
Wer heute in AI-Visibility-Tracking investiert, sollte vorher die Grundlagenforschung kennen. Eine neue Studie von Rand Fishkin (SparkToro) und Patrick O’Donnell (Gumshoe.ai) liefert erstmals belastbare Daten zur Konsistenz von Markenempfehlungen in ChatGPT, Claude und Google AI. Die Ergebnisse sind ernüchternd — und gleichzeitig aufschlussreich.

Das Experiment
600 Freiwillige gaben 12 identische Prompts jeweils 60–100 Mal in die drei meistgenutzten KI-Tools ein: ChatGPT, Claude und Google Search AI (Overviews bzw. AI Mode). Insgesamt wurden 2.961 Antworten erfasst, normalisiert und statistisch ausgewertet. Die Prompts deckten verschiedene Branchen und Kategoriengrößen ab — von Kochmessern über Kopfhörer bis hin zu Krebskliniken und Digital-Marketing-Beratungen.
Die methodische Grundlage bildete die Carnegie-Mellon-Studie „Estimating LLM Consistency“, deren Pairwise-Correlation-Metriken für die Analyse übernommen wurden. Die Rohdaten sind öffentlich verfügbar.
Allein bei der Frage nach Kochmessern für Hobbyköche produzierte ChatGPT eine erstaunliche Vielfalt an Marken und Modellen — mit teils über 40 verschiedenen Empfehlungen in der Gesamtauswertung:
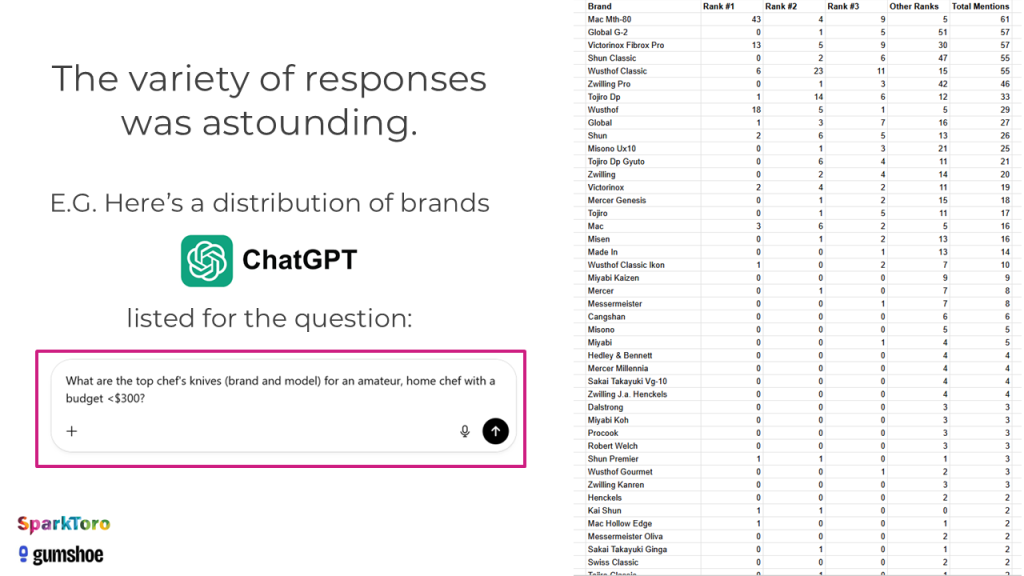
Die Kernbefunde
Nahezu jede Antwort ist ein Unikat. Stellt man einem KI-Tool hundertmal dieselbe Frage nach Markenempfehlungen, unterscheiden sich die Antworten in drei Dimensionen: welche Marken genannt werden, in welcher Reihenfolge sie erscheinen und wie viele Empfehlungen die Liste überhaupt enthält.
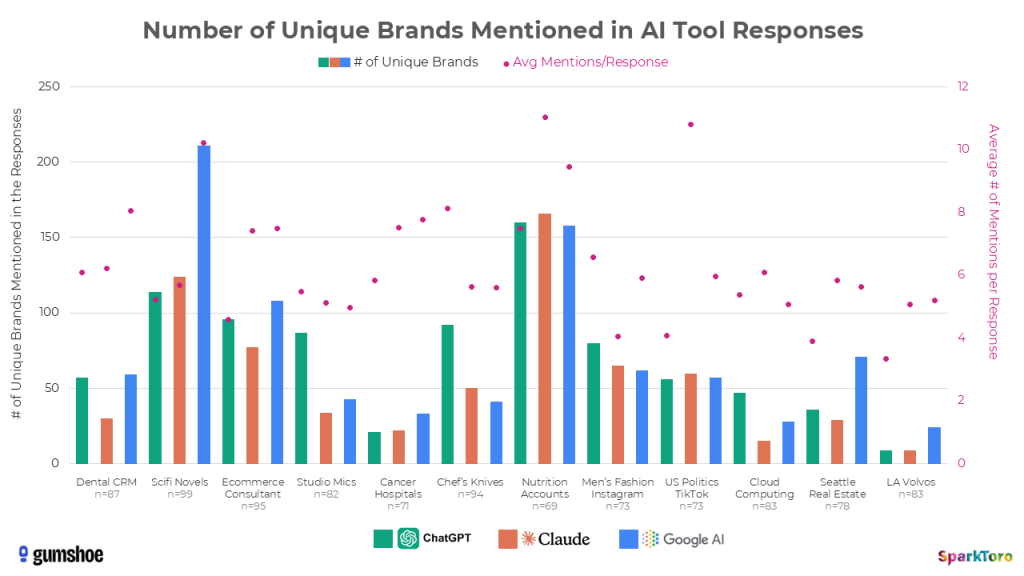
Die folgende Grafik zeigt, wie viele einzigartige Marken die drei KI-Tools über alle 12 Prompt-Kategorien hinweg nannten. In breiten Kategorien wie Science-Fiction-Romanen oder Nutrition Accounts auf Social Media explodierten die Zahlen — in engen Märkten wie LA-Volvo-Händlern blieben sie überschaubar:
Listenidentität unter 1 %. Die Wahrscheinlichkeit, dass ChatGPT oder Google AI bei zwei beliebigen Durchläufen dieselbe Markenliste zurückgibt, liegt unter 1:100. Claude produziert minimal häufiger identische Listen (1,65 %), variiert dafür die Reihenfolge noch stärker (0,07 % Übereinstimmung):
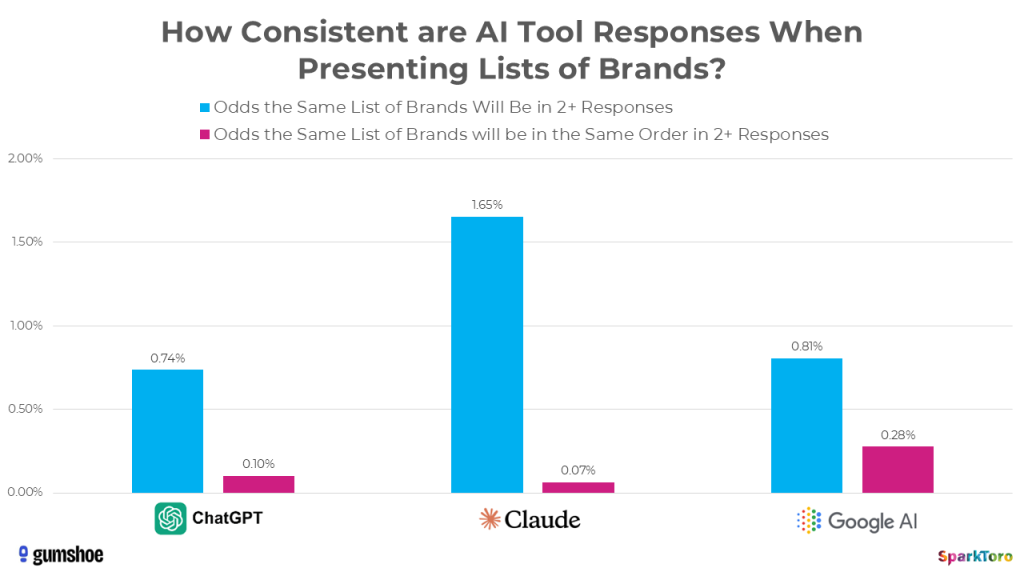
Reihenfolge praktisch zufällig. Dieselbe Reihenfolge zweimal zu erhalten, hat eine Wahrscheinlichkeit von etwa 1:1.000. Wer also „Ranking-Positionen in KI“ trackt, misst statistisches Rauschen.
Listenlänge variiert unkontrolliert. Manche Antworten enthalten zwei bis drei Empfehlungen, andere zehn oder mehr — bei identischem Prompt.
Aber: Visibility-Prozente haben Substanz
Fishkins Ausgangshypothese war, dass AI-Tracking grundsätzlich nutzlos sei. Diese Hypothese wurde teilweise widerlegt. Denn obwohl Listen, Reihenfolge und Umfang massiv schwanken, zeigt sich über viele Durchläufe hinweg ein stabiles Muster: Bestimmte Marken tauchen konsistent häufiger auf als andere.
Die folgende Grafik zeigt für alle 12 Kategorien und drei KI-Tools, wie oft die jeweils am häufigsten, zweithäufigsten und dritthäufigsten genannten Marken in den Antworten auftauchten:
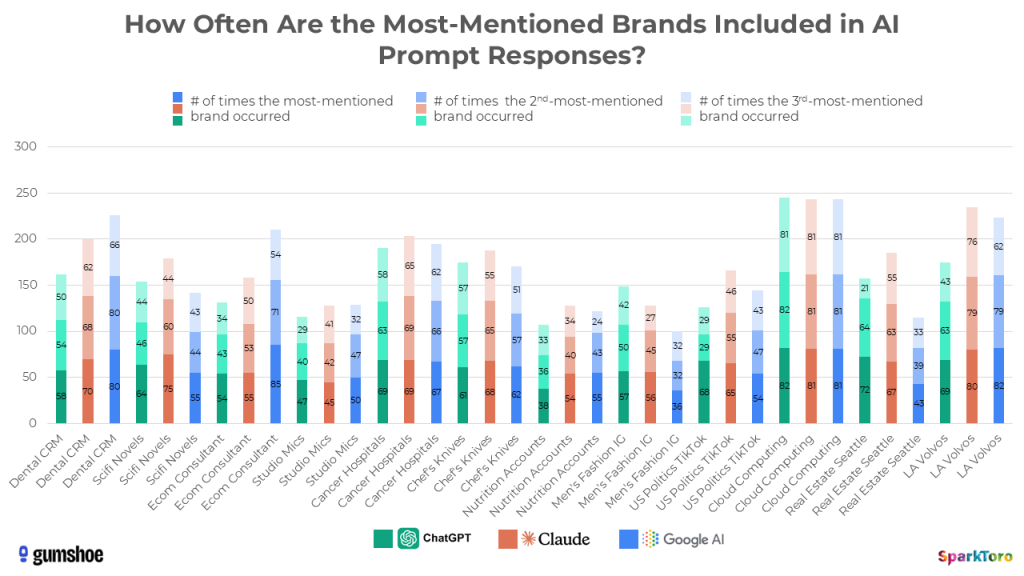
Beispiel: Bei der Frage nach Digital-Marketing-Beratungen mit E-Commerce-Expertise erschien die Agentur Smartsites in 85 von 95 Google-AI-Antworten. City of Hope tauchte bei der Frage nach den besten Krebskliniken an der US-Westküste in 69 von 71 ChatGPT-Antworten auf — eine Sichtbarkeit von 97 %. Aber: Nur in 25 dieser 71 Antworten war City of Hope auch die erstgenannte Empfehlung.
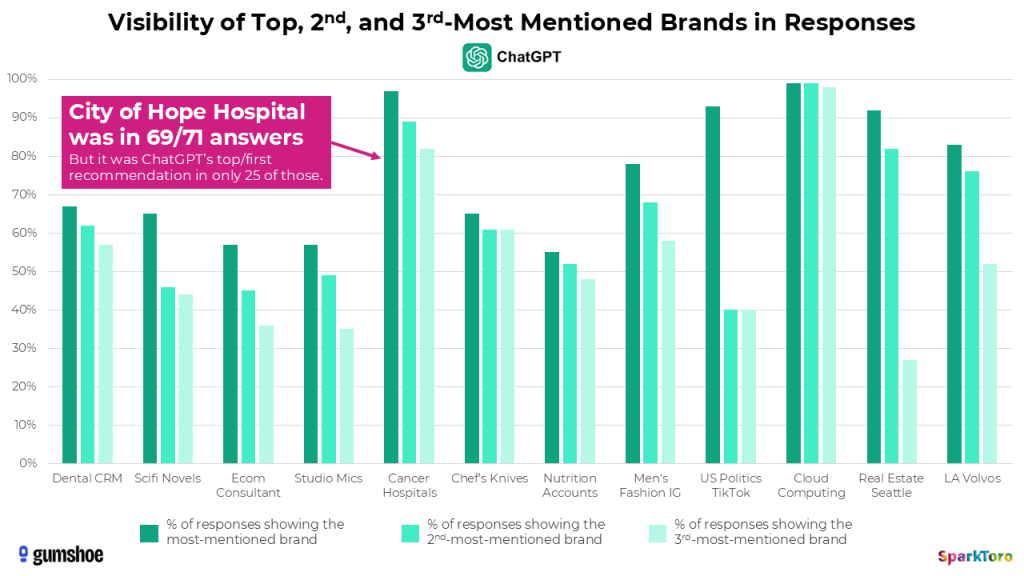
Die entscheidende Erkenntnis: Nicht die Position in einer einzelnen Antwort ist aussagekräftig, sondern die Häufigkeit des Erscheinens über viele Durchläufe hinweg. Visibility-Prozent — also der Anteil an Antworten, in denen eine Marke überhaupt genannt wird — scheint eine statistisch belastbare Metrik zu sein.
Kategoriegröße bestimmt Varianz
Die Studie zeigt einen klaren Zusammenhang zwischen der Breite einer Kategorie und der Streuung der Ergebnisse. Die Konsistenz variiert stärker zwischen Branchen als zwischen KI-Tools — ein zentraler Befund:
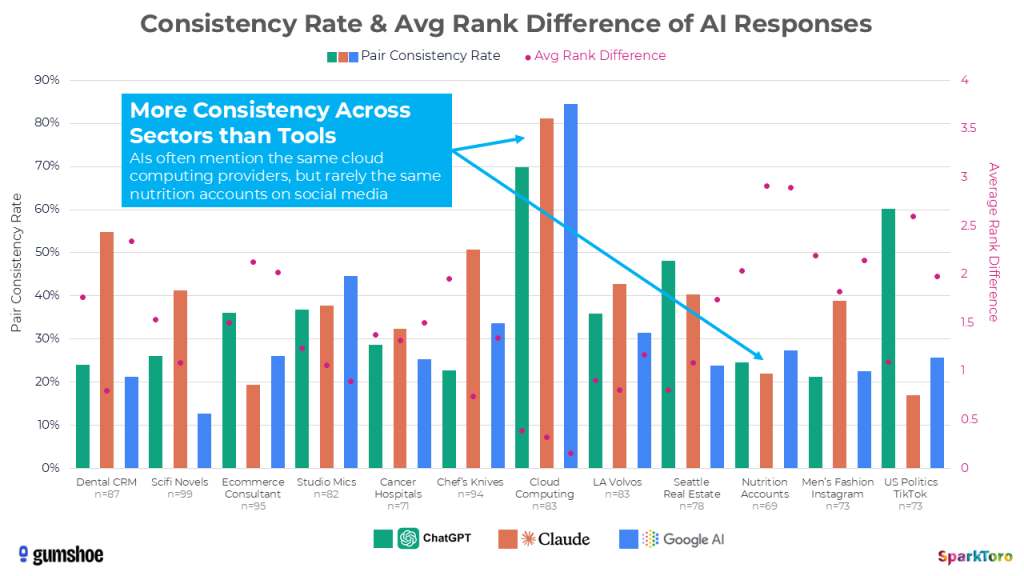
In engen Märkten mit wenigen relevanten Anbietern — etwa Cloud-Computing-Anbieter für SaaS-Startups — liegt die Pairwise-Konsistenzrate bei 70–85 %. In breiten Kategorien wie Science-Fiction-Romanen oder Branding-Agenturen fällt sie auf unter 15 %. Die KI hat schlicht mehr Optionen zur Auswahl, was die Streuung erhöht. Für GEO bedeutet das: Je fragmentierter der Markt, desto schwieriger ist es, konsistente Sichtbarkeit zu erreichen — und desto wichtiger wird eine systematische Strategie.
Das Prompt-Problem
Ein zweiter Teil der Studie untersuchte, wie echte Menschen Prompts formulieren. 142 Teilnehmer schrieben Prompts mit derselben Intention (Kopfhörer-Empfehlung für ein reisendes Familienmitglied). Die semantische Ähnlichkeit zwischen den Prompts lag bei 0,081 — extrem niedrig. Die Heatmap visualisiert diese Dissimilarität eindrücklich:
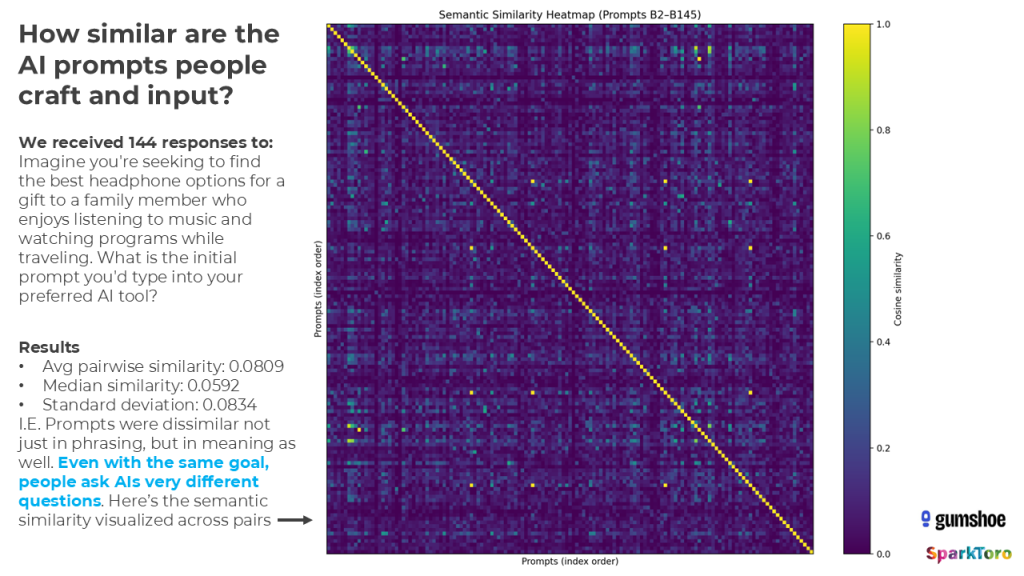
Trotzdem: Die KI-Tools erkannten die zugrunde liegende Intention zuverlässig und lieferten über 994 Antworten hinweg ein konsistentes Set an Top-Marken. Gumshoe ließ alle 142 einzigartigen Prompts durch ihr System laufen — das Ergebnis bestätigte die Befunde der kontrollierten Studie:

Intent überlebt Prompt-Varianz. Die Tools sind besser im Erkennen der Absicht als im konsistenten Formatieren der Antwort.
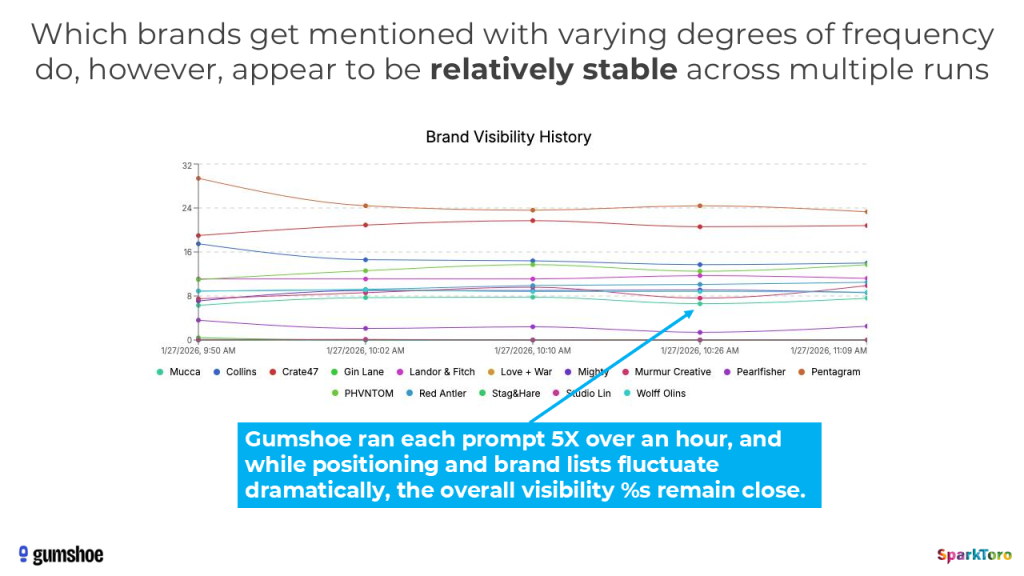
Auch über die Zeit hinweg bleiben die Visibility-Prozente relativ stabil, selbst wenn die konkreten Listen und Positionen sich bei jedem Durchlauf ändern:
Was das für GEO-Strategien bedeutet
1. Ranking-Position in KI-Antworten ist bedeutungslos. Jedes Tool oder jeder Anbieter, der „Platz 1 bei ChatGPT“ als Metrik verkauft, verkauft statistische Artefakte. Die einzig sinnvolle Metrik ist die prozentuale Sichtbarkeit über viele Durchläufe.
2. Visibility-Tracking braucht Volumen. Einzelne Stichproben sind wertlos. Fishkin empfiehlt mindestens 60–100 Durchläufe pro Prompt, um belastbare Daten zu erhalten. Anbieter von AI-Tracking-Tools sollten ihre Methodik offenlegen und statistisch validieren.
3. Intent-Orientierung schlägt Keyword-Optimierung. Weil Nutzer ihre Prompts radikal unterschiedlich formulieren, die KI-Tools aber die Intention zuverlässig erkennen, muss GEO auf Intent-Cluster statt auf einzelne Formulierungen optimieren.
4. Marktbreite ist ein strategischer Faktor. In Nischen mit wenigen Anbietern reicht konsistente Präsenz in den relevanten Quellen. In fragmentierten Märkten braucht es eine breitere Strategie mit mehr Touchpoints im Trainingscorpus der Modelle.
5. Anbieter-Transparenz einfordern. Bevor Budget in AI-Tracking fließt, sollten Unternehmen folgende Fragen stellen: Wie oft wird jeder Prompt ausgeführt? Wird die Methodik öffentlich dokumentiert? Wie wird mit der dokumentierten Varianz umgegangen? Werden Ranking-Positionen berichtet (die laut Forschung bedeutungslos sind)?
Einordnung und offene Fragen
Die SparkToro-Studie ist die erste öffentliche Untersuchung dieser Art — und sie ist methodisch transparent. Fishkin und O’Donnell veröffentlichen Rohdaten, Prompts und Methodik. Gleichzeitig bleiben Fragen offen:
- API vs. Web-Interface: Erste Hinweise deuten darauf hin, dass API-Antworten sich von Interface-Antworten unterscheiden könnten. Das ist relevant, weil die meisten Tracking-Tools über APIs arbeiten.
- Zeitliche Stabilität: Die Daten stammen aus November/Dezember 2025. Ob Visibility-Werte über Monate hinweg stabil bleiben, ist ungeklärt.
- Stichprobengröße: Für eine vollwertige statistische Absicherung wären deutlich größere Samples nötig.
- Modell-Updates: Wie sich Modell-Aktualisierungen auf die Visibility einzelner Marken auswirken, wurde nicht untersucht.
Ausblick: Weitere Forschung in Vorbereitung
Die SparkToro-Studie ist ein wichtiger erster Schritt — aber sie kratzt erst an der Oberfläche. In unserer Research Group an der RPTU Kaiserslautern-Landau bereitet aktuell ein Doktorand eine groß angelegte wissenschaftliche Studie vor, die genau diese Fragestellungen systematisch untersucht. Denn neben den von Fishkin und O’Donnell betrachteten Variablen gibt es weitere Faktoren, die die Konsistenz und Zusammensetzung von KI-Empfehlungen beeinflussen und bislang nicht erfasst wurden.
Ohne zu viel vorwegzunehmen: Wir setzen an mehreren Stellen an, an denen die SparkToro-Studie designbedingt Grenzen hat. Das Panel aus menschlichen Freiwilligen war für eine explorative Studie sinnvoll, limitiert aber Reproduzierbarkeit und Skalierung. Unsere Studie wird auf technisch automatisierten Testläufen basieren, mit deutlich höheren Stichprobengrößen und einer breiteren Abdeckung an Plattformen über die drei US-Marktführer hinaus. Zudem planen wir eine Anbindung an den existierenden akademischen Forschungsstand — etwa durch den Rückgriff auf etablierte Prompt-Kataloge aus Benchmarks wie GEO-Bench —, um die Ergebnisse in den wissenschaftlichen Diskurs einordnen zu können.
Ich werde hier in den kommenden Monaten deutlich mehr in diese Richtung berichten.
Fazit
Die Studie bestätigt, was viele im GEO-Umfeld intuitiv vermutet haben: KI-Empfehlungen sind probabilistisch, nicht deterministisch. Rankings in KI-Antworten sind Zufall. Aber die Häufigkeit, mit der eine Marke im Consideration Set der Modelle auftaucht, ist messbar und strategisch relevant.
Für Unternehmen bedeutet das: Nicht die Position in einer einzelnen Antwort entscheidet, sondern die systematische Präsenz in den Datenquellen, aus denen KI-Modelle ihre Empfehlungen generieren. Genau das ist der Kern von Generative Engine Optimization.
Quelle: Fishkin, R. & O’Donnell, P. (2026). „NEW Research: AIs are highly inconsistent when recommending brands or products.“ SparkToro Blog, 27. Januar 2026. sparktoro.com
Alle Grafiken: © SparkToro / Gumshoe.ai — verwendet mit Quellenangabe zu Analysezwecken.
Abonniere das AFAIK-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz im Online Marketing!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen Rund um KI aus den Bereichen Online-Marketing, SEO, GEO, WordPress und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.



