
Wer in der SEO-Welt sozialisiert wurde, kennt Broders Dreiteilung aus dem Jahr 2002: Navigational, Informational, Transactional. Drei Kategorien, die zwei Jahrzehnte lang als Goldstandard galten. Doch seit Large Language Models nicht mehr nur Links ranken, sondern Antworten generieren, reicht dieses Modell nicht mehr aus. Die zentrale Frage hat sich verschoben: Nicht mehr „Welche Seite passt zur Suchanfrage?“, sondern „Wird die Engine überhaupt externe Quellen heranziehen, um diese Antwort zu erzeugen?“
Genau an dieser Stelle arbeite ich gerade an einem akademischen Framework: der Generative Intent Operationalization (GIO). Und während ich das Paper schreibe, liefern OpenAI und Microsoft unabhängig voneinander empirische Daten und Systemsignale, die zeigen, wie drängend die Frage nach einer neuen Intent-Taxonomie geworden ist. Dieser Beitrag ordnet diese Entwicklungen ein.
Warum es ein neues Framework braucht
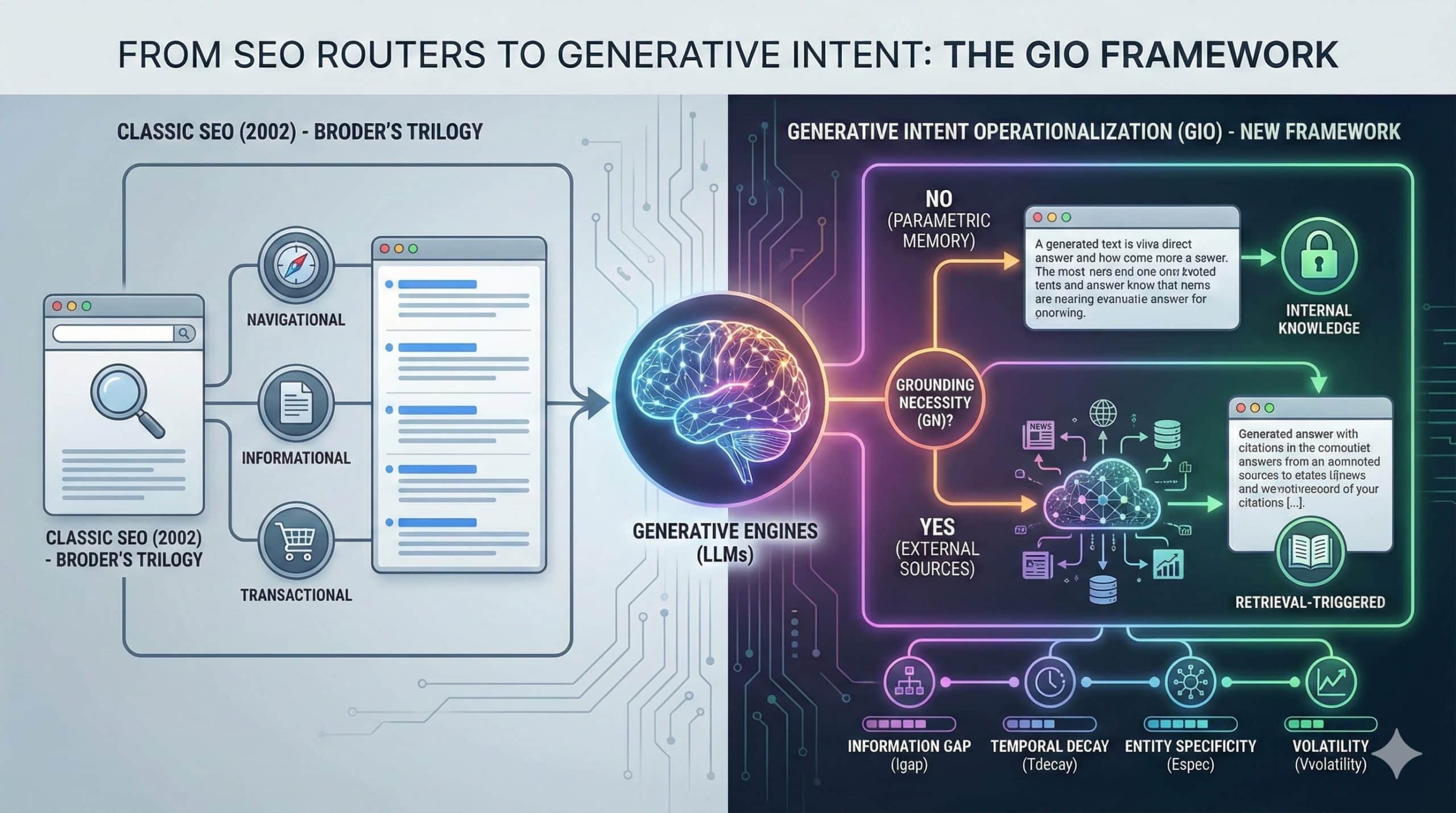
Klassische Intent-Modelle wurden für Suchmaschinen gebaut, die als deterministische Router funktionieren: Der Nutzer gibt eine Anfrage ein, das System liefert eine Ergebnisliste, der Nutzer klickt. Das Retrieval war implizit — jede Suchanfrage löste eine Suche aus.
Generative Engines funktionieren fundamental anders. Sie sind probabilistische Antwortmaschinen, die entscheiden müssen, ob sie externe Quellen brauchen. Ein GPT-Modell kann „Wie binde ich eine Krawatte?“ komplett aus dem parametrischen Gedächtnis beantworten. Aber „Welche Förderungen gibt es 2026 für Wärmepumpen in Baden-Württemberg?“ erfordert zwingend aktuelle externe Daten. Diese Unterscheidung – parametrisch lösbar vs. grounding-abhängig – existiert in keinem klassischen Modell.
Für GEO-Strategen ist das der entscheidende Hebel: Nur wenn die Engine retrieval-getriggert arbeitet, besteht überhaupt die Möglichkeit, als Quelle zitiert zu werden. Content, der auf rein parametrische Anfragen optimiert wird, ist verschwendete Energie.
GIO formalisiert genau diesen Hebel. Das Framework klassifiziert Nutzer-Intents vor der Antwortgenerierung anhand der Grounding Necessity (GN) – der epistemischen Notwendigkeit, externe Evidenz heranzuziehen. GN wird dabei über vier Dimensionen operationalisiert: Information Gap (Igap), Temporal Decay (Tdecay), Entity Specificity (Espec) und Volatility (Vvolatility). Das Ergebnis ist eine Klassifizierungsmatrix, die direkt in GEO-Strategien übersetzt werden kann.
Was OpenAI über die eigene Nutzung weiß: Die NBER-Studie
Im September 2025 veröffentlichten Chatterji et al. unter dem Titel „How People Use ChatGPT“ (NBER Working Paper 34255) die bisher umfassendste Analyse von ChatGPT-Nutzungsdaten. Die Studie klassifizierte über eine Million Konversationen anhand von fünf Taxonomien:
1. Work/Non-Work (binär): 73% aller Nachrichten im Juni 2025 waren nicht arbeitsbezogen. Für GEO-Zwecke ist diese Dimension irrelevant – Grounding Necessity ist unabhängig davon, ob jemand beruflich oder privat fragt.
2. Conversation Topic (24 Kategorien, 7 Gruppen): Die drei dominanten Gruppen sind Practical Guidance (~29%), Seeking Information (~24%) und Writing (~24%). Hier liegt das erste Problem für GEO-Strategen: „Writing“ umfasst sowohl „Schreib mir ein Anschreiben“ (rein parametrisch, kein Retrieval nötig) als auch „Fasse den aktuellen EZB-Zinsentscheid zusammen“ (zwingend grounding-abhängig). Die Kategorie ist aus Grounding-Perspektive blind.
3. Asking/Doing/Expressing (ternär): Die analytisch interessanteste Dimension. „Asking“ (49%) beschreibt Informations- und Beratungssuche, „Doing“ (40%) die Auftragserteilung an das Modell, „Expressing“ (11%) den Ausdruck von Gefühlen oder Meinungen ohne Handlungserwartung. Für eine GIO-Pipeline könnte diese Dreiteilung als Vorfilter dienen: „Expressing“ und rein kreatives „Doing“ (Fiktion, Rollenspiel) haben praktisch null GEO-Relevanz und können vor der aufwändigeren GN-Analyse ausgeschlossen werden. Aber: Eine „Asking“-Frage nach der Höhe des Eiffelturms hat null Retrieval-Bedarf, während eine „Doing“-Anfrage zur Zusammenfassung einer neuen Gesetzgebung maximalen Bedarf hat. Der Vorfilter spart Rechenkosten, ersetzt aber nicht die epistemische Analyse.
4. O*NET Work Activities: Eine arbeitsmarktsoziologische Zuordnung zu 332 Intermediate Work Activities. Für GEO irrelevant.
5. Interaction Quality: Post-Generation-Analyse der Nutzerzufriedenheit. Per Definition nicht pre-generation-fähig.
Das Fazit: Die Chatterji-Studie beantwortet die Frage „Was tun Nutzer mit ChatGPT?“ – deskriptiv, soziologisch, auf aggregierter Ebene. Mein GIO-Framework beantwortet eine orthogonale Frage: „Wird die Engine für diesen spezifischen Prompt externe Quellen heranziehen?“ Die beiden Ansätze sind komplementär, aber nicht substituierbar.
Was Microsoft intern verwendet: Die Bing AI Performance-Klassifizierung
Parallel zur akademischen Debatte gibt es Signale aus der Industrie, die zeigen, dass die großen Anbieter intern längst eigene Intent-Taxonomien für ihre generativen Systeme operationalisieren.
Im Client-Side-Quellcode der Bing Webmaster Tools AI Performance (Beta) finden sich Hinweise auf eine 13-stufige Intent-Klassifizierung, die Microsoft offenbar für die Zuordnung von Citations in Copilot/Bing AI verwendet:
- Navigational
- Learning and Problem Solving
- Creation
- Entertainment
- Shopping or Transaction
- Small Talk
- Informational Search
- Utility
- Multimedia Search
- Research
- Planning
- Comparison
- Others
Diese Taxonomie ist bemerkenswert, weil sie mehrere Dinge gleichzeitig zeigt.
Erstens: Microsoft unterscheidet zwischen „Informational Search“ und „Research“ – eine Trennung, die implizit verschiedene Grounding-Tiefen abbildet. Eine einfache Faktenabfrage (Informational Search) kann oft parametrisch beantwortet werden; eine Recherche (Research) erfordert typischerweise Multi-Source-Synthese mit hoher Grounding Necessity.
Zweitens: Kategorien wie „Small Talk“ und „Entertainment“ sind aus GEO-Perspektive Nullwert-Kategorien – analog zu GIOs Einordnung als „Low GN“. Die Engine wird für Smalltalk keine externen Quellen zitieren. Wer Content für diese Kategorien optimiert, optimiert ins Leere.
Drittens: „Comparison“ als eigene Kategorie ist strategisch aufschlussreich. Vergleichsanfragen erfordern fast immer aktuelle, multi-attributive Daten aus mehreren Quellen – ein klassischer High-GN-Fall, der in GIO als Mode 1.2 (Real-Time Synthesis) mit hoher Komplexität eingeordnet würde.
Viertens: „Creation“ dürfte das gleiche Ambiguitätsproblem haben wie Chatterjis „Writing“ – es mischt parametrische Generierung („Schreib ein Gedicht“) mit grounding-abhängiger Produktion („Erstelle eine Marktanalyse zum deutschen E-Auto-Markt 2026“).
Die Quelle: RESENEOs Reverse-Engineering-Arbeit
Für die Hinweise auf Microsofts interne Klassifizierung und weit darüber hinaus gebührt Olivier de Segonzac, Gründer der Pariser Agentur RESONEO, besondere Anerkennung. RESONEO leistet derzeit echte Pionierarbeit im Bereich GEO-Reverse-Engineering und liefert damit empirische Grundlagen, die der akademischen Forschung oft fehlen.
Besonders hervorzuheben sind zwei Analysen:

Eine technische Analyse von Googles AI Overviews und AI Mode, die eine vierstufige Citation-Pipeline offenlegt (Information Retrieval, Grounding URLs, Pool, Displayed). Besonders relevant: RESONEO identifizierte Hidden Grounding URLs – Quellen, die das Modell zur Generierung heranzieht, aber dem Nutzer nie anzeigt. Diese Entdeckung hat direkte Implikationen für jede GEO-Strategie, weil sie zeigt, dass bisherige Sichtbarkeitsstudien die tatsächliche Retrieval-Nutzung systematisch unterschätzten. Ebenfalls aufgedeckt: AI Mode zerlegt Nutzeranfragen in 8-12 parallele Sub-Queries (bei Deep Search Hunderte), während AI Overviews kaum Sub-Query-Dekomposition betreiben – ein fundamentaler architektonischer Unterschied.
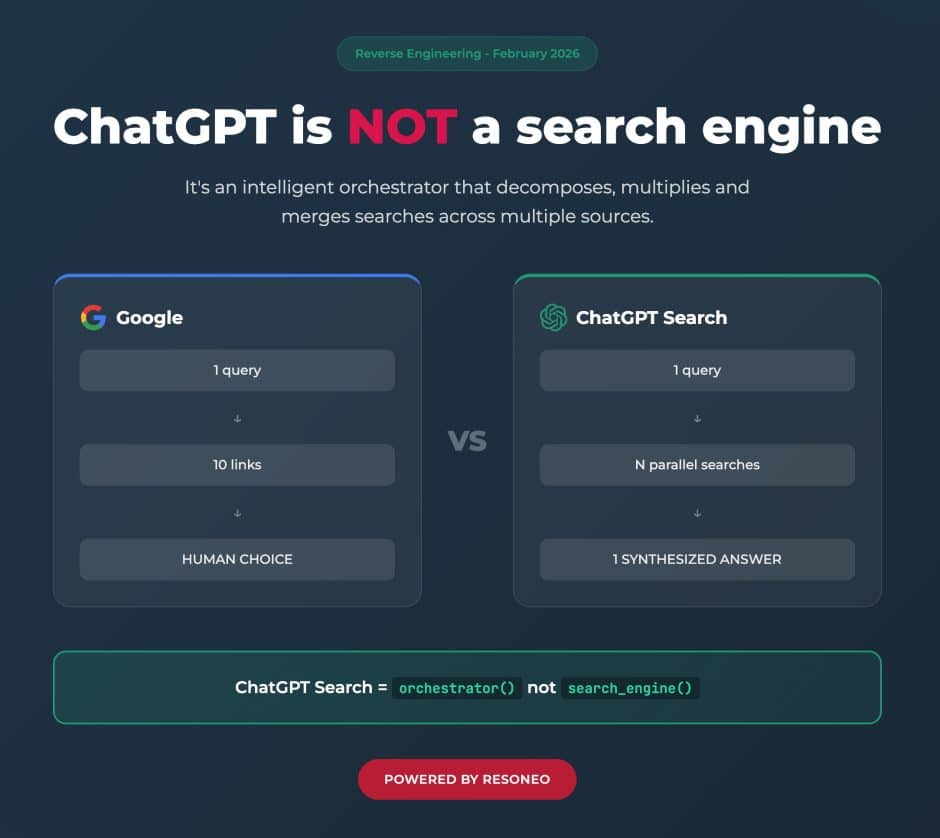
Eine Analyse des ChatGPT-Suchsystems, die unter anderem den Sonic Classifier identifizierte — einen probabilistischen Entscheider, der vor der Antwortgenerierung über einen search_prob-Score (Schwellenwert ~65%) bestimmt, ob externe Daten benötigt werden. Das ist exakt der Mechanismus, den GIO theoretisch modelliert: eine Pre-Generation-Entscheidung über Grounding Necessity. RESONEO dokumentierte außerdem das Fan-Out-System (1-3 Standard-Queries, 20+ im Thinking Mode) und die Abhängigkeit von Drittanbieter-Scrapern statt eigener Suchindizes.
Was alle drei Ansätze gemeinsam zeigen — und wo sie sich unterscheiden
Die Konvergenz ist bemerkenswert: OpenAI klassifiziert post-hoc, was Nutzer tun. Microsoft klassifiziert in Echtzeit, wie Citations zugeordnet werden. GIO klassifiziert pre-generation, ob Retrieval überhaupt nötig ist. Drei verschiedene Fragen, drei verschiedene Operationalisierungen — aber alle kreisen um denselben Kern: Die alte Dreiteilung Navigational/Informational/Transactional reicht für generative Systeme nicht mehr aus.
Die Unterschiede sind dabei ebenso aufschlussreich:
- Granularität vs. Operationalisierbarkeit: Chatterjis 24 Kategorien und Microsofts 13 Klassen bieten deskriptive Breite, aber keine direkte Handlungsanweisung für Content-Strategen. GIO ist bewusst schmaler angelegt, weil jede Klasse direkt in eine GEO-Strategie mündet.
- Post-hoc vs. Pre-Generation: Chatterjis Taxonomie wurde auf historische Konversationslogs angewendet. Microsofts Klassifizierung scheint in Echtzeit zu operieren (sie steuert die Citation-Zuordnung). GIO ist konzeptionell pre-generation: Es soll die Grounding-Entscheidung vorhersagen, bevor das Modell antwortet — und damit dem Content-Strategen ermöglichen, proaktiv zu optimieren.
- Deskriptiv vs. Prädiktiv: OpenAI und Microsoft beschreiben, was passiert. GIO will vorhersagen, was passieren wird — und daraus ableiten, was Content-Produzenten tun sollten.
Was das für die GEO-Praxis bedeutet
Für SEO-Professionals, die sich Richtung GEO bewegen, ergeben sich aus dieser Dreiecksbetrachtung konkrete Implikationen:
Erstens, die Chatterji-Daten zeigen, dass knapp die Hälfte aller ChatGPT-Nachrichten „Asking“-Queries sind – also Informations- und Beratungssuche. Das ist der primäre Raum, in dem GEO-Strategien greifen können. Die 11% „Expressing“ und ein substanzieller Teil der 40% „Doing“ (kreative Textproduktion, Rollenspiel) sind für Content-Publisher strategisch irrelevant.
Zweitens, Microsofts Trennung von „Informational Search“ und „Research“ als separaten Kategorien bestätigt, dass die Engine selbst zwischen unterschiedlichen Grounding-Tiefen differenziert. Wer Content produziert, sollte sich fragen: Ist das eine Faktenabfrage, die das Modell aus dem Kopf beantworten kann? Oder eine Recherchefrage, für die es zwingend aktuelle, strukturierte externe Daten braucht? Nur im zweiten Fall lohnt sich die GEO-Investition.
Drittens, RESENEOs Identifikation des Sonic Classifiers und der Hidden Grounding URLs zeigt: Die Mechanismen, die GIO theoretisch modelliert, existieren in der Praxis bereits als harte architektonische Entscheidungen. Die Frage „Wird die Engine retrieval-triggern?“ ist keine akademische Abstraktion, sondern ein messbarer Schwellenwert in produktiven Systemen.
Das GIO-Paper befindet sich derzeit in der Finalisierung. Es wird als Position Paper die theoretische Grundlage legen und einen empirischen Validierungsplan vorschlagen. Die hier diskutierten Industrie-Signale fließen bewusst nicht in das akademische Paper ein – dafür sind sie zu flüchtig und zu wenig dokumentiert. Aber sie bestätigen die zentrale These: Wer Generative Engine Optimization ernst nimmt, braucht ein Framework, das vor der Generierung ansetzt. Nicht bei dem, was Nutzer tun. Sondern bei dem, was die Engine tun wird.
Abonniere das AFAIK-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz im Online Marketing!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen Rund um KI aus den Bereichen Online-Marketing, SEO, GEO, WordPress und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Woche eine E-Mail von mir. Versprochen.



