusagen als Zusammenfassung.
Die Qualität dieser Systeme wird weniger von dem Sprachmodell verbessert, sondern inbesondere von der Suchtechnologie dahinter.
Allerdings leiden sämtliche LLM-getriebene Suchsysteme, also auch perplexity noch unter Halluzinationen und liefern zum Teil falsche Informationen, trotz korrekter Inputs durch die Quellen.
Man muss also das Modell garnicht permanent nachtrainieren, um aktuelle und korrekte Antworten zu erhalten. Man muss nur die Frage des Nutzers mittels GPT in eine Anfrage an die eigene Datenbank umformulieren lassen und die Liste der Ergebnisse mittels GPT wieder versprachlichen.
Texttransformation. Dafür ist GPT gebaut worden.
Nicht dafür Antworten zu geben oder Fakten zu speichern.
Natürlich kannst Du jetzt einfach ein Sprachmodell vor deine Datenbank packen. Dann hast du sofort einen vollautomatisierten Chatbot. Theoretisch zumindest, denn in der Praxis ist es extrem schierig mit unerwarteten Anfragen umzugehen und die Nutzererwartung nicht zu enttäuschen.
Abonniere das AFAIK-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz im Online Marketing!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen Rund um KI aus den Bereichen Online-Marketing, SEO, GEO, WordPress und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Monat eine E-Mail von mir. Versprochen.