

Du gibst deinem Coding-Agenten den Auftrag, eine Funktion in einem großen Projekt zu refactorn. Er beginnt zu greppen. Er öffnet Dateien. Er liest 200 Zeilen. Er verliert den Faden. Das Ergebnis ist halbgar. Nicht weil der Agent dumm ist – sondern weil er keine Übersicht von deiner Codebasis hat. WaveScope liefert diese.
Das Problem: Agenten navigieren blind
Jeder, der schon mal einen KI-Coding-Agenten auf eine echte, gewachsene Codebasis losgelassen hat, kennt das Muster: Das Modell kann unmöglich die gesamte Codebasis in seinen Kontext laden – das würde das Token-Budget sprengen. Also greift es auf das zurück, was es kann: grep, Dateiköpfe lesen, einzelne Blöcke untersuchen, raten.
Code hat aber eine hierarchische Struktur mit Ebenen und Grenzen. Funktionen stecken in Klassen. Klassen leben in Dateien. Dateien bilden Module. Eine einzige 400-Zeilen-Datei kann sechs konzeptuell völlig verschiedene Bereiche enthalten. Grep findet Textmuster – aber es weiß nicht, wo eine Klasse endet und die nächste anfängt.
Die zwei klassischen Lösungsansätze haben beide ihre Schwächen:
- Grep-Suche – findet exakte Texttreffer, ignoriert aber vollständig die Struktur
- Embedding-basiertes RAG – versteht semantische Bedeutung, verliert aber Position und Architektur
Keiner der beiden gibt dem Modell ein echtes Gefühl für die Architektur der Codebasis. WaveScope will das ändern – mit einem Ansatz aus der Signalverarbeitung.
Wäre es nicht schön, wenn der Agent wie du rein- und rauszoomen könnte – erst das große Bild, dann gezielt zu der Funktion springen, die er wirklich braucht?
Die Analogie: Progressive Bildladung
Kennst du das Phänomen, wenn eine Webseite ein JPEG lädt und das Bild nicht einfach von oben nach unten aufgebaut wird, sondern zunächst verschwommen erscheint und dann immer schärfer wird? Das nennt sich progressive Bildladung.
Zuerst siehst du das komplette Bild in niedriger Auflösung – grob, pixelig, aber erkennbar. Dann kommt mit jedem weiteren Lade-Durchgang mehr Detail hinzu. Am Ende ist das vollständig scharfe Bild da. Der entscheidende Vorteil: Du weißt von Anfang an, was du vor dir hast – und kannst entscheiden, ob es das ist, was du gesucht hast, bevor alle Details geladen sind.
Genau das macht WaveScope mit Code. Anstatt eine 500-Zeilen-Datei komplett in den Kontext zu laden, bekommt der Agent drei Zoom-Ebenen gleichzeitig:
Wie Wavelets funktionieren – und warum Code ein Signal ist
Bevor wir zu Wavelets kommen, eine Beobachtung: Code hat einen Rhythmus. Öffne eine beliebige Datei in Clojure, TypeScript, Rust oder Go – du siehst überall wiederkehrende Strukturen. Imports oben. Klassen- und Funktionsdefinitionen in regelmäßigen Abständen. Einrückungen mit ihren eigenen Mustern. Kommentarblöcke und Leerzeilen als Pausen dazwischen.
Was wäre, wenn man diese Muster extrahieren könnte – eine Art AST, ohne die Syntax der Sprache kennen zu müssen? Wavelets wurden genau dafür entwickelt: ein Signal in mehreren Auflösungen gleichzeitig zu zerlegen. Seismologen nutzen sie, um Erdbeben in Messdaten zu erkennen. Radiologen schärfen MRT-Aufnahmen damit. Tontechniker trennen Basslinien von Gesang. Code-Struktur ist eben auch ein Signal.
Schritt 1: Jede Zeile bekommt einen Score
WaveScope vergibt zunächst für jede Zeile einen numerischen Score basierend auf ihrem strukturellen Gewicht: class zählt 1.0, export 0.6, readonly-Felder etwa 0.08, Kommentare und Leerzeilen 0.0. So entsteht aus der Datei eine Sequenz von Zahlen – ein eindimensionales Signal, das mit der strukturellen Dichte steigt und fällt.
Schritt 2: Der Ricker-Wavelet findet Grenzen
Über dieses Signal wird nun der Ricker-Wavelet geschoben – eine kleine, charakteristisch geformte Schablone: eine Beule mit je einer Delle rechts und links davon (auch „Mexikanischer Hut“ genannt). An jeder Position misst WaveScope, wie gut das Signal darunter zu dieser Form passt. Ein starkes Match bedeutet: hier ist eine erhöhte Region zwischen zwei ruhigeren Bereichen – also eine strukturelle Grenze.
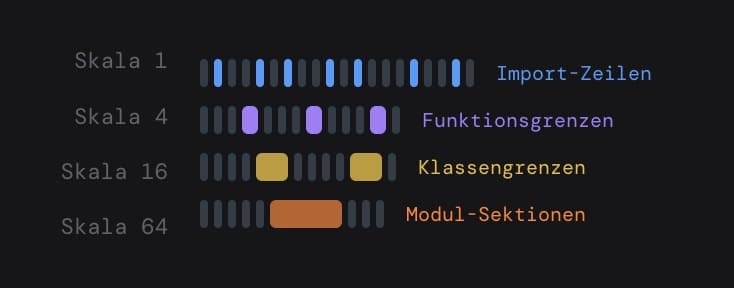
Der entscheidende Trick: Die Schablone wird in acht verschiedenen Breiten gleichzeitig geschoben – Skalen 1, 2, 4, 8, 16, 32, 64 und 128 Zeilen. Eine schmale Schablone reagiert auf kleine, scharfe Features wie einzelne import-Anweisungen. Eine breite ignoriert Zeilen-Level-Rauschen und reagiert auf große Strukturen wie ganze Klassen.
Schritt 3: Peaks werden erkannt und zu Bändern gruppiert
Aus dem Koeffizientenfeld extrahiert WaveScope die lokalen Maxima, rankt sie nach Stärke und kollabiert Duplikate (dieselbe Grenze erscheint ja auf mehreren benachbarten Skalen). Das Ergebnis ist eine sortierte Liste der strukturell wichtigsten Positionen in der Datei – sprachagnostisch, schnell, kein Parser nötig.
Reale Grenzen wie der Beginn einer Klasse erscheinen konsistent über mehrere Skalen hinweg – das unterscheidet sie von zufälligem Rauschen. Boilerplate-Regionen erhalten einen niedrigen Komplexitätsscore und können zusammengefasst oder übersprungen werden. Dichter, verzweigter Code erhält einen hohen Score und bekommt die volle Aufmerksamkeit des Agenten.
Was der Agent bekommt – und was das kostet
WaveScope wurde an realistischen Aufgaben auf seiner eigenen ~5.000-Zeilen-TypeScript-Codebasis getestet und mit dem klassischen Vorgehen verglichen (Greppen + Datei-Chunks lesen):
| Aufgabe | Klassisch (Tokens) | WaveScope (Tokens) | Ersparnis |
|---|---|---|---|
| Struktur einer 854-Zeilen-Datei verstehen | ~2.000 | ~750 | −63 % |
| Tangled Code für Refactoring finden | ~5.200 | ~436 | −92 % |
| Architektonisch zentrale Dateien identifizieren | ~2.900 | ~1.700 | −41 % |
Ein 128K-Token-Fenster würde für diese drei Aufgaben beim klassischen Ansatz 8 % seiner Kapazität verbrauchen. Mit WaveScope sind es 2 %. Und der Rechenaufwand für WaveScope selbst? Im Schnitt 3 Millisekunden pro Datei.
Ein 128K-Kontextfenster ist kein Freibrief. Je mehr drin ist, desto schwerer wird Fokussierung. WaveScope gibt dem Modell die Karte – nicht den vollen Karteninhalt.
WaveScope einbinden: Die drei großen Agenten
WaveScope ist ein MCP-Server und lässt sich in wenigen Minuten in jeden MCP-fähigen Agenten einbinden. Zuerst die globale Installation:
npm install -g wavescope-mcpClaude Code (Anthropic)
Entweder per CLI-Befehl hinzufügen:
claude mcp add wavescope -- wavescope-mcpOder manuell in .claude/mcp_config.json im Projektverzeichnis (bzw. global unter ~/.claude/mcp_config.json):
{
"mcpServers": {
"wavescope": {
"command": "wavescope-mcp"
}
}
}Claude Code erkennt verfügbare MCP-Tools automatisch und kann sie ohne weiteres Zutun aufrufen. Im Prompt direkt ansprechen: „Nutze WaveScope, um die Struktur von src/ zu analysieren, bevor du etwas änderst.“
OpenAI Codex CLI
Konfiguration in ~/.codex/config.json:
{
"mcpServers": {
"wavescope": {
"command": "wavescope-mcp"
}
}
}Alternativ direkt beim Aufruf als Flag:
codex --mcp-server "wavescope:wavescope-mcp" "Analysiere Struktur von src/"Google Antigravity 2.0
Antigravity 2.0, IDE und CLI teilen sich eine zentrale Konfiguration in ~/.gemini/config/mcp_config.json. Entweder direkt bearbeiten oder in der App: Agent-Panel → „…“ → MCP Servers → Manage MCP Servers → View raw config.
{
"mcpServers": {
"wavescope": {
"command": "wavescope-mcp"
}
}
}Hinweis: Antigravity nutzt für remote HTTP-Server serverUrl statt url – bei einem lokalen Binary wie WaveScope bleibt es aber bei command.
Den Agenten trainieren, wann er WaveScope nutzen soll
Die reine Konfiguration reicht nicht aus – der Agent muss auch wissen, wann er WaveScope einsetzen soll. Das geht über System-Anweisungen oder Custom Instructions. Eine bewährte Formulierung (auf Englisch, damit der Agent sie direkt versteht):
When navigating an unfamiliar codebase or working in large files (>100 lines),
always start with WaveScope's get_important_positions to get a structural overview
before opening any file. Use query_wavelet_context centered on the relevant line
before reading surrounding code. Use get_complexity_heatmap to identify
refactoring candidates before reading implementation details.Fazit: Eine Karte, kein Teleskop
WaveScope löst kein LLM-Problem – es löst ein Navigations- und Kontextproblem. Die Idee, Wavelets für strukturelle Code-Analyse zu nutzen, ist ungewöhnlich clever: kein Parser, keine Sprachabhängigkeit, kein großer Compute-Aufwand. Nur Signalverarbeitung auf einem 1D-Score-Signal – und das Ergebnis ist eine hierarchische, multi-skalare Karte der Codebasis.
Ob das in der Praxis mit größeren, komplexeren Projekten genauso gut funktioniert wie im Blog-Artikel beschrieben, muss sich noch zeigen – das Repository hat erst drei Stars und wurde Anfang Juni 2026 veröffentlicht. Aber die Idee ist solide, der Code liegt offen, und die Integration dauert fünf Minuten.
Für alle, die LLM-Agenten in Code-Review-, Analyse- oder Refactoring-Workflows einsetzen: WaveScope ist einen Test wert.
→ github.com/yogthos/wavescope-mcp
Abonniere das AFAIK-Update
Bleib auf dem Laufenden in Sachen Künstliche Intelligenz im Online Marketing!
Melde Dich jetzt mit Deiner E-Mail-Adresse an und ich versorge Dich kostenlos mit News-Updates, Tools, Tipps und Empfehlungen Rund um KI aus den Bereichen Online-Marketing, SEO, GEO, WordPress und vieles mehr.
Keine Sorge, ich mag Spam genauso wenig wie Du und gebe Deine Daten niemals weiter! Du bekommst höchstens einmal pro Monat eine E-Mail von mir. Versprochen.