
Vorwort: Wieso sind Suchsysteme und deren Verständnis relevant?
Suchsysteme helfen den Nutzern, sich im Internet zurecht zu finden. Sie bieten einen einfachen Zugang zu relevanten Webseiten und werden mittlerweile von 18 Millionen Internetnutzern in Deutschland täglich und weiteren 22,36 Mio. wöchentlich zur Informationssuche eingesetzt [1]. Stefan Schulz fasst den Nutzen treffend zusammen: „Suchmaschinen machen Informationen einfach handhabbar.“ [2] Bei der Wahl der Suchmaschine sind sich die Deutschen laut Schulz einig: „Egal wie alt und gebildet Menschen sind, sie verwenden nur eine Suchmaschine – Google. Fünf Milliarden Suchen verarbeitet das Unternehmen inzwischen täglich.“ [3]
Die Anzahl der an Google gestellten Suchanfragen (mit Ausnahme des Jahres 2014) steigt weltweit immer weiter an. So ist es nicht verwunderlich, dass auch kommerzielle Anbieter, wie zum Beispiel E-Commerce Unternehmen, Verlage oder auch TV-Sender, längst die Bedeutung der Suchmaschinen als Traffic-Kanal erkannt und in ihre Marketing-Aktivitäten einbezogen haben.
Relevanz von WDF * IDF innerhalb von Suchsystemen
TF-IDF (Term Frequency-Inverse Document Frequency) ist ein statistisches Verfahren, das verwendet wird, um die Wichtigkeit eines Begriffs in einem Dokument im Vergleich zu seiner Häufigkeit in einer Sammlung von Dokumenten (in der Regel eine Datenbank oder eine Sammlung von Dokumenten) zu bestimmen. Der Algorithmus berechnet zwei Metriken: Termfrequenz (TF) und die Inverse Dokumentfrequenz (IDF).
- TF misst die Häufigkeit, mit der ein Begriff in einem Dokument vorkommt. Es wird berechnet, indem die Anzahl der Vorkommen eines Begriffs in einem Dokument durch die Gesamtzahl der Wörter in diesem Dokument dividiert wird.
- IDF misst die Seltenheit eines Begriffs in einer Sammlung von Dokumenten. Es wird berechnet, indem die Anzahl der Dokumente in der Sammlung durch die Anzahl der Dokumente, in denen der Begriff vorkommt, dividiert wird, und dann die logarithmische Funktion angewendet wird.
Der TF-IDF-Wert eines Begriffs in einem bestimmten Dokument wird berechnet, indem die TF-Wert des Begriffs mit dem IDF-Wert des Begriffs multipliziert wird. Je höher der TF-IDF-Wert, desto relevanter und wichtiger ist der Begriff für das Dokument. Der Algorithmus wird in vielen Anwendungen wie der Informationssuche, Textanalyse und der Schlagwortgenerierung verwendet.
Doch dieses Verfahren ist nicht neu!
Karen Spärck Jones veröffentlichte bereits 1972 im Journal of Documentation einen Artikel mit dem “A statistical interpretation of term specificity and its application in retrieval”, indem die Spezifität eines Terms erstmals berechenbar beschrieben und später als inverse Dokumentenfrequenz bekannt wurde.[4] Diese Methode basiert darauf, die Anzahl aller Dokumente zu zählen, in denen das jeweilige Wort vorkommt. Die Denkweise war wie folgt: Ein Wort aus einer Suchanfrage, das in sehr vielen Dokumenten vorkommt, ist kein geeigneter Diskriminierer und sollte daher weniger stark im Vergleich zu einem Wort gewichtet werden, das in sehr wenigen Dokumenten vorkommt.
Kombiniert mit der Termfrequenz, also der Häufigkeit eines Begriffs im jeweiligen Dokument (je mehr, desto besser), hat es die inverse Dokumentenfrequenz in nahezu jeden Wortgewichtungs-Algorithmus gefunden. Die Klasse dieser Gewichtungs-Algorithmen, die generell mit WDF * IDF engl. TF*IDF bezeichnet werden (hierbei wird das IDF-Maß mit dem WDF-Maß multipliziert), haben sich als überaus robust und schwer zu schlagen erwiesen, sogar durch wesentlich ausgefeiltere Methoden und Theorien.[5]
Um die Gewichtung eines Terms in einem Dokument innerhalb eines Information Retrieval Systems zu ermitteln, wird dessen Häufigkeit also in Relation zur Häufigkeit dieses Begriffes in allen anderen Dokumenten im Index gesetzt.[6]
Wieso hilft TF * IDF bzw. WDF * IDF im SEO?
TF-IDF kann helfen, die Relevanz einer Seite für bestimmte Suchbegriffe zu bestimmen und so die Suchmaschinenoptimierung (SEO) zu verbessern. Indem es die wichtigsten Begriffe auf einer Seite identifiziert, kann es dazu beitragen, dass die Seite für diese Begriffe besser rankt.
Einige der Möglichkeiten, wie TF-IDF bei der SEO helfen kann, sind:
- Keyword-Optimierung: Indem es die wichtigsten Begriffe auf einer Seite identifiziert, kann es dazu beitragen, dass diese Begriffe in den wichtigsten Bereichen wie Überschrift, Inhaltsabschnitte und Meta-Tags verwendet werden.
- Content-Optimierung: Indem es die Häufigkeit und Relevanz von Begriffen auf einer Seite misst, kann es dazu beitragen, dass der Inhalt für die Zielgruppe und die Suchbegriffe optimiert wird.
- Konkurrenzanalyse: Indem es die wichtigsten Begriffe einer Seite im Vergleich zu Konkurrenten identifiziert, kann es dazu beitragen, die eigene SEO-Strategie zu verbessern.
Es ist zu beachten, dass der Algorithmus allein nicht ausreichend ist, um eine gute SEO-Strategie zu erstellen. Es müssen weitere Faktoren wie die Nutzerfreundlichkeit, die Ladezeit, die Verlinkung, die technischen Aspekte und die Qualität des Inhalts betrachtet werden.
Praxisbeispiel: TF * IDF bzw. WDF * IDF im Einsatz
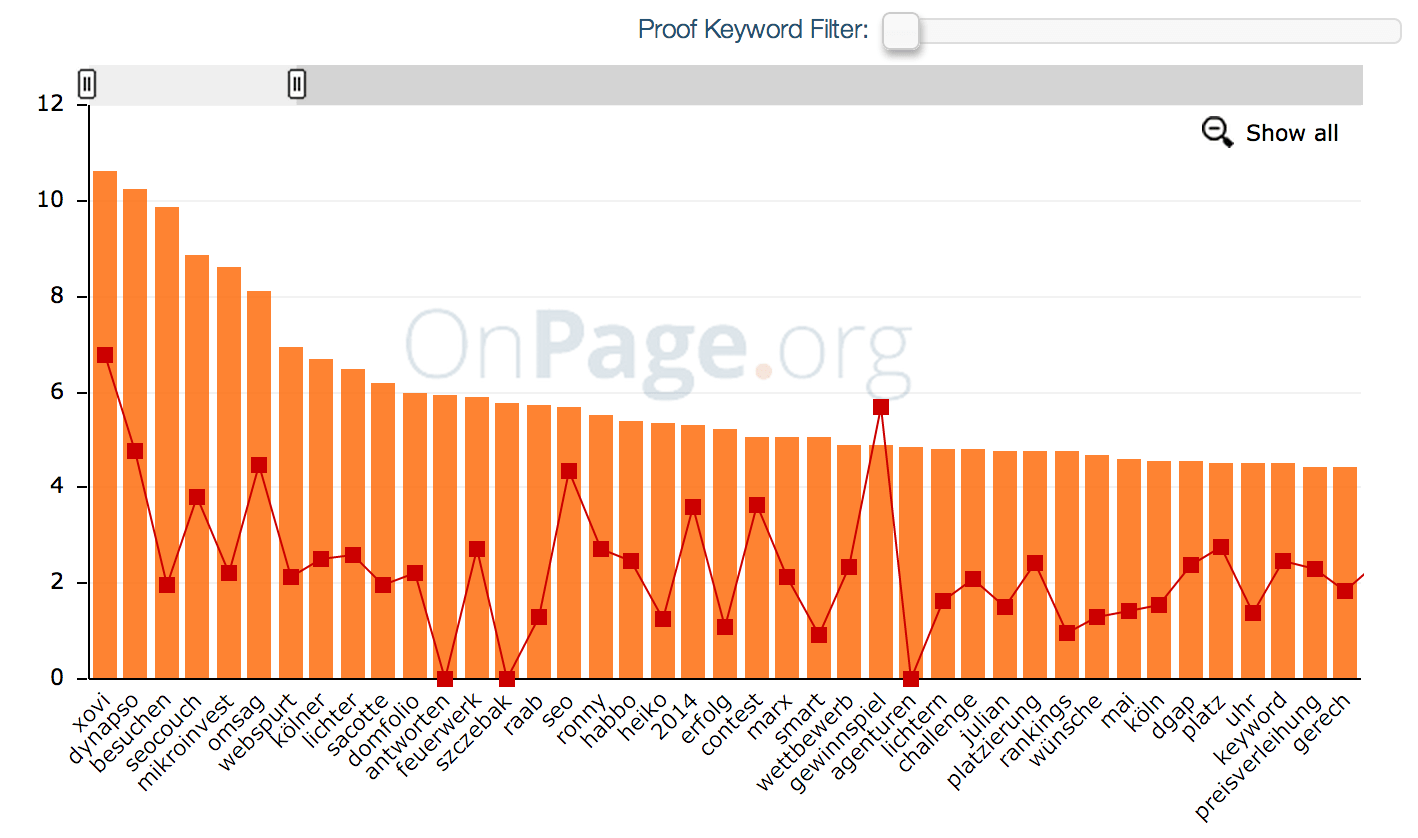
Selbst wenn Google selbst mittlerweile fortgeschrittenere Algorithmen einsetzt, findet man in einem guten TF * IDF Tool für informationsbezogene Suchanfragen, also sogenannte informational Queries, dennoch relevante Inhaltslücken, also Themen und Aspekte, die man in seinem Text noch ergänzen sollte. Beispielsweise hatte ich anfangs in meinem Artikel zu WordPress Hostings die Firmen webgo, strato und alfahosting nicht erwähnt, was mir ZU RECHT direkt von TermLabs um die Ohren gehauen wurde:
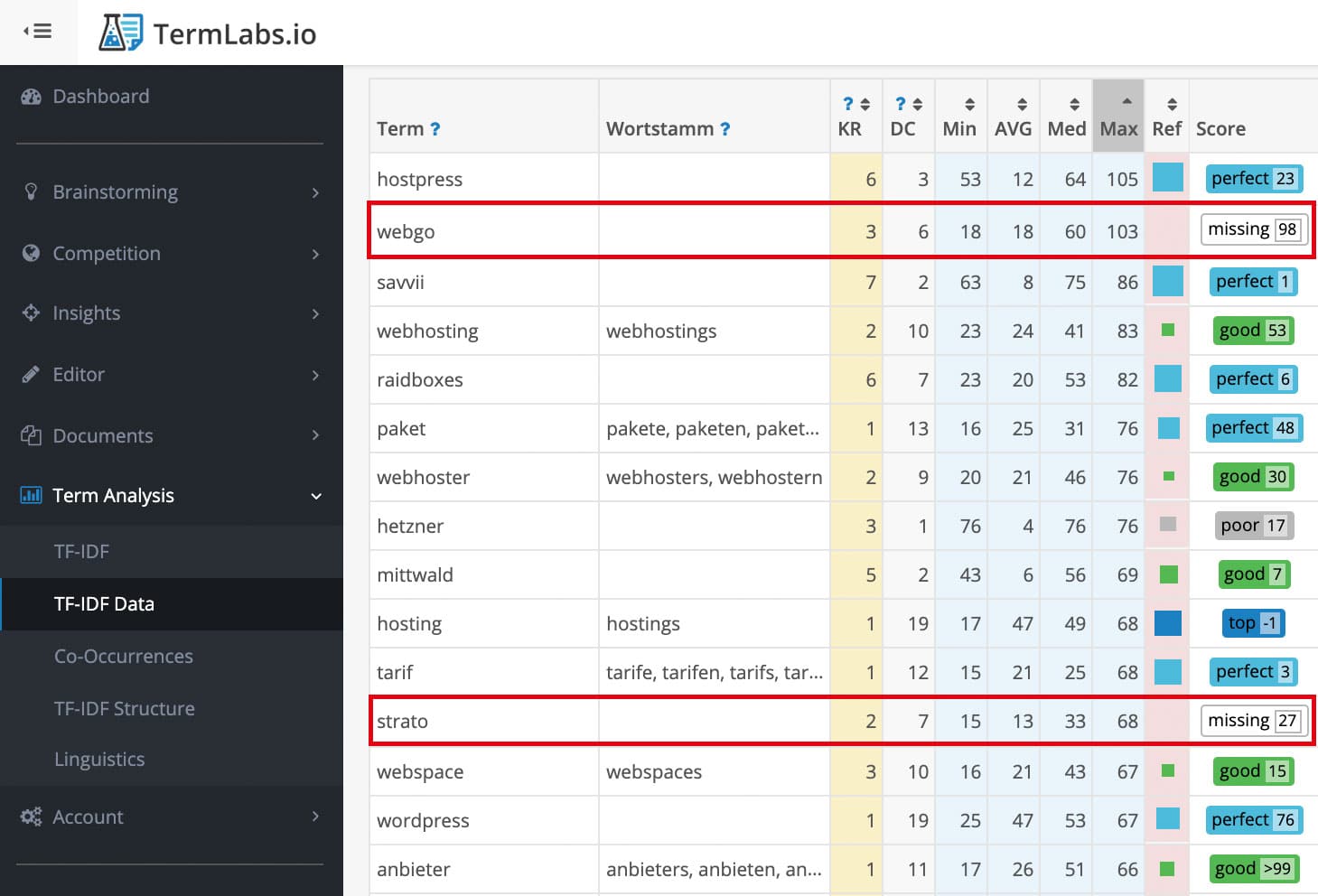
Diese als missing hervorgehobenen Begriffe stehen sinnbildlich für wichtige Themen, die der Leser in einem relevanten Dokument erwarten würde. Genau dafür ist ein gutes TF-IDF-Tool Gold wert!
Mit einem kostenlosen Tool kommt dagegen nur Unsinn bei raus:
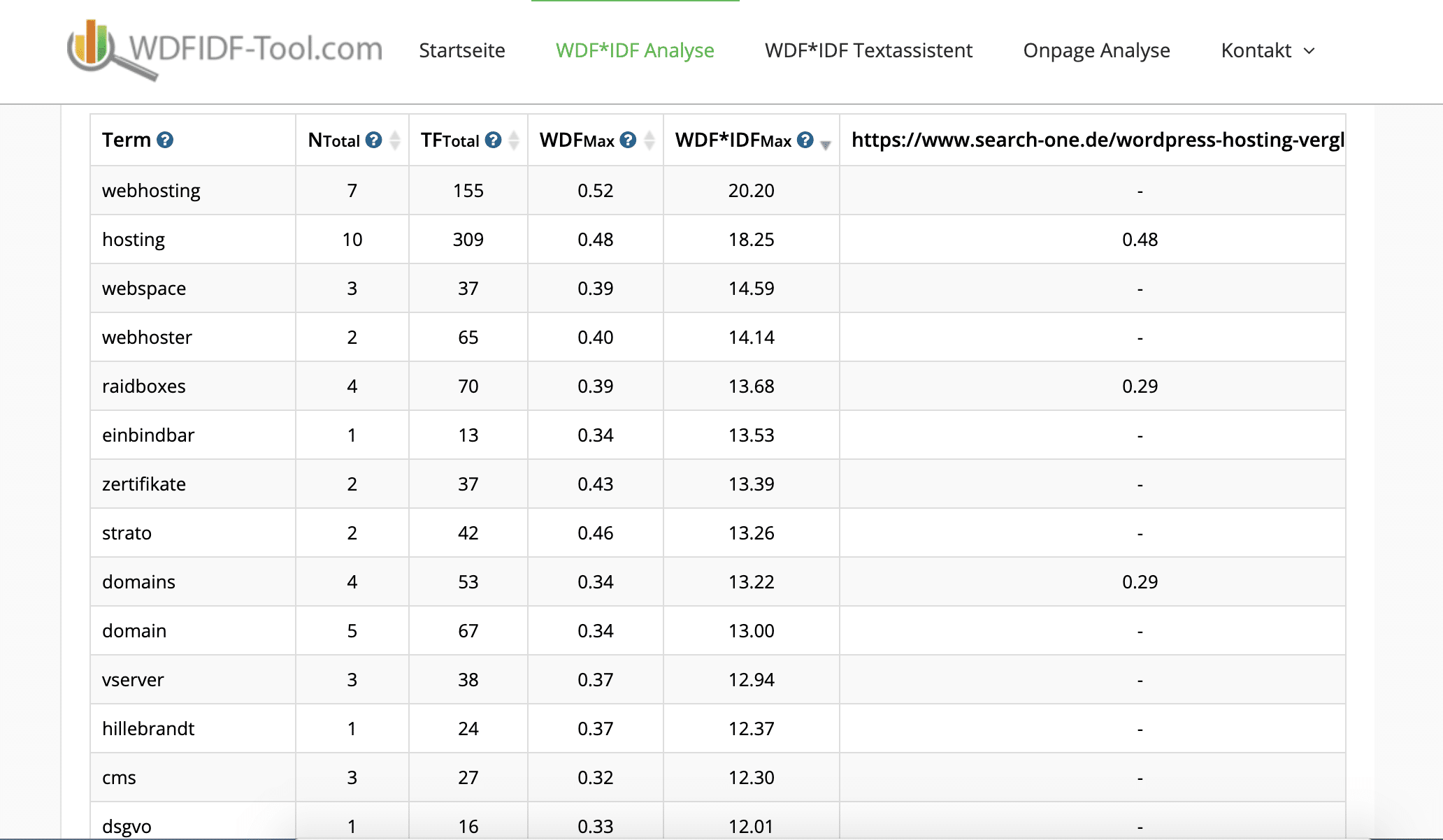
Das liegt an folgenden drei Fehlern, die nahezu alle WDF*IDF-Tools machen:
Keine Analyse ohne Stemming!
Die beiden Wörter ‚domain‘ und ‚domains‘ als zwei Terme zu behandeln (wie im obigen Beispiel) ist einfältig und fachlich schlicht falsch. Suchmaschinen führen mittels Stemming (Auch Stammformreduktion oder Normalformenreduktion genannt) alle Terme auf ihre Grundfunktion, also ihren Wortstamm zurück (Reduktion) und analysieren erst danach statistische Zusammenhänge!
Der Hauptinhalt muss extrahiert werden!
Ebenso wird das Layout analysiert und der Hauptinhalt analysiert, den Google in den Quality Rater Guidelines auch Main Content nennt. Hierbei werden Texte in Header, Footer und Sidebars quasi ignoriert, was die Relevanz der analysierten Terme deutlich verbessert.
Es geht nicht ohne guten Korpus und Termindex!
Letztendlich zeigt sich die Qualität einer guten Termanalyse inbesondere bei der korrekten Berechnung der inversen Termfrequenz. Dabei benötigt man einen möglichst vollständigen Dokumentenkorpus, den man regelmäßig aktualisiert und in einen Wortindex überführt, in dem alle Terme nach Häufigkeit sortiert vorliegen. Nur damit lässt sich effektiv die Gewichtung von Termen berechen!
Was ist der Unterschied zwischen WDF * IDF und TF * IDF
WDF*IDF (Weighted Log Frequency of Term) und TF-IDF (Term Frequency-Inverse Document Frequency) sind beide Algorithmen, die verwendet werden, um die Wichtigkeit von Begriffen in Dokumenten zu bestimmen. Der wesentliche Unterschied zwischen den beiden besteht darin, wie die Gewichtung der Begriffe berechnet wird.
TF-IDF berechnet die Gewichtung eines Begriffs in einem Dokument als die Multiplikation von seiner Termfrequenz (TF) und der Inverse Dokumentfrequenz (IDF).
WDF*IDF berechnet die Gewichtung eines Begriffs in einem Dokument als die Multiplikation von seiner WDF (Weighted Document Frequency) und IDF. WDF ist eine Funktion, die die Häufigkeit eines Begriffs in einem Dokument in Abhängigkeit von seiner Häufigkeit in der gesamten Dokumentensammlung berücksichtigt. Es ist eine Variation von TF-IDF, die es ermöglicht, die Wichtigkeit von häufigen Begriffen zu reduzieren, die in vielen Dokumenten vorkommen.
Im Allgemeinen sind sowohl TF-IDF als auch WDF*IDF gute Möglichkeiten, um die Relevanz von Begriffen in Dokumenten zu bestimmen und für Informationssuche, Textanalyse und Schlagwortgenerierung verwendet werden. Welcher Algorithmus am besten geeignet ist, hängt von der spezifischen Anwendung und dem verwendeten Datensatz ab.
BM25 schlägt TF-IDF und WDF*IDF
Es gibt noch weitere Algorithmen, die sich von TF-IDF und WDF*IDF unterscheiden, aber die Wichtigkeit von Begriffen berechnen, wie zum Beispiel BM25, das wieder eine andere Formel verwendet. BM25 berücksichtigt im Gegensatz zu TF-IDF und WDF*IDF auch die Länge des Dokuments, da längere Dokumente in der Regel eine höhere Anzahl von Schlüsselwörtern enthalten und daher als relevantere Ergebnisse angesehen werden können.
BM25 hat sich in der Praxis als einer der besten Algorithmen für die Dokumentenrelevanz bewährt.
Quellen
- [1] Vgl. VuMA (Arbeitsgemeinschaft Verbrauchs- und Medienanalyse). Anzahl der Personen in Deutschland, die das Internet zur Informationssuche (Suchmaschinen) nutzen, nach Häufigkeit von 2012 bis 2015 (in Millionen). https://de.statista.com/statistik/daten/studie/183133/umfrage/nachrichten-und-informationen—internetnutzung/ (Abgerufen am 23.09.2016).
- [2] Vgl. Schulz, Stefan, FAZ.net Google-Suchmaschine: Wir nutzen sie ohne einen blassen Schimmer http://www.faz.net/aktuell/feuilleton/buecher/google-suchmaschine-wir-nutzen-sie-ohne-einen-blassen-schimmer-13348664.html (Abgerufen am 22.09.2016)
- [3] Vgl. Ebenda
- [4] Vgl. Sparck Jones, K. (1972), A statistical interpretation of term specificity and its application in retrieval, Journal of Documentation, Vol. 28, S 11–21.
- [5] Vgl. Robertson, Stephen (2004) Understanding inverse document frequency: on theoretical arguments for IDF, Journal of Documentation , Vol. 60 Iss: 5 S 1.
- [6] Vgl. Ricardo Baeza-Yates, Berthier Ribeiro-Neto: Modern Information Retrieval. Addison-Wesley, Harlow u. a. 1999, S. 29–30.