Die wirklich entscheidende Fähigkeit in der KI ist nicht mehr das Prompting, sondern das Context Engineering.
Warum die Zukunft der KI denen gehört, die Informationen strukturieren können, und nicht nur denen, die Anweisungen formulieren.
1. Das Ende der Ära des „magischen Prompts“
In der rasanten Welt der künstlichen Intelligenz hat sich etwas grundlegend verschoben. Die Diskussion, die sich einst um die Kunst des „Prompt Engineering“ drehte, weicht nun einer breiteren, strategischeren Disziplin: dem Context Engineering. Führende Köpfe der Branche, von Shopify-CEO Tobi Lutke bis zum renommierten KI-Forscher Andrej Karpathy, haben diesen Wandel erkannt. Sie argumentieren, dass die wahre Herausforderung beim Bau leistungsfähiger KI-Systeme nicht mehr darin besteht, die perfekte Frage zu stellen, sondern eine umfassende Informationsumgebung zu schaffen, in der ein großes Sprachmodell (LLM) eine Aufgabe sinnvoll lösen kann.1
Dieser Wandel ist mehr als nur eine Wortklauberei; er markiert den Reifeprozess der KI von experimentellen Werkzeugen zu produktionsreifen Systemen, die in der Lage sind, komplexe, reale Probleme anzugehen. Um zu verstehen, warum dieser Wandel so fundamental ist, müssen wir uns zunächst die Reise des Prompt Engineering ansehen – seinen Aufstieg, seine Techniken und letztendlich seine Grenzen.
1.1 Der Aufstieg des Prompt Engineers: Ein notwendiger erster Schritt
Die anfängliche „Flitterwochenphase“ der generativen KI war geprägt vom Prompt Engineering, das sich als primäre Schnittstelle zur Kommunikation mit LLMs etablierte.3 Es war der erste entscheidende Schritt, um zu lernen, wie man mit diesen neuen, leistungsstarken Modellen „spricht“.5 Die Geschichte des Begriffs ist eng mit der Entwicklung der Verarbeitung natürlicher Sprache (NLP) verbunden, aber er wurde erst mit dem Aufkommen von Modellen wie GPT-3 zu einer kritischen Komponente, die zeigte, wie man das Verhalten von Modellen durch sorgfältig gestaltete Eingaben steuern kann.6
Prompt Engineering ist die Praxis, Anweisungen (Prompts) zu entwerfen und zu verfeinern, um spezifische Antworten von KI-Modellen zu erhalten, und fungiert als Brücke zwischen menschlicher Absicht und maschineller Ausgabe.4 In dieser Ära wurden mehrere Schlüsseltechniken entwickelt:
- Zero-Shot Prompting: Hier gibt man dem Modell eine direkte Anweisung ohne Beispiele. Diese Technik testet die Fähigkeit des Modells, sein vortrainiertes Wissen zu verallgemeinern.4 Ein Beispiel wäre die einfache Anweisung: „Erkläre das Konzept des Klimawandels.“
- Few-Shot Prompting / In-Context Learning: Bei dieser Methode gibt man dem Modell einige Beispiele (Shots), um seine Antwort zu lenken. Dies ist eine Art temporäres „On-the-fly“-Lernen, bei dem das Modell aus dem unmittelbaren Kontext lernt, ohne seine Parameter dauerhaft zu ändern.4 Man könnte dem Modell zum Beispiel einige Übersetzungspaare zeigen (
maison→house,chat→cat), bevor man es bittet,chienzu übersetzen.8 - Chain-of-Thought (CoT) Prompting: Diese fortgeschrittene Technik leitet das Modell durch eine Reihe von logischen Zwischenschritten, um zu einer Schlussfolgerung zu gelangen. Dies kann entweder als Zero-Shot-Prompt (durch Hinzufügen von Phrasen wie „Lass uns Schritt für Schritt denken“) oder als Few-Shot-Prompt (durch die Bereitstellung von Beispielen, die den Denkprozess demonstrieren) umgesetzt werden.4 Dieser Ansatz verbessert die Fähigkeit des Modells, komplexe logische oder arithmetische Probleme zu lösen, erheblich.
Andere Techniken wie Self-Consistency (Generierung mehrerer Denkketten und Auswahl der häufigsten Antwort) und Tree-of-Thought (Erkundung mehrerer Argumentationspfade parallel) sind Erweiterungen dieser Kernideen und zeigen die zunehmende Raffinesse des Feldes.8
1.2 Die semantische Drift: Als „Engineering“ zu „Tippen“ wurde
Trotz seiner technischen Tiefe litt das Prompt Engineering unter einem Wahrnehmungsproblem. Während es als komplexe Disziplin gedacht war, wurde es in der öffentlichen Vorstellung oft zu einem „lächerlich prätentiösen Begriff für das Eintippen von Dingen in einen Chatbot“ degradiert.1 Diese semantische Drift schuf die Notwendigkeit für einen neuen Begriff, der die Komplexität des Baus von produktionsreifen KI-Systemen besser erfasst.
Diese Entwicklung war nicht nur eine Frage der Umbenennung, sondern eine direkte Folge der Popularisierung der Technologie. Als Millionen von Nutzern begannen, mit Chatbots zu „prompten“, verlor der Begriff in der öffentlichen Wahrnehmung seine Assoziation mit tiefgreifendem technischem Fachwissen. Gleichzeitig standen Entwickler, die Anwendungen auf diesen Modellen aufbauten, vor Herausforderungen, die weit über einen einzelnen Prompt hinausgingen – wie Skalierbarkeit, Zustandsverwaltung und Datenintegration. Sie erkannten, dass ihre Hauptaufgabe nicht darin bestand, den Prompt-String zu schreiben, sondern alles um den Prompt herum zu verwalten. Diese intellektuelle und sprachliche Lücke wurde perfekt durch den Begriff „Context Engineering“ gefüllt, der von Branchenführern als eine präzisere Beschreibung der eigentlichen Arbeit beim Bau robuster KI-Systeme angenommen wurde.1
1.3 Risse im Fundament: Warum Prompt Engineering bei der Skalierung versagt
Der entscheidende Wendepunkt ist die Erkenntnis, dass Prompt Engineering zwar für einmalige Aufgaben und Demos wirksam ist, aber beim Aufbau zuverlässiger, skalierbarer Systeme an seine Grenzen stößt.10 Der Ansatz des „Vibe Coding“, bei dem man sich auf Intuition verlässt, um einen guten Prompt zu finden, bricht zusammen, wenn man versucht, etwas Reales zu bauen.3 Die Grenzen sind vielfältig und systemisch:
- Inkonsistenz und Nicht-Determinismus: Derselbe Prompt kann unterschiedliche Ergebnisse liefern, was ihn für kritische Arbeitsabläufe unzuverlässig macht. Geringfügige Änderungen am Prompt können an anderer Stelle zu Regressionen führen.11 Eine Studie zeigte, dass selbst subtile Variationen wie die Höflichkeit („Bitte“ vs. „Ich befehle“) die Leistung bei einzelnen Fragen dramatisch, aber inkonsistent beeinflussen können.13
- Beschränkungen des Kontextfensters: Prompts sind durch Token-Limits begrenzt. Bei langen Gesprächen oder komplexen Dokumenten vergisst das Modell frühere Anweisungen, was zu einem Verlust des Kontexts führt.14 Wichtige Informationen, die zu Beginn eines langen Gesprächs gegeben werden, können aus dem „Gedächtnis“ des Modells verdrängt werden.15
- Hölle der Skalierbarkeit und Wartung: Mit wachsenden Anwendungen wird die Verwaltung und Versionierung einer Vielzahl von spröden, fest codierten Prompts zu einer technischen Belastung. Ein Prompt, der in einem System funktioniert, schlägt in einem anderen fehl, und es gibt keine Standardisierung.11 Das Behandeln von Prompts wie Code – mit Versionierung, Tests und kontinuierlicher Evaluierung – wird unerlässlich, aber oft vernachlässigt.11
- Die Illusion der Einfachheit: Was in einer Chatbot-Oberfläche intuitiv erscheint, wird unglaublich komplex, wenn man es mit realen Variablen, Grenzfällen und Produktionsanforderungen zu tun hat.11 Der iterative Prozess der Feinabstimmung durch Versuch und Irrtum ist zeitaufwändig und frustrierend.15
- Modellabhängigkeit und mangelnde Portabilität: Prompts sind oft auf die Architektur und die Trainingsdaten eines bestimmten Modells zugeschnitten. Ein Prompt, der auf GPT-4o gut funktioniert, kann bei Claude 3 versagen, was zu einer Anbieterbindung und hohen Wechselkosten führt.15
Diese Einschränkungen offenbaren eine grundlegende Wahrheit über den aktuellen Stand von LLMs: Sie sind leistungsstarke Denkmaschinen, aber sie sind weder allwissend noch telepathisch. Ihr Versagen ist oft ein Eingabefehler, kein Modellfehler.2 Dies deutet darauf hin, dass die nächste Innovationswelle in der KI nicht von marginalen Verbesserungen der Modellarchitektur kommen wird, sondern von radikalen Verbesserungen der Systeme, die sie mit Informationen versorgen. Der Engpass hat sich von der „CPU“ (dem LLM) auf die „I/O“ (die Kontext-Pipeline) verlagert.
2. Definition der neuen Disziplin: Was ist Context Engineering?
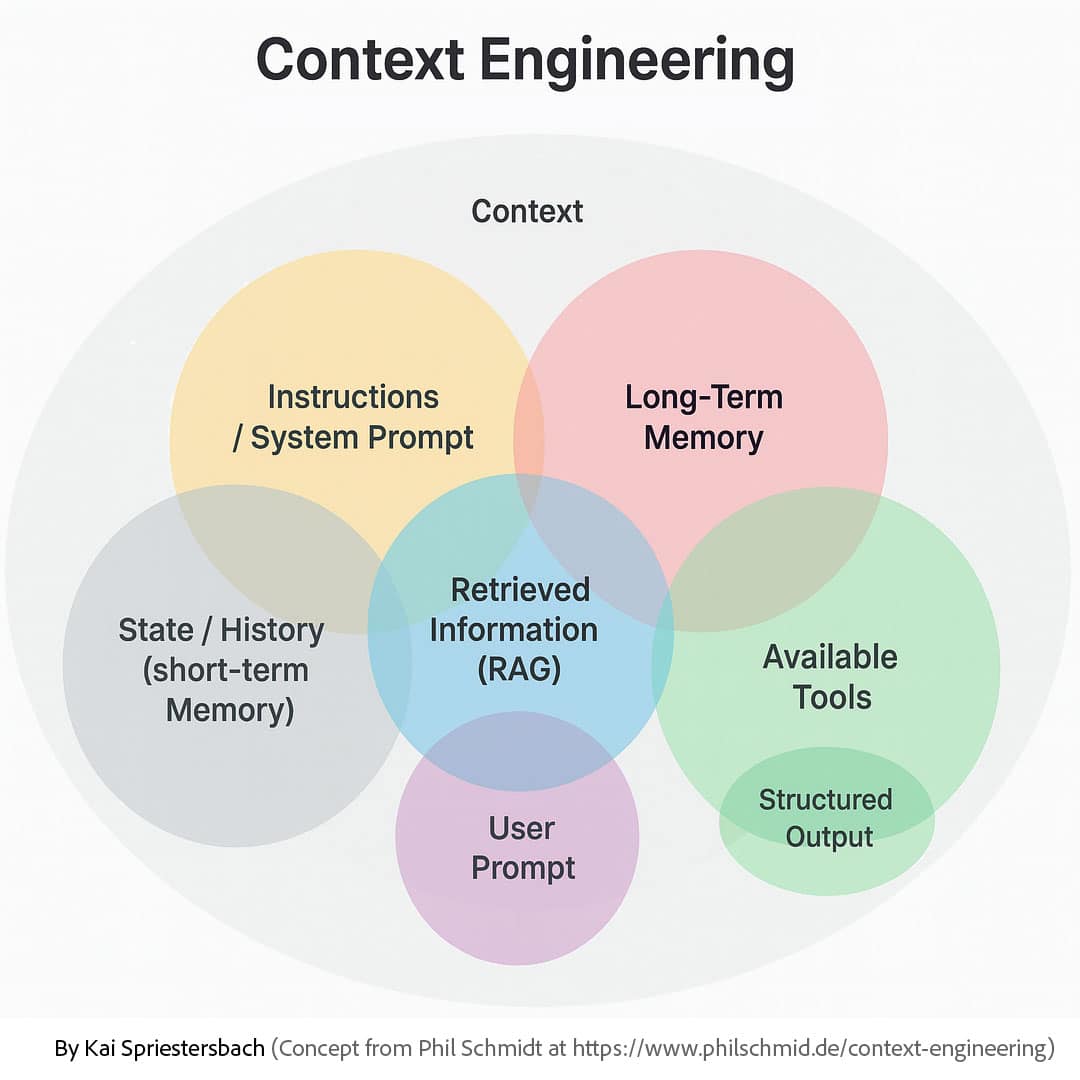
Während das Prompt Engineering an seine Grenzen stößt, tritt eine neue Disziplin in den Vordergrund, die einen grundlegenden Wandel in der Art und Weise darstellt, wie wir KI-Systeme konzipieren und bauen. Diese Disziplin, das Context Engineering, verlagert den Fokus von der Formulierung von Anweisungen auf die Architektur von Informationen.
2.1 Ein neues Paradigma: Die Architektur des „Geistes“ des Modells
Die formale Definition lautet: Context Engineering ist die Disziplin des Entwerfens und Bauens dynamischer Systeme, die zur richtigen Zeit die richtigen Informationen und Werkzeuge im richtigen Format bereitstellen, um einem LLM alles zu geben, was es benötigt, um eine Aufgabe plausibel zu bewältigen.2 Die Kernidee ist eine Verlagerung von der Konzentration darauf,
was man dem Modell sagt, hin zu der Konzentration darauf, was das Modell weiß, wenn man es ihm sagt.10 Es geht darum, die Bühne zu bereiten, bevor die Schauspieler ihre Zeilen sprechen.18
Eine treffende Analogie ist die des LLM als CPU und des Kontextfensters als dessen RAM.20 Prompt Engineering ist das Schreiben eines einzelnen Programms, das auf der CPU ausgeführt wird. Context Engineering hingegen ist das Betriebssystem, das den RAM verwaltet und die notwendigen Daten für jede gegebene Aufgabe lädt und entlädt.
2.2 Dekonstruktion des Kontextfensters: Das gesamte Informationsökosystem
Um Context Engineering zu verstehen, muss die Definition von „Kontext“ über einen einzelnen Prompt hinaus erweitert werden. Es ist alles, was das Modell sieht, bevor es eine Antwort generiert.2 Dieses Ökosystem umfasst mehrere entscheidende Komponenten 2:
- Anweisungen / System-Prompt: Die persistenten, übergeordneten Direktiven, die die Persona, Regeln und Einschränkungen der KI definieren (z. B. „Du bist ein hilfreicher Assistent für Rechtsrecherche“).
- Benutzer-Prompt: Die unmittelbare, aktuelle Frage oder Aufgabe des Benutzers.
- Zustand / Verlauf (Kurzzeitgedächtnis): Das laufende Gesprächsprotokoll, das den unmittelbaren Konversationskontext liefert.
- Langzeitgedächtnis: Eine persistente Wissensbasis mit Benutzerpräferenzen, früheren Interaktionen und Fakten, die über Sitzungen hinweg gesammelt wurden.
- Abgerufene Informationen (RAG): Dynamisch abgerufene externe Kenntnisse aus Dokumenten, Datenbanken oder APIs, um das Modell in Fakten zu verankern und ihm Zugriff auf aktuelle Informationen zu geben.
- Verfügbare Werkzeuge: Die Definitionen und Schemata von Funktionen oder APIs, die das Modell aufrufen kann, um Aktionen auszuführen oder weitere Informationen zu sammeln (z. B. eine
send_email-Funktion). - Strukturierte Ausgabe: Definitionen des gewünschten Antwortformats (z. B. ein JSON-Schema), um vorhersagbare, maschinenlesbare Ausgaben zu gewährleisten.
2.3 Eine Geschichte zweier Disziplinen: Prompt vs. Context Engineering
Die Unterschiede zwischen diesen beiden Disziplinen sind fundamental und lassen sich am besten in einer vergleichenden Analyse verdeutlichen.
Tabelle 1: Prompt Engineering vs. Context Engineering: Eine vergleichende Analyse
| Merkmal | Prompt Engineering | Context Engineering |
| Zweck | Eine spezifische Antwort auf einen einzelnen Prompt erhalten, meist für eine einmalige Aufgabe.10 | Sicherstellen, dass das Modell über Sitzungen, Benutzer und Aufgaben hinweg konsistent und zuverlässig agiert.10 |
| Umfang | Arbeitet mit einem einzelnen Eingabe-Ausgabe-Paar.10 | Verwaltet das gesamte Kontextfenster: Gedächtnis, Verlauf, Werkzeuge, System-Prompts.10 |
| Denkweise | Das Verfassen klarer Anweisungen; ähnlich dem kreativen Schreiben oder Copywriting.10 | Das Entwerfen des gesamten Informationsflusses und der Architektur; ähnlich dem Systemdesign oder der Softwarearchitektur.10 |
| Natur | Ein statischer String oder eine Vorlage.2 | Ein dynamisches System, das vor dem LLM-Aufruf läuft, um den Kontext on-the-fly zusammenzustellen.2 |
| Werkzeuge | Ein Texteditor oder eine Chatbot-Oberfläche.10 | RAG-Systeme, Vektordatenbanken, Gedächtnismodule, API-Verkettung, Orchestrierungs-Frameworks (z. B. LangGraph).10 |
| Fehlerbehebung | Umformulieren, Phrasen anpassen und raten.10 | Inspektion des gesamten Kontextfensters, der Gedächtnisslots, der Werkzeugaufrufe und des Token-Flusses mit Observability-Tools (z. B. LangSmith).10 |
| Skalierbarkeit | Spröde; bricht bei der Skalierung aufgrund von Grenzfällen zusammen.10 | Von Anfang an auf Skalierbarkeit und Wiederverwendbarkeit ausgelegt.10 |
| Beziehung | Eine Teilmenge des Context Engineering. Es ist das, was man innerhalb des Kontextfensters tut.10 | Die Disziplin, die entscheidet, was das Kontextfenster füllt.10 |
Dieser Wandel hat tiefgreifende architektonische und strategische Auswirkungen. Der Fokus der KI-Entwicklung verlagert sich von der Modellinteraktionsebene (dem Prompt) auf die Datenorchestrierungsebene (die Kontext-Pipeline). Das bedeutet, dass die wertvollste Arbeit nicht mehr im Moment des LLM-Aufrufs stattfindet, sondern in den vorbereitenden Schritten, die die Informationen für diesen Aufruf zusammenstellen. Wie es in einer Analyse treffend heißt: „Das Geheimnis beim Bau wirklich effektiver KI-Agenten hat weniger mit der Komplexität des von Ihnen geschriebenen Codes zu tun, sondern alles mit der Qualität des von Ihnen bereitgestellten Kontexts“.2
Die Wertschöpfung und Komplexität haben sich somit „stromaufwärts“ vom LLM-Aufruf verlagert. Die technische Herausforderung liegt nun in der Datenlogistik und Informationsarchitektur, nicht nur in der Linguistik. Dies verändert grundlegend, wie Organisationen über ihre Daten denken sollten. Daten sind nicht mehr nur ein passives Gut, das analysiert wird; sie sind eine aktive, dynamische Ressource, die in agentische Systeme eingespeist wird. Die proprietären Daten eines Unternehmens – Kundenhistorie, interne Dokumente, Produktschemata – werden zu seinem wichtigsten Wettbewerbsvorteil im Zeitalter der KI, da sie den einzigartigen Kontext bilden, den kein Konkurrent replizieren kann. Die Qualität der Context-Engineering-Infrastruktur eines Unternehmens wird direkt die Intelligenz seiner KI-Agenten bestimmen.
3. Der architektonische Bauplan kontextbewusster Systeme
Nachdem die grundlegende Philosophie des Context Engineering etabliert ist, ist es an der Zeit, in die technischen Details einzutauchen. Dieser Abschnitt bildet den technischen Kern des Artikels und erklärt, wie kontextbewusste Systeme aufgebaut sind, indem er die wichtigsten Bausteine und Strategien detailliert beschreibt.
3.1 Die tragende Säule: Retrieval-Augmented Generation (RAG)
Das Herzstück vieler moderner kontextbewusster Systeme ist die Retrieval-Augmented Generation (RAG). RAG ist der primäre Mechanismus, um LLMs in faktenbasiertem, externem Wissen zu verankern, wodurch Halluzinationen reduziert und der Zugriff auf Echtzeitinformationen ermöglicht wird.21 Anstatt sich nur auf das während des Trainings gelernte Wissen zu verlassen, leitet RAG das LLM an, relevante Informationen aus maßgeblichen, vorab festgelegten Wissensquellen abzurufen, bevor eine Antwort generiert wird.21
Der RAG-Prozess lässt sich in mehrere logische Schritte unterteilen:
- Datenaufnahme und -vorbereitung: Der Prozess beginnt mit der Sammlung externer Daten aus verschiedenen Quellen wie Dokumenten-Repositories, Datenbanken oder APIs.21
- Chunking: Große Dokumente werden in kleinere, semantisch zusammenhängende Abschnitte (Chunks) zerlegt. Dies verbessert die Relevanz und Effizienz des Abrufs, da das System gezielt auf bestimmte Themen fokussieren kann, anstatt ganze Dokumente zu verarbeiten.23
- Embedding: Ein Embedding-Modell wandelt die Text-Chunks in numerische Vektorrepräsentationen um. Diese Vektoren, die die semantische Bedeutung des Textes erfassen, werden in einer Vektordatenbank gespeichert.21 Diese Vektordatenbank fungiert als durchsuchbare Wissensbibliothek für das KI-System.24
- Abruf (Retrieval): Wenn eine Benutzeranfrage eingeht, wird diese ebenfalls in einen Vektor umgewandelt. Das System führt dann eine Ähnlichkeitssuche (z. B. mittels Kosinus-Ähnlichkeit) in der Vektordatenbank durch, um die Text-Chunks zu finden, deren Vektoren der Anfrage am ähnlichsten sind.23
- Anreicherung und Generierung (Augmentation & Generation): Die abgerufenen Chunks werden dem ursprünglichen Prompt als Kontext hinzugefügt. Dieser angereicherte Prompt wird dann an das LLM gesendet, um eine endgültige, faktenbasierte und kontextuell relevante Antwort zu generieren.21
RAG ist ein aktives Forschungsfeld, in dem kontinuierlich an Best Practices, der Behebung von Fehlerquellen und fortgeschrittenen Architekturen wie multimodalen RAG-Systemen gearbeitet wird, die über verschiedene Datentypen wie Text, Bilder und Videos hinweg funktionieren.26
3.2 Jenseits des Abrufs: Fortgeschrittene Strategien zur Kontextverwaltung
Während RAG die Wissensbasis liefert, sind weitere Strategien erforderlich, um ein wirklich dynamisches und intelligentes System zu schaffen.
Gedächtnis- und Zustandsverwaltung:
LLMs sind von Natur aus zustandslos, aber sinnvolle Interaktionen erfordern einen Zustand. Um dieses Problem zu lösen, werden Gedächtnismechanismen implementiert:
- Kurzzeitgedächtnis: Techniken wie die Zusammenfassung von Konversationen oder die Verwendung von gleitenden Kontextfenstern helfen, den Überblick über laufende Interaktionen zu behalten.17
- Langzeitgedächtnis: Informationen werden über Sitzungen hinweg persistent gemacht. Dies kann durch „Scratchpads“ (das Speichern von Plänen oder Notizen in einer Datei oder einem Zustandsobjekt) oder dadurch erreicht werden, dass das LLM basierend auf Interaktionen automatisch Erinnerungen generiert und in einer Datenbank speichert.20 Prominente Beispiele wie die Gedächtnisfunktion von ChatGPT zeigen diesen Ansatz in der Praxis.20
Agentischer Werkzeuggebrauch:
Um ein LLM von einem passiven Antwortgeber zu einem aktiven Problemlöser zu machen, wird es mit Werkzeugen ausgestattet.
- Das Konzept: Durch die Bereitstellung von Definitionen für Werkzeuge (APIs, Funktionen) kann ein Agent Aktionen ausführen, zusätzliche Informationen nachschlagen oder mit externen Systemen interagieren.17
- Funktionsweise: Wenn ein Agent mit einer Aufgabe konfrontiert wird, die er mit seinem aktuellen Kontext nicht lösen kann, kann er eine strukturierte Anfrage (z. B. ein JSON-Objekt) ausgeben, um ein bestimmtes Werkzeug aufzurufen. Das System führt das Werkzeug aus und speist das Ergebnis wieder in das Kontextfenster für den nächsten Denkschritt des LLM ein.20
Kontextorchestrierung: Die vier Kernoperationen:
Um das begrenzte „RAM“ des Kontextfensters effektiv zu verwalten, haben sich vier Schlüsselstrategien herauskristallisiert 20:
- Schreiben (Write): Persistieren von Kontext außerhalb des unmittelbaren Fensters (z. B. in einem Scratchpad oder Gedächtnis), um zu verhindern, dass er verloren geht.
- Auswählen (Select): Intelligente Auswahl der relevantesten Kontextteile für jeden Schritt (z. B. durch RAG oder das Abrufen spezifischer Erinnerungen).
- Komprimieren (Compress): Zusammenfassen oder Beschneiden weniger relevanter Informationen (wie ältere Teile eines Gesprächs), um Platz zu sparen und gleichzeitig den Kern zu erhalten.
- Isolieren (Isolate): Verwendung von Techniken wie Sandboxing, um Werkzeugaufrufe auszuführen oder den Zustand separat zu verwalten. Dies verhindert eine „Kontextvergiftung“ oder „Kontextverwirrung“, bei der irrelevante oder fehlerhafte Informationen den Hauptdenkprozess stören.20
3.3 Ein praktisches Framework für das Kontextdesign
Um von der Theorie zur Praxis zu gelangen, können Entwickler etablierte Frameworks nutzen. Die CLEAR-Methode für die Informationsarchitektur (Chronological, Layered, Essential, Accessible, Referenced) und das IMPACT-Framework für die Prompt-Konstruktion innerhalb des Kontexts (Intent, Method, Parameters, Audience, Criteria, Tone) bieten strukturierte Ansätze für das Design.31
Ein entscheidendes, aber oft übersehenes Konzept ist die „linguistische Kompression“: die Fähigkeit, die Anzahl der Tokens zu reduzieren und gleichzeitig die Informationsdichte zu maximieren. Dies ist eine entscheidende Fähigkeit, um das Beste aus einem begrenzten Kontextfenster herauszuholen.19 Darüber hinaus ermöglichen fortgeschrittene Konzepte wie „kognitive Werkzeuge“ – strukturierte Vorlagen, die den Denkprozess des LLM unterstützen – eine höhere Form des Werkzeuggebrauchs, die über einfache API-Aufrufe hinausgeht.33
Diese Komponenten sind nicht nur ein Werkzeugkasten; sie bilden ein dynamisches, zyklisches System. Die Ausgabe eines Werkzeugs kann in den Speicher geschrieben werden. Der Speicher kann beeinflussen, welche Dokumente über RAG abgerufen werden. Die abgerufenen Dokumente können Informationen enthalten, die ein anderes Werkzeug auslösen. Dies schafft eine „Denkschleife“, in der der Kontext bei jedem Schritt der Aufgabe eines Agenten ständig neu aufgebaut und verfeinert wird. Dies ist der Kern dessen, was einen Agenten „agentisch“ macht. Das Aufkommen umfassender Frameworks (wie LangGraph), detaillierter praktischer Anleitungen und sogar vorgeschlagener Protokolle (wie das Narrative Context Protocol) zeigt, dass sich das Context Engineering schnell von einer Sammlung von Ad-hoc-„Hacks“ zu einer formalen, strukturierten Ingenieurdisziplin mit eigenen Prinzipien, Mustern und Best Practices entwickelt. Dies ist ein klares Zeichen für ein reifendes technologisches Feld.
4. Context Engineering in Aktion: Von „billigen Demos“ zu „magischen“ Produkten
Die wahre Bedeutung einer technologischen Verschiebung zeigt sich nicht in der Theorie, sondern in der praktischen Anwendung. Context Engineering ist der entscheidende Faktor, der den Unterschied zwischen einer enttäuschenden KI-Interaktion und einem wirklich „magischen“ Erlebnis ausmacht. Dieser Abschnitt beleuchtet anhand von konkreten Beispielen und Fallstudien, wie die Architektur von Informationen die Leistung von KI-Systemen dramatisch verbessert.
4.1 Die Geschichte zweier Agenten: Die Macht eines reichhaltigen Kontexts
Ein eindrucksvolles Beispiel, das den Wert von Context Engineering verdeutlicht, ist die scheinbar einfache Aufgabe, ein Meeting zu planen.2
- Der „billige Demo“-Agent: Erhält nur den Benutzer-Prompt: „Hey, ich wollte nur fragen, ob du morgen Zeit für ein kurzes Gespräch hast.“ Da er keinen weiteren Kontext hat, ist seine Antwort roboterhaft und wenig hilfreich: „Wann würde es Ihnen passen?“ Er legt die gesamte kognitive Last wieder auf den Benutzer.
- Der „magische“ Agent: Bevor er das LLM aufruft, wird sein Kontext sorgfältig konstruiert. Er enthält:
- Ihren Kalender (der zeigt, dass Sie komplett ausgebucht sind).
- Ihre bisherigen E-Mails mit dieser Person (um den passenden informellen Ton zu treffen).
- Ihre Kontaktliste (um den Absender als wichtigen Partner zu identifizieren).
- Verfügbare Werkzeuge wie
send_inviteundsend_email.
Mit diesem reichhaltigen Kontext kann das LLM eine natürliche, hilfreiche und autonome Antwort generieren, die die Aufgabe erledigt: „Hey! Morgen ist leider komplett voll, aber ich habe übermorgen um 10 Uhr oder 15 Uhr Zeit. Habe dir eine Einladung für 10 Uhr geschickt, lass mich wissen, ob das passt.“ Die Magie liegt nicht in einem klügeren Modell, sondern im konstruierten Kontext.2
4.2 Unternehmensanwendung: Fallstudien zu kontextbewusster KI
Große Unternehmen setzen diese Prinzipien bereits ein, um messbare Geschäftsergebnisse zu erzielen. Die erfolgreichsten KI-Agenten sind diejenigen, die Informationen aus mehreren, proprietären Echtzeit-Datenquellen integrieren und synthetisieren können.
- Reisen & Buchung (Priceline & Booking.com): Der Agent „Penny“ von Priceline nutzt Kontextbewusstsein und Echtzeit-Sprach-Streaming für ein nahtloses Buchungserlebnis.34 Booking.com hat einen modularen KI-Reiseplaner entwickelt, der ein mehrschichtiges Agentensystem mit benutzerdefinierten Modellen und Orchestrierung verwendet, um personalisierte Reiserouten anzubieten. Dies führte zu höheren Konversionsraten und geringerer Latenz. Eine wichtige Erkenntnis von Booking.com war die Notwendigkeit, eigene Orchestrierungswerkzeuge zu entwickeln, da Open-Source-Lösungen im Produktionsbetrieb versagten – ein klares Zeichen für den Trend zu robustem, internem Context Engineering.34
- Flottenmanagement (Geotab): Der KI-Agent von Geotab ermöglicht es nicht-technischen Flottenmanagern, riesige und komplexe Fahrzeugdatenschemata in natürlicher Sprache abzufragen. Dies ist ein klassischer Anwendungsfall für RAG und Context Engineering, der den Datenzugriff vereinfacht und bessere Entscheidungen ohne SQL-Kenntnisse ermöglicht.34
- Versicherungswesen (Five Sigma): Five Sigma konnte die Fehlerquote um 80 % senken, indem es KI-Systeme implementierte, die Context Engineering nutzen, um gleichzeitig auf Policendaten, Schadenshistorien und regulatorische Informationen zuzugreifen.35
- Finanzwesen (Bud Financial): Dieses agentische System geht über das Beantworten von Fragen hinaus und ergreift Maßnahmen. Mit dem Kontext der Finanzhistorie und der Ziele eines Kunden kann es autonom Geld überweisen, um Überziehungsgebühren zu vermeiden oder bessere Zinssätze zu nutzen.36
Diese Fallstudien zeigen ein konsistentes Muster: Der Wert liegt nicht im LLM selbst, das zunehmend zur Ware wird, sondern in den proprietären Daten, die ihm zugeführt werden. Die Context-Engineering-Pipeline ist der entscheidende Mechanismus, der diesen Geschäftswert freisetzt.
4.3 Ein interdisziplinärer Werkzeugkasten: Praktische Beispiele
Die Anwendbarkeit des Context Engineering erstreckt sich über alle Branchen. Der Unterschied zwischen einem Standard-Prompt und einem kontextuell angereicherten Prompt ist in jedem Bereich spürbar 37:
- Programmierung:
- Standard-Prompt: „Schreibe eine Python-Funktion zum Parsen einer CSV-Datei.“
- Kontext-angereicherter Prompt: „Schreibe eine robuste Python-Funktion, die Pandas verwendet, um CSV-Dateien mit inkonsistenten Trennzeichen (manchmal Semikolon, manchmal Komma) und leicht variierenden Kopfzeilen (z. B. ‚Betrag‘ oder ‚Betr.‘) zu standardisieren und zu parsen.“
- Marketing:
- Standard-Prompt: „Schreibe einen Blogbeitrag über Produktivität.“
- Kontext-angereicherter Prompt: „Du schreibst einen kurzen, leicht sarkastischen Blogbeitrag für ausgebrannte Startup-Mitarbeiter, die allergisch auf das Wort ‚Hustle‘ reagieren. Ton: trockener Humor, minimaler Fülltext. Er sollte 5 Anti-Produktivitätstipps bieten – Dinge, die die Leute aufhören sollten zu tun, wenn sie fokussierter sein wollen. Betrachte es als das Gegenteil der üblichen Selbsthilfeartikel.“
- Rechtliches:
- Standard-Prompt: „Erstelle eine grundlegende NDA-Vereinbarung.“
- Kontext-angereicherter Prompt: „Du bist ein juristischer Mitarbeiter, der eine gegenseitige NDA für einen nicht-technischen Startup-Gründer und einen freiberuflichen Entwickler im Ausland (Indien) entwirft, die ein potenzielles KI-Projekt besprechen. Die Vereinbarung sollte die Vertraulichkeit von Geschäftsgeheimnissen, Quellcode und Kundendaten abdecken und nach indischem Recht durchsetzbar sein.“
- Medizinische Beratung:
- Standard-Prompt: „Was sind die Symptome von Diabetes?“
- Kontext-angereicherter Prompt: „Verhalte dich wie ein Hausarzt, der mit einem leicht ängstlichen 45-Jährigen spricht, der zu viel googelt. Erkläre die frühen Symptome von Typ-2-Diabetes in einfacher, nicht beunruhigender Sprache. Verwende bei Bedarf lockere Metaphern. Liste sie nicht wie ein Lehrbuch auf – erzähle eine Geschichte. Erwähne auch, welche Symptome unbedenklich sind, solange sie nicht anhalten. Beende mit: wann es in Ordnung ist zu warten und wann man einen Arzt aufsuchen sollte.“
Diese Beispiele zeigen, dass der Wettbewerbsvorteil in der Fähigkeit liegt, robuste Pipelines zur Nutzung einzigartiger Datenbestände aufzubauen. In vielen dieser Fälle ist das Context-Engineering-System das Produkt. Unternehmen bauen nicht mehr nur Apps, die eine KI aufrufen; sie bauen KI-native Systeme, bei denen die intelligente Orchestrierung von Kontext das zentrale Wertversprechen ist. Dies hat massive Auswirkungen auf das Produktdesign, die Infrastrukturinvestitionen und die Teamstruktur.
5. Der Wandel des Humankapitals: Neue Rollen und wesentliche Fähigkeiten
Der Übergang vom Prompting zum Context Engineering ist nicht nur ein technologischer, sondern auch ein menschlicher Wandel. Er definiert die auf dem Technologiemarkt gefragten Fähigkeiten neu und schafft neue Rollen, während er bestehende transformiert. Dieser Abschnitt analysiert die tiefgreifenden Auswirkungen dieses Wandels auf die Belegschaft und definiert die wesentlichen Fähigkeiten, die für den Erfolg im Zeitalter kontextbewusster KI erforderlich sind.
5.1 Der Aufstieg des Context Engineers
Wir erleben die Entstehung einer neuen, entscheidenden Rolle: des „Context Engineer“.38 Diese Rolle ist der Nachfolger des Prompt Engineers für ernsthafte KI-Implementierungen und geht weit über das Schreiben von Prompts hinaus. Ein Context Engineer ist ein Architekt des Informationsökosystems der KI.35 Es handelt sich um eine multidisziplinäre Rolle, die eine Mischung aus Fähigkeiten erfordert: teils Produktdesigner, teils Datenarchitekt, teils KI-Flüsterer.39 Ihre Hauptverantwortung liegt im Entwurf, Bau und der Wartung der Kontext-Pipelines, die LLMs mit den notwendigen Informationen versorgen.
5.2 Das Skillset des Context Engineers: Eine neue Art von Ingenieur
Die für diese neue Rolle erforderlichen Fähigkeiten sind spezifisch und anspruchsvoll. Sie spiegeln die systemische Natur der Aufgabe wider und erfordern eine Mischung aus technischen und konzeptionellen Kompetenzen 38:
- Informationsarchitektur: Die Fähigkeit, komplexe Informationshierarchien zu strukturieren, Inhalte innerhalb von Token-Beschränkungen zu optimieren und zu verstehen, wie verschiedene Datenformate das Verständnis der KI beeinflussen.
- Übersetzung von Domänenexpertise: Die Umwandlung von implizitem Geschäftswissen in expliziten, maschinenlesbaren Kontext. Dies erfordert die Überbrückung der Lücke zwischen Fachexperten und KI-Systemen.
- Design dynamischer Systeme: Der Bau von Systemen, die den Kontext basierend auf sich ändernden Anforderungen anpassen, die Echtzeit-Kontextzusammenstellung implementieren und Kontext-Pipelines über mehrere Datenquellen hinweg verwalten.
- Verständnis der „KI-Psychologie“: Die Intuition dafür, wie unterschiedliche Kontextstrukturen das Verhalten des Modells beeinflussen, das Erkennen von Mustern in KI-Antworten, die auf Kontextprobleme hinweisen, und die Fehlerbehebung von KI-Ausgaben durch Analyse der Kontextqualität.
- Sicherheits- und Compliance-Kontext: Sicherstellen, dass Kontext-Pipelines keine Sicherheitslücken einführen oder sensible Daten preisgeben, und die Implementierung von Audit-Trails für Kontextentscheidungen.
- Leistungsoptimierung: Das Ausbalancieren von Kontextreichtum mit den Rechenkosten (Latenz, finanzielle Kosten) und die effektive Verwaltung der Beschränkungen des Kontextfensters.
5.3 Die sich wandelnde Rolle des Produktmanagers
Das Context Engineering transformiert auch die Rolle des Produktmanagers in einem KI-getriebenen Unternehmen. Um die Entwicklung dieser komplexen Systeme effektiv zu leiten, benötigen sie ein neues Set von Fähigkeiten. Die folgenden Kompetenzen, die aus Analysen moderner Produktmanagement-Anforderungen abgeleitet wurden, sind entscheidend 40:
- Strategisches Denken & Vision: Die Definition des „Warum“ hinter dem Produkt und wie kontextbewusste KI die Geschäftsziele erreicht.
- Datengetriebene Entscheidungsfindung: Der Übergang von Intuition zur Nutzung von Datenanalysen (aus Nutzerverhalten, Markttrends), um zu bestimmen, welcher Kontext am wertvollsten ist.
- Technische Kompetenz: Produktmanager müssen nicht programmieren können, aber sie müssen die Architektur von Kontextsystemen (RAG, Vektordatenbanken, Agenten) verstehen, um fundierte Kompromisse eingehen und glaubwürdige Diskussionen mit den Ingenieurteams führen zu können. Ein Verständnis von Konzepten wie APIs und Datenmodellen ist unerlässlich.
- Kundenzentrierung & Empathie: Ein tiefes Verständnis der Schmerzpunkte der Nutzer, um den kritischsten Kontext zu identifizieren, der zur Lösung ihrer Probleme erforderlich ist.
- Kommunikation: Die Funktion als Übersetzer zwischen Geschäftsinteressenten, Fachexperten und dem technischen Context-Engineering-Team.
Die folgende Tabelle fasst die wesentlichen Fähigkeiten für Fachleute zusammen, die in diesem neuen Paradigma erfolgreich sein wollen.
Tabelle 2: Wesentliche Fähigkeiten für den kontextbewussten KI-Profi
| Rolle | Kernkompetenz | Beschreibung der Fähigkeiten |
| Context Engineer | Informationsarchitektur | Strukturierung komplexer Daten, Optimierung für Token-Limits, Verständnis von Datenformaten.38 |
| Design dynamischer Systeme | Bau adaptiver, echtzeitfähiger Kontext-Pipelines, die mehrere Quellen integrieren.38 | |
| „KI-Psychologie“ | Intuition für das Modellverhalten, Debugging von Ausgaben durch Analyse der Kontextqualität.38 | |
| Leistungsoptimierung | Abwägung von Kontextreichtum gegen Latenz und Kosten, Verwaltung von Kontextfensterbeschränkungen.38 | |
| Produktmanager | Strategisches Denken | Definition der Produktvision und Ausrichtung der KI-Fähigkeiten an den Geschäftszielen.41 |
| Datengetriebene Entscheidungsfindung | Nutzung von Analysen zur Priorisierung von Kontextquellen und zur Validierung von Hypothesen.42 | |
| Technische Kompetenz | Verständnis der KI-Architektur (RAG, Agenten), um fundierte Kompromisse einzugehen und die technische Machbarkeit zu beurteilen.41 | |
| Kommunikation & Empathie | Übersetzung zwischen technischen und geschäftlichen Teams, tiefes Verständnis der Nutzerbedürfnisse, um den relevantesten Kontext zu definieren.40 |
5.4 Der Ingenieur als KI-Copilot
Die vielleicht tiefgreifendste Veränderung ist die Neudefinition der Rolle des Ingenieurs. Ingenieure werden nicht durch KI ersetzt, sondern ihre Rolle wird aufgewertet. Sie werden zu den „menschlichen Copiloten“, die die Systeme architekturieren, die KI-Agenten erst wirklich effektiv machen.38 Der wertvollste Ingenieur ist derjenige, der das reichhaltigste und dynamischste Kontextsystem bauen kann.
Diese Entwicklung führt zu einer Konvergenz der Rollen. Ein Context Engineer muss wie ein Softwarearchitekt (Systeme entwerfen), ein Dateningenieur (Pipelines bauen) und ein Produktmanager (Nutzerabsicht und Geschäftslogik verstehen) denken. Ein Produktmanager muss wiederum technisch versierter sein als je zuvor. Dies schafft ein neues „Full-Stack“-KI-Profil, das stark funktionsübergreifend ist. Diese Rollenkonvergenz wird erhebliche Auswirkungen haben. Unternehmen müssen ihre Teams von isolierten Funktionen zu funktionsübergreifenden „KI-Agenten“-Teams umstrukturieren. Bildungseinrichtungen und Schulungsprogramme müssen neue Lehrpläne entwickeln, die diese Mischung aus Software, Daten und Produktstrategie vermitteln. Die Nachfrage nach diesen hybriden Fachleuten wird das Angebot bei weitem übersteigen, was zu einem erheblichen Talentengpass und einer enormen Chance für diejenigen führt, die sich weiterbilden.44
6. Die Zukunft ist kontextbewusst
Während sich die KI-Branche weiterentwickelt, wird deutlich, dass Context Engineering kein vorübergehender Trend ist, sondern die grundlegende Arbeit für die nächste Ära der künstlichen Intelligenz.45 Die Fähigkeit, Informationen effektiv zu architekturieren, wird die Gewinner von den Verlierern trennen. Dieser letzte Abschnitt blickt auf den Horizont, fasst die Bedeutung des Context Engineering zusammen und prognostiziert seine zukünftige Entwicklung.
6.1 Die unausweichliche Entwicklung: Hin zur vollen agentischen Autonomie
Das ultimative Ziel der aktuellen KI-Entwicklung ist die Schaffung hochentwickelter, autonomer KI-Agenten, die komplexe, mehrstufige Aufgaben ausführen können.35 Diese Agenten werden nicht nur auf Anfragen reagieren, sondern proaktiv handeln, planen und sich an neue Informationen anpassen. Gartner prognostiziert, dass bis 2028 33 % der Unternehmenssoftware agentische KI enthalten wird, was die Geschwindigkeit dieses Übergangs unterstreicht.35 Solche Systeme sind ohne ausgereifte Context-Engineering-Fähigkeiten unmöglich zu realisieren. Sie benötigen eine konstante Zufuhr von präzisem, relevantem und zeitnahem Kontext, um ihre Ziele zuverlässig zu erreichen.
6.2 Die nächsten Grenzen des Kontexts
Die Forschung und Entwicklung im Bereich des Context Engineering schreitet schnell voran und konzentriert sich auf mehrere wichtige zukünftige Trends:
- Multimodale Kontextintegration: Die nächste Grenze besteht darin, über reinen Text hinauszugehen und Bilder, Audio, Video und andere Datentypen nahtlos in einheitliche Kontext-Frameworks zu integrieren.35 Dies wird es KI-Systemen ermöglichen, in reichhaltigen, realen Umgebungen zu verstehen und zu agieren, anstatt auf textbasierte Interaktionen beschränkt zu sein. Neue Forschungsansätze wie UniversalRAG, die über verschiedene Modalitäten hinweg arbeiten, weisen bereits den Weg.27
- Automatisiertes Context Engineering: Die Entwicklung von Systemen, die Meta-Learning nutzen, um ihr eigenes Kontextmanagement zu optimieren, ist ein entscheidender nächster Schritt.35 Die KI wird lernen, welche Informationsquellen für welche Aufgaben am wertvollsten sind, und ihre eigenen Kontext-Pipelines automatisch verfeinern, um die Leistung zu verbessern und den manuellen Aufwand zu reduzieren. Dies führt zu einer weiteren Abstraktionsebene in der KI-Entwicklung. Wenn die KI ihren eigenen Kontext optimal auswählen, komprimieren und abrufen kann, verlagert sich die Aufgabe des menschlichen Ingenieurs von der manuellen Gestaltung der Pipeline-Logik zur Definition der übergeordneten Ziele, ethischen Leitplanken und Erfolgskriterien für diese autonomen Systeme. Der Mensch wird zum strategischen Direktor und ethischen Aufseher.
- Das kontextorientierte Unternehmen: Wir werden den Aufstieg von „Context Engines“ als Kernstück der Unternehmensinfrastruktur erleben.48 Unternehmen werden ihre Kontext-Pipelines als erstklassiges Produkt behandeln – versioniert, getestet und mit der gleichen Strenge gewartet wie ihre primären Anwendungen.39
6.3 Fazit: Kontext ist der neue Code
Während die Modelle weiter verbessert werden, wird der wahre Differenzierungsfaktor und die Quelle des Wettbewerbsvorteils die Qualität des Kontexts sein, den ein Unternehmen ihnen zur Verfügung stellen kann.49 Die Vision von KI-Agenten als primäres Ziel für Werbung, wie sie vom Gründer von Perplexity AI skizziert wurde, deutet auf einen seismischen Wandel in der digitalen Wirtschaft hin.30 Wenn Agenten, ausgestattet mit perfektem Kontext über unsere Vorlieben und Bedürfnisse, Kaufentscheidungen in unserem Namen treffen, würde die gesamte B2C-Marketing- und Werbebranche auf den Kopf gestellt. Der Fokus würde sich von der Erregung menschlicher Aufmerksamkeit mit emotionaler Werbung auf die Bereitstellung strukturierter, faktenbasierter Daten verlagern, die ein Agent analysieren kann, um eine optimale Entscheidung zu treffen. Dies würde eine neue „B2A“-Ökonomie (Business-to-Agent) schaffen und die Art und Weise, wie Produkte verkauft und entdeckt werden, grundlegend verändern.
Die abschließende Botschaft ist ein Aufruf zum Handeln: für Entwickler, Führungskräfte und Organisationen, ihren Fokus von der reinen Nutzung von KI auf die Architektur der intelligenten Systeme zu verlagern, die das nächste Jahrzehnt definieren werden. Die Beherrschung des Context Engineering ist nicht nur ein technischer Imperativ; es ist die strategische Grundlage für den Erfolg im Zeitalter der künstlichen Intelligenz.
Quellen
- Context engineering – Simon Willison’s Weblog, accessed July 3, 2025, https://simonwillison.net/2025/Jun/27/context-engineering/
- The New Skill in AI is Not Prompting, It’s Context Engineering – Philschmid, accessed July 3, 2025, https://www.philschmid.de/context-engineering
- Context Engineering is the New Vibe Coding (Learn this Now) – YouTube, accessed July 3, 2025, https://www.youtube.com/watch?v=Egeuql3Lrzg
- What is Prompt Engineering? A Detailed Guide For 2025 | DataCamp, accessed July 3, 2025, https://www.datacamp.com/blog/what-is-prompt-engineering-the-future-of-ai-communication
- A Complete Guide to Prompt Engineering | Build AI Applications With SingleStore, accessed July 3, 2025, https://www.singlestore.com/blog/a-complete-guide-to-prompt-engineering/
- Evolution – Prompt Engineering 4U, accessed July 3, 2025, https://www.promptengineering4u.com/learning/evolution
- Prompt Engineering Techniques | IBM, accessed July 3, 2025, https://www.ibm.com/think/topics/prompt-engineering-techniques
- Prompt engineering – Wikipedia, accessed July 3, 2025, https://en.wikipedia.org/wiki/Prompt_engineering
- What is In-context Learning, and how does it work: The Beginner’s Guide – Lakera AI, accessed July 3, 2025, https://www.lakera.ai/blog/what-is-in-context-learning
- Context Engineering vs Prompt Engineering | by Mehul Gupta | Data …, accessed July 3, 2025, https://medium.com/data-science-in-your-pocket/context-engineering-vs-prompt-engineering-379e9622e19d
- Building with LLMs? Prepare for these 8 prompt engineering challenges, accessed July 3, 2025, https://learningdaily.dev/building-with-llms-prepare-for-these-8-prompt-engineering-challenges-8c4216aa7a3b
- Prompt Engineering: Challenges, Strengths, and Its Place in Software Development’s Future, accessed July 3, 2025, https://www.infoq.com/articles/prompt-engineering/
- Technical Report: Prompt Engineering is Complicated and Contingent, accessed July 3, 2025, https://gail.wharton.upenn.edu/research-and-insights/tech-report-prompt-engineering-is-complicated-and-contingent/
- The Limitations of AI Prompt Engineering – FatCat Coders, accessed July 3, 2025, https://fatcatcoders.com/it-glossary/prompt-engineering/limitations-of-prompt-engineering
- Why Prompt Engineering is still imperfect in 2025 – Educraft, accessed July 3, 2025, https://educraft.tech/why-prompt-engineering-is-still-imperfect-in-2025/
- How developers can overcome prompt engineering challenges – Educative.io, accessed July 3, 2025, https://www.educative.io/blog/prompt-engineering-challenges
- The rise of „context engineering“ – LangChain Blog, accessed July 3, 2025, https://blog.langchain.com/the-rise-of-context-engineering/
- Context Engineering vs Prompt Engineering : r/ChatGPTPromptGenius – Reddit, accessed July 3, 2025, https://www.reddit.com/r/ChatGPTPromptGenius/comments/1lmnj1j/context_engineering_vs_prompt_engineering/
- What’s this ‚Context Engineering‘ Everyone Is Talking About?? My Views.. : r/ClaudeAI, accessed July 3, 2025, https://www.reddit.com/r/ClaudeAI/comments/1lnxk1r/whats_this_context_engineering_everyone_is/
- Context Engineering – LangChain Blog, accessed July 3, 2025, https://blog.langchain.com/context-engineering-for-agents/
- What is RAG? – Retrieval-Augmented Generation AI Explained – AWS, accessed July 3, 2025, https://aws.amazon.com/what-is/retrieval-augmented-generation/
- RAG Architecture Explained: A Comprehensive Guide [2025] | Generative AI Collaboration Platform, accessed July 3, 2025, https://orq.ai/blog/rag-architecture
- What is Retrieval Augmented Generation (RAG)? – DataCamp, accessed July 3, 2025, https://www.datacamp.com/blog/what-is-retrieval-augmented-generation-rag
- What Is Retrieval-Augmented Generation aka RAG – NVIDIA Blog, accessed July 3, 2025, https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
- A Complete Guide to Retrieval-Augmented Generation – Domo, accessed July 3, 2025, https://www.domo.com/blog/a-complete-guide-to-retrieval-augmented-generation
- [2501.07391] Enhancing Retrieval-Augmented Generation: A Study of Best Practices – arXiv, accessed July 3, 2025, https://arxiv.org/abs/2501.07391
- [2504.20734] UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities – arXiv, accessed July 3, 2025, https://arxiv.org/abs/2504.20734
- Seven Failure Points When Engineering a Retrieval Augmented Generation System – arXiv, accessed July 3, 2025, https://arxiv.org/abs/2401.05856
- Context Engineering: Why Feeding AI the Right Context Matters | by Inspired Nonsense, accessed July 3, 2025, https://inspirednonsense.com/context-engineering-why-feeding-ai-the-right-context-matters-353e8f87d6d3
- Context engineering emerges as crucial discipline for AI agent success – PPC Land, accessed July 3, 2025, https://ppc.land/context-engineering-emerges-as-crucial-discipline-for-ai-agent-success/
- Created a simple, comprehensive Prompt/Context Engineering Guide for Beginners : r/ChatGPT – Reddit, accessed July 3, 2025, https://www.reddit.com/r/ChatGPT/comments/1lojpza/created_a_simple_comprehensive_promptcontext/
- Context Engineering tutorials for beginners (YT Playlist) : r/PromptEngineering – Reddit, accessed July 3, 2025, https://www.reddit.com/r/PromptEngineering/comments/1low4l1/context_engineering_tutorials_for_beginners_yt/
- davidkimai/Context-Engineering, GitHub, accessed July 3, 2025, https://github.com/davidkimai/Context-Engineering
- AI Agent Useful Case Study – Three Real World Examples, accessed July 3, 2025, https://arize.com/ai-agent-useful-case-study/
- Context is Everything: The Massive Shift Making AI Actually Work in …, accessed July 3, 2025, https://www.philmora.com/the-big-picture/context-is-everything-the-massive-shift-making-ai-actually-work-in-the-real-world
- 6 Agentic AI Examples and Use Cases Transforming Businesses – Moveworks, accessed July 3, 2025, https://www.moveworks.com/us/en/resources/blog/agentic-ai-examples-use-cases
- Context Engineering Examples – Medium, accessed July 3, 2025, https://medium.com/data-science-in-your-pocket/context-engineering-examples-015c662fcb69
- You Are the Copilot: Why Engineers Must Master Context … – Medium, accessed July 3, 2025, https://medium.com/@jblakemartin/you-are-the-copilot-why-engineers-must-master-context-engineering-for-ai-success-37f61079a571
- Context Engineering Will Decide the Winners in AI | by Dinand Tinholt | Jun, 2025 | Medium, accessed July 3, 2025, https://medium.com/@tinholt/context-engineering-will-decide-the-winners-in-ai-700ad063ced7
- Top Skills of a Product Manager (and How to Develop Them) | Stanford Online, accessed July 3, 2025, https://online.stanford.edu/top-skills-product-manager-and-how-develop-them
- 18 Product Manager Skills to Master in 2025, accessed July 3, 2025, https://productschool.com/blog/skills/product-manager-skills
- 14 Essential Product Management Skills | Userflow Blog, accessed July 3, 2025, https://www.userflow.com/blog/14-essential-product-management-skills
- 12 Critical Product Managers Skills to Focus on in 2025 | Sembly AI, accessed July 3, 2025, https://www.sembly.ai/blog/the-core-product-manager-skills/
- The Impact of AI in Engineering: Key Applications and Trends – Rutgers University, accessed July 3, 2025, https://engineeringmastersonline.rutgers.edu/articles/how-is-ai-driving-revolution-in-engineering/
- The Rise of Context Engineering: Why AI’s Future Depends on More Than Just Prompts #ainews #ai – YouTube, accessed July 3, 2025, https://www.youtube.com/watch?v=cfUV1nFjftE
- Context Engineering: The Next Frontier in AI Usability and Performance | by Md Mazaharul Huq | Jun, 2025 | Medium, accessed July 3, 2025, https://medium.com/@jewelhuq/context-engineering-the-next-frontier-in-ai-usability-and-performance-c71bee6f8f7b
- Context Engineering: The Future of AI Prompting Explained – AI-Pro.org, accessed July 3, 2025, https://ai-pro.org/learn-ai/articles/why-context-engineering-is-redefining-how-we-build-ai-systems/
- Context Engines: The Future of AI in Application Development | data.world, accessed July 3, 2025, https://data.world/blog/the-next-frontier-in-application-development-is-context-aware-ai/
- Context engineering is what makes AI magical – Boris Tane, accessed July 3, 2025, https://boristane.com/blog/context-engineering/
Dieser Artikel wurde mit Hilfe von Gemini 2.5 Pro und Deep Research verfasst.
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.



