
In der SEO- und Marketing-Bubble geistert gerade eine gewaltige Zahl durch die Feeds: 1,2 Millionen. So viele Suchergebnisse hat Kevin Indig in seiner viel beachteten Studie „The Science of How AI Pays Attention“ analysiert. Sein Ziel: Endlich das Geheimnis zu lüften, worauf KI-Suchmaschinen wie Google AI Overviews, Perplexity oder SearchGPT eigentlich achten, wenn sie Antworten generieren.
Das zentrale Ergebnis klingt revolutionär und banal zugleich: KIs sind faul. Sie leiden unter einem massiven „Attention Decay“. Was nicht ganz oben im Text steht, existiert für die Maschine oft gar nicht.
Aber stimmt das wirklich? Ist das ein technisches Limit der großen Sprachmodelle (LLMs), oder messen wir hier nur menschliche Gewohnheiten? Und vor allem: Wie belastbar ist diese „Big Data“-Analyse eigentlich für unsere tägliche Arbeit?
Als jemand, der sich tief in die Wissenschaft, LLMs und Generative Engine Optimization (GEO) eingegraben hat, habe ich mir die Studie methodisch sehr genau angesehen. Lass uns gemeinsam die „Statistik-Zwiebel“ schälen, die akademische Beweislage prüfen und schauen, was am Ende wirklich an Gold für deine Content-Strategie übrig bleibt:
Die Statistik-Zwiebel: Was bedeuten „1,2 Millionen“ wirklich?
Bevor wir Ergebnisse blind übernehmen, müssen wir die Datenbasis verstehen. In der heutigen „Headline-Ökonomie“ wirken große Zahlen wie Autoritäts-Booster. „1,2 Millionen analysierte Ergebnisse“ suggeriert eine lückenlose Vermessung des Internets, die keinen Raum für Zufälle lässt.
Doch wissenschaftlich betrachtet müssen wir differenzieren. Man muss sich die Datenbasis wie eine Zwiebel oder einen Trichter vorstellen, der nach unten hin immer enger wird:
- Der Top of Funnel (Die Basis): Ja, es wurden 1,2 Millionen Keywords (SERPs) überwacht. Das ist das Spielfeld. Aber hier liegt bereits der erste „Selection Bias“: Die Keywords waren stark kommerziell geprägt (z.B. „Best CRM Software“). Informationsorientierte Nischen-Themen sind unterrepräsentiert.
- Der erste Filter (AI-Trigger): Nicht jede Suche löst eine AI-Antwort aus. Die Verbreitung von AI Overviews schwankt massiv. Wir betrachten also nur die Teilmenge, bei der Google überhaupt eine Antwort generiert hat.
- Die Extraktion (Zitate): Jede AI-Antwort enthält Quellen. Diese müssen extrahiert werden.
- Das Matching (Der kritische Kern): Um zu prüfen, wo im Text eine Information stand, muss die Studie den zitierten Satz exakt im Quellcode der Webseite wiederfinden. Hier schrumpft die Datenbasis von der Million auf einen Bereich von ca. 18.000 bis 50.000 verifizierten Datenpunkten.
Zwischenfazit: Die Stichprobe ist immer noch groß genug, um statistisch signifikant zu sein – sie ist weit besser als bloßes Bauchgefühl. Aber sie ist kein absolutes Naturgesetz. Wir sollten die Ergebnisse als starke Heuristik (Faustregel) betrachten, aber immer im Hinterkopf behalten, dass hier primär „Review-Content“ analysiert wurde! Eine Übertragung auf andere Content-Typen ist zumindest fraglich!
Der „Front-Loading“-Effekt: Ein klassisches Henne-Ei-Problem
Das wichtigste Chart der Studie ist visuell eindeutig: 44,2 % aller Zitate stammen aus den ersten 30 % des Contents. Danach fällt die Kurve steil ab. Indig nennt das treffend den „Busy Editor“-Effekt: Die KI liest wie ein gestresster Chefredakteur – ein schneller Scan des Intros, die wichtigsten Fakten werden mitgenommen, der Rest wird ignoriert.
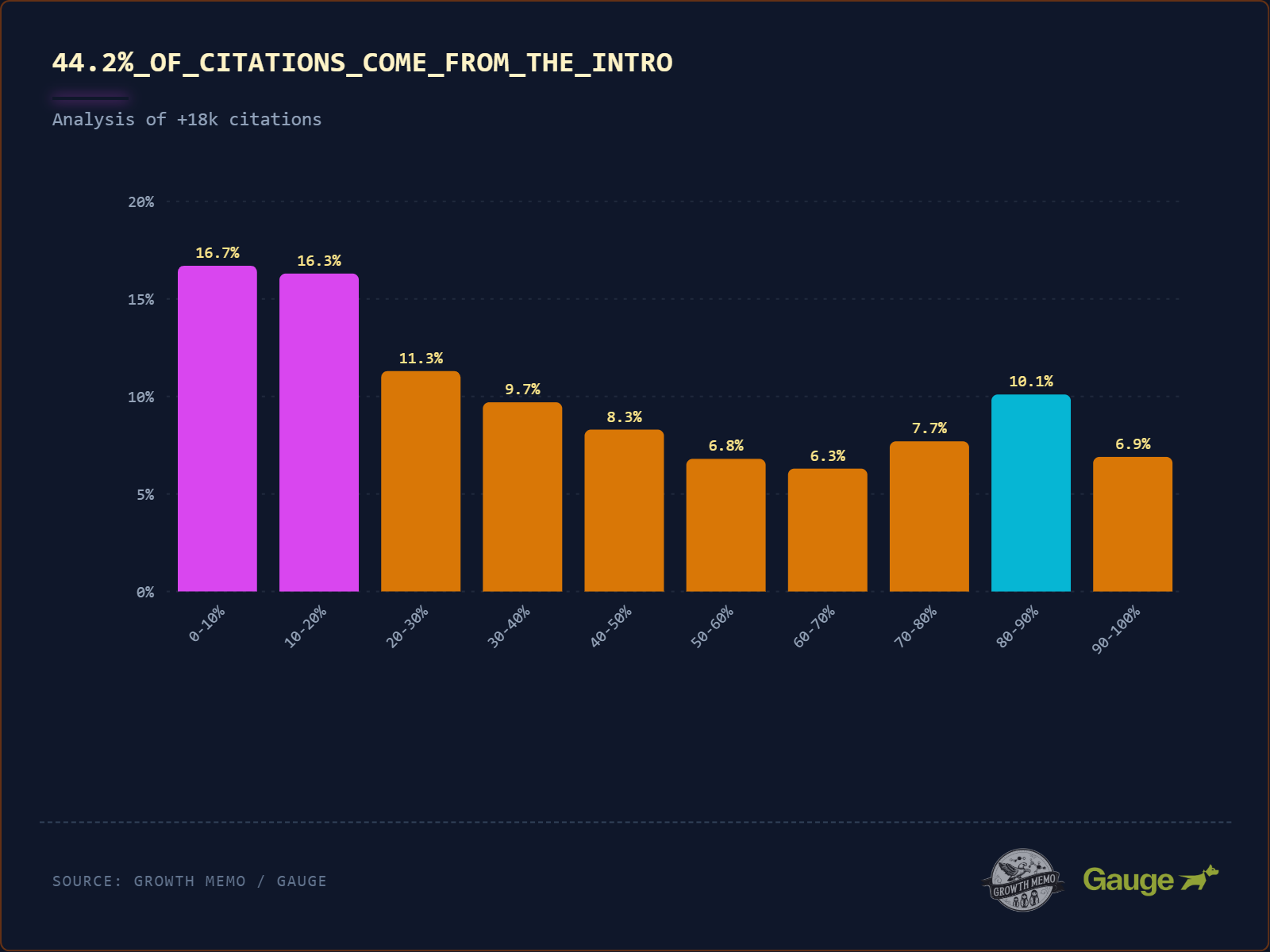
Hier müssen wir jedoch methodisch kritisch einhaken. Die Studie zeigt eine Korrelation, keine Kausalität.
- Die These der Studie: Die KI bevorzugt technisch den Anfang (Attention Bias).
- Der Gegenentwurf (Nullhypothese): Gute Autoren schreiben seit 100 Jahren nach dem Prinzip der „Umgekehrten Pyramide“.
Jeder Journalist lernt am ersten Tag: Das Wichtigste (die News, das Fazit, die Antwort) gehört nach oben – „Above the Fold“. Wenn also 90 % der relevanten Fakten im Internet zufällig im ersten Drittel stehen, dann muss die KI sie dort finden, um die Frage korrekt zu beantworten.
Sprich: Messen wir hier also einen Bias der Maschine oder einfach nur den Qualitätsstandard guter Autoren? Die Studie selbst kann das aufgrund ihres Designs (Beobachtung von Live-Daten statt Labor-Experiment) nicht auflösen.
Die wissenschaftliche Evidenz: Warum Indig trotzdem recht hat
Müssen wir die Studie also verwerfen? Nein. Denn auch wenn Indigs Design die Ursache nicht isolieren kann, gibt es harte wissenschaftliche Rückendeckung für die „Front-Loading“-These aus der Computerwissenschaft.
Die berühmte Studie „Lost in the Middle“ von Liu et al. beweist das Phänomen unter Laborbedingungen. Die Forscher zeigten, dass LLMs (wie GPT-4 oder Claude) eine U-förmige Aufmerksamkeitskurve haben:
- Primacy Effect: Informationen ganz am Anfang des Kontext-Fensters werden exzellent verarbeitet.
- Recency Effect: Informationen ganz am Ende ebenfalls.
- The Valley of Death: Informationen in der Mitte eines langen Kontextes werden signifikant häufiger „vergessen“ oder halluziniert.
Dazu kommt ein technischer Aspekt der RAG-Systeme (Retrieval Augmented Generation): Um Kosten und Rechenleistung zu sparen, lesen Crawler oft nicht die gesamte Seite, sondern setzen ein Token-Limit. Da wir als SEOs nie wissen, wann der Crawler „abschneidet“ (Cut-off), ist das Ende einer Seite ein unsicherer Ort. Der Anfang bleibt der einzige sichere Hafen für deine Kernbotschaften.
Die 5 Gewinnermerkmale der KI-Suche (und ihr Faktencheck)
Neben der Positionierung hat die Studie fünf spezifische textliche Eigenschaften identifiziert, die Gewinner-Inhalte gemeinsam haben. Doch auch hier gilt: Nicht blind optimieren! Lass uns jeden Punkt mit der gleichen methodischen Strenge behandeln wie das Front-Loading.
A. Definitive Language (Klartext statt Konjunktiv)
Was die Studie sagt: Zitierte Texte enthalten fast doppelt so häufig definitive Sprache wie nicht-zitierte (36,2 % vs. 20,2 %). Gemeint sind klare „X ist Y“-Strukturen mit Verben wie „is defined as“ oder „refers to“.
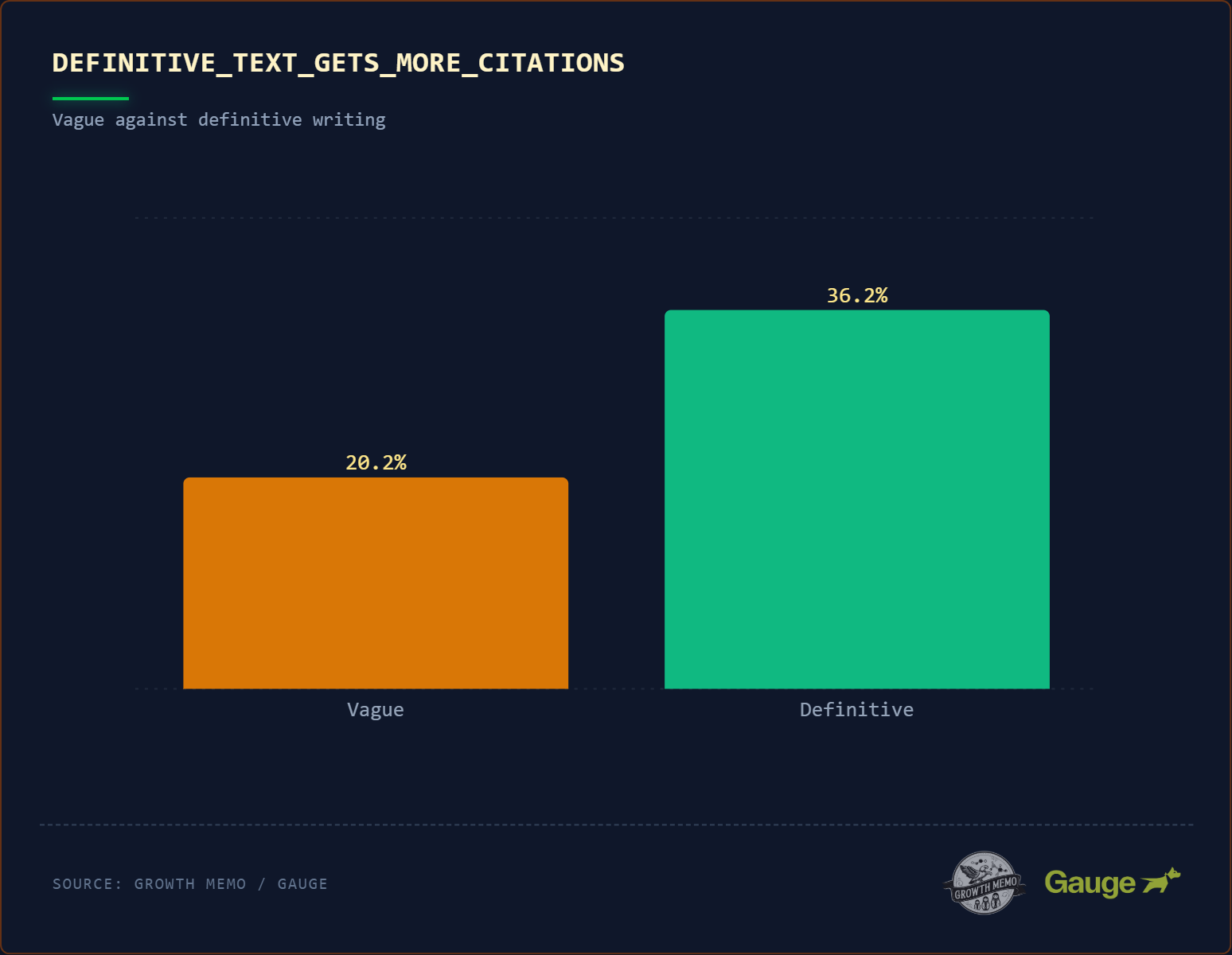
Die methodische Einordnung: Die Erklärung der Studie klingt technisch elegant: In einer Vektor-Datenbank fungiere das Wort „ist“ als starke semantische Brücke zwischen Subjekt und Definition. Wenn ein Nutzer fragt „Was ist X?“, suche das Modell den kürzesten Vektorpfad – und der führe fast immer zu einem direkten „X ist Y“-Satz.
Das ist im Kern korrekt, aber die Kausalität ist komplizierter als die Studie es darstellt. Was wir hier beobachten, ist kein mysteriöser „Preference Bias“ der KI für Klartext. Es ist ein Artefakt der Architektur.
LLMs operieren auf Basis eines Attention-Mechanismus (Vaswani et al., 2017, „Attention Is All You Need“). Dieser Mechanismus berechnet die Beziehungsstärke zwischen Token-Paaren im Kontext. Ein Satz wie „Demo-Automatisierung ist der Prozess der Nutzung von Software zur…“ erzeugt in der Attention-Matrix einen extrem starken, gerichteten Pfad vom Subjekt zum Prädikat. Ein Satz wie „In unserer schnelllebigen Welt wird Automatisierung immer wichtiger…“ verteilt die Attention-Gewichte diffus auf irrelevante Füllwörter – die eigentliche Relation ertrinkt im Rauschen.
Das Phänomen lässt sich auch über das Konzept der Perplexität erklären: Definitive Sätze sind für das Modell vorhersagbarer (niedrigere Perplexität), weil die „X ist Y“-Struktur eines der häufigsten Muster in den Trainingsdaten ist. Schwammige Formulierungen erhöhen die Perplexität, was das Modell als Signal für geringere Informationsqualität interpretiert.
Aber Vorsicht – der YMYL-Vorbehalt: In Nischen wie Medizin, Recht oder Finanzen kann ein „X ist Y“-Absolutismus gefährlich werden. Wenn ein medizinischer Text behauptet „Vitamin D heilt Depressionen“ statt „Studien zeigen einen Zusammenhang zwischen Vitamin-D-Mangel und depressiven Symptomen“, dann gewinnt er vielleicht das Zitat – aber verliert die fachliche Seriosität. Googles Quality-Rater-Guidelines bewerten übermäßige Vereinfachung in YMYL-Bereichen explizit negativ! Die Empfehlung „Schreib definitiv“ ist also kein Universalgesetz, sondern gilt primär für die untersuchte Stichprobe kommerzieller Ratgeber-Queries.
Das Fazit für deine Praxis: Beantworte die Kernfrage in deinem ersten Satz mit einer klaren „X ist Y“-Struktur. Aber verwechsle „definitiv“ nicht mit „vereinfacht“. Präzision schlägt Vagheit – aber erfundene Gewissheit schlägt zurück.
B. Conversational Question-Answer Structure (Q&A-Format)
Was die Studie sagt: Zitierte Texte enthalten doppelt so häufig Fragezeichen wie nicht-zitierte (18 % vs. 8,9 %). Noch wichtiger: 78,4 % dieser Fragen stehen in Überschriften (H2-Tags). Die KI behandelt die Überschrift als User-Prompt und den folgenden Absatz als generierte Antwort.
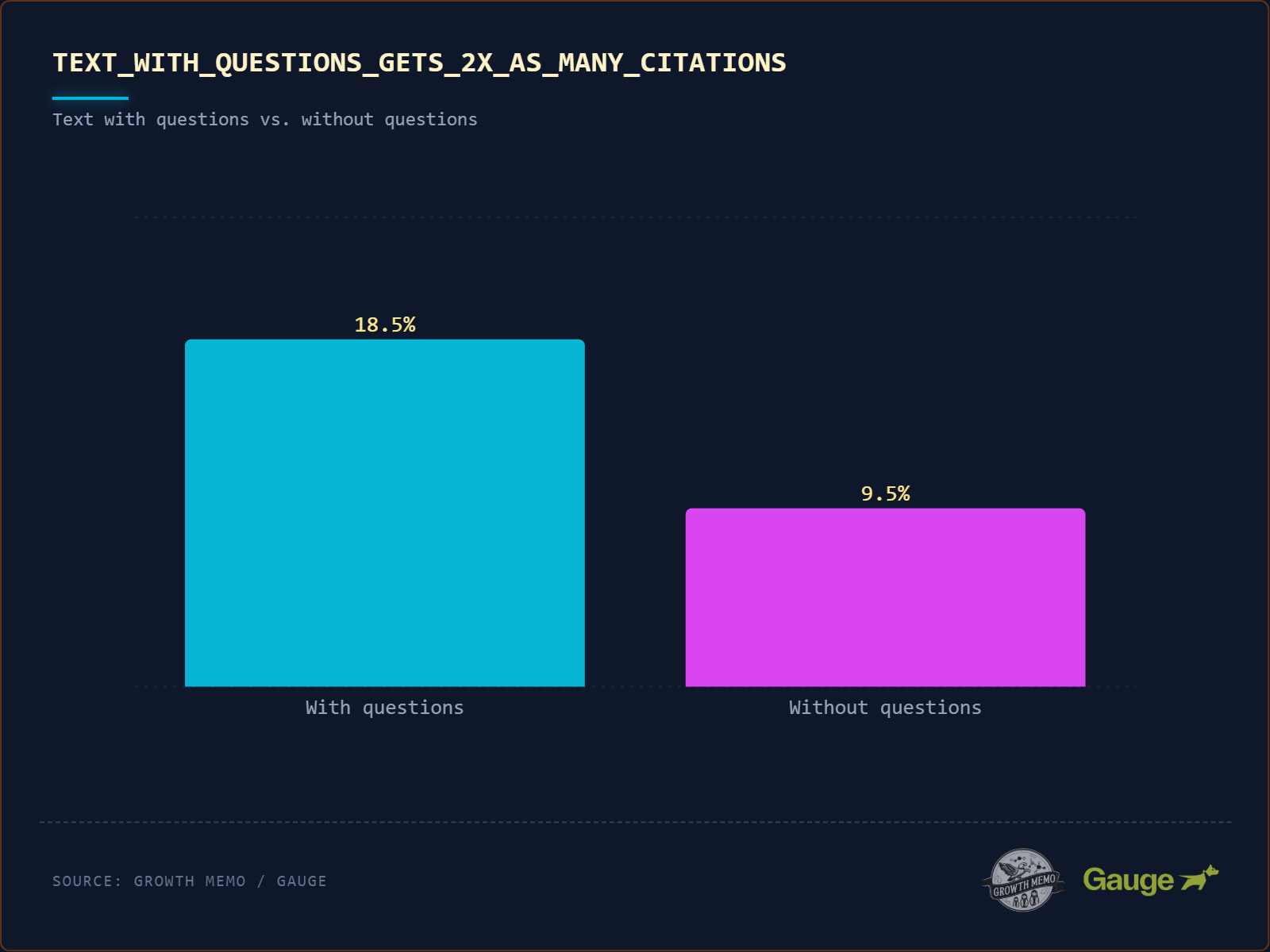
Die methodische Einordnung: Von allen fünf Ergebnissen hat dieses die stärkste kausale Begründung – und zwar direkt aus der Architektur moderner LLMs.
Der Grund liegt im sogenannten „Instruction Tuning“ (auch „RLHF“ – Reinforcement Learning from Human Feedback, Ouyang et al., 2022). Jedes moderne LLM durchläuft nach dem Pretraining eine Feinabstimmungsphase, in der es auf Millionen von Frage-Antwort-Paaren trainiert wird. Das innere Format ist dabei immer identisch: User: [Frage] → Assistant: [Antwort]. Dieses Schema ist so tief im Modell verankert, dass es quasi die „Muttersprache“ jedes LLMs darstellt.
Wenn du nun eine H2-Überschrift als Frage formulierst und im ersten Satz darunter direkt antwortest, dann replizierst du exakt das Format, auf das das Modell optimiert ist. Die Studie beschreibt dafür den treffenden Mechanismus des „Entity Echoing“: Wenn die Überschrift nach „SEO“ fragt und das erste Wort der Antwort „SEO“ ist, erzeugt das im Attention-Mechanismus einen direkten Rückbezug, der die Relevanz des Absatzes für die Frage maximiert.
Das ist auch aus der Information-Retrieval-Forschung gut belegt. BM25, der klassische Ranking-Algorithmus, bewertet Term-Frequenz und inverse Dokumentfrequenz. Neuere Dense-Retrieval-Modelle arbeiten ähnlich: Ein Passage wird als relevant für eine Query eingestuft, wenn die semantische Überlappung im Embedding-Raum hoch ist. Eine Frage-Überschrift, die das Query exakt spiegelt, erzeugt maximale Überlappung.
Warum das Ergebnis trotzdem nicht universell ist: Die 78,4 % gelten für die untersuchte Stichprobe kommerzieller Queries. Für narrative Formate (Longform-Reportagen, wissenschaftliche Abhandlungen) ist eine reine Q&A-Struktur weder üblich noch sinnvoll. Die Studie misst, was KI-Suchmaschinen für informationssuchende Queries zitieren – nicht, was generell den „besten“ Content ausmacht.
Das Fazit für deine Praxis: Formuliere deine H2-Überschriften als exakte User-Fragen. Beginne den ersten Satz darunter mit einer direkten Antwort, die die Schlüssel-Entität aus der Frage wiederholt. Das ist kein Hack – es ist die strukturelle Sprache, die LLMs am besten verstehen.
C. Entity Richness (Faktendichte)
Was die Studie sagt: Normaler englischer Text hat eine „Entitätsdichte“ (Anteil von Eigennamen wie Marken, Tools, Personen) von ca. 5–8 %. Häufig zitierter Text liegt bei 20,6 % – fast dem Vierfachen.
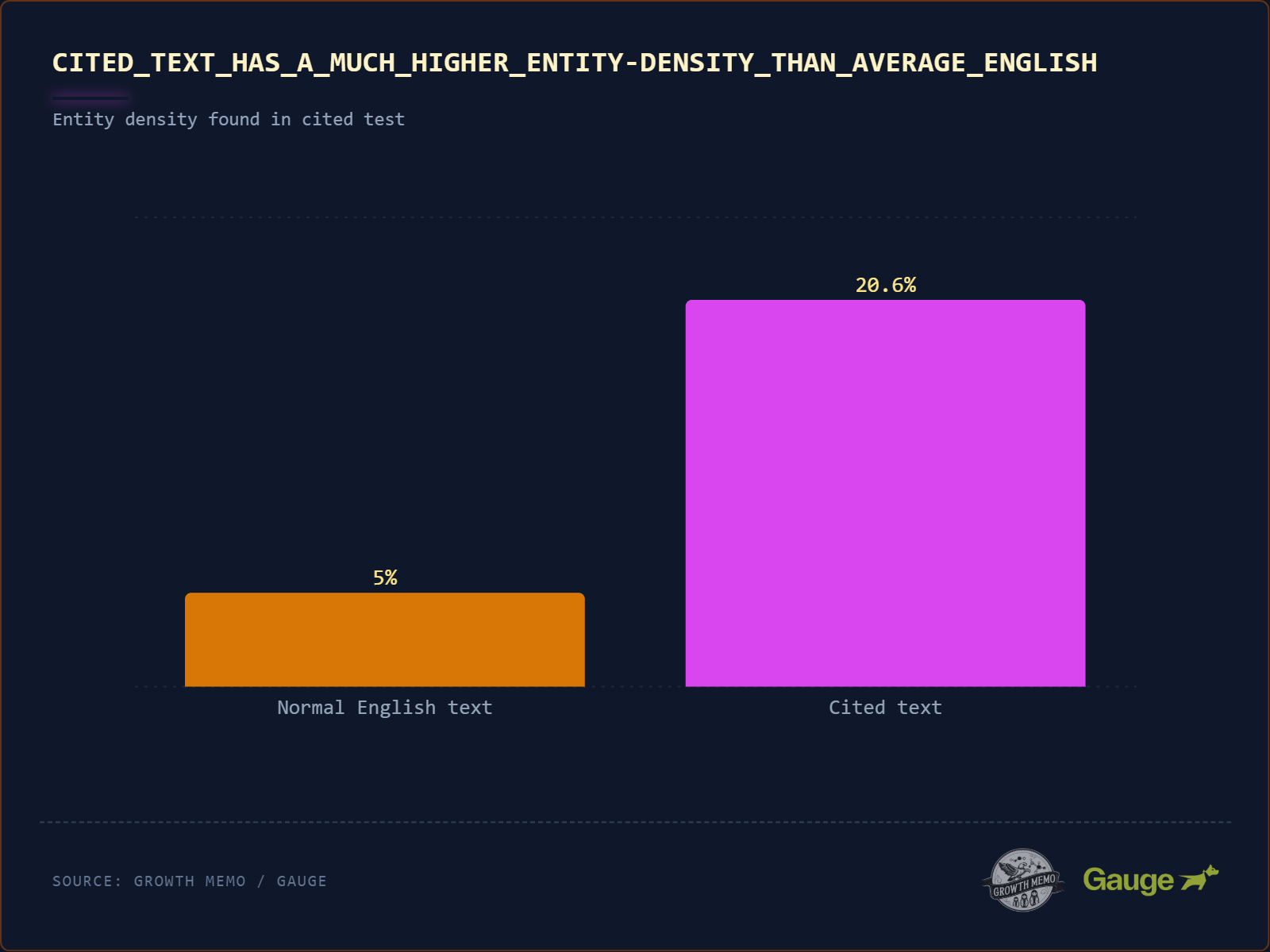
Die methodische Einordnung: Die Referenzwerte von 5–8 % stammen laut Studie aus linguistischen Standard-Korpora wie dem Brown Corpus und dem Penn Treebank. Das ist eine solide Benchmark für „durchschnittliches Englisch“. Der Sprung auf 20,6 % ist beeindruckend – aber methodisch liegt hier ein klassischer Zirkelschluss vor, den die Studie nicht adressiert.
Das Problem: Die untersuchten Suchanfragen sind überwiegend kommerziell und entitätsbezogen. „Best CRM Software“ verlangt nach Antworten, die Salesforce, HubSpot und Pipedrive nennen. Ein Text, der diese Frage beantwortet, ohne Entitäten zu nennen, wäre schlicht eine schlechte Antwort. Die hohe Entitätsdichte der „Winner“ ist also kein KI-Bias, sondern eine Mindestanforderung an inhaltliche Relevanz für diese Art von Queries.
Wissenschaftlich lässt sich das über das Konzept des „Information Gain“ einordnen. In der Information-Retrieval-Theorie wird ein Dokument als relevanter eingestuft, wenn es mehr neue, konkrete Information liefert als konkurrierende Dokumente. Entitäten sind dabei die effizientesten Informationsträger: Der Satz „Das Gerät ist schnell“ enthält nahezu null Information Gain. Der Satz „Der Apple M2-Chip verarbeitet 15,8 Billionen Operationen pro Sekunde“ trägt drei Entitäten (Apple, M2, Operationen/Sekunde) und einen konkreten Datenpunkt. Für ein Sprachmodell bedeutet mehr Entitäten pro Satz weniger Perplexität bei der Antwortgenerierung – die Aussage ist „verankert“ und verifizierbar.
Das Gegenargument: Die 20,6 % sind kein Zielwert zum Reverse-Engineeren. Wenn du künstlich Markennamen in einen Text stopfst, der sie nicht braucht, verschlechterst du die Lesbarkeit, ohne Relevanz zu gewinnen. Entitäten sind kein Stilmittel, sondern ein Indikator für Informationsdichte. Der Unterschied ist entscheidend!
Das Fazit für deine Praxis: Ersetze generische Formulierungen durch konkrete Entitäten – Markennamen, Produktbezeichnungen, Kennzahlen, Personennamen. Aber tu das nicht als Keyword-Stuffing, sondern weil es deinen Text faktisch besser macht. Und ja: Nenne ruhig auch Wettbewerber. Ein Vergleich „Salesforce vs. HubSpot vs. Pipedrive“ ist für die KI informativer als „verschiedene Tools im Vergleich“.
D. Balanced Sentiment (Die „Analysten-Stimme“)
Was die Studie sagt: Zitierte Texte haben einen durchschnittlichen Subjectivity Score von 0,47 auf einer Skala von 0,0 (rein objektiv) bis 1,0 (rein subjektiv). Die KI will weder trockenen Wikipedia-Stil (0,1) noch ungefilterte Meinung (0,9), sondern eine Art „Analysten-Stimme“.
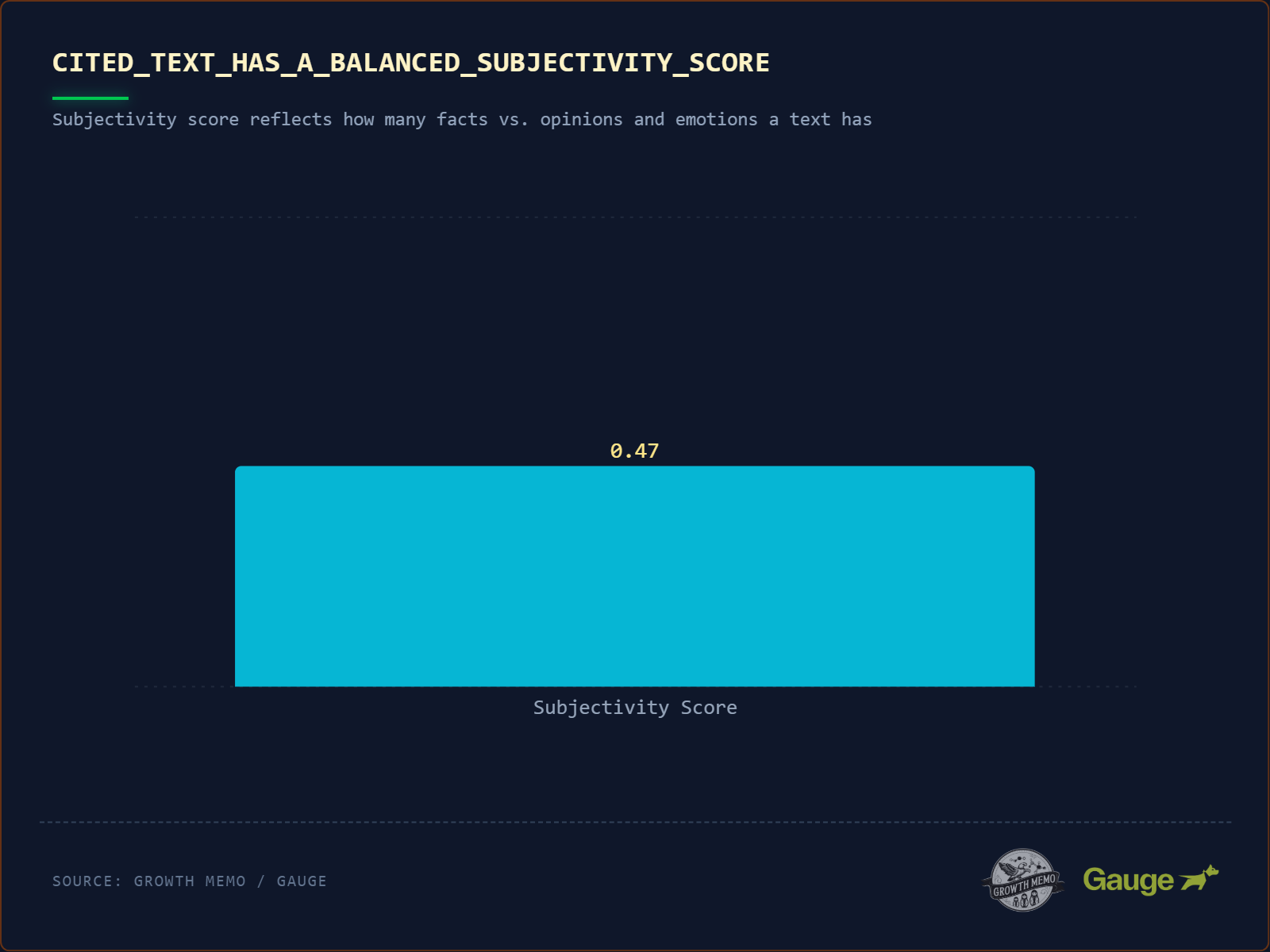
Die methodische Einordnung: Der Subjectivity Score ist eine Standard-Metrik im Natural Language Processing (NLP) und misst den Anteil persönlicher Meinungen, Emotionen oder Wertungen in einem Text. Die Studie nutzt ihn, um zu zeigen, dass ein ausgewogener Ton bevorzugt wird. Aber wie belastbar ist dieser Wert?
Zunächst das methodische Problem: Ein Subjectivity Score von 0,47 ist ein Durchschnitt. Durchschnitte können irreführend sein, wenn die Verteilung bimodal ist – also wenn sowohl sehr objektive als auch sehr subjektive Texte zitiert werden und sich der Mittelwert „zufällig“ bei 0,5 einpendelt. Ohne Einsicht in die Verteilung der Scores (Standardabweichung, Quartile) ist die Aussagekraft begrenzt.
Trotzdem ist das Ergebnis wissenschaftlich plausibel, und zwar aus zwei Gründen:
Erstens durchlaufen alle modernen LLMs ein Safety-Alignment via RLHF. In diesem Prozess werden die Modelle systematisch darauf trainiert, ausgewogene, hilfreiche und nicht-polarisierende Antworten zu bevorzugen. Wenn ein Retrieval-System einen Textbaustein für eine Antwort auswählt, wird ein Kandidat, der selbst bereits dem trainierten „Ton“ des Modells ähnelt, mit höherer Wahrscheinlichkeit übernommen. Extreme Meinungen – ob euphorisch positiv oder harsch negativ – weichen vom trainierten Gleichgewicht ab und werden häufiger verworfen.
Zweitens gibt es einen informativen Grund: Ein rein faktischer Satz („Das iPhone 15 wurde im September 2023 veröffentlicht“) beantwortet ein „Wann?“, aber kein „Warum sollte mich das interessieren?“. Ein rein meinungsbasierter Satz („Das iPhone 15 ist ein absolutes Meisterwerk!“) liefert keine verwertbare Information. Der „Sweet Spot“ bei ~0,5 ergibt sich, weil die nützlichsten Antworten Fakt und Einordnung verbinden: „Das iPhone 15 setzt auf den A16-Chip (Fakt), was es besonders für Content Creator attraktiv macht (Analyse).“
Das Fazit für deine Praxis: Schreib wie ein Analyst, nicht wie ein Marktschreier und nicht wie ein Lexikon. Jede Behauptung braucht einen Fakt als Fundament, und jeder Fakt profitiert von einer Einordnung, die dem Leser (und der KI) sagt, warum er relevant ist. Vermeide sowohl werbliche Superlative („Das beste Tool aller Zeiten!“) als auch emotionslose Datenfriedhöfe.
E. Business-Grade Writing (Einfachheit ≠ Verdummung)
Was die Studie sagt: „Winner“-Texte haben einen Flesch-Kincaid-Grade-Level von 16 (College-Niveau), „Loser“-Texte von 19,1 (akademisches PhD-Niveau). Selbst bei komplexen Themen schadet übermäßige sprachliche Komplexität.
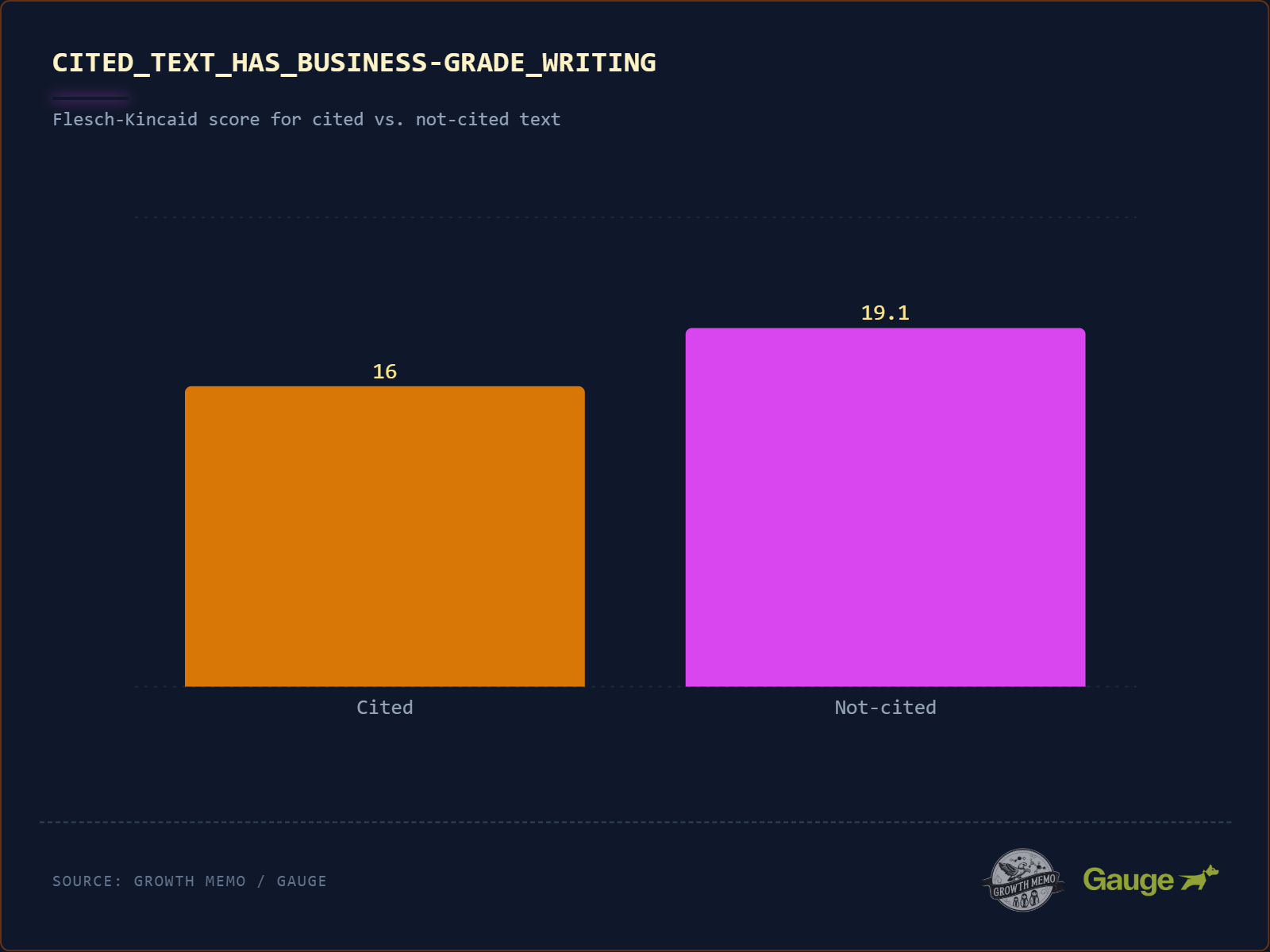
Die methodische Einordnung: Der Flesch-Kincaid-Score ist eine der ältesten Lesbarkeitsformeln (Kincaid et al., 1975) und basiert auf genau zwei Variablen: durchschnittliche Satzlänge und durchschnittliche Silbenzahl pro Wort. Das ist einerseits ein Vorteil (objektiv, reproduzierbar), andererseits eine massive Vereinfachung. Der Score misst Oberflächenkomplexität, nicht inhaltliche Tiefe.
Was die Studie trotzdem richtig erfasst, ist ein Architektur-Effekt der Transformer-Modelle. LLMs verarbeiten Text Token für Token und berechnen Attention-Gewichte zwischen allen Token-Paaren in einem Fenster. Bei langen Schachtelsätzen mit vielen Einschüben steigt die Distanz zwischen semantisch zusammengehörigen Token. Die Attention muss über mehr „Rauschen“ hinweg die richtige Verbindung herstellen – was die Wahrscheinlichkeit erhöht, dass der semantische Bezug verloren geht.
Konkret: Der Satz „Salesforce, das 1999 von Marc Benioff gegründete und heute in San Francisco ansässige Unternehmen, das sowohl im B2B- als auch im B2C-Segment aktiv ist, bietet eine CRM-Lösung an“ zwingt das Modell, über 25+ Token hinweg die Verbindung zwischen „Salesforce“ und „CRM-Lösung“ aufrechtzuerhalten. Der Satz „Salesforce bietet eine CRM-Lösung an“ erzeugt die gleiche Kernaussage mit maximaler Attention-Konzentration.
Hier widerlegt die Studie übrigens eine verbreitete Annahme in der SEO-Szene: Nein, KI belohnt nicht das „Dumbing Down“ von Content! Ein Flesch-Kincaid-Score von 16 ist College-Niveau – das entspricht dem Stil von The Economist oder Harvard Business Review. Es geht nicht darum, Fachsprache zu vermeiden, sondern darum, sie in klaren syntaktischen Strukturen zu verpacken. „Einfache Sprache“ bedeutet: kurze Sätze, Subjekt-Verb-Objekt, ein Gedanke pro Satz. Es bedeutet nicht: einfache Gedanken.
Das Fazit für deine Praxis: Vereinfache die Satzstruktur, nicht den Inhalt. Zerlege komplexe Aussagen in mehrere kurze Sätze. Nutze Fachbegriffe, wenn sie nötig sind – aber bette sie in klare syntaktische Strukturen ein. Dein Zielwert ist „The Economist“, nicht „Blöd-Zeitung“ und nicht „Doktorarbeit“.
Du willst tiefer in die Welt der Generative Engine Optimization eintauchen und lernen, wie du deine Inhalte systematisch für die KI-Suche fit machst? Genau darum geht es in meinem neuen Buch „SEO für KI – Auf den Punkt“, an dem ich gerade schreibe. Abonniere gerne meinen Newsletter, um den Start nicht zu verpassen.
Abonniere das AFAIK-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz im Online Marketing!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen Rund um KI aus den Bereichen Online-Marketing, SEO, GEO, WordPress und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.



