Hattest Du schonmal folgenden Fehler beim Hochladen der Disavow-Datei und wusstest nicht, was Du tun sollst?
Die Datei disavow.txt darf entweder nur ASCII-Zeichen enthalten oder muss in UTF-8 codiert sein.Beim Hochladen der Datei mit für ungültig erklärten Links (disavow.txt) ist ein Fehler aufgetreten (siehe Fehlermeldungen oben). Der Upload wurde nicht durchgeführt.
Dann wird Dir diese Anleitung hoffentlich helfen, den Fehler zu finden und zu beheben:
Das Einfachste aus meiner Sicht ist es, die Disavow-Datei im ASCII-Zeichensatz zu belassen und alle Einträge, die nicht-ASCII-Zeichen enthalten, durch die jeweilige Repräsentation in Punycode für Domainnamen und URL-Codiert bei Pfaden zu ersetzen.
1. Finde nicht ASCII-Zeichen in Deiner Disavow-Datei
Dabei nutzt Du am besten einen Texteditor, bei dem Du RegEx, also reguläre Ausdrücke suchen kannst. Für Windows, Linux und Mac empfehle ich den Sublime Text Editor.
Hier kann man einfach bei der Suche ganz Links auf das .* Symbol klicken und nach dem regulären Ausdruck [^\x00-\x7F]+ suchen. Dann findet der Sublime Editor alle nicht-ASCII-Zeichen im aktuellen Dokument.
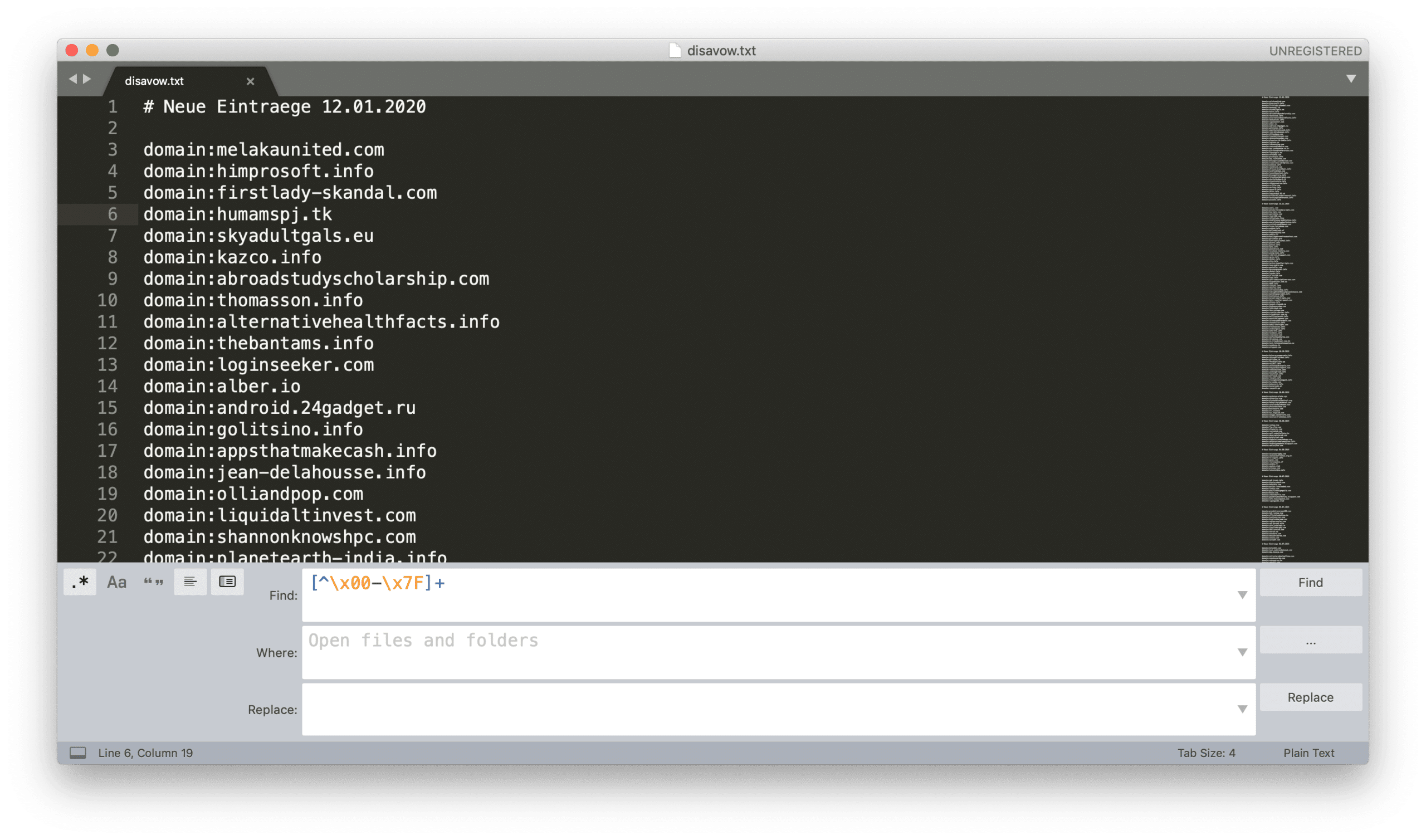
2. Ersetze Non-ASCII-Domains (IDNs) durch Punycode-Darstellung
Handelt es sich dabei um ein Zeichen innerhalb einer Domain, musst Du diese IDN mittels Punycode-Konverter in eine ASCII-Zeichenkette umwandeln.
So müsstest Du beispielsweise anstatt
domain:tráitim.vn
deinen Eintrag in
domain:xn--tritim-qta.vn
umwandeln.
3. Ersetze Non-ASCII-Pfade (UTF-8) durch URL-Codierung
Steht das gefundene Nicht-ASCII-Zeichen im Pfad einer URL, musst Du das Zeichen mittels URL-Encoder in eine URL-codierte ASCII-Zeichenkette umwandeln.
So wird beispielsweise aus
https://www.afaik.de/seo-münchen/
dann
https://www.afaik.de/seo-m%C3%BCnchen/
Hast Du nun sämtliche Zeichen durch ASCII- und URL-konforme Zeichen ersetzt, kannst Du die Disavow-Datei ganz normal abspeichern und im Disavow-Tool hochladen.
Noch ein wenig Hintergrundwissen zum besseren Verständnis gefällig?
Hintergrundwissen Zeichenkodierung
Was ist eigentlich ASCII und was ist UTF-8?
Hierbei handelt es sich um zwei Systeme zur Zeichenkodierung. Wie Du bestimmt weißt, arbeiten Computer intern ja nur mit Nullen und Einsen. Damit nun aber in einer Datei nicht nur 0 und 1 gespeichert werden kann, sondern auch menschenlesbarer Text, hat man sich auf ein System zur Codierung von Buchstaben in Nullen und Einsen geeinigt. ASCII (American Standard Code for Information Interchange) ist das erste System, das sich großflächig durchgesetzt und wurde bereits im Juni 1963 von der American Standards Association (ASA) als Standard gebilligt.
Der ASCII ist eine 7-Bit-Zeichenkodierung, verwendet also jeweils sieben Bits für einen Buchstaben und dient gleichzeitig als Grundlage für spätere, auf mehr Bits basierende Kodierungen für Zeichensätze wie beispielsweise UTF-8. Die Zeichenkodierung definiert 128 Zeichen, bestehend aus 33 nicht druckbaren sowie 95 druckbaren Zeichen. Druckbare Zeichen sind, beginnend mit dem Leerzeichen:
!“#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
Jedem Zeichen wird ein Bitmuster aus 7 Bit zugeordnet. Da jedes Bit zwei Werte annehmen kann, gibt es 27 = 128 unterschiedliche Muster, die auch als Zahlen 0–127 (hexadezimal 00h–7Fh) interpretiert werden können:
ASCII-Zeichentabelle, hexadezimale Nummerierung
| Code | …0 | …1 | …2 | …3 | …4 | …5 | …6 | …7 | …8 | …9 | …A | …B | …C | …D | …E | …F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0… | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1… | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2… | SP | ! | „ | # | $ | % | & | ‚ | ( | ) | * | + | , | – | . | / |
| 3… | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4… | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5… | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6… | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7… | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Bei UTF-8 wird diese Tabelle nun um 8-Bit Muster ergänzt und ermöglicht es somit gleichzeitig Buchstaben und Zeichen aus anderen Zeichensystemen, wie beispielsweise aus dem Chinesischen, Russischen oder Griechischen Alphabet direkt in Textdokumenten zu verwenden. UTF-8 ist der De-facto-Standard des Internets und in den ersten 128 Stellen abwärtskompatibel, das heißt in den ersten 128 Zeichen (Indizes 0–127) deckungsgleich mit ASCII.
Dadurch ist der Speicherbedarf für Zeichen vieler westlicher Sprachen geringer und eignet sich besonders für die Kodierung englischsprachiger Texte, die sich im Regelfall ohne Modifikation daher sogar mit nicht-UTF-8-fähigen Texteditoren ohne Beeinträchtigung bearbeiten lassen.
Was ist Punycode?
Domainnamen durften in den ersten 50 Jahren des Internets nur aus den Zeichen a bis z, 0 bis 9 und dem Bindestrich – bestehen. Da viele ältere Software, insbesondere in kritischer Infrastruktur des Internets nicht mit anderen Zeichen als diesen umgehen können, hat man sich bei der Einführung von Internationalisierten Domainnamen, den sogenannten IDNs, auf ein System zur Übersetzung von fremdsprachigen Unicode-Zeichenketten in ASCII-kompatible Zeichenketten geeinigt. Dieses System wird als Punycode bezeichnet. In Deutschland kennen wir dieses Phänomen seit der Einführung von Umlautdomains bei der DeNIC zum 1. März 2004. Seit Mai 2010 gibt es IDN-Top-Level-Domains und damit komplette Domains aus nicht-lateinischen Buchstaben.
Hier einige Beispiel-Domains und ihre entsprechende Schreibweise in Punycode:
- dömäin.example → xn--dmin-moa0i.example
- äaaa.example → xn--aaa-pla.example
- aäaa.example → xn--aaa-qla.example
- aaäa.example → xn--aaa-rla.example
- aaaä.example → xn--aaa-sla.example
- موقع.وزارة-الاتصالات.مصر → xn--4gbrim.xn—-ymcbaaajlc6dj7bxne2c.xn--wgbh1c
Da durch den Punycode also jedes nicht-ASCII-Zeichen ersetzt wird, ist dies auch die einfachste uns sicherste Variante eine IDN in einer Disavow-Datei einzutragen.
Was ist URL-Codierung?
URL-Codierung, auch URL-Encoding oder Prozentkodierung genannt, ist ein Verfahren, das dazu dient, nicht ASCII-konforme Informationen in einer URL zu kodieren. Innerhalb von URLs dürfen nur bestimmte Zeichen des ASCII-Zeichensatzes verwendet werden.
Ohne diese Kodierung wären viele Zeichen nicht in einer URL darstellbar. Beispielsweise wird ein Leerzeichen in aller Regel vom Browser als Ende der URL interpretiert, nachfolgende Zeichen würden ignoriert oder führten zu einem Fehler. Mit der URL-Kodierung kann ein Leerzeichen innerhalb eines Pfades oder eines Dateinamens durch die Zeichenfolge %20 übergeben werden.
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.
