Informationsarchitektur (IA) ist der Prozess der Organisation und Strukturierung von Informationen auf einer Website. Es geht darum, die Navigation bzw. das Finden von Inhalten für die Benutzer*innen so einfach wie möglich zu gestalten. Eine IA ist der Grundstein für eine erfolgreiche Website und kann dazu beitragen, dass Benutzer*innen sich länger auf der Seite aufhalten und schneller an die gewünschten Informationen gelangen. Dieser Artikel behandelt die Grundlagen, um eine solche IA zu gestalten.
[toc heading_levels=“2,3″]
Teil 1: IA-Grundlagen
1. Vorwort
Grundlage für diesen Artikel bilden die beiden Bücher „Information Architecture for the Web and beyond“ von Louis Rosenfeld, Peter Morville & Jorge Arango und „Integrierte Informationsarchitektur“ von Henrik Arndt.
2. Mentale Modelle & Metaphern
Metaphern stehen im Mittelpunkt nahezu aller User Interfaces interaktiver Anwendungen. Bei Metaphern handelt es sich wörtlich um eine Übertragung (meta (dt. über) pherein (dt. tragen)).
Nahezu unser gesamtes Verständnis zur Bedienung von Anwendungen beruht auf der Existenz von Metaphern (Vgl. Computer-Betriebssysteme: Ordner, Fenster, Papierkorb, Schreibtisch, etc.)
Louis Rosenfeld und Peter Morville haben für die Konzeption von Websites weitere Überlegungen zur Metapher angeführt:
- Organisations-Metaphern beschreiben die Übertragung eines bekannten Systems auf ein anderes, unbekanntes (Bsp.: Die Website eines Autohändlers kann in der gleichen Form organisiert sein, wie ein tatsächlicher physischer Showroom)
- Funktionale Metaphern sind einzelne abgeschlossene Aufgaben (Bsp.: Stöbern in den Regalen in einer Bibliothek (analog) bzw. im Online-Shop (digital) oder das Stellen einer Frage an einen Bibliothekar (analog) bzw. Kontakt-Formular oder Chatbot (digital)
- Visuelle Metaphern sind grafische Elemente wie zum Beispiel Bilder, Icons, Farben (Bsp.: Gelbe Seiten)
Die Struktur von Websites, v.a. Online-Shops, wird häufig mittels Organisations-Metaphern erklärt und organisiert. So sind bspw. die Kategorien vergleichbar mit den „Abteilungen“ bzw. Regalen im Einzelhandel (Bsp.: „Maschinen“ in Baumärkten oder „Feinkost“ in Supermärkten)


Nachdem Kund*innen die gewünschte Abteilung gefunden haben, suchen sie anschließend nach einem konkreten Produkt innerhalb der Abteilung. Das jeweilige Produkt-Listing in Online-Shops ist also vergleichbar mit den konkreten Regalen eines Baumarkts.


3. Strukturierung von Informationen / Klassifikation
Seit der Mensch Informationen (über die Welt) aufzeichnet strukturiert er diese. Aristoteles entwickelte 350 v. Chr. eine universale Struktur, die auf zehn Hauptkategorien basiert:
- Substanz
- Qualität
- Quantität
- Relation
- Ort
- Zeit
- Tun
- Lage
- Haben
- Leiden
Bis heute finden diese Kategorien in wissenschaftlichen Unterteilungen Verwendung.
Ein weiterer Meilenstein war der industrielle Buchdruck in Europa Mitte des 15. Jahrhunderts. Erst dadurch wurden Informationen nahezu der gesamten Bevölkerung zugänglich gemacht. Eine verständliche und nachvollziehbare Strukturierung von Informationen war deshalb von dort an umso wichtiger. Im Bibliothekswesen setzte sich die Bezeichnung „Klassifizierung“ durch, also die Einteilung des Wissens in ein System von sogenannten Klassen.

4. Hierarchien
Fast alle Klassifikationen sind hierarchisch strukturiert. Hierarchie bedeutet:
- Informationssektionen sind in verschiedenen Ebenen einander über- oder untergeordnet und jeweils von Ebene zu Ebene miteinander verknüpft
- Die Übergeordnete Sektion bildet immer die Kategorie für alle ihr untergeordneten Sektionen
- Jeder Sektion sind nur die Eigenschaften zugewiesen, die sie von der ihr übergeordneten Kategorie unterscheidet
Bsp.: Kraftfahrzeug -> PKW -> Cabrio

Wenn ein Mensch einmal das grundsätzliche Prinzip hierarchischer Strukturen versteht, kann er problemlos jedes auf diese Art strukturierte System nutzen. Genau das macht Hierarchien so mächtig und wertvoll für uns. Wir organisieren große Teile unserer Welt & unseres Lebens hierarchisch.
Probleme von Hierarchien
Durch die Verwendung von Hierarchien (in Websites) entstehen leider ebenfalls diverse Probleme. Größere Websites werden sehr schnell so umfangreich, dass einerseits das menschliche Vorstellungsvermögen an seine Grenzen kommt und andererseits eine Visualisierung ihrer Struktur erheblich erschwert wird.
Ein weiteres Problem von komplexen Strukturen ist, dass „der Weg“ zur gewünschten Information sehr lang ist. Nutzer*innen müssen auf jeder hierarchischen Ebene eine Entscheidung treffen, um einen Schritt weiter zu kommen.
Beispiel: Startseite Baumarkt > Technik > Eisenwaren & Beschläge > Nägel & Stifte > Stahlnägel & Stahlstifte
In der Konzeption von Websites wird hier häufig von „empty pages“ gesprochen, also Seiten, die selbst keinen wirklichen Inhalt bzw. Mehrwert haben, sondern deren einzige Aufgabe es ist, die Nutzer*innen zur gewünschten Information zu bringen.
Eine Mono-Hierarchie beschreibt eine Struktur in der es ausschließlich einen Weg zum gewünschten Ziel gibt. Diese Form der Klassifizierung stellt deshalb ein Problem dar, da nicht jedem*r Nutzer*in klar ist welcher Weg zur gewünschten Information führt
Beispiel: Gehören „Stahlnägel“ zur Übergeordneten Kategorie „Technik“ oder zu „Bauen“?
Websites bestehen oft aus polyhierarchischen Strukturen. Hier kann ein Produkt oder eine Information mehreren übergeordneten Kategorien zugeordnet werden. Diese Form der Klassifizierung verfügt jedoch ebenfalls über diverse Schwachpunkte (Stichwort Duplicate Content).
Teil 2: Was macht ein Informationsarchitekt?
Um die Aufgabenbereiche einer*s Informationsarchitekt*in bestmöglich zu beschreiben, bedienen wir uns am älteren, stärker verbreiteten und eng verwandten Berufsbild des Architekten.
Architekten verantworten die technische, funktionale, gestalterische und wirtschaftliche Planung.
Das Berufsbild des Architekten ist an der Schnittstelle zwischen Auftraggeber, den Planungsbeteiligten, Behörden und Ausführenden angesiedelt. Als zentrales „Organ“ übernimmt der Architekt die Projektsteuerung, vertritt den Bauherren gegenüber allen Beteiligten und koordiniert diese (Quelle: Wikipedia).
Während ein Architekt an der Konzeption und Errichtung von Gebäuden und Bauwerken beteiligt ist, übernimmt der Informationsarchitekt die Aufgaben der Planung und Erstellung interaktiver Anwendungen.
Beispiel: Web-Anwendungen (Websites, Apps, etc.)), lokale Software-Anwendungen oder die Mischung der beiden (Cloud-Anwendungen (SaaS))
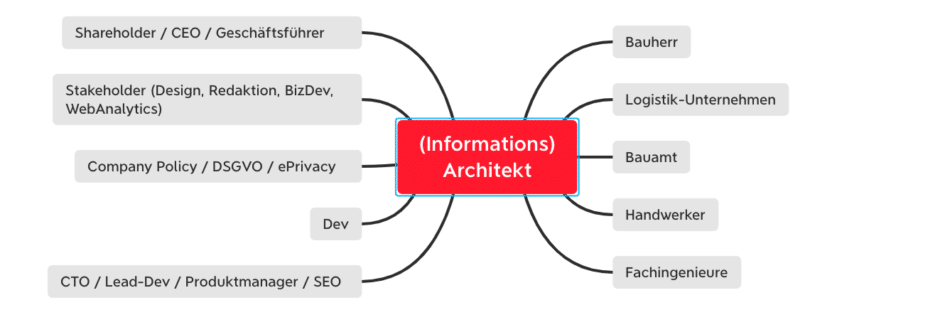
Übrigens: In diesem Teil „Was macht ein Informationsarchitekt“ bedienen wir uns bspw. einer Organisations-Metapher.
Apps oder Software-Anwendungen bilden häufig in sich geschlossene Systeme ab. Sie werden bspw. via App-Stores auf entsprechenden Endgeräten installiert und verwendet. Hersteller dieser Anwendungen können selbstständig festlegen was Nutzer*innen beim Öffnen der Anwendungen zuerst sehen und wie die Navigationsmöglichkeiten gestaltet werden sollen. Es gibt sozusagen einen klar definierten Ein- und Ausgang, vergleichbar mit der Organisation eines Supermarktes

Websites sind i.d.R. frei zugängliche Orte im WWW. Suchmaschinen und Bots von Social Media Portalen ermöglichen einen direkten Zugriff auf alle freigegebenen Unterseiten dieser Website. Dies hat zur Folge, dass es keinen eindeutigen Ein- und Ausgang gibt. Sie können über Suchmaschinen direkt auf einem Artikel landen, ohne die Startseite jemals besucht zu haben. Das wäre in der realen Welt so, als hätte ein Supermarkt keinen konkreten Ein- und Ausgang und Kund*innen könnten von allen Seiten in den Laden strömen.
Die IA-Anforderungen an Websites sind aufgrund dieser Tatsache multi-dimensional und erfordern ein hohes Maß an Komplexität.
Teil 3: IA-Komponenten
Rosenfeld und Morville teilen die Informationsarchitektur in vier Komponenten auf – Organisations-, Labeling-, Navigations- und Such-Systeme.
1. Organisations-Systeme
Wir organisieren unsere Welt so, dass sie uns Antworten auf unsere Fragen liefert. Unser Klassifizierungs-System bildet dabei das ab, was im Volksmund als „Schubladen denken“ bezeichnet wird. Entgegen der negativen Bedeutung des Schubladendenkens, ist es in unserem Kontext eine hilfreiche und sogar nahezu unumgängliche Eigenschaft menschlichen Denkens. Klassifizierungs-Systeme helfen uns grundsätzlich Dinge einzuordnen, damit wir sie überhaupt erst begreifen und verstehen können.
Digitale Medien ermöglichen einen enorm flexiblen Umgang mit diesen Organisations-Systemen. In den letzten Jahrzehnten, mit steigender Verbreitung des Internets, tritt das organisieren großer Mengen von Information stark in den Vordergrund. Jeder Mensch muss gewisse Fähigkeiten erwerben, um in der heutigen Zeit an genau diejenige Information zu gelangen, die er oder sie sucht (Stichwort „Googlen“, „Surfen“)
Klassifizierungs-Systeme bestehen aus Sprache – und Sprache ist mehrdeutig. In diesem Zusammenhang treten bereits die ersten Hürden auf – auf einer „Bank“ kann ich entweder sitzen oder Geld abheben.


Die unterschiedlichen Perspektiven, mit welchen Menschen auf Organisations-Systeme blicken, ist eine weitere Hürde. Dinge, die uns selbst völlig klar und logisch erscheinen, können für unsere Nutzer*innen völlig unklar sein.
Häufige Fehler in der Praxis sind haltlose Annahmen darüber, wie Nutzer*innen sich auf der eigenen Website verhalten würden. Die Balance zwischen eigener Kriterien (Erfahrung, Intuition, etc.) und fremder Kriterien (Studien, Nutzerumfragen, User-Tests, etc.) ist hierbei ein wesentlicher Faktor.
1.1. Organisations-Schemata
Organisations-Schemata begleiten uns tagtäglich durch unser Leben. Die Kontaktliste auf unserem Handy, die Anordnung von Produkten im Supermarkt oder die Notizen im Notizblock – alles das sind Beispiele für gewisse Organisations-Schemata. Es wird grundsätzlich zwischen folgenden Schemata unterschieden:

- Exakte Organisations-Schemata
- Alphabetisch (z.B. Kontakte auf dem Handy)
- Chronologisch (z.B. Notizen)
- Geographisch (z.B. Geolocations in GoogleMaps)
- Mehrdeutige Organisations-Schemata
- Thema (z.B. Supermarkt-Regale)
- Aufgabenorientiert (z.B. Playlists auf Spotify)
- Zielgruppen-spezifisch (z.B. B2B- & B2C-Bereich auf einer Website )
- Metaphorisch (z.B. Ordner, Papierkorb und Schreibtisch bei Microsoft Windows)
- Hybride Organisations-Schemata
- Hierbei handelt es sich um die Kombination zweier oder mehr unterschiedlicher Schemata

1.2. Organisations-Struktur
Die Struktur von Informationen weist den primären Weg auf, den Nutzer*innen nehmen um an die vorliegenden Informationen zu gelangen. Die Organisations-Strukturen eines Informationsarchitekten sind:
- Hierarchie
Hierarchien wurden in Teil 1 bereits thematisiert. Menschen neigen dazu in Hierarchien zu denken, weshalb das Verständnis dieser Struktur sehr leicht fällt.
Wichtig bei der Gestaltung einer Hierarchie ist, auf die Exklusivität der Kategorien zu achten, das heißt, dass ein und dasselbe „Item“ in so wenigen Kategorien wie möglich gleichzeitig vorkommen sollte. Das wiederholte Vorkommen von Items in unterschiedlichen Kategorien nennt sich Polyhierarchie. Polyhierarchien schwächen die Stabilität der Gesamt-Hierarchie.
Beispiel: Befindet sich ein Produkt an mehreren Orten im Geschäft, fällt es uns schwerer uns dies zu merken.
Des Weiteren ist es wichtig auf die Balance zwischen Breite und Tiefe der Hierarchie zu achten. Die Breite stellt die Anzahl der Kategorien pro Ebene dar, die Tiefe die Anzahl der Ebenen.
„Balance“ ist ein variabler Begriff. Die Millersche Zahl hat Antworten auf diese Frage. Sie besagt, dass das Kurzzeitgedächtnis des Menschen gleichzeitig nur 7 ± 2 Informationseinheiten präsent halten kann. - Datenbank-orientiert
Auf Datenbank-orientierte Strukturen möchte ich in diesem Artikel nicht weiter eingehen, da sie für die typische Arbeit mit Websites nicht in Frage kommt. - Hypertext
Hypertext besteht im Grunde aus zwei Bausteinen: Die Items bzw. Seiten (Unterseiten von Websites) und die Links, die zwischen diesen Seiten verlinken. Hierarchien in Websites helfen uns also im Hypertext-Chaos namens Internet nicht verloren zu gehen.

1.3. Soziale Klassifikation
In der Regel wird unter sozialer Klassifikation verstanden, dass Inhalte von Usern klassifiziert werden. Ein bekanntes Beispiel hierfür ist das Tagging in Social Media (bspw. auf Twitter). Sogenanntes „User generated content tagging“ kommt auch bei normalen Websites vor, allerdings stellt das unkontrollierte Erstellen von Tags häufig auch Probleme für Website-Betreiber dar.
Beispiel: In einem Nachrichten-Artikel erhalten „Coca-Cola“, „CocaCola“, „Cola“, und „Coke“ jeweils eigene Tags. Zu jedem Tag entsteht eine eigene Tag-Seite, ein klassischer Fall von Duplicate Content.
2. Labeling-Systeme
Labeling bzw. Beschriftung bezeichnet die Repräsentation einer gewissen Menge von Informationen. Sie kann als eine Art „Zusammenfassung eines Blocks von Informationen“ verstanden werden.
Im WWW kennen wir Labels von „Anker-Texten“ bei Links. Als Anker-Text bezeichnet man Link-Texte, auf die User klicken wenn sie zu einer speziellen Information gelangen möchten.
Beispiel: Dieser Anker-Text gibt dem User einen Eindruck davon, was hinter dem Link zu erwarten ist. Je präziser die Beschreibung, desto klarer ist die Vorstellung beim User. In diesem Fall ist die Wikipedia-Seite verlinkt, die Bedeutung und Verwendung von Anker-Texten im Detail erläutert.
Labeling-Systeme werden von unterschiedlichsten Rollen im Unternehmen verantwortet.
Beispiel: Das Labeln von Links in Artikeln übernehmen in der Regel Texter*innen oder Redakteur*innen. Die Labels einer globalen Navigation werden häufig von Produktmanager*in festgelegt.
Es gibt nicht diese eine Anleitung für ein gelungenes Labeling-System, da es unter anderem auch von personellen Verantwortlichkeiten im Unternehmen abhängt. Es ist jedoch so, dass erfolgreiche Labeling-Systeme mindestens eine Eigenschaft gemeinsam haben: Konsistenz.
Konsistentes Labeling hilft Nutzer*innen und Suchmaschinen die Informationen besser, einfacher und eindeutiger zu erfassen.
3. Navigations-Systeme
Wie der Name bereits vermuten lässt, „leiten“ uns Navigations-Systeme zu einer entsprechenden Information. Vor allem für Websites kann ein gut strukturiertes Navigations System erfolgsentscheidend sein.
Structure and organization is about building rooms. Navigation design is about adding doors and windows
Information Architecture for the Web and beyond (4th Edition) S. 176
Aufgrund der sich rasant verändernden Bedingungen für User Interfaces – bspw. die unterschiedlichen Display-Größen von Notebooks, Tablets und Smartphones – verändern sich auch die Anforderungen für Navigations-Systeme.
Beim Entwurf von Navigations-Systemen befinden wir uns bereits in fachübergreifenden Disziplinen aus Informationsarchitektur, Interaktionsdesign, Informationsdesign, Visual Design und Usability Engineering.
Es gibt grundsätzlich drei Formen bzw. Basis-Elemente von Navigations-Systemen: Globale, Lokale und Kontext-Abhängige Navigations-Systeme.
Alle drei sollen Nutzer*innen dabei helfen
A) zu verstehen wo sie sich aktuell befinden und
B) wohin sie von dort aus gelangen können.
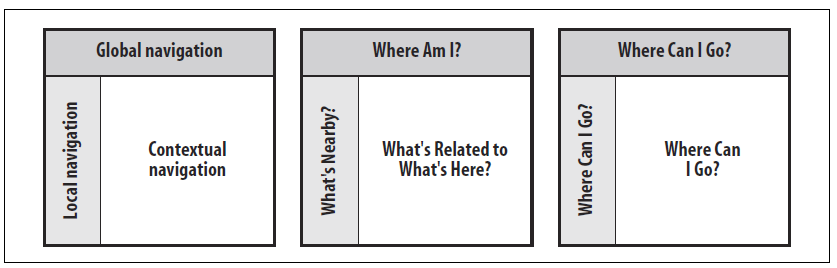
Globale Navigations-Systeme sind dadurch definiert, dass sie auf jeder Unterseite einer Website aufzufinden sind. Sie ermöglichen den Zugang zu den wichtigsten Bereichen und Funktionen einer Website, unabhängig davon auf welcher Hierarchie-Stufe sich der User befindet.
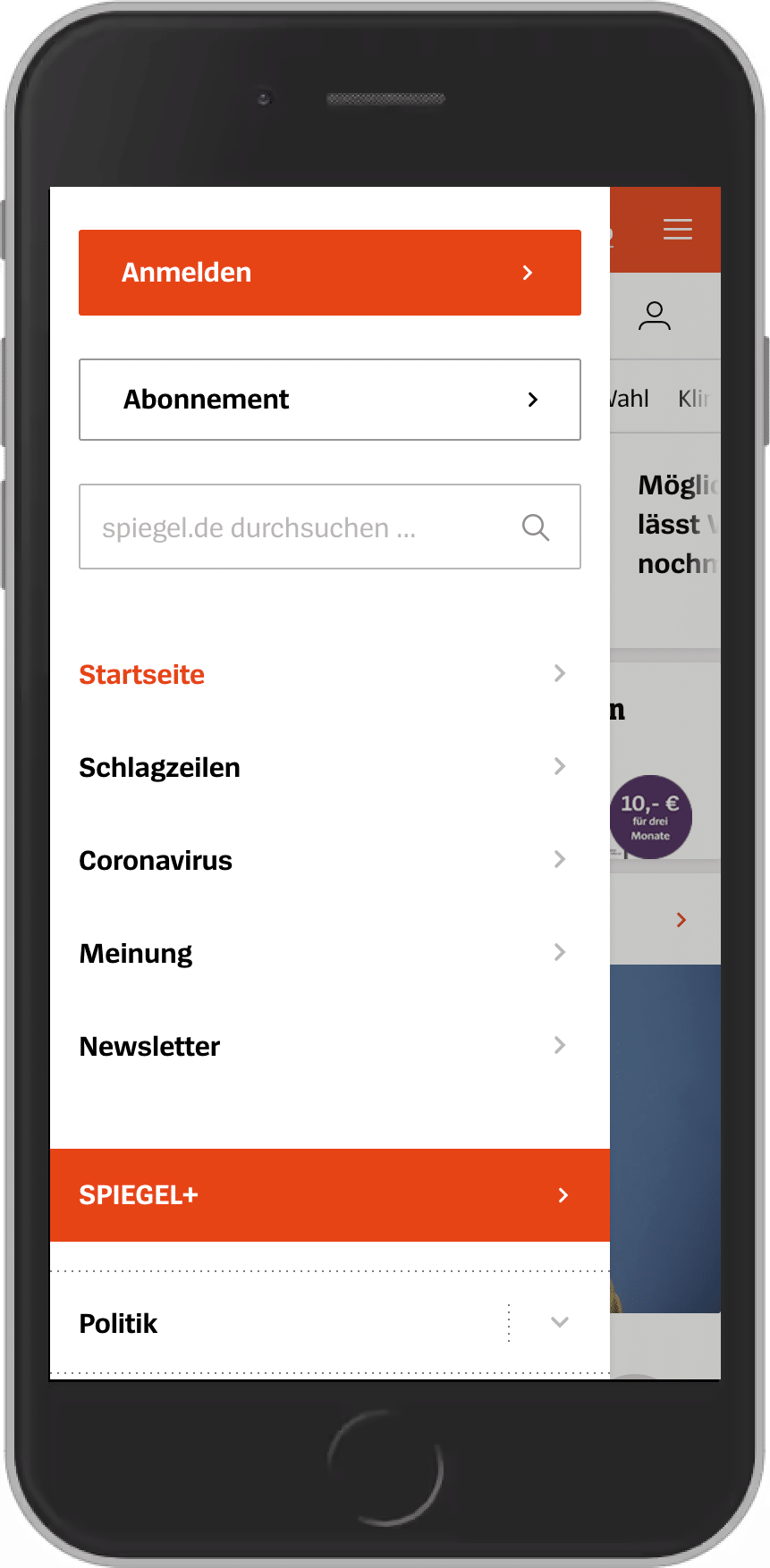
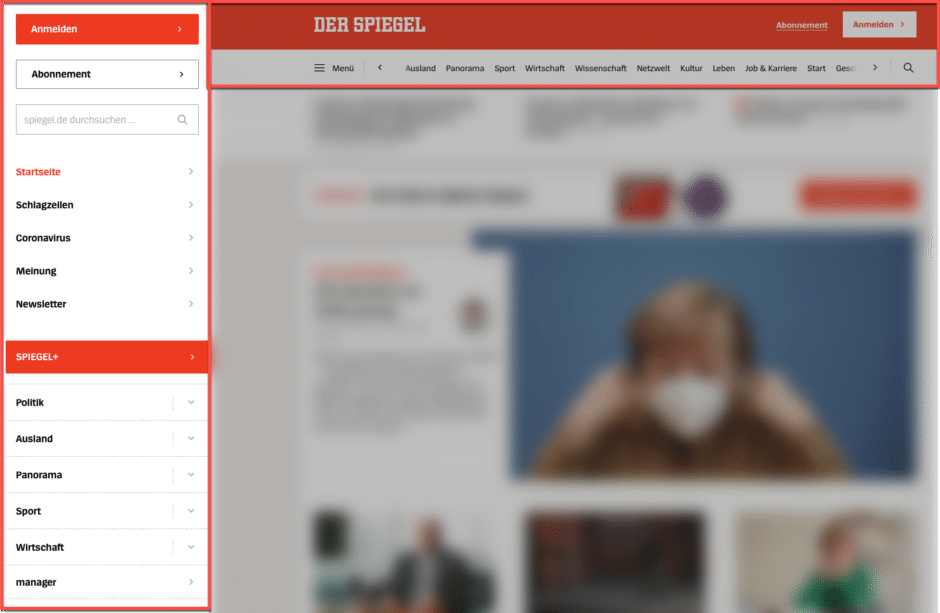
Lokale Navigations-Systeme sind abhängig von der Seite, auf der sich der User befindet. Dabei wird versucht dem User die möglichen Wege innerhalb eines bestimmten Bereichs aufzuzeigen.
Beispiel: Im SEO wird diese Technik als Siloing bezeichnet. Die alt bekannte rechte Randspalte hat in der Vergangenheit häufig als eine solche lokale Navigation gedient. Sie hat es in die heutige, mobile, Welt nicht geschafft.
In der Praxis werden Lokale Navigations-Systeme häufig ergänzend und in Kombination zur globalen Navigation verwendet.


Als Kontext-Abhängige Navigations-Systeme bezeichnet man in der Regel Bereiche, die wir bspw. in Online-Shops als „Nutzer kauften auch“ oder „ähnliche Artikel“ kennen. Auch redaktionell platzierte Links innerhalb eines Textes zählen hierzu.

Des Weiteren gibt es sog. ergänzende Navigations-Systeme (supplemental navigation systems) wie z.B. Sitemaps, Indizes oder Guides (Tutorials, etc.). Sie ermöglichen, neben den Basis-Elementen, weitere Wege, um an eine gewünschte Information zu gelangen.


4. Such-Systeme


Such-Systeme bieten Nutzer*innen mittels einer Eingabe die Möglichkeit an eine gewünschte Information zu gelangen. Sie gehören in der Regel zur globalen Navigation und werden mit einem Lupen Symbol dargestellt. In der Praxis wird die interne Suche leider häufig stark vernachlässigt, obwohl sie eine enorme Relevanz für Nutzer*innen hat. Ein Grund für ihre Vernachlässigung könnte die Komplexität sein, die mit einem gut funktionierenden Such-System, einhergeht.
Eine interne Suche muss die Voraussetzung erfüllen Nutzer*innen und deren Bedürfnissen bestmöglich gerecht zu werden. Vernachlässigte Such-Systeme tragen schnell zur Verwirrung und Frustration von Nutzer*innen bei. Sie schaden dann der User Experience und sorgen für eine negative Gesamterfahrung.
Simon Streich
Teil 4: IA-Projekte durchführen
Die Durchführung von Informationsarchitektur-Projekten betrifft nahezu jede Abteilung und jedes Team innerhalb einer Organisation. Nicht zuletzt deshalb ist Projektmanagement bzw. das Stakeholder-Management ein wesentlicher Faktor für den Erfolg eines solchen Projekts.
Ebenfalls entscheidend ist das Vorhandensein einer Unternehmenskultur, die Veränderungen zulässt. Aufgrund der Größe und Tragweite solcher Projekte ist es unmöglich ein IA-Projekt einfach Top-Down zu diktieren.
1. Vorbereitung
In den meisten Fällen beginnt ein IA-Projekt nicht auf der grünen Wiese. Stattdessen muss in der Regel ein bestehendes Konzept/System überarbeitet werden. Dieser Abschnitt soll also den Ablauf eines IA-Projekts skizzieren, welches im laufenden Betrieb einer Unternehmung stattfindet.
Das Verständnis für folgende Themen ist vorab notwendig:
- Markt- und Wettbewerbsbedingungen
- Customer- und User-Journeys
- (Buyer-)Personas
- Unternehmensziele und strategische Ausrichtung
- Prozessabläufe
- Eigenschaften zur Unternehmenskultur und -politik
- Historisches Wissen
- Verantwortlichkeiten bzw. Rollenprofile
Um während des Projekts den Überblick zu behalten, bieten sich sogenannte Sitemaps als visuelles Instrument an. Diese können bspw. mittels eines Crawls der Website hergeleitet werden.
Eine solche Übersicht könnte wie folgt aussehen:

2. Durchführung
Eine IST- bzw. Zustands-Analyse ist dann die Basis für ein IA-Projekt. Diese Analyse kann in die folgenden drei Bestandteile aufgeteilt werden:
1. Verständnis für Merkmale der Items entwickeln
Zu Beginn sollten die einzelnen Items bzw. Seiten im Detail betrachtet und geprüft werden. Welche Merkmale sind für das jeweilige Item entscheidend?
Beispiel: Auf einer Nachrichten-Seite ist das Item ein Artikel. Autor, Veröffentlichungs-Datum, Thema/Resort, Format, etc. sind mögliche gemeinsame Merkmale.
Im E-Commerce hingegen stellt das Item ein Produkt dar und die entscheidenden Merkmale sind dann Produkt-Kategorie, Preis, Produkt-Eigenschaft (Farbe, Größe, Anzahl, Maße), etc.

2. Organisations-Struktur verstehen
Im zweiten Schritt schauen wir uns die Struktur an, mit der die Items in den Gesamt-Kontext eingebettet sind. In den meisten Fällen handelt es sich hier um eine hierarchische Struktur. Ein Online-Shop ist bspw. so aufgebaut, dass eine Startseite auf diverse Kategorien verweist, welche dann entsprechende Produkte listen, die sich innerhalb dieser Kategorien befinden.

3. Organisations-Schemata herausarbeiten
Im letzten Schritt wird Schemata betrachtet, mit dem das System bzw. die einzelnen Bereiche aufgebaut sind. Nachrichten-Seiten verwenden für ihre Resorts/Kategorien häufig ein chronologisches Schemata, da Nutzer*innen die neusten Artikel zum Beginn der Seite erwarten.

Beispiel: Ein weiteres, besonderes, Beispiel für Schemata liefert Amazon. Auf den Kategorie-Seiten werden die Produkte (bzw. Items) nach „Amazon präsentiert“ sortiert, d.h. Amazon hat hier ein eigenes Schemata kreiert, welches sich wahrscheinlich an verschiedenen Merkmalen wie z.B. Bewertung, Marge, Marke, Verkaufte Artikel, etc. orientiert. Dadurch ist das Unternehmen in der Lage eine völlig eigene Sortierung der Artikel vorzunehmen.


Im Anschluss an die IST-Analyse erfolgt die SOLL-Analyse. Hier werden die selben Schritte nochmals durchgeführt. Dabei müssen u.a. folgende Fragen beantwortet werden:
- Sind alle Merkmale vorhanden und ausreichend beschrieben?
Gibt es passendere Merkmale als die aktuellen? Fehlen gewisse Merkmale? - Ist die Organisations-Struktur sinnvoll gewählt?
Gibt es eine passendere Struktur? - Ist das Organisations-Schemata sinnvoll gewählt?
Gibt es Seiten-Bereiche, die unterschiedliche Schemata benötigen?
Was sind die neuen technischen Voraussetzungen für eine Änderung eines Schemata?
Beispiele:
- Ein chronologisches Schemata für Resorts bei Nachrichten-Seiten mag zwar insgesamt sinnvoll sein, jedoch wäre es für Nutzer*innen möglicherweise auch interessant, die meist gelesenen oder die laut Chefredakteur*in wichtigsten Artikel zusätzlich empfohlen zu bekommen. In vielen Fällen erhöht man mit einem solchen hybriden Modell die Wahrscheinlichkeit das Bedürfnis der Nutzer*in zu treffen.
- Stellen wir uns vor: In einer fiktiven E-Commerce-Kategorie „Haus & Garten“ werden tausende Produkte gelistet. Für jemanden, der einen Gartenschlauch sucht, sind alle Produkte, die zu „Haus“ gehören uninteressant, was die Suche nach dem passenden Produkt erschwert. Je nachdem, ob das gesamte System eine feinere Granularität zulässt (Stichwort „breite“ und „tiefe“ der hierarchischen Struktur“) wäre hier möglicherweise eine Aufsplittung in separate Kategorien „Haus“ und „Garten“ sinnvoll.
Ein wesentlicher Teil der Informations-Architektur für eine Website ist die URL. Sie gibt an, wie die Koordinaten einer Landkarte, an welchem Ort sich eine gewünschte Information befindet. Nicht zuletzt aufgrund technischer Rahmenbedingungen sollte hierauf ein besonderes Augenmerk gelegt werden. Je nach Content-Management-System können die technischen Möglichkeiten hier stark limitiert sein.
Beispiel: Ein Produkt wird zwei unterschiedlichen Kategorien zugeordnet und ist aufgrund dessen auch mittels zwei unterschiedlicher URLs auffindbar. Dies beschreibt die selbe Problematik, wie wenn ein Produkt in zwei unterschiedlichen Regalen im Supermarkt liegt. Ein*e Mitarbeiter*in wird aufgrund dieser Uneindeutigkeit möglicherweise Schwierigkeiten haben dem Kunden zu erklären wo das Produkt zu finden ist. Wenn Vorräte aus dem Lager aufgefüllt werden müssen, muss dies immer an zwei Stellen passieren, etc.
Achten Sie im IA-Prozess auf die URL-Struktur. Sie sollte einerseits immer zu Ihren Anforderungen passen und andererseits müssen all Ihre Systeme sauber damit umgehen können.
Simon Streich
Teil 5: Schlusswort
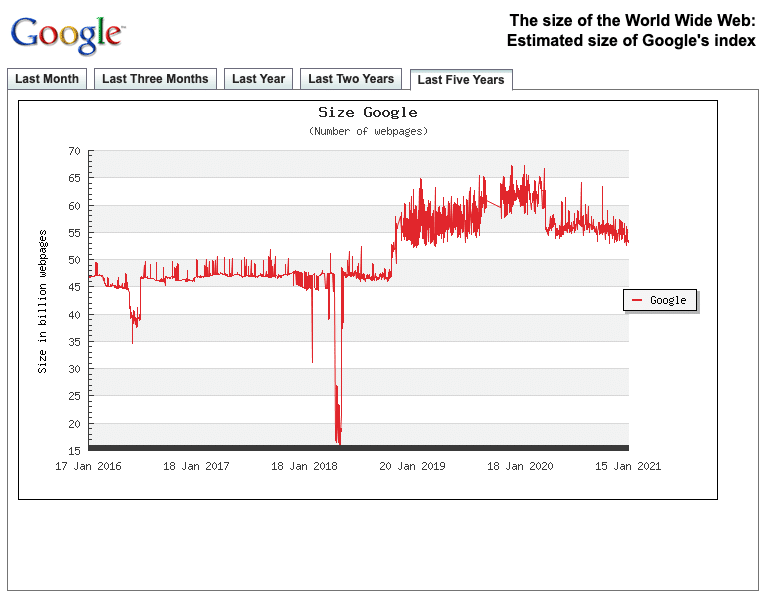
Sowohl das WWW als auch die Indizes von Suchmaschinen wachsen stetig. Ständig neue Möglichkeiten und Web-Technologien machen das WWW zu einem lebendigen Organismus.
Die dort vorhandenen Informationen gut erreich- und auffindbar zu machen wird auch in Zukunft eine wichtige Rolle spielen und die Disziplin der Informationsarchitektur kann uns dabei unterstützen.
Abonniere das kostenlose KI-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen aus den Bereichen Künstliche Intelligenz für dein Online Business, WordPress, SEO, Online-Marketing und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.




